Kubernetes 监控
1. Weave Scope
Weave Scope 容器地图
创建 Kubernetes 集群并部署容器化应用只是第一步。一旦集群运行起来,我们需要确保一起正常,所有必要组件就位并各司其职,有足够的资源满足应用的需求。Kubernetes 是一个复杂系统,运维团队需要有一套工具帮助他们获知集群的实时状态,并为故障排查提供及时和准确的数据支持。
Weave Scope 是 Docker 和 Kubernetes 可视化监控工具。Scope 提供了至上而下的集群基础设施和应用的完整视图,用户可以轻松对分布式的容器化应用进行实时监控和问题诊断。
Weave Scope 的最大特点是会自动生成一张 Docker 容器地图,让我们能够直观地理解、监控和控制容器。
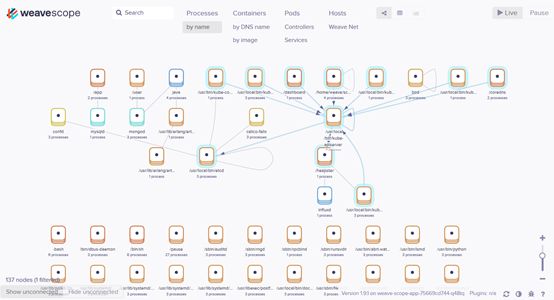
Weave Scope部署
安装 Scope 的方法很简单,执行如下命令:
kubectl apply -f scope.yaml
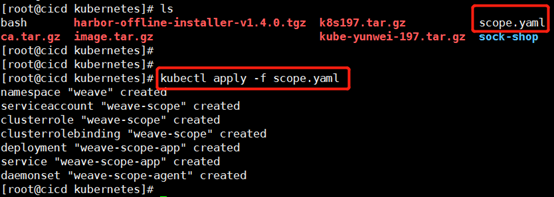
部署成功后,有如下相关组件:
1) DaemonSet weave-scope-agent,集群每个节点上都会运行的 scope agent 程序,负责收集数据。
2) Deployment weave-scope-app,scope 应用,从 agent 获取数据,通过 Web UI 展示并与用户交互。
3) Service weave-scope-app,默认是 ClusterIP 类型,为了方便已通过 kubectl edit 修改为 NodePort。
使用weavescope
登陆weavescope
浏览器访问 http://ip:28125/,Scope 默认显示当前所有的Controller(Deployment、DaemonSet 等)。
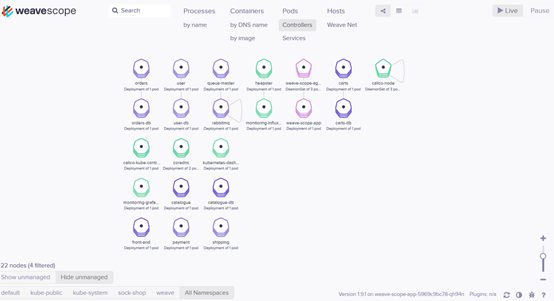
拓扑结构
Scope 会自动构建应用和集群的逻辑拓扑。比如点击顶部 PODS,会显示所有 Pod 以及 Pod 之间的依赖关系。

点击 HOSTS,会显示各个节点之间的关系。

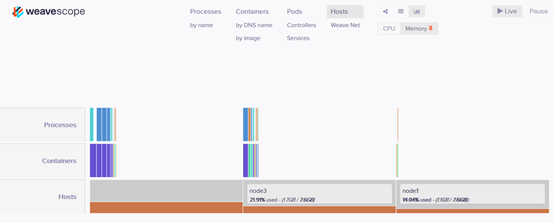
实时资源监控
可以在 Scope 中查看资源的 CPU 和内存使用情况。

支持图,表,柱状图显示

在线操作
Scope 还提供了便捷的在线操作功能,比如选中某个 Host,点击 >_ 按钮可以直接在浏览器中打开节点的命令行终端:
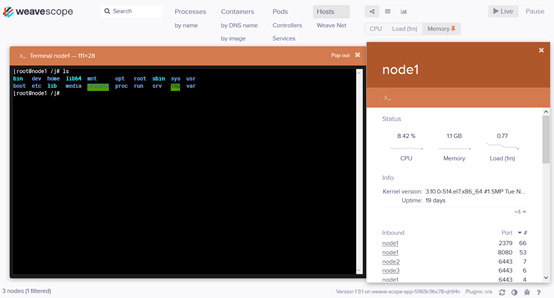
点击 Deployment 的 + 可以执行 Scale Up 操作:

可以 attach、restart、stop 容器,以及直接在 Scope 中排查问题:
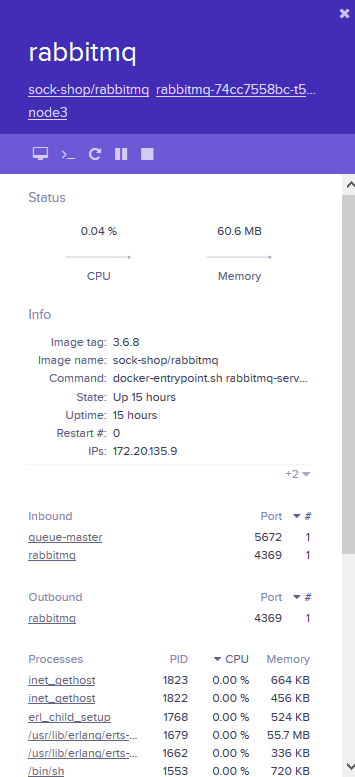
详细信息包括这么几部分:
Status:CPU、内存的实时使用情况以及历史曲线。
INFO:容器 image、启动命令、状态、网络等信息。
以下几项需拉动滚动条查看。

PROCESSES:容器中运行的进程。
ENVIRONMENT VARIABLES:环境变量。
DOCKER LABELS:容器启动命令。
IMAGE:镜像详细信息。
在容器信息的上面还有一排操作按钮。

attach 到容器启动进程,相当于执行 docker container attach
打开shell,相当于执行docker container exec
重启容器,相当于执行 docker container restart
暂停容器,相当于执行 docker container pause
关闭容器,相当于执行 docker container stop
强大的搜索功能
Scope 支持关键字搜索和定位资源。
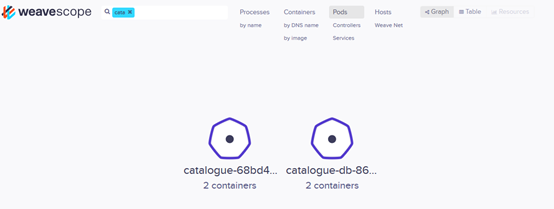
还可以进行条件搜索,比如查找和定位 cpu > 1% 的 Containers 。

Weave Scope 界面极其友好,操作简洁流畅,更多功能留给大家去探索。

2. 用 Heapster 监控集群
Heapster介绍
Heapster 是 Kubernetes 原生的集群监控方案。Heapster 以 Pod 的形式运行,它会自动发现集群节点、从节点上的 Kubelet 获取监控数据。Kubelet 则是从节点上的 cAdvisor 收集数据。
Heapster 将数据按照 Pod 进行分组,将它们存储到预先配置的 backend 并进行可视化展示。Heapster 当前支持的 backend 有 InfluxDB(通过 Grafana 展示),Google Cloud Monitoring 等。Heapster 的整体架构如下图所示:

Heapster 本身是一个 Kubernetes 应用,部署方法很简单,之前章节中我们实践了由 Heapster、InfluxDB 和 Grafana 组成的监控方案。Kubelet 和 cAdvisor 是 Kubernetes 的自带组件,无需额外部署。
Kubernetes 监控的更多相关文章
- Kubernetes监控:部署Heapster、InfluxDB和Grafana
本节内容: Kubernetes 监控方案 Heapster.InfluxDB和Grafana介绍 安装配置Heapster.InfluxDB和Grafana 访问 grafana 访问 influx ...
- 【译】Kubernetes监控实践(2):可行监控方案之Prometheus和Sensu
本文介绍两个可行的K8s监控方案:Prometheus和Sensu.两个方案都能全面提供系统级的监控数据,帮助开发人员跟踪K8s关键组件的性能.定位故障.接收预警. 拓展阅读:Kubernetes监控 ...
- Kubernetes 监控方案之 Prometheus Operator(十九)
目录 一.Prometheus 介绍 1.1.Prometheus 架构 1.2.Prometheus Operator 架构 二.Helm 安装部署 2.1.Helm 客户端安装 2.2.Tille ...
- 云原生应用 Kubernetes 监控与弹性实践
前言 云原生应用的设计理念已经被越来越多的开发者接受与认可,而Kubernetes做为云原生的标准接口实现,已经成为了整个stack的中心,云服务的能力可以通过Cloud Provider.CRD C ...
- 通过Kubernetes监控探索应用架构,发现预期外的流量
大家好,我是阿里云云原生应用平台的炎寻,很高兴能和大家一起在 Kubernetes 监控系列公开课上进行交流.本次公开课期望能够给大家在 Kubernetes 容器化环境中快速发现和定位问题带来新的解 ...
- 介绍Kubernetes监控Heapster
什么是Heapster? Heapster是容器集群监控和性能分析工具,天然的支持Kubernetes和CoreOS,Kubernetes有个出名的监控agent—cAdvisor.在每个kubern ...
- kubernetes监控--Prometheus
本文基于kubernetes 1.5.2版本编写 kube-state-metrics kubectl create ns monitoring kubectl create sa -n monito ...
- kubernetes监控-prometheus(十六)
监控方案 cAdvisor+Heapster+InfluxDB+Grafana Y 简单 容器监控 cAdvisor/exporter+Prometheus+Grafana Y 扩展性好 容器,应用, ...
- kubernetes监控-Heapster+InfluxDB+Grafana(十五)
cAdvisor+InfluxDB+Grafana cAdvisor:是谷歌开源的一个容器监控工具,采集主机上容器相关的性能指标数据.比如CPU.内存.网络.文件系统等. Heapster是谷歌开源的 ...
- Kubernetes监控实践
一.Kubernetes介绍 Kubernetes(K8s)是一个开源平台,能够有效简化应用管理.应用部署和应用扩展环节的手动操作流程,让用户更加灵活地部署管理云端应用. 作为可扩展的容错平台,K8s ...
随机推荐
- Android Studio 之 Navigation【2.数据的传递】
Android Studio 之 Navigation[2.数据的传递和过渡动画] 在资源navigation资源的xml文件中,在[目标界面] detialFragment中点击,在右边 Argum ...
- 如何保证redis数据都是热点数据
mySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据? 1.限定 Redis 占用的内存,Redis 会根据自身数据淘汰策略,加载热数据到内存.所以,计算 ...
- “/usr/local/lib/libosipparser2.so.7: could not read symbols: Invalid operation” 异常解决
编译c代码报错如下 /usr/bin/ld: /tmp/ccl8nBND.o: undefined reference to symbol 'osip_message_get_body' /usr/b ...
- Java通过poi创建Excel文件并分页追加数据
以下的main函数,先生成一个excel文件,并设置sheet的名称,设置excel头:而后,以分页的方式,向文件中追加数据 maven依赖 <dependency> <groupI ...
- centos7.2上安装CDH5.16.2及Spark2【原创】
背景:我自己的电脑配置太低,想在centos操作系统上安装CDH5.1.2并配置集群,我去阿里云上买了3台按流量计费的阿里云服务器. 大家一定要注意,配置,购买的阿里云服务器不要太低了.建议:3台2核 ...
- 《Linux就该这么学》培训笔记_ch12_使用Samba或NFS实现文件共享
<Linux就该这么学>培训笔记_ch12_使用Samba或NFS实现文件共享 文章最后会post上书本的笔记照片. 文章主要内容: SAMBA文件共享服务 配置共享资源 Windows挂 ...
- Zookeeper connection loss leads to Flink job restart
Flink可以使用zookeeper来进行ha,而一般我们都会使用zookeeper的高级api架构curator来对zk进行通讯.在curator中引入了状态的概念,包括connected,reco ...
- 【LeetCode】缺失的第一个正数【原地HashMap】
给定一个未排序的整数数组,找出其中没有出现的最小的正整数. 示例 1: 输入: [1,2,0] 输出: 3 示例 2: 输入: [3,4,-1,1] 输出: 2 示例 3: 输入: [7,8,9,11 ...
- elasticsearch迁移数据到新索引中
因为业务原因,需要修改索引的映射的某个字段的类型,比如更改Text为Keyword. 需要如下步骤: 1).先新建索引,映射最新的映射实体 2).迁移老索引的数据到新索引中(数据较大的话,可以分批迁移 ...
- 第十五节:Asp.Net Core中的各种过滤器(授权、资源、操作、结果、异常)
一. 简介 1. 说明 提到过滤器,通常是指请求处理管道中特定阶段之前或之后的代码,可以处理:授权.响应缓存(对请求管道进行短路,以便返回缓存的响应). 防盗链.本地化国际化等,过滤器用于横向处理业务 ...