利用 Scrapy 爬取知乎用户信息
思路:通过获取知乎某个大V的关注列表和被关注列表,查看该大V和其关注用户和被关注用户的详细信息,然后通过层层递归调用,实现获取关注用户和被关注用户的关注列表和被关注列表,最终实现获取大量用户信息。
一、新建一个scrapy项目
scrapy startproject zhihuuser
移动到新建目录下:
cd zhihuuser
新建spider项目:
scrapy genspider zhihu zhihu.com
二、这里以爬取知乎大V轮子哥的用户信息来实现爬取知乎大量用户信息。
a) 定义 spdier.py 文件(定义爬取网址,爬取规则等):
# -*- coding: utf-8 -*-
import json from scrapy import Spider, Request from zhihuuser.items import UserItem class ZhihuSpider(Spider):
name = 'zhihu'
allowed_domains = ['zhihu.com']
start_urls = ['http://zhihu.com/']
#自定义爬取网址
start_user = 'excited-vczh'
user_url = 'https://www.zhihu.com/api/v4/members/{user}?include={include}'
user_query = 'allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics'
follows_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
follows_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' followers_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
followers_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics'
#定义请求爬取用户信息、关注用户和被关注用户的函数
def start_requests(self):
yield Request(self.user_url.format(user=self.start_user, include=self.user_query), callback=self.parseUser)
yield Request(self.follows_url.format(user=self.start_user, include=self.follows_query, offset=0, limit=20), callback=self.parseFollows)
yield Request(self.followers_url.format(user=self.start_user, include=self.followers_query, offset=0, limit=20), callback=self.parseFollowers) #请求爬取用户详细信息
def parseUser(self, response):
result = json.loads(response.text)
item = UserItem() for field in item.fields:
if field in result.keys():
item[field] = result.get(field)
yield item
#定义回调函数,爬取关注用户与被关注用户的详细信息,实现层层迭代
yield Request(self.follows_url.format(user=result.get('url_token'), include=self.follows_query, offset=0, limit=20), callback=self.parseFollows)
yield Request(self.followers_url.format(user=result.get('url_token'), include=self.followers_query, offset=0, limit=20), callback=self.parseFollowers) #爬取关注者列表
def parseFollows(self, response):
results = json.loads(response.text) if 'data' in results.keys():
for result in results.get('data'):
yield Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), callback=self.parseUser) if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield Request(next_page, callback=self.parseFollows) #爬取被关注者列表
def parseFollowers(self, response):
results = json.loads(response.text) if 'data' in results.keys():
for result in results.get('data'):
yield Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), callback=self.parseUser) if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield Request(next_page, callback=self.parseFollowers)
b) 定义 items.py 文件(定义爬取数据的信息,使其规整等):
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html from scrapy import Field, Item class UserItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
allow_message = Field()
answer_count = Field()
articles_count = Field()
avatar_url = Field()
avatar_url_template = Field()
badge = Field()
employments = Field()
follower_count = Field()
gender = Field()
headline = Field()
id = Field()
name = Field()
type = Field()
url = Field()
url_token = Field()
user_type = Field()
c) 定义 pipelines.py 文件(存储数据到MongoDB):
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo #存储到MongoDB
class MongoPipeline(object): collection_name = 'users' def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db @classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE')
) def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db] def close_spider(self, spider):
self.client.close() def process_item(self, item, spider):
self.db[self.collection_name].update({'url_token': item['url_token']}, dict(item), True) #执行去重操作
return item
d) 定义settings.py 文件(开启MongoDB、定义请求头、不遵循 robotstxt 规则):
# -*- coding: utf-8 -*-
BOT_NAME = 'zhihuuser' SPIDER_MODULES = ['zhihuuser.spiders'] # Obey robots.txt rules
ROBOTSTXT_OBEY = False #是否遵守robotstxt规则,限制爬取内容。 # Override the default request headers(加载请求头):
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36',
'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20'
} # Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'zhihuuser.pipelines.MongoPipeline': 300,
} MONGO_URI = 'localhost'
MONGO_DATABASE = 'zhihu'
三、开启爬取:
scrapy crawl zhihu
部分爬取过程中的信息
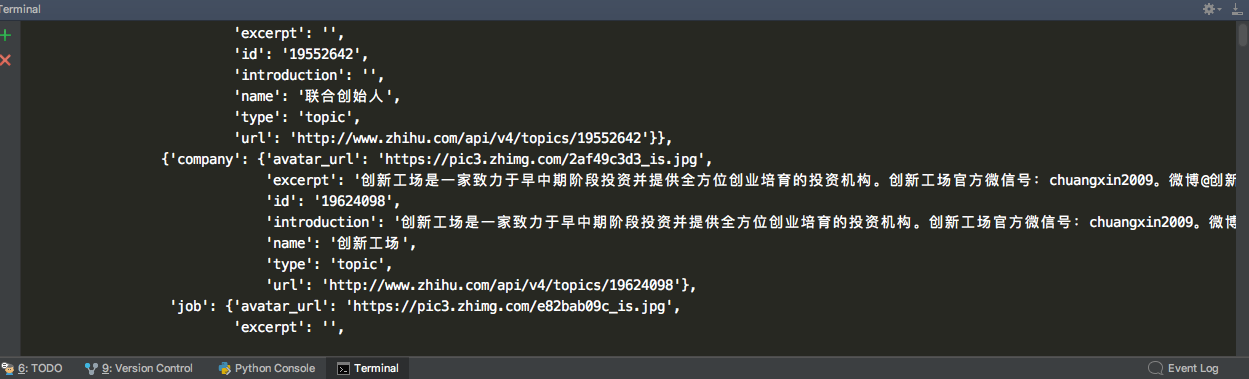
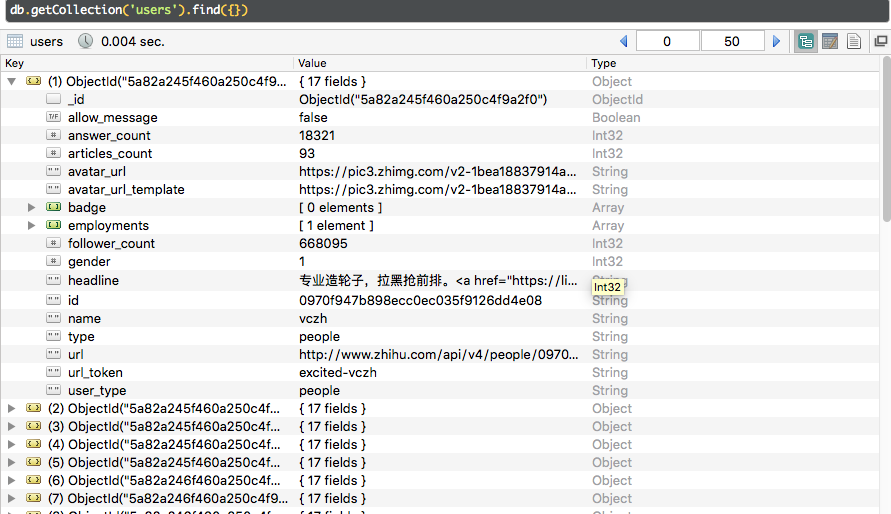
存储到MongoDB的部分信息:
利用 Scrapy 爬取知乎用户信息的更多相关文章
- 爬虫实战--利用Scrapy爬取知乎用户信息
思路: 主要逻辑图:
- 爬虫(十六):scrapy爬取知乎用户信息
一:爬取思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账 ...
- 基于webmagic的爬虫小应用--爬取知乎用户信息
听到“爬虫”,是不是第一时间想到Python/php ? 多少想玩爬虫的Java学习者就因为语言不通而止步.Java是真的不能做爬虫吗? 当然不是. 只不过python的3行代码能解决的问题,而Jav ...
- 使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法. 这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中. 首先,看一下我要爬取哪些内容: 如下图所示,我要爬取一个问题的6个信息: ...
- Srapy 爬取知乎用户信息
今天用scrapy框架爬取一下所有知乎用户的信息.道理很简单,找一个知乎大V(就是粉丝和关注量都很多的那种),找到他的粉丝和他关注的人的信息,然后分别再找这些人的粉丝和关注的人的信息,层层递进,这样下 ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- python scrapy爬取知乎问题和收藏夹下所有答案的内容和图片
上文介绍了爬取知乎问题信息的整个过程,这里介绍下爬取问题下所有答案的内容和图片,大致过程相同,部分核心代码不同. 爬取一个问题的所有内容流程大致如下: 一个问题url 请求url,获取问题下的答案个数 ...
- 利用Scrapy爬取所有知乎用户详细信息并存至MongoDB
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者 :崔庆才 本节分享一下爬取知乎用户所有用户信息的 Scrapy 爬虫实战. 本节目标 本节要实现的内容有 ...
- scrapy 爬取知乎问题、答案 ,并异步写入数据库(mysql)
python版本 python2.7 爬取知乎流程: 一 .分析 在访问知乎首页的时候(https://www.zhihu.com),在没有登录的情况下,会进行重定向到(https://www. ...
随机推荐
- Java基础学习笔记六 Java基础语法之类和ArrayList
引用数据类型 引用数据类型分类,提到引用数据类型(类),其实我们对它并不陌生,如使用过的Scanner类.Random类.我们可以把类的类型为两种: 第一种,Java为我们提供好的类,如Scanner ...
- string和c_str()使用时的坑
先看一段代码和它的运行结果: 看到结果了么这个运行的结果和我们理解的是不会有差距.对于经验丰富的开发者可能会微微一笑,但是对于一个刚刚学习的人就开始疑惑了.这里主要说两个问题: 1.声明了一个stri ...
- 关于如何学习C语言
2016级计算机专业的C语言分为两个学期,第一学期是C语言(基础),第二学期是C语言(高级),在第一学期主要学习的内容是基本的数据类型,分支结构和循环结构,一维和二维数组,字符数组,函数.通过这学期独 ...
- python 操作PostgreSQL
pip install psycopg Python psycopg2 模块APIs 以下是psycopg2的重要的的模块例程可以满足Python程序与PostgreSQL数据库的工作. S.N. A ...
- css变化代码2
<!DOCTYPE html><html> <head> <meta charset="utf-8" /> ...
- vue class与style 绑定详解——小白速会
一.绑定class的几种方式 1.对象语法 直接看例子: <div id="app3"> <div :class="{'success':isSucce ...
- iis / asp.net 使用 .config 和 .xml 文件的区别
由于在项目中有同学使用后缀为 .xml 的文件作为配置文件,而配置文件中有一些敏感信息被记录,如接口地址,Token,甚至还有数据库连接字符串. 以前都没想过为何微软会使用.config 的后缀在作为 ...
- Sphinx主索引和增量索引来实现索引实时更新的关键步骤
1.配置csft.conf文件 vim /etc/csft.conf # # Minimal Sphinx configuration sample (clean, simple, functiona ...
- 【JavaScript中typeof、toString、instanceof、constructor与in】
JavaScript中typeof.toString.instanceof.constructor与in JavaScript 是一种弱类型或者说动态语言.这意味着你不用提前声明变量的类型,在程序运行 ...
- C# 文件操作类大全
C# 文件操作类大全 时间:2015-01-31 16:04:20 阅读:1724 评论:0 收藏:0 [点我收藏+] 标签: 1.创建文件夹 //usin ...