python爬虫案例:使用XPath爬网页图片
用XPath来做一个简单的爬虫,尝试爬取某个贴吧里的所有帖子,并且将该这个帖子里每个楼层发布的图片下载到本地。
# -*- coding:utf-8 -*- import urllib
import urllib2
from lxml import etree def loadPage(url):
"""
作用:根据url发送请求,获取服务器响应文件
url: 需要爬取的url地址
"""
#print url
#headers = {"User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"} request = urllib2.Request(url)
html = urllib2.urlopen(request).read()
# 解析HTML文档为HTML DOM模型
content = etree.HTML(html)
#print content
# 返回所有匹配成功的列表集合
link_list = content.xpath('//div[@class="t_con cleafix"]/div/div/div/a/@href') #link_list = content.xpath('//a[@class="j_th_tit"]/@href')
for link in link_list:
fulllink = "http://tieba.baidu.com" + link
# 组合为每个帖子的链接
#print link
loadImage(fulllink) # 取出每个帖子里的每个图片连接
def loadImage(link):
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
request = urllib2.Request(link, headers = headers)
html = urllib2.urlopen(request).read()
# 解析
content = etree.HTML(html)
# 取出帖子里每层层主发送的图片连接集合
#link_list = content.xpath('//img[@class="BDE_Image"]/@src')
# link_list = content.xpath('//div[@class="post_bubble_middle"]')
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
# 取出每个图片的连接
for link in link_list:
# print link
writeImage(link) def writeImage(link):
"""
作用:将html内容写入到本地
link:图片连接
"""
#print "正在保存 " + filename
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 文件写入
request = urllib2.Request(link, headers = headers)
# 图片原始数据
image = urllib2.urlopen(request).read()
# 取出连接后10位做为文件名
filename = link[-10:]
# 写入到本地磁盘文件内
with open(filename, "wb") as f:
f.write(image)
print "已经成功下载 "+ filename def tiebaSpider(url, beginPage, endPage):
"""
作用:贴吧爬虫调度器,负责组合处理每个页面的url
url : 贴吧url的前部分
beginPage : 起始页
endPage : 结束页
"""
for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50
#filename = "第" + str(page) + "页.html"
fullurl = url + "&pn=" + str(pn)
#print fullurl
loadPage(fullurl)
#print html print "谢谢使用" if __name__ == "__main__":
kw = raw_input("请输入需要爬取的贴吧名:")
beginPage = int(raw_input("请输入起始页:"))
endPage = int(raw_input("请输入结束页:")) url = "http://tieba.baidu.com/f?"
key = urllib.urlencode({"kw": kw})
fullurl = url + key
tiebaSpider(fullurl, beginPage, endPage)
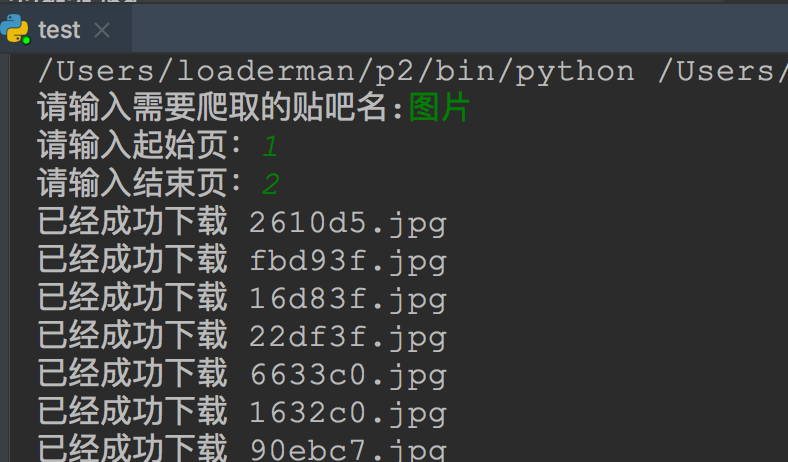
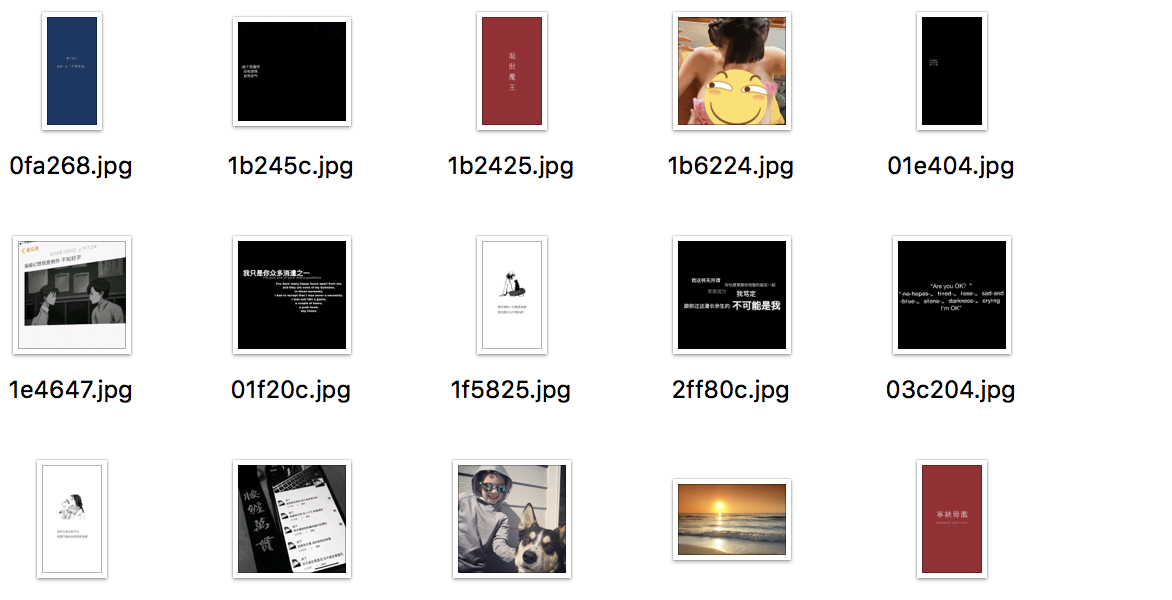
效果:
python爬虫案例:使用XPath爬网页图片的更多相关文章
- Python 爬虫之 Beautifulsoup4,爬网站图片
安装: pip3 install beautifulsoup4 pip install beautifulsoup4 Beautifulsoup4 解析器使用 lxml,原因为,解析速度快,容错能力强 ...
- 【Python爬虫案例学习】下载某图片网站的所有图集
前言 其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. 其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 基本环境配置 python 版本:2.7 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
随机推荐
- SQL LISTAGG 合并行
LISTAGG Syntax 语法 listagg_overflow_clause::= Purpose For a specified measure, LISTAGG orders data w ...
- H3C 802.11网络的基本元素
- H3C WLAN相关组织和标准
- ubifs使用方法
常用命令: 查看块设备分区信息cat /proc/mtd 查看块设备信息mtdinfo /dev/mtd0 格式化mtd分区ubiformat /dev/mtd0 将mtd分区与ubi关联ubiatt ...
- Linux文件系统及管理
Linux文件系统及管理 一.Linux系统的文件系统与目录结构 Linux系统的文件目录结构为一个单根倒置的树结构,具体表现如下图: 从CentOS7开始,以下目录与之前的版本发生变化 ◆/bi ...
- SHA-1算法——(2)
地址:https://www.alvestrand.no/objectid/1.3.14.3.2.26.html 地址:http://oidref.com/1.3.14.3.2.26 这个值好像是个标 ...
- poj1679The Unique MST(次小生成树模板)
次小生成树模板,别忘了判定不存在最小生成树的情况 #include <iostream> #include <cstdio> #include <cstring> ...
- 管理员权限运行-C#程序
C#程序以管理员权限运行 在Vista 和 Windows 7 及更新版本的操作系统,增加了 UAC(用户账户控制) 的安全机制,如果 UAC 被打开,用户即使以管理员权限登录,其应用程序默认情况下也 ...
- ARTS-week3
Algorithm 给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度.不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件 ...
- destoon下动态链接301到伪静态(ngnix)
分享一个destoon6.0/7.0下动态链接301到伪静态上面,实现权重提升. if ($request_uri ~* "^/index.php\?itemid=(\d+)&mod ...