zz——Recent Advances on Object Detection in MSRA
本文由DataFun社区根据微软亚洲研究院视觉组Lead Researcher Jifeng Dai老师在2018 AI先行者大会中分享的《Recent Advances on Object Detection in MSRA》编辑整理而成。
今天分享的内容会从以下几个方面进行,首先是R-FCN and its extensions,然后是Deformable Conv Nets and its extensions,接着是我们在Video object detection方面所做的工作,最后是一个简单的Summary。
一图胜千言,描述生动
详解 R-FCN:
https://zhuanlan.zhihu.com/p/30867916
《R-FCN:Object Detection via Region-based Fully Convolutional Networks》
连接:R-FCN:Object Detection via Region-based Fully Convolutional Networks
这篇论文是NIPS 2016的一篇论文,主要贡献在于解决了“分类网络的位置不敏感性(translation-invariance in image classification)”与“检测网络的位置敏感性(translation-variance in object detection)”之间的矛盾,在提升精度的同时利用“位置敏感得分图(position-sensitive score maps)”提升了检测速度。
基于ResNet-101的R-FCN在PASCAL VOC 2007的测试集上的mAP=83.6%,速度为170ms per image
动机
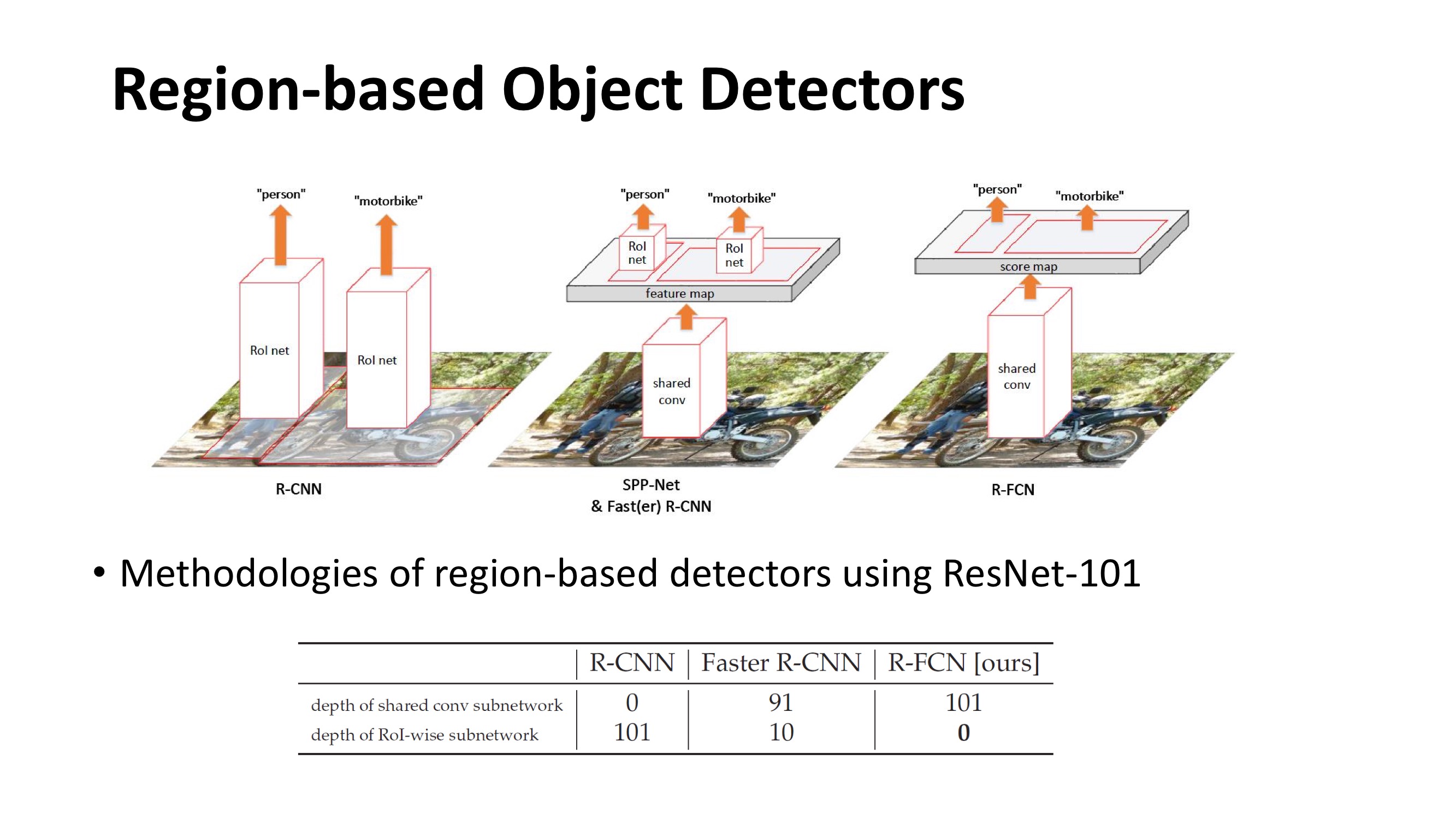
Faster R-CNN是首个利用CNN来完成proposals的预测的,之后的很多目标检测网络都是借助了Faster R-CNN的思想。而Faster R-CNN系列的网络都可以分成2个部分:
- Fully Convolutional subnetwork before RoI Layer
- RoI-wise subnetwork
第1部分就是直接用普通分类网络的卷积层,用其来提取共享特征,然后一个RoI Pooling Layer在第1部分的最后一张特征图上进行提取针对各个RoIs的特征向量(或者说是特征图,维度变换一下即可),然后将所有RoIs的特征向量都交由第2部分来处理(分类和回归),而第二部分一般都是一些全连接层,在最后有2个并行的loss函数:softmax和smoothL1,分别用来对每一个RoI进行分类和回归,这样就可以得到每个RoI的真实类别和较为精确的坐标和长宽了。
这里要注意的,第1部分都是像VGG、GoogleNet、ResNet之类的基础分类网络,这些网络的计算都是所有RoIs共享的,在一张图片测试的时候只需要进行一次前向计算即可。而对于第2部分的RoI-wise subnetwork,它却不是所有RoIs共享的,因为这一部分的作用就是“给每个RoI进行分类和回归”,所以当然不能共享计算。那么现在问题就处在这里,首先第1部分的网络具有“位置不敏感性”,而如果我们将一个分类网络比如ResNet的所有卷积层都放置在第1部分用来提取特征,而第2部分则只剩下全连接层,这样的目标检测网络是“位置不敏感的translation-invariance”,所以其检测精度会较低,并且也白白浪费了分类网络强大的分类能力(does not match the network's superior classification accuracy)。而ResNet论文中为了解决这样的位置不敏感的缺点,做出了一点让步,即将RoI Pooling Layer不再放置在ResNet-101网络的最后一层卷积层之后而是放置在了“卷积层之间”,这样RoI Pooling Layer之前和之后都有卷积层,并且RoI Pooling Layer之后的卷积层不是共享计算的,它们是针对每个RoI进行特征提取的,所以这种网络设计,其RoI Pooling Layer之后就具有了“位置敏感性translation-variance”,但是这样做牺牲了测试速度,因为所有RoIs都要经过若干层卷积计算,测试速度会很慢。
那么到底怎么办?要精度还是要速度?R-FCN的回答是:都要!!!
核心设计思想:把 RoI 切分成 k*k 的子网格;——一个RoI必须是 个子区域都含有该物体的相应部位,才能判断该RoI属于该物体,如果该物体的很多部位都没有出现在相应的子区域中,那么就判断该RoI为背景类别。那么现在的问题就是“网络如何判断一个RoI的
个子区域都含有相应部位呢?”前面我们是假设知道每个子区域是否含有物体的相应部位,那么我们就能判断该RoI是否属于该物体还是属于背景。那么现在的任务就是“判断RoI子区域是否含有物体的相应部位”。
R-FCN会在共享卷积层的最后再接上一层卷积层,而该卷积层就是“位置敏感得分图position-sensitive score map”,该score map是什么意义呢?首先它就是一层卷积层,它的height和width和共享卷积层的一样,但是它的channels=
其它
- Atrous 技巧
作者将最后1个池化层的步长从2减小到1,那么图像将从缩小32倍变成只缩小16倍,这样就提高了共享卷积层的输出分辨率。而这样做就要使用Atrous Convolution算法,具体参见论文Semantic Image Segmentation With Deep Convolutional Nets and Fully Connnected CRFS
- 输入Image的RoI是如何映射到position-sensitive score map上的?
因为RoI的坐标应该相对于原始image的真实坐标,而Position-sensitive RoI pooling的池化操作却是利用RoI在position-sensitive score map上完成的,那么现在就必须有一个映射关系将输入image上的RoI映射到position-sensitive score map上,大致映射见下图(详情可参见原始图片中的ROI如何映射到到feature map?):
论文链接:https://arxiv.org/pdf/1605.06409.pdf
Matlab源码:https://github.com/daijifeng001/r-fcn
R-FCN是微软亚洲研究院的代季峰在2016年提出的一种全新的目标检测结构。它对传统的Faster R-CNN结构进行了改造,将ROI层后的卷积都移到了ROI层前,并利用一种位置敏感的特征图来评估各个类别的概率,使其在保持较高定位准确度的同时,大幅提高检测速率。
网上很容易找到关于R-FCN的各种文章,所以不再重复介绍它的结构,只是选几个容易引起误解的点做深入解读。
理解难点1:平移不变性和平移可变性
作者在论文中提到了两个概念,平移不变性(translation invariance)和平移可变性(translation variance)。平移不变性比较好理解,在用基础的分类结构比如ResNet、Inception给一只猫分类时,无论猫怎么扭曲、平移,最终识别出来的都是猫,输入怎么变形输出都不变这就是平移不变性,网络的层次越深这个特性会越明显。平移可变性则是针对目标检测的,一只猫从图片左侧移到了右侧,检测出的猫的坐标会发生变化就称为平移可变性。当卷积网络变深后最后一层卷积输出的feature map变小,物体在输入上的小偏移,经过N多层pooling后在最后的小feature map上会感知不到,这就是为什么原文会说网络变深平移可变性变差。
再来看个Faster R-CNN + ResNet-101结构的例子。如果在Faster R-CNN中没有ROI层,直接对整个feature map进行分类和位置的回归,由于ResNet的结构较深,平移可变性较差,检测出来的坐标会极度不准确。如果在ResNet中间(图1 conv4与conv5间)加个ROI层结果就不一样了,ROI层提取出的proposal中,有的对应前景label,有的对应背景label,proposal位置的偏移就有可能造成label分类(前景和背景分类)的不同。偏移后原来的前景很有可能变成了背景,原来的背景很有可能变成了前景,换句话说分类loss对proposal的位置是敏感的,这种情况ROI层给深层网络带来了平移可变性。如果把ROI加到ResNet的最后一层(图1 conv5后)结果又是怎样呢?conv5的第一个卷积stride是2,造成conv5输出的feature map更小,这时proposal的一个小偏移在conv5输出上很有可能都感知不到,即proposal对应的label没有改变,所以conv5后虽然有ROI也对平移可变性没有什么帮助,识别出来的位置准确度会很差。
论文中作者给了测试的数据:ROI放在ResNet-101的conv5后,mAP是68.9%;ROI放到conv5前(就是标准的Faster R-CNN结构)的mAP是76.4%,差距是巨大的,这能证明平移可变性对目标检测的重要性。
理解难点2:R-FCN结构的由来
R-FCN要解决的根本问题是Faster R-CNN检测速度慢的问题,速度慢是因为ROI层后的结构对不同的proposal是不共享的,试想下如果有300个proposal,ROI后的全连接网络就要计算300次,这个耗时就太吓人了。所以作者把ROI后的结构往前挪来提升速度,但光是挪动下还不行,ROI在conv5后会引起上节提到的平移可变性问题,必须通过其他方法加强结构的可变性,所以作者就想出了通过添加Position-sensitive score map来达到这个目的。
理解难点3:Position-sensitive score map的结构
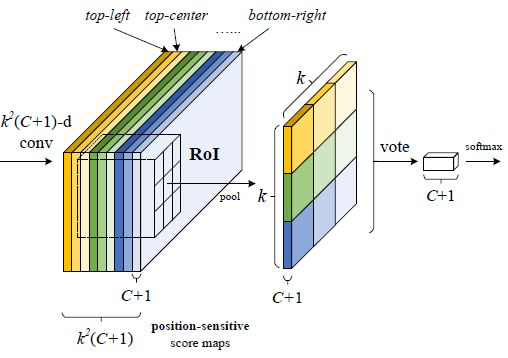
图1的ResNet-101应用到R-FCN时会把最后的average pool和1000-d fc全连接层都去掉了,仅保留前100层,再新加一个1x1x1024的卷积层用来降维(从2048维降到1024维),和一个很特殊的卷积来生成k2* (C+1)维的Position-sensitive score map。其中的C是要分类的类别数,比如PASCAL VOC类别就是20,加上1表示加上一个背景分类;k是之后的ROI Pooling中对ROI区域要划分的小格数,比如论文中k=3就是对ROI在长宽方向各三等分形成9个小区域(如图2)。Position-sensitive score map的值对小区域相对于ROI中的位置很敏感,为什么这么说后面会解释。

图2中最后一个特殊卷积输出Position-sensitive score map后,就要做ROI Pooling了,和Faster R-CNN中的ROI Pooling一样要对9个小区域分别进行pooling,要注意的是R-FCN中9个小区域并不是在所有k2* (C+1)维度上都做pooling,每个小区域只会在对应的(C+1)个维度上作pooling,比如ROI左上角的区域就在前C+1个维度上pooling,左中位置的区域就在C+2到2C+2间的维度上作pooling,以此类推。pooling后输出的是C+1维度的k*k数据,每个维度上的k*k个数据再加到一起(图2的vote过程)形成C+1个单点数据,就代表了C+1个类别的分类概率。
对于目标定位的输出和上面的分类输出过程类似,只是维度不再是k2* (C+1),而是k2*4,表示9个小区域的[dx,dy,dw,dh]4个偏移坐标。
理解难点4:Position-sensitive score map为什么会带来平移可变性
Position-sensitive score map的概念最早来自另一篇实例分割的论文Instance-sensitive Fully Convolutional Networks (https://arxiv.org/pdf/1603.08678.pdf)。图3是示意图,中间的9张图对应Position-sensitive score map的9个维度的输出。拿左上角的图说明:它的每一个点代表该点正好出现在目标左上角的概率(更准确的说应该是得分,因为还没做softmax),也可以理解是该点右下方正好是目标的概率。要注意的是:“目标左上角的概率”的概念并不局限于图中画的绿色框范围,而是整张图上的每一个点,这是新学习者很容易引起误解的地方。同理其余8张图各自对应了目标正上侧、右上侧、左中侧、正中侧、右中侧、左下侧、正下侧、右下侧的概率。在训练时,一个ROI的9个小区域从每张图的对应区域去Pooling出一个结果,组成新的图(图3右侧的9宫格图),如果ROI刚好覆盖ground truth,这个新的区域就标记为前景(label=1)。
这里有个关键点要解释,为什么每张图都能携带相对位置信息?因为从图3提取1~9号小方格时,每个小方格在每张图上的位置并不相同,而是在上下左右方向上有偏移,当组合出来的9宫格对应ground truth时,小方格1就对应了 ground truth左上角的位置,小方格2对应了ground truth正上方的位置,依此类推,所以用这种9宫格训练目标时就有了相对目标位置的信息在里面 。

作者:张磊_0503
链接:https://www.jianshu.com/p/409fd61db9db
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
https://arleyzhang.github.io/tags/object-detection/
1.R-FCN and its extensions
首先介绍下R-FCN,它的highlights是Region-based, fully-convolutional networks for object detection非常快、非常准确。在后续也起到了很多extensions的工作。Region-based Object Detectors在不同方法上的比较,给定一些事先决定好的region processor,put工作在R-CNN里面,是将整个网络挂到每个region的ROI上面,这样会导致很多向量。其后续工作SPP-Net&Faster放到R-CNN里面,将Rol convert部分一个子网络applied到Linux上提取一个feature map,然后在shared feature map上做input,分别对不同区域做ROI inputing产生每个部分特定的特征。我们也会保留一些层FC层、conv层等,通过一个ROI specific网络apply到每个抽取的特定区域上,继续对某个区域进行识别。在R-FCN里所有可以学习的layer都是apply到主栈image上,且是一个Pooling convolution方式,能够直接产生一种share在全图上的一个Score map,这个Score map上只需要用非常少的计算量就可以做一些putting操作拿到ROI得分,然后进行识别和检测。
接下来介绍下为什么之前设计需要把ROI层不自然的插到所有的层之间,这是由于Increasing translation invariance for image classification和Respecting translation variance for object detection联码困境。一方面在feature网络时喜欢translation invariance,如图一群鸟在图中位置不变也可以判断图中是有鸟的类别,所以设计的image convolution尽量让其translation invariance,这样的网络在image classification取得更好地效果。另一方面对于object detection任务需要translation invariance,如图中红色区域框在鸟上可以判断是一只鸟,但是稍微有点translation变化就会出现不是鸟的框;所以把依赖的per-trian网络单独放到object detection任务上需要在每个ROI保留一部分到ROI计算上,这样才能translation invariance feature map上经过多层layer处理达到一个translation invariance效果。
在R-FCN paper里面尝试用连耦方式解决反联码,网络是shared fully convolutional architectures,是以IPN方式,为了使IPN能够产生translation invariance这样一个output。我们利用是Position-sensitive技术,respond for map不止是由C+1个channel来对每个class产生一个output,而是进行一个分广,增加的evention是来encode Position-sensitive信息,不同的key代表的是不同物体的相对位置。通过Position-sensitive ROI pooling方式基于不同的位置选择不同组的C+1维channel组合成一个output。
图中是一个婴儿的图,经过R-FCN产生position-sensitive score maps,如第一组respond在婴儿的左上方,会有一个比较强的响应,第三组会在右下方有个比较强的响应,下面一组是对空间位置有个比较强的响应。在做ROI pooling时采用Position-sensitive策略,将其responds取出做一个计算作为框的score,偏一点的框其overlap就没有那么大,其得分较低。
R-FCN有两个比较关键的性质,第一个就是ROI的计算量变成可以忽略的。在之前的RCN其ROI计算量是不可以忽略的,尤其是处理很大的服务,有很多图片时,就会占整个网络计算量很大的一部分。还有一个优点是整个网络结构是端到端。Fast R-CNN与R-FCN比较,基本能获得一样的正确率,速度在训练时也快很多。
接下来讲一下R-FCN extensions,第一个是我们自己做的,将fully convolutional方式从pure fully convolutional solution 到 instance segmentation。就是要在图像中标出哪些是第一个instance,哪些是第二个instance。好处是非常准确,并没有对feature做working操作,feature在过程中没有丢失任何空间信息,同时速度也是非常快的,region的计算量也是可以忽略。
第二个R-FCN extensions是Light-head R-CNN,第一行是fast R-CNN,计算量会在每个ROI上有很多,需要有很多层对ROI做计算。第二行是R-FCN,当类别数很多时,会产生一个position-sensitive for map,这部分计算量也是很大。其将position-sensitive推广到feature map上,这样的好处就是在类别很多时,无论是在权属的shared fully convolutional或者ROI都很小,速度很快,在很多公司产品中得到应用。还有一个extensions是R-FCN-3000 at 30fps,Decoupled classification and localization for scaling up,基于这个对R-FCN进行改动。
2. Deformable Conv Nets and its extensions
接下来介绍下我们做的第二个技术和所做的改进Deformable Conv Nets,实现了对spatial transformation几何变形进行建模,并不需要额外的supervision。在比较复杂的视觉任务上,实现了Significant accuracy improvements on sophisticated vision tasks。
几何变形建模是在long standing中的一个挑战,可能来源于人的同时态、同尺度,以及同一变化、同一类别,还有视角的变化。这些有很多经典的算法解决这些问题,第一种就是在建训练数据的时候将这些desired variations建立到训练数据中。建设一组transformation都符合一种规律,如仿射变换,确定仿射变换参数,进行information,将其样本放入训练数据中,这种条件是算法足够强大。第二种方式是设计一些变换算法,不是一个黑箱模式给定什么数据都进行处理,而是尝试显示transformation在算法内进行处理和建模。如cale Invariant Feature Transform利用no-label的feature找到正确的变换,还有Deformable Part-based Model尝试对物体状态进行建模。上述两种方法都需要假定变形属于某一特定类别,都是刻画的简单类别,但是实际中几何形变都是很复杂,只能从数据中进行学习。
在CNN时代,先前研究主要集中在如何获得更加强大representation能力,将网络变得更深、更加宽大。但是通常忽略了basic model,都是源于inherently limited to model large unknown transformations。比如我们常见的模块如convolutional模块和regular convolutional模块,我们只是fix apply 3X3的convolutional产生一种新的feature map。将regular convolutional模块处理后,在一些特定的feature map layer看到的信息也是fix的,不会随着comment的变化而变化。还有ROI pooling模块也是一个bread structure,如图左上角对应一个人的手,但是第二幅对应一个人的肩膀,这是有很大差异的,我们直接转化为bread structure上旋。
先前用Spatial Transformer Networks来解决这项工作,是第一篇去学习Spatial Transformation的工作。原理是将feature map用global parametric transformation进行几何变换,还是用fire Transformation,旁边会有一个网络依据input feature map去预测当前图片的几何形态是怎样的。但是complex vision tasks不能很好地工作。
基于这种情况我们提出了Deformable Convolution和Deformable Ro I Pooling两个模块,能够有效的增强CNN对几何形变的建模能力。基本的想法是尝试去学习deform the sampling locations in the convolution/RoI Pooling modules,改变采样的位置,然后deformation offset可以自适应进行调整。跟Transformation network比较,学习到的是local sense和no-parametric transformation,有很大的对information建模的能力。
设计的模块第一个是Deformable Convolution,是在Regular convolution上加了一个二维offset,能够对非常复杂的free form的information进行建模,设计如上图所示。Offset是从其input feature map 上预测出来,做法是加了一层额外的convolution,每一个位置预测其x、y的变化,一共是18为的output。然后将2X9的convolution进行apply到convolution的Corner上指导采样。
相似的设计就是Deformable ROI Pooling,就是在ROI的每个bin里面加了offset。同样也是从input feature map上获取,获取方式是在feature map上给定一个input ROI预测一个2X9的offset,只需要依据很少的参数和计算量就可以对几何形变进行建模。
好处是与regular convolution和regular ROI pooling相比有同样的input和output,因此可以直接将Regular convolution -> deformable convolution, Regular Ro I pooling -> deformable Ro I pooling。同时也不需要额外的supervision,对于产生offset的一路是有梯度,可以回传,并不需要对训练数据进行额外的标注。
当把Deformable convolution运行起来后,对information的建模能力得到进一步的放大。上图中绿点是在deep feature map上的一个点,红点可以将其project back,在三层或四层之前的形态是怎样的,当看的点是在background上,网络自动会将阈值点放的比较大,当绿点在foreground上,可以自适应。通过网络优化给定一个自由度,最后选择一个最好的方案,其他的更依赖于上下文信息。
3. Video object detection
接下来我们做了一系列工作,取得的效果算法Powering the winner of Image Net VID 2017。进一步的发展是基于High Performance做的更快和更好,最新的文章将其推广到Video Object Detection for Mobiles。在计算量很小,在嵌入型设备或者手机上做核心算法,实现更好的工作。
4.Summary
最后总结下General object detection 仍然是一个open unsolved fundamental vision problem,如何对不同的objects有很大的large appearance variations进行识别,在mobile devices上如何识别,以及如何对全景进行识别而不是部分识别,以及对每个像素进行识别都是很有挑战的问题。再者对产品的应用不是那么乐观,如对人和车的识别技术还差很远。
作者介绍:
Jifeng Dai is currently a Lead Researcher in Visual Computing Group at Microsoft Research Asia (MSRA). Before he joined MSRA in 2014, he received the B.S. degree and the Ph.D. degree from Tsinghua University with honor in 2009 and 2014 respectively. He was also a visiting student to University of California, Los Angeles (UCLA) from 2012 to 2013. His current research focus is on deep learning for high-level vision, especially for instance recognition. He is the first author of R-FCN for object detection and Deformable ConvNets. He and his team members has won the 1st place in COCO challenge in 2015 and 2016. He published around 20 papers in top conferences and journals in the field, receiving more than 2000 citations on Google Scholar. He served as a senior program Committee member of AAAI 2018.
zz——Recent Advances on Object Detection in MSRA的更多相关文章
- Image Processing and Computer Vision_Review:A survey of recent advances in visual feature detection(Author's Accepted Manuscript)——2014.08
翻译 一项关于视觉特征检测的最新进展概述(作者已被接受的手稿) 和A survey of recent advances in visual feature detection——2014.08内容相 ...
- 论文阅读笔记四十八:Bounding Box Regression with Uncertainty for Accurate Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1809.08545.pdf github:https://github.com/yihui-he/KL-Loss 摘要 大规模的目标检测数据集在 ...
- object detection[content]
近些年,随着DL的不断兴起,计算机视觉中的对象检测领域也随着CNN的广泛使用而大放异彩,其中Girshick等人的<R-CNN>是第一篇基于CNN进行对象检测的文献.本文欲通过自己的理解来 ...
- 目标检测(一)RCNN--Rich feature hierarchies for accurate object detection and semantic segmentation(v5)
作者:Ross Girshick,Jeff Donahue,Trevor Darrell,Jitendra Malik 该论文提出了一种简单且可扩展的检测算法,在VOC2012数据集上取得的mAP比当 ...
- (转)Awesome Object Detection
Awesome Object Detection 2018-08-10 09:30:40 This blog is copied from: https://github.com/amusi/awes ...
- 关于目标检测 Object detection
NO1.目标检测 (分类+定位) 目标检测(Object Detection)是图像分类的延伸,除了分类任务,还要给定多个检测目标的坐标位置. NO2.目标检测的发展 R-CNN是最早基于C ...
- Viola–Jones object detection framework--Rapid Object Detection using a Boosted Cascade of Simple Features中文翻译 及 matlab实现(见文末链接)
ACCEPTED CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION 2001 Rapid Object Detection using a B ...
- Histograms of Sparse Codes for Object Detection用于目标检测的稀疏码直方图
AbstractObject detection has seen huge progress in recent years, much thanks to the heavily-engineer ...
- tensorfolw配置过程中遇到的一些问题及其解决过程的记录(配置SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving)
今天看到一篇关于检测的论文<SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real- ...
随机推荐
- 【Excel】创建目录
1.=INDEX(GET.WORKBOOK(1),ROW(A1))&T(NOW()) 2. =IFERROR(HYPERLINK(我的目录&"!A1",MID(我的 ...
- Nginx 安装与部署配置
下载 官方网站:https://nginx.org/en/download.html Windows下安装 安装 下载后解压(切记不能含有中文路径!!),文件结构如图(我解压的路径就有中文,记得拷贝放 ...
- C++ TCP客户端网络消息发送接收同步实现
废话不多说, 直入主题, 我们在写客户单的时候希望在哪里发消息出去,然后在哪里返回消息(同步), 然后继续往下运行-, 而不是在这里发送了一个消息给服务端, 在另一个地方接受消息(异步) , 也不知道 ...
- C# HTTP系列 HttpWebRequest 与 HttpWebResponse
HTTP协议,即超文本传输协议(Hypertext transfer protocol).是一种详细规定了浏览器和万维网(WWW = World Wide Web)服务器之间互相通信的规则,通过因特网 ...
- 网Js RSA加密,后端(Asp.Net)解码(非对称加解密)
前言 RSA加解密知识自行百度了解决一下 1.取得公钥与私钥方法 JSEncrypt Download 下载后将其发布成网站进入:http://127.0.0.1:3000/demo/index.ht ...
- D3力布图绘制--基本方法
本文主要结合案例记录使用D3.js绘制力布图的基本方法 样例显示 基本配置 this.force = d3.layout .force() .size([this.width, this.height ...
- mysql float类型详解
mysql float类型详解float类型长度必须设置3以上 不然会报错 out of range如果设置3 就只是 整数+小数的长度 比方说3.23 3.2等等 3.333就不行了 4位了
- HTML+CSS基础 border css属性 Div块 盒子
border css属性 边框颜色 border-color:red/#ffffff/rgb()默认为黑色 边框样式 border-style:solid (实线) dashed (虚线).默认为n ...
- Vue.js 源码分析(二十六) 高级应用 作用域插槽 详解
普通的插槽里面的数据是在父组件里定义的,而作用域插槽里的数据是在子组件定义的. 有时候作用域插槽很有用,比如使用Element-ui表格自定义模板时就用到了作用域插槽,Element-ui定义了每个单 ...
- Restful服务应不应该在URI中加入版本号
程序员们对于Restful服务应不应该在URI中加入版本信息的问题在stackoverflow上进行了积极的讨论: Best practices for API versioning ,该问题被赞了7 ...