k8s 应用优先级,驱逐,波动,动态资源调整
k8s 应用优先级,驱逐,波动,动态资源调整
应用优先级
Requests 和 Limits 的配置除了表明资源情况和限制资源使用之外,还有一个隐藏的作用:它决定了 Pod 的 QoS 等级。
上一节我们提到了一个细节:如果 Pod 没有配置 Limits ,那么它可以使用节点上任意多的可用资源。这类 Pod 能灵活使用资源,但这也导致它不稳定且危险,对于这类 Pod 我们一定要在它占用过多资源导致节点资源紧张时处理掉。优先处理这类 Pod,而不是处理资源使用处于自己请求范围内的 Pod 是非常合理的想法,而这就是 Pod QoS 的含义:根据 Pod 的资源请求把 Pod 分成不同的重要性等级。
Kubernetes 把 Pod 分成了三个 QoS 等级:
- Guaranteed:优先级最高,可以考虑数据库应用或者一些重要的业务应用。除非 Pods 使用超过了它们的 Limits,或者节点的内存压力很大而且没有 QoS 更低的 Pod,否则不会被杀死。
- Burstable:这种类型的 Pod 可以多于自己请求的资源(上限由 Limit 指定,如果 Limit 没有配置,则可以使用主机的任意可用资源),但是重要性认为比较低,可以是一般性的应用或者批处理任务。
- Best Effort:优先级最低,集群不知道 Pod 的资源请求情况,调度不考虑资源,可以运行到任意节点上(从资源角度来说),可以是一些临时性的不重要应用。Pod 可以使用节点上任何可用资源,但在资源不足时也会被优先杀死。
Pod 的 Requests 和 Limits 是如何对应到这三个 QoS 等级上的,用下面一张表格概括:
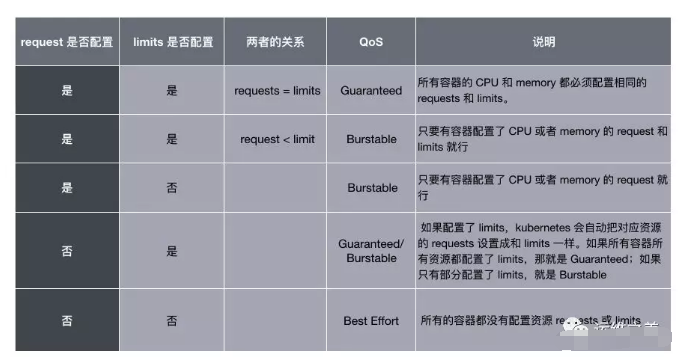
问题:如果不配置 Requests 和 Limits,Pod 的 QoS 竟然是最低的。没错,所以推荐大家理解 QoS 的概念,并且按照需求一定要给 Pod 配置 Requests 和 Limits 参数,不仅可以让调度更准确,也能让系统更加稳定。
Pod 的 QoS 还决定了容器的 OOM(Out-Of-Memory)值,它们对应的关系如下:

QoS 越高的 Pod OOM 值越低,也就越不容易被系统杀死。对于 Bustable Pod,它的值是根据 Request 和节点内存总量共同决定的:
oomScoreAdjust := 1000 - (1000*memoryRequest)/memoryCapacity
其中 memoryRequest 是 Pod 申请的资源,memoryCapacity 是节点的内存总量。可以看到,申请的内存越多,OOM 值越低,也就越不容易被杀死。
Pod 优先级(Priority)
除了 QoS,Kubernetes 还允许我们自定义 Pod 的优先级,比如:
apiVersion: scheduling.k8s.io/v1alpha1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for XYZ service Pods only."
优先级的使用也比较简单,只需要在 Pod.spec.PriorityClassName 指定要使用的优先级名字,即可以设置当前 Pod 的优先级为对应的值。
Pod 的优先级在调度的时候会使用到。首先,待调度的 Pod 都在同一个队列中,启用了 Pod priority 之后,调度器会根据优先级的大小,把优先级高的 Pod 放在前面,提前调度。
如果在调度的时候,发现某个 Pod 因为资源不足无法找到合适的节点,调度器会尝试 Preempt 的逻辑。简单来说,调度器会试图找到这样一个节点:找到它上面优先级低于当前要调度 Pod 的所有 Pod,如果杀死它们,能腾足够的资源,调度器会执行删除操作,把 Pod 调度到节点上。更多内容可以参考:Pod Priority and Preemption - Kubernetes。
讲述的都是理想情况下 Kubernetes 的工作状况,我们假设资源完全够用,而且应用也都是在使用规定范围内的资源。
在管理集群的时候我们常常会遇到资源不足的情况,在这种情况下我们要保证整个集群可用,并且尽可能减少应用的损失。保证集群可用比较容易理解,首先要保证系统层面的核心进程正常,其次要保证 Kubernetes 本身组件进程不出问题;但是如何量化应用的损失呢?首先能想到的是如果要杀死 Pod,要尽量减少总数。另外一个就和 Pod 的优先级相关了,那就是尽量杀死不那么重要的应用,让重要的应用不受影响。
Pod 的驱逐是在 Kubelet 中实现的,因为 Kubelet 能动态地感知到节点上资源使用率实时的变化情况。其核心的逻辑是:Kubelet 实时监控节点上各种资源的使用情况,一旦发现某个不可压缩资源出现要耗尽的情况,就会主动终止节点上的 Pod,让节点能够正常运行。被终止的 Pod 所有容器会停止,状态会被设置为 Failed。
目前主要有三种情况:实际内存不足、节点文件系统的可用空间(文件系统剩余大小和 Inode 数量)不足、以及镜像文件系统的可用空间(包括文件系统剩余大小和 Inode 数量)不足。
下面这图是具体的触发条件:
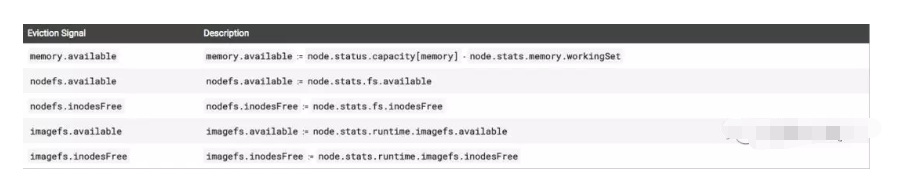
有了数据的来源,另外一个问题是触发的时机,也就是到什么程度需要触发驱逐程序?Kubernetes 运行用户自己配置,并且支持两种模式:按照百分比和按照绝对数量。比如对于一个 32G 内存的节点当可用内存少于 10% 时启动驱逐程序,可以配置 memory.available<10%或者 memory.available<3.2Gi。
NOTE:默认情况下,Kubelet 的驱逐规则是
memory.available<100Mi,对于生产环境这个配置是不可接受的,所以一定要根据实际情况进行修改。
因为驱逐 Pod 是具有毁坏性的行为,因此必须要谨慎。有时候内存使用率增高只是暂时性的,有可能 20s 内就能恢复,这时候启动驱逐程序意义不大,而且可能会导致应用的不稳定,我们要考虑到这种情况应该如何处理;另外需要注意的是,如果内存使用率过高,比如高于 95%(或者 90%,取决于主机内存大小和应用对稳定性的要求),那么我们不应该再多做评估和考虑,而是赶紧启动驱逐程序,因为这种情况再花费时间去判断可能会导致内存继续增长,系统完全崩溃。
为了解决这个问题,Kubernetes 引入了 Soft Eviction 和 Hard Eviction 的概念。
软驱逐可以在资源紧缺情况并没有哪些严重的时候触发,比如内存使用率为 85%,软驱逐还需要配置一个时间指定软驱逐条件持续多久才触发,也就是说 Kubelet 在发现资源使用率达到设定的阈值之后,并不会立即触发驱逐程序,而是继续观察一段时间,如果资源使用率高于阈值的情况持续一定时间,才开始驱逐。并且驱逐 Pod 的时候,会遵循 Grace Period ,等待 Pod 处理完清理逻辑。和软驱逐相关的启动参数是:
--eviction-soft:软驱逐触发条件,比如memory.available<1Gi。--eviction-sfot-grace-period:触发条件持续多久才开始驱逐,比如memory.available=2m30s。--eviction-max-Pod-grace-period:Kill Pod 时等待 Grace Period 的时间让 Pod 做一些清理工作,如果到时间还没有结束就做 Kill。
前面两个参数必须同时配置,软驱逐才能正常工作;后一个参数会和 Pod 本身配置的 Grace Period 比较,选择较小的一个生效。
硬驱逐更加直接干脆,Kubelet 发现节点达到配置的硬驱逐阈值后,立即开始驱逐程序,并且不会遵循 Grace Period,也就是说立即强制杀死 Pod。对应的配置参数只有一个 --evictio-hard,可以选择上面表格中的任意条件搭配。
设置这两种驱逐程序是为了平衡节点稳定性和对 Pod 的影响,软驱逐照顾到了 Pod 的优雅退出,减少驱逐对 Pod 的影响;而硬驱逐则照顾到节点的稳定性,防止资源的快速消耗导致节点不可用。
软驱逐和硬驱逐可以单独配置,不过还是推荐两者都进行配置,一起使用。
上面已经整体介绍了 Kubelet 驱逐 Pod 的逻辑和过程。牵涉到一个具体的问题:要驱逐哪些 Pod?驱逐的重要原则是尽量减少对应用程序的影响。
如果是存储资源不足,Kubelet 会根据情况清理状态为 Dead 的 Pod 和它的所有容器,以及清理所有没有使用的镜像。如果上述清理并没有让节点回归正常,Kubelet 就开始清理 Pod。
一个节点上会运行多个 Pod,驱逐所有的 Pods 显然是不必要的,因此要做出一个抉择:在节点上运行的所有 Pod 中选择一部分来驱逐。虽然这些 Pod 乍看起来没有区别,但是它们的地位是不一样的,
系统组件的 Pod 要比普通的 Pod 更重要,另外运行数据库的 Pod 自然要比运行一个无状态应用的 Pod 更重要。Kubernetes 又是怎么决定 Pod 的优先级的呢?这个问题的答案就藏在我们之前已经介绍过的内容里:Pod Requests 和 Limits、优先级(Priority),以及 Pod 实际的资源使用。
简单来说,Kubelet 会根据以下内容对 Pod 进行排序:Pod 是否使用了超过请求的紧张资源、Pod 的优先级、然后是使用的紧缺资源和请求的紧张资源之间的比例。具体来说,Kubelet 会按照如下的顺序驱逐 Pod:
- 使用的紧张资源超过请求数量的
BestEffort和BurstablePod,这些 Pod 内部又会按照优先级和使用比例进行排序。 - 紧张资源使用量低于 Requests 的
Burstable和Guaranteed的 Pod 后面才会驱逐,只有当系统组件(Kubelet、Docker、Journald 等)内存不够,并且没有上面 QoS 比较低的 Pod 时才会做。执行的时候还会根据 Priority 排序,优先选择优先级低的 Pod。
波动有两种情况,第一种。驱逐条件出发后,如果 Kubelet 驱逐一部分 Pod,让资源使用率低于阈值就停止,那么很可能过一段时间资源使用率又会达到阈值,从而再次出发驱逐,如此循环往复……为了处理这种问题,我们可以使用 --eviction-minimum-reclaim解决,这个参数配置每次驱逐至少清理出来多少资源才会停止。
另外一个波动情况是这样的:Pod 被驱逐之后并不会从此消失不见,常见的情况是 Kubernetes 会自动生成一个新的 Pod 来取代,并经过调度选择一个节点继续运行。如果不做额外处理,有理由相信 Pod 选择原来节点的可能性比较大(因为调度逻辑没变,而它上次调度选择的就是该节点),之所以说可能而不是绝对会再次选择该节点,是因为集群 Pod 的运行和分布和上次调度时极有可能发生了变化。
无论如何,如果被驱逐的 Pod 再次调度到原来的节点,很可能会再次触发驱逐程序,然后 Pod 再次被调度到当前节点,循环往复…… 这种事情当然是我们不愿意看到的,虽然看似复杂,但这个问题解决起来非常简单:驱逐发生后,Kubelet 更新节点状态,调度器感知到这一情况,暂时不往该节点调度 Pod 即可。--eviction-pressure-transition-period 参数可以指定 Kubelet 多久才上报节点的状态,因为默认的上报状态周期比较短,频繁更改节点状态会导致驱逐波动。
使用了上面多种参数的驱逐配置实例:
–eviction-soft=memory.available<80%,nodefs.available<2Gi \
–eviction-soft-grace-period=memory.available=1m30s,nodefs.available=1m30s \
–eviction-max-Pod-grace-period=120 \
–eviction-hard=memory.available<500Mi,nodefs.available<1Gi \
–eviction-pressure-transition-period=30s \
--eviction-minimum-reclaim="memory.available=0Mi,nodefs.available=500Mi,imagefs.available=2Gi"
Kubernetes 的调度器在为 Pod 选择运行节点的时候,只会考虑到调度那个时间点集群的状态,经过一系列的算法选择一个当时最合适的节点。但是集群的状态是不断变化的,用户创建的 Pod 也是动态的,随着时间变化,原来调度到某个节点上的 Pod 现在看来可能有更好的节点可以选择。比如考虑到下面这些情况:
- 调度 Pod 的条件已经不再满足,比如节点的 Taints 和 Labels 发生了变化。
- 新节点加入了集群。如果默认配置了把 Pod 打散,那么应该有一些 Pod 最好运行在新节点上。
- 节点的使用率不均匀。调度后,有些节点的分配率和使用率比较高,另外一些比较低。
- 节点上有资源碎片。有些节点调度之后还剩余部分资源,但是又低于任何 Pod 的请求资源;或者 Memory 资源已经用完,但是 CPU 还有挺多没有使用。
想要解决上述的这些问题,都需要把 Pod 重新进行调度(把 Pod 从当前节点移动到另外一个节点)。但是默认情况下,一旦 Pod 被调度到节点上,除非给杀死否则不会移动到另外一个节点的。
Kubernetes 社区孵化了一个称为 Descheduler 的项目,专门用来做重调度。重调度的逻辑很简单:找到上面几种情况中已经不是最优的 Pod,把它们驱逐掉(Eviction)。
Descheduler 不会决定驱逐的 Pod 应该调度到哪台机器,而是假定默认的调度器会做出正确的调度抉择。也就是说,之所以 Pod 目前不合适,不是因为调度器的算法有问题,而是因为集群的情况发生了变化。如果让调度器重新选择,调度器现在会把 Pod 放到合适的节点上。这种做法让 Descheduler 逻辑比较简单,而且避免了调度逻辑出现在两个组件中。
Descheduler 执行的逻辑是可以配置的,目前有几种场景:
RemoveDuplicates:RS、Deployment 中的 Pod 不能同时出现在一台机器上。LowNodeUtilization:找到资源使用率比较低的 Node,然后驱逐其他资源使用率比较高节点上的 Pod,期望调度器能够重新调度让资源更均衡。RemovePodsViolatingInterPodAntiAffinity:找到已经违反 Pod Anti Affinity 规则的 Pods 进行驱逐,可能是因为反亲和是后面加上去的。RemovePodsViolatingNodeAffinity:找到违反 Node Affinity 规则的 Pods 进行驱逐,可能是因为 Node 后面修改了 Label。
当然,为了保证应用的稳定性,Descheduler 并不会随意地驱逐 Pod,还是会尊重 Pod 运行的规则,包括 Pod 的优先级(不会驱逐 Critical Pod,并且按照优先级顺序进行驱逐)和 PDB(如果违反了 PDB,则不会进行驱逐),并且不会驱逐没有 Deployment、RS、Jobs 的 Pod 不会驱逐,Daemonset Pod 不会驱逐,有 Local storage 的 Pod 也不会驱逐。
Descheduler 不是一个常驻的任务,每次执行完之后会退出,因此推荐使用 CronJob 来运行。
总的来说,Descheduler 是对原生调度器的补充,用来解决原生调度器的调度决策随着时间会变得失效,或者不够优化的缺陷。
动态调整的思路:应用的实际流量会不断变化,因此使用率也是不断变化的,为了应对应用流量的变化,我们应用能够自动调整应用的资源。比如在线商品应用在促销的时候访问量会增加,我们应该自动增加 Pod 运算能力来应对;当促销结束后,有需要自动降低 Pod 的运算能力防止浪费。
运算能力的增减有两种方式:改变单个 Pod 的资源,以及增减 Pod 的数量。这两种方式对应了 Kubernetes 的 HPA 和 VPA。
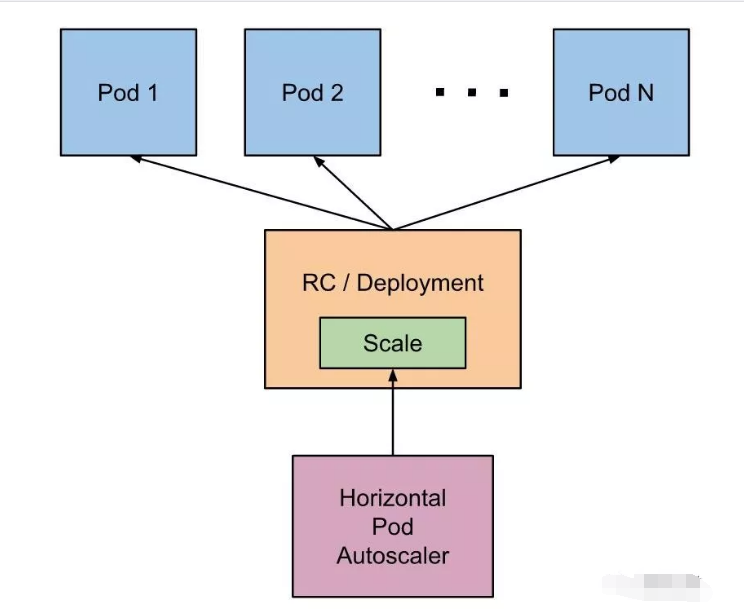
横向 Pod 自动扩展的思路是这样的:Kubernetes 会运行一个 Controller,周期性地监听 Pod 的资源使用情况,当高于设定的阈值时,会自动增加 Pod 的数量;当低于某个阈值时,会自动减少 Pod 的数量。自然,这里的阈值以及 Pod 的上限和下限的数量都是需要用户配置的。
一个重要的信息:HPA 只能和 RC、Deployment、RS 这些可以动态修改 Replicas 的对象一起使用,而无法用于单个 Pod、Daemonset(因为它控制的 Pod 数量不能随便修改)等对象。
目前官方的监控数据来源是 Metrics Server 项目,可以配置的资源只有 CPU,但是用户可以使用自定义的监控数据(比如:Prometheus)。其他资源(比如:Memory)的 HPA 支持也已经在路上了。
和 HPA 的思路相似,只不过 VPA 调整的是单个 Pod 的 Request 值(包括 CPU 和 Memory)。VPA 包括三个组件:
- Recommander:消费 Metrics Server 或者其他监控组件的数据,然后计算 Pod 的资源推荐值。
- Updater:找到被 VPA 接管的 Pod 中和计算出来的推荐值差距过大的,对其做 Update 操作(目前是 Evict,新建的 Pod 在下面 Admission Controller 中会使用推荐的资源值作为 Request)。
- Admission Controller:新建的 Pod 会经过该 Admission Controller,如果 Pod 是被 VPA 接管的,会使用 Recommander 计算出来的推荐值。
可以看到,这三个组件的功能是互相补充的,共同实现了动态修改 Pod 请求资源的功能。相对于 HPA,目前 VPA 还处于 Alpha,并且还没有合并到官方的 Kubernetes Release 中,后续的接口和功能很可能会发生变化。
随着业务的发展,应用会逐渐增多,每个应用使用的资源也会增加,总会出现集群资源不足的情况。为了动态地应对这一状况,我们还需要 CLuster Auto Scaler,能够根据整个集群的资源使用情况来增减节点。
对于公有云来说,Cluster Auto Scaler 就是监控这个集群因为资源不足而 Pending 的 Pod,根据用户配置的阈值调用公有云的接口来申请创建机器或者销毁机器。对于私有云,则需要对接内部的管理平台。
目前 HPA 和 VPA 不兼容,只能选择一个使用,否则两者会相互干扰。而且 VPA 的调整需要重启 Pod,这是因为 Pod 资源的修改是比较大的变化,需要重新走一下 Apiserver、调度的流程,保证整个系统没有问题。目前社区也有计划在做原地升级,也就是说不通过杀死 Pod 再调度新 Pod 的方式,而是直接修改原有 Pod 来更新。
理论上 HPA 和 VPA 是可以共同工作的,HPA 负责瓶颈资源,VPA 负责其他资源。比如对于 CPU 密集型的应用,使用 HPA 监听 CPU 使用率来调整 Pods 个数,然后用 VPA 监听其他资源(Memory、IO)来动态扩展这些资源的 Request 大小即可。当然这只是理想情况,
集群的资源使用并不是静态的,而是随着时间不断变化的,目前 Kubernetes 的调度决策都是基于调度时集群的一个静态资源切片进行的,动态地资源调整是通过 Kubelet 的驱逐程序进行的,HPA 和 VPA 等方案也不断提出,相信后面会不断完善这方面的功能,让 Kubernetes 更加智能。
资源管理和调度、应用优先级、监控、镜像中心等很多东西相关,是个非常复杂的领域。在具体的实施和操作的过程中,常常要考虑到企业内部的具体情况和需求,做出针对性的调整,并且需要开发者、系统管理员、SRE、监控团队等不同小组一起合作。但是这种付出从整体来看是值得的,提升资源的利用率能有效地节约企业的成本,也能让应用更好地发挥出作用。
k8s 应用优先级,驱逐,波动,动态资源调整的更多相关文章
- spark动态资源(executor)分配
spark动态资源调整其实也就是说的executor数目支持动态增减,动态增减是根据spark应用的实际负载情况来决定. 开启动态资源调整需要(on yarn情况下) 1.将spark.dynamic ...
- nginx+tomcat集群配置(2)---静态和动态资源的分离
前言: 在web性能优化的领域, 经常能听到一个词, 就是静态/动态资源分离. 那静态/动态资源分离究竟是什么呢? 本文不讲文件系统服务, 云存储, 也不讲基于CDN的优化. 就简单讲讲基于nginx ...
- KVM虚拟机管理——资源调整
1. 概述2. 计算资源调整2.1 调整处理器配置2.2 调整内存配置3. 存储资源调整3.1 根分区扩展3.2 添加磁盘4. 网络资源调整 1. 概述 KVM在使用过程中,会涉及到计算(CPU,内存 ...
- 静态资源(StaticResource)和动态资源(DynamicResource)
静态资源(StaticResource)和动态资源(DynamicResource) 资源可以作为静态资源或动态资源进行引用.这是通过使用 StaticResource 标记扩展或 DynamicRe ...
- Dynamic Resource – 动态资源
Dynamic Resource – 动态资源 与Static Resource不同的是,Dynamic Resource可以在程序运行时重新评估/计算资源来生成对应的对象/值,它支持向前引用,只 ...
- servlet基本原理(手动创建动态资源+工具开发动态资源)
一.手动开发动态资源 1 静态资源和动态资源的区别 静态资源: 当用户多次访问这个资源,资源的源代码永远不会改变的资源. 动态资源:当用户多次访问这个资源,资源的源代码可能会发送改变. <scr ...
- zzy:请求静态资源和请求动态资源, src再次请求服务器资源
[总结可以发起请求的阶段:请求动态资源:通过web.xml匹配action然后,自定义Servlet处理该action1)form表单提交请求的时候,用action设定,该页面发起请求的Servlet ...
- Liferay 6.2 改造系列之十一:默认关闭CDN动态资源
在行业客户中,一般无法提供CDN服务,因此默认关闭CDN动态资源功能: 在/portal-master/portal-impl/src/portal.properties文件中,有如下配置: # # ...
- WPFの静态资源(StaticResource)和动态资源(DynamicResource)
下面是前台代码: <Window.Resources> <TextBlock x:Key="res1" Text="好好学习"/ ...
随机推荐
- TypeScript 菜鸟教程
非常好的Js教程,web api,canvas API教程 https://wangdoc.com/ 语法基础 https://www.runoob.com/typescript/ts-install ...
- Photoshop如何自定义形状
Photoshop如何自定义形状,自定义形状定义一次,可以随便使用,而且形状无大小,填充后不会有像素问题,普通人可把常用的自定义成形状,很方便.PS中有一些自定义的形状,自己可以随便使用,但是不是很全 ...
- python实践项目九:操作文件-修改文件名
描述:多个文件,文件名名包含美国风格的日期( MM-DD-YYYY),需要将它们改名为欧洲风格的日期( DD-MM-YYYY) 代码1:先创建100个文件名为美国风格日期的文件(文件路径为项目当前路径 ...
- Linux下安装pj Navicat121 x64版本
一,先在官网下载https://www.navicat.com.cn/download/navicat-premium Linux 64位版本(说是Linux,其实就是Windows+Wine版本)[ ...
- 嵌入式qt显示中文和隐藏鼠标
最近项目快接近尾声了,要把项目移植到板子上,但是板子上的系统没有安装字库,导致中文无法显示,并且有一个很讨厌的鼠标光标(又没有鼠标),上网找了一些解决方案,记录一下 qt显示中文: 如果你急于在ARM ...
- redhat7.6Linux安装Oracle19C完整版教程
首先安装配置虚拟机,见博客https://www.cnblogs.com/xuzhaoyang/p/11264563.html 然后配置IP地址,见博客https://www.cnblogs.com/ ...
- max_prepared_stmt_count参数
MySQL报错[mysqld-5.5.17-log]Can't create more than max_prepared_stmt_count statements (current value: ...
- 计数器的Verilog写法
计数器是非常基本的使用,没有计数器就无法处理时序.我在学习时发现市面上有几种不同的计数器写法,非常有趣,在此记录下来: 一.时序逻辑和组合逻辑彻底分开(by锆石科技FPGA教程) 1.代码 //=== ...
- 使用Git管理版本
原文地址:廖雪峰的网站 Git 是目前世界上最先进的分布式版本控制系统 Git 的历史 集中式 vs 分布式 集中式的版本库是集中存放在中央服务器的.缺点是必须联网.网速慢的情况就会让人抓狂. 分布式 ...
- Relative Sort Array
Relative Sort Array Given two arrays arr1 and arr2, the elements of arr2 are distinct, and all eleme ...