Scrapy爬虫案例 | 数据存储至MySQL
首先,MySQL创建好数据库和表
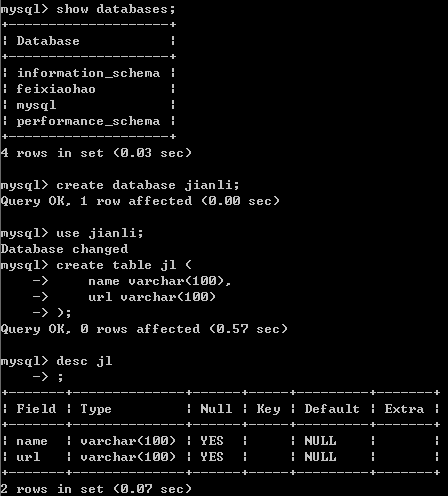
然后编写各个模块
item.py
import scrapy class JianliItem(scrapy.Item):
name = scrapy.Field()
url = scrapy.Field()
pipeline.py
import pymysql #导入数据库的类 class JianliPipeline(object):
conn = None
cursor = None def open_spider(self,spider):
print('开始爬虫')
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='',db='jianli') #链接数据库 def process_item(self, item, spider): #编写向数据库中存储数据的相关代码
self.cursor = self.conn.cursor() #1.链接数据库
sql = 'insert into jl values("%s","%s")'%(item['name'],item['url']) #2.执行sql语句 try: #执行事务
self.cursor.execute(sql)
self.conn.commit() except Exception as e:
print(e)
self.conn.rollback() return item def close_spider(self,spider):
print('爬虫结束')
self.cursor.close()
self.conn.close()
spider
# -*- coding: utf-8 -*-
import scrapy
import re
from lxml import etree
from jianli.items import JianliItem class FxhSpider(scrapy.Spider):
name = 'jl'
# allowed_domains = ['feixiaohao.com']
start_urls = ['http://sc.chinaz.com/jianli/free_{}.html'.format(i) for i in range(3)] def parse(self,response):
tree = etree.HTML(response.text)
a_list = tree.xpath('//div[@id="container"]/div/a') for a in a_list:
item = JianliItem (
name=a.xpath("./img/@alt")[0],
url=a.xpath("./@href")[0]
) yield item
settings.py
#USER_AGENT
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
} # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'jianli.pipelines.JianliPipeline': 300,
}
查看存储情况
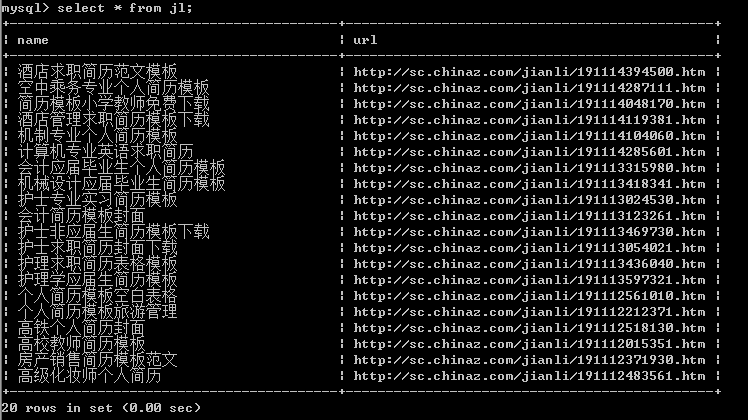
Scrapy爬虫案例 | 数据存储至MySQL的更多相关文章
- Scrapy爬虫案例 | 数据存储至MongoDB
豆瓣电影TOP 250网址 要求: 1.爬取豆瓣top 250电影名字.演员列表.评分和简介 2.设置随机UserAgent和Proxy 3.爬取到的数据保存到MongoDB数据库 items.py ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- 猫眼电影爬取(一):requests+正则,并将数据存储到mysql数据库
前面讲了如何通过pymysql操作数据库,这次写一个爬虫来提取信息,并将数据存储到mysql数据库 1.爬取目标 爬取猫眼电影TOP100榜单 要提取的信息包括:电影排名.电影名称.上映时间.分数 2 ...
- python之scrapy爬取数据保存到mysql数据库
1.创建工程 scrapy startproject tencent 2.创建项目 scrapy genspider mahuateng 3.既然保存到数据库,自然要安装pymsql pip inst ...
- 第四天,同步和异常数据存储到mysql,item loader方法
github对应代码:伯乐在线文章爬取 一. 普通插入方法 1. 连接到我的阿里云,用户名是test1,然后在navicat中新建数据库
- Spring Boot 揭秘与实战(二) 数据存储篇 - MySQL
文章目录 1. 环境依赖 2. 数据源3. 脚本初始化 2.1. 方案一 使用 Spring Boot 默认配置 2.2. 方案二 手动创建 4. 使用JdbcTemplate操作5. 总结 4.1. ...
- 使用MapReduce读取HBase数据存储到MySQL
Mapper读取HBase数据 package MapReduce; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hba ...
- 第十节:Web爬虫之数据存储与MySQL8.0数据库安装和数据插入
用解析器解析出数据之后,接下来就是存储数据了,保存的形式可以多种多样,最简单的形式是直接保存为文本文件,如 TXT.JSON.csv 另外,还可以保存到数据库中,如关系型数据库MySQL ,非关系型数 ...
- 爬虫实践——数据存储到Excel中
在进行爬虫实践时,我已经爬取到了我需要的信息,那么最后一个问题就是如何把我所爬到的数据存储到Excel中去,这是我没有学习过的知识. 如何解决这个问题,我选择先百度查找如何解决这个问题. 百度查到的方 ...
随机推荐
- Shadowmap简易实现
之前一直没有自己实现过阴影,只是概念上有所了解,这次通过Demo进行实际编写操作. 总的来说没有什么可以优化的,倒是对于窗户这种可用面片代替的物体似乎能优化到贴图上,之前arm有个象棋屋的demo做过 ...
- 如何在pycharm中设置环境变量
今天运行tensorflow的时候,发现在pycharm下,程序无法找到CUDA的libcupti.so文件.而在添加完环境变量: export LD_LIBRARY_PATH=$LD_LIBRARY ...
- Python中的单例设计
01. 单例设计模式 设计模式 设计模式 是 前人工作的总结和提炼,通常,被人们广泛流传的设计模式都是针对 某一特定问题 的成熟的解决方案 使用 设计模式 是为了可重用代码.让代码更容易被他人理解.保 ...
- Python pip安装第三方库的国内镜像
Windows系统下,一般情况下使用pip在DOS界面安装python第三方库时,经常会遇到超时的问题,导致第三方库无法顺利安装,此时就需要国内镜像源的帮助了. 使用方法如下: 例如:pip inst ...
- 谈谈游戏服务端SDK接入
“接sdk其实本质上就是一个对着接口文档写adaptor的工作,重复和无味.” 团队减员,身负多职,上一次调SDK已经可以回溯到游戏测试前夕了... 一般SDK只包含验证和支付功能,绝少部分SDK包含 ...
- android的子线程切换到主线程
在子线程中,如果想更新UI,必须切换到主线程,方法如下: if (Looper.myLooper() != Looper.getMainLooper()) { // If we finish mark ...
- formData详细使用教程
formData是ajax2.0(XMLHttpRequest Level2)新提出的接口,利用FormData对象可以将form表单元素的name与value进行组合,实现表单数据的序列化,从而介绍 ...
- 5.1 dex文件解析
1.DexHeader结构体占用0x70字节,源码位置 dalvik\libdex\DexFile.h文件中269/* 270 * Direct-mapped "header_item&qu ...
- 使用APICloud创建一个webapp项目
1.在APICloud官网注册,下载APICloud Studio并解压.(这里我选择的是APICloud Studio,还可以选择其他的开发工具的APICloud插件如Sublime,Webstor ...
- rest framework 之渲染器
根据 用户请求URL 或 用户可接受的类型,筛选出合适的 渲染组件. 用户请求头: Accept:text/html,application/xhtml+xml,application/xml;q=0 ...