day17_7.19包与logging模块,深浅拷贝
一。包
在模块的定义里,模块就是方法的集合,可以将一些常用的方法封装到一个py文件中,通过调用使用,而且,其中的表现形式也有以包的形式导入。
其实,包就是一系列模块的结合体,表示形式就是一个文件夹,在文件夹中有一个__init__py文件。
init文件就是将包中的方法全部集合 的地方,使用者使用包的时候就是通过运行init文件。
在init文件中可以使用两种方法调用包里的方法:
import p.m1 from p.m1 import f1
当文件启动时:首次导入包:先产生一个执行文件的名称空间
1.创建包下面的__init__.py文件的名称空间
2.执行包下面的__init__.py文件中的代码 将产生的名字放入包下面的__init__.py文件名称空间中
3.在执行文件中拿到一个指向包下面的__init__.py文件名称空间的名字。
而无论是import 还是from import都需要以起始运行文件为参照。
为了更加方便的管理包,作为包的设计者来说
1.当模块的功能特别多的情况下 应该分文件管理
2.每个模块之间为了避免后期模块改名的问题 你可以使用相对导入(包里面的文件都应该是被导入的模块)
我总结了几个使用包的方法:
1.在写包的时候,将所有的模块中的方法都写到init中,在调用包的时候就可以直接调用方法。
2.在调用包的阶段索引包的位置导入包的模块,然后再使用模块中的方法。
而包也有相对路径和绝对路径 之分
站在包的开发者角度来说,如果使用绝对路径来管理的自己的模块 那么它只需要永远以包的路径为基准依次导入模块站。
在包的使用者你必须得将包所在的那个文件夹路径添加到system path中。
在py2和py3中也有对于包不同的地方:
python2如果要导入包 包下面必须要有__init__.py文件
python3如果要导入包 包下面没有__init__.py文件也不会报错
当你在删程序不必要的文件的时候 千万不要随意删除__init__.py文件。
二。logging模块(日志模块)
记录事务的模块
日志分为5个等级,从10-50从轻到重。
logging.debug('debug日志') #
logging.info('info日志') #
logging.warning('warning日志') #
logging.error('error日志') #
logging.critical('critical日志') #
日志的生成
import logging
logging.basicConfig(filename='access.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10,
)
filename是文件名,format是生成日志的格式,datefmt是时间的格式,level设置的是日志错误显示的的等级下线。最后生成一个文件。
如果在终端打印是可以将stream参数变成true,而且不能与filename一起使用。
4个logging对象
1.logger对象:负责产生日志。
2.filter对象:过滤日志
3.handler对象:控制日志输出的位置(文件/终端)
4.formmater对象:规定日志内容的格式。
在handler对象中可以设置日志对象输出的方向:
hd1 = logging.FileHandler('a1.log',encoding='utf-8') # 输出到文件中
hd2 = logging.FileHandler('a2.log',encoding='utf-8') # 输出到文件中
hd3 = logging.StreamHandler() # 输出到终端
可以设置多个对象。
在规定formmater对象中可以规定日志内容的格式。:
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
formmate中用到的格式:
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
同样,也可以设置多个对象。
然后,需要对logger对象进行绑定handler
logger.addHandler(hd1)
logger.addHandler(hd2)
logger.addHandler(hd3)
#将hd1,2,3绑定到logger,规定输出方向
后面再对其格式进行绑定:
hd1.setFormatter(fm1)
hd2.setFormatter(fm2)
hd3.setFormatter(fm1)
#对hd对象绑定格式。
设置日志等级
logger.setLevel(20)
最后记录日志
logger.debug('写了半天 好累啊 好热啊 好想释放')
logger,handler,formmate三者的关系如下:
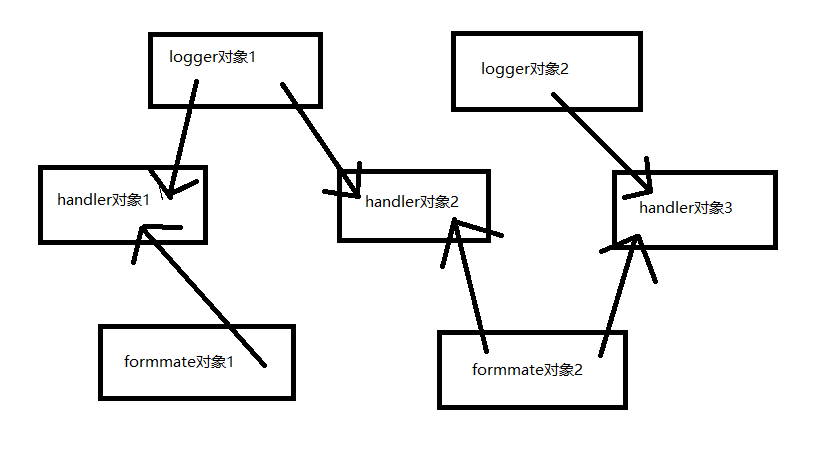
logger可以给多个handler对象,一个formate也可以修饰多个handler,最后由handler对象输出到该输出的位置。
上述过程就是将日志文件生成log的过程,很麻烦,所以可以使用日志字典来处理:
import os
import logging.config # 定义三种日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' # 定义日志输出格式 结束
"""
下面的两个变量对应的值 需要你手动修改
"""
logfile_dir = os.path.dirname(__file__) # log文件的目录
logfile_name = 'a3.log' # log文件名 # 如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir):
os.mkdir(logfile_dir) # log文件的全路径
logfile_path = os.path.join(logfile_dir, logfile_name)
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 默认都会使用该k:v配置
},
} # 使用日志字典配置
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
logger1 = logging.getLogger('asajdjdskaj')
logger1.debug('好好的 不要浮躁 努力就有收获')
在项目的编写中使用logger需要对其路径进行配置,对其getlogger的名字可以随意修改,其返回值也应该是logger1对象,使得用户可以自由返回日志内容。
三。haslib模块
哈希lib模块是一个对文件加密的模块
1.md5算法:
import hashlib
md1=hashlib.md5()
md1.update(b'')
print(md1.hexdigest())
#输出结果>>>a87ff679a2f3e71d9181a67b7542122c
在上述代码中,引入了hashlib模块的md5算法,然后建立一个制造密文的对象,调用该对象使用update进明文加密,注意,update只接受bytes格式的数据。最后输出密文。
hashlib的加密是无法被解密的,因为这个算法是不可逆的,唯一的破解方法就是撞库,
撞库分为脱库和洗库,将各个字符串的哈希值存储到数据库中,在根据哈希值逆推原数据。
只要传入的内容相同,生成的密文一定相同,密文可以分多次传入:
import hashlib
md1=hashlib.md5()
md2=hashlib.md5()
md1.update(b'')
md1.update(b'')
md1.update(b'')
md2.update(b'')
print(md1.hexdigest())
print(md2.hexdigest())
#输出结果>>>550a141f12de6341fba65b0ad0433500
#550a141f12de6341fba65b0ad0433500
不同的算法使用的方法是相同的。
生成的密文越长,算法越复杂,所消耗的时间就越多。
应用场景
1.密码的密文存储
2.检验文件是否相同
加盐:
在加密的时候,可以通过加盐处理对密文进行加工,是密文更加复杂,即使通过撞库获得了原密码,也不会知道真正的密码。
md1=hashlib.md5()
md1.update('我是盐'.encode('utf-8'))
md1.update('我是密码'.encode('utf-8'))
print(md1.hexdigest())
比加盐更复杂的是动态加盐,就是对加的盐进行动态处理。
在实际应用中可以用函数对其封装,解密的时候再次调用函数进行对比。
四。openpyxl模块
openpyxl模块是为了操作excel文件而存在
在03版本之前,excel的后缀名是xls,而03以后的版本是xlsx。
openpyxl只支持03版本以后的,就是操作文件后缀为xlsx的文件。
openpyxl是第三方模块,所以需要在setting里面设置模块下载。
from openpyxl import Workbook
wb = Workbook() # 先生成一个工作簿
wb1 = wb.create_sheet('index',0) # 创建一个表单页 后面可以通过数字控制位置
wb2 = wb.create_sheet('index1')
wb1.title = 'login' # 后期可以通过表单页对象点title修改表单页名称
wb.save('test.xlsx')
首先建立一个工作铺,然后对工作簿进行操作就是对表进行操作。
使用create_sheet的方法建立表中的分表,也可以传入索引指定表所生成的位置。
当分表建立好之后可以使用.title方法对分表的名字进行修改。
最后使用save进行保存,这样就会生成该名字的表。
索引写入值:
wb1['A3'] = 666
wb1['A4'] = 444
wb1.cell(row=6,column=3,value=88888888)
wb1['A5'] = '=sum(A3:A4)'
直接对分表中的单元格进行赋值。赋值也可以写入函数对其他单元格中的数据进行求和等操作。
使用cell方法输入行列和值也可以对单元格进行传值。
wb1.append(['username','age','hobby'])
wb1.append(['jason',18,'study'])
wb1.append(['tank',72,'吃生蚝'])
wb1.append(['egon',84,'女教练'])
wb1.append(['sean',23,'会所'])
wb1.append(['nick',28,])
wb1.append(['nick','','秃头'])
使用append将一个列表加入分表。
读文件:
使用load_workbook对文件进行读操作:
from openpyxl import load_workbook # 读文件
wb = load_workbook('test.xlsx',read_only=True,data_only=True)
print(wb.sheetnames)
其输出的是一个对象,使用sheetname可以返回其终端分表单。
print(wb['login']['A3'].value)
print(wb['login']['A4'].value)
print(wb['login']['A5'].value)
使用这种方法可以取出单元格中的值
如果使用函数data_only将单元格中 的算数数据变成实际数据。需要在表格写完后,认为的改动文件后才能看到真实数据。也就是说存算法变成数据时存储的时算法。
读取表格中的数据,(大面积)
res = wb['login']
# print(res)
ge1 = res.rows
for i in ge1:
for j in i:
print(j.value)
五。深浅拷贝
以列表为例,在列表的拷贝中,有深与浅的区别:
import copy l = [1,2,[1,2]]
l1 = l
print(id(l),id(l1))
l1 = copy.copy(l) # 拷贝一份 ....... 浅拷贝
print(id(l),id(l1))
l[0] = 222
print(l,l1)
l[2].append(666)
print(l,l1)
#输出结果>>>1939403613512 1939403613512
#1939403613512 1939403614792
#[222, 2, [1, 2]] [1, 2, [1, 2]]
#[222, 2, [1, 2, 666]] [1, 2, [1, 2, 666]]
当拷贝完毕后,输出其id发现是一样的,而拷贝后的id是不一样的,当变动其中的不可变类型数据后,浅拷贝后的列表对应元素是不可变的,而变动其可变类型的数据会使得元素改变,原理如图:
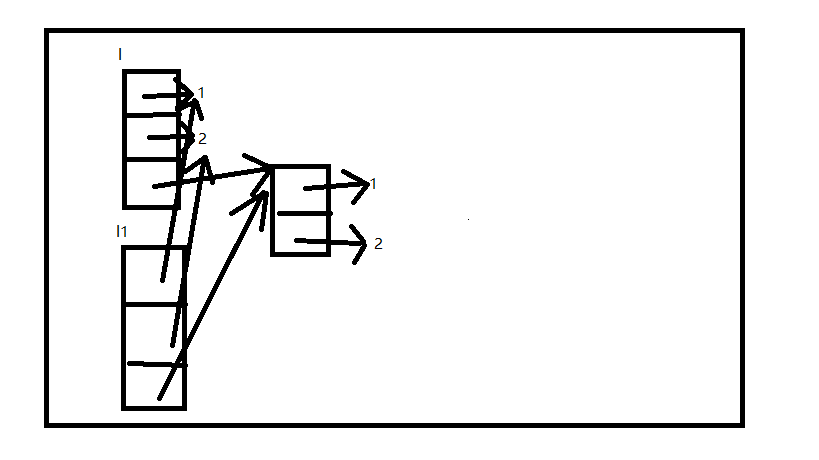
其中的元素都是完全不变的拷贝下来,而深拷贝则是另外创建一个列表
import copy l = [1,2,[1,2]]
l1 = copy.deepcopy(l)
l[2].append(666)
print(l,l1)
#输出结果>>>[1, 2, [1, 2, 666]] [1, 2, [1, 2]]
深拷贝后改变原来的列表中的列表,拷贝后的文件就不会改变了:
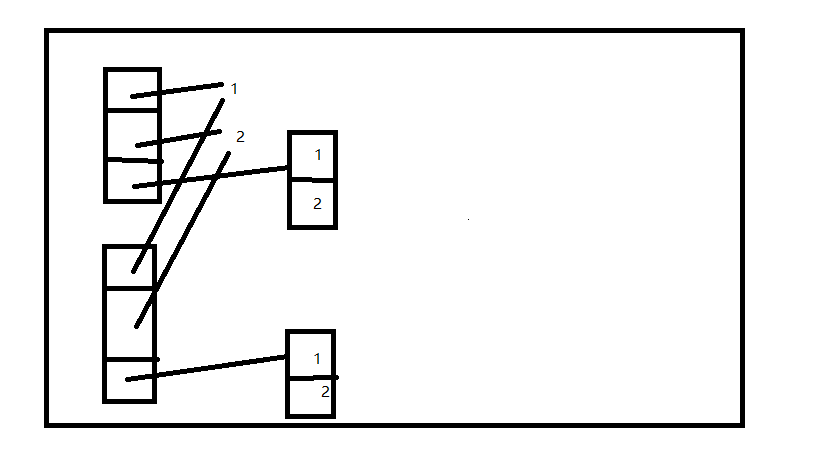
print(wb.sheetnames)
day17_7.19包与logging模块,深浅拷贝的更多相关文章
- 包、logging模块、hashlib模块、openpyxl模块、深浅拷贝
包.logging模块.hashlib模块.openpyxl模块.深浅拷贝 一.包 1.模块与包 模块的三种来源: 1.内置的 2.第三方的 3.自定义的 模块的四种表现形式: 1.py文件 2.共享 ...
- 7.19 包 logging模块 hashlib模块 openpyxl模块 深浅拷贝
包 包是什么 他是一系列文件的结合体,表现形式就是文件夹 包的本质还是模块 他通常会有__init__.py文件 我们首先回顾一下模块导入的过程 import module首次导入模块(.py文件) ...
- 2019-7-19 包、logging模块、hashlib(加密模块)、openpyxl模块、深浅拷贝
一.包 什么是包: 它是一系列模块文件的结合体,表示形式就是一个文件夹.该文件内部通常会有一个__init__.py文件,包的本质还是一个模块,可以被调用,调包就相当于与调用__init__.py文件 ...
- python包-logging-hashlib-openpyxl模块-深浅拷贝-04
包 包: # 包是一系列模块文件的结合体,表现形式是文件夹,该文件夹内部通常会包含一个__init__.py文件,本质上还是一个模块 包呢,就是前两篇博客中提到的,模块的四种表现形式中的第三种 # 把 ...
- python基础之包与logging模块
包 1.什么是包? 包是模块的一种形式,包的本质就是一个含有__init__.py文件的文件夹 2.为什么要有包? 提高程序的结构性和可维护性 3.如何使用包? 导入包就是在导包下的__init__. ...
- python基础--包、logging、hashlib、openpyxl、深浅拷贝
包:它是一系列模块文件的结合体,表现形式就是一个文件夹,该文件夹内部通常会有一个__init__.py文件,包的本质还是一个模块. 首次导入包:(在导入语句中中 . 号的左边肯定是一个包(文件夹)) ...
- 人生苦短之我用Python篇(深浅拷贝、常用模块、内置函数)
深浅拷贝 有时候,尤其是当你在处理可变对象时,你可能想要复制一个对象,然后对其做出一些改变而不希望影响原来的对象.这就是Python的copy所发挥作用的地方. 定义了当对你的类的实例调用copy.c ...
- Python collection模块与深浅拷贝
collection模块是对Python的通用内置容器:字典.列表.元组和集合的扩展,它包含一些专业的容器数据类型: Counter(计数器):dict子类,用于计算可哈希性对象的个数. Ordere ...
- day18包的使用与日志(logging)模块
包的使用与日志(logging)模块1. 什么是包 包就是一个包含有__init__.py文件的文件夹 包本质就是一种模块,即包是用包导入使用的,包内部包含的文件也都是用来被导入使用2 为 ...
随机推荐
- python27期JavaScript:
JavaScript:(简称“JS”) 是一种轻量级的编程语言(ECMAscript5或6)是一种解释性脚本语言(代码不进行预编译)主要用来向HTML页面添加交互行为JavaScript 是互联网上最 ...
- CF798D Mike and distribution
CF798D Mike and distribution 洛谷评测传送门 题目描述 Mike has always been thinking about the harshness of socia ...
- LG1393 动态逆序对
问题描述 LG1393 题解 本题可以使用\(\mathrm{CDQ}\)分治完成. 二维偏序 根据偏序的定义,逆序对是一个二维偏序,但这个二维偏序比较特殊: \(i>j,a_i<a_j\ ...
- 生成git的SSH公钥
1.右键,点击 git bash here 2.安装成功后设置用户和邮箱git config --global user.name "name"git config --glob ...
- 【新特性速递】单元格导航(上下左右键,TAB键和ENTER键)
上下左右按键 其实单元格导航(上下左右按键,需要启用表格的ShowSelectedCell属性)一直都存在,只不过之前的版本(v5.5.0)有一些小的BUG. BUG1 比如锁定列存在时,上下左右键只 ...
- Shell基本运算符之布尔运算符、逻辑运算符
Shell基本运算符 =============================摘自与菜鸟教程=============================== 1.布尔运算符 ! 非运算,表达式为tru ...
- jquery改变表单某个输入框的值时,另一个或几个输入框的值同步变化,这里演示的是改变数量时价格同步变化
效果如下,当我输入数量时,下面的价格同步变化 代码如下: 上图圈起来的事件是当input 框里面的值改变时触发的事件. 补图
- spring的一些概念及优点
Spring是一个轻量级的DI和AOP容器框架.说它轻量级有一大部分原因是相对于EJB的(虽然本人从来没有接触过EJB的应用),但重要的是Spring是非侵入式的,基于Spring开发应用一般不依赖于 ...
- [转载].NET ASP.NET 中web窗体(.aspx)利用ajax实现局部刷新
之前开发的一套系统中用到了大量的 checkboxList 控件,但是每次选定之后都会刷新整个页面,用户体验很差,百度了之后查到这篇文章,尝试了一下可以实现,所以转载了过来,记录一下,也给其他有相同困 ...
- IP 跟踪
#coding=utf-8import sysimport os import re import urllibimport subprocess def getlocation(ip): resul ...