Thread-Specific-Storage for C/C++
引用出处:https://www.cse.wustl.edu/~schmidt/PDF/TSS-pattern.pdf
摘要:
理论上多线程会提高程序性能,但实际上,由于在获取和释放锁的开销,多线程经常会比单线程表现得更糟。除此之外,为了避免竞争和死锁需要复杂的并发控制协议,多线程编程很难。
这里介绍Thread-Specific Storage模式(线程专用存储),解决一些多线程性能和编程复杂度的问题。Thread-Specific-Storage pattern 让多线程使用一个逻辑上全局接入点来获取thread-specific数据,并且每次获取时不会引起锁开销。
1 Intent
Thread-Specific-Storage pattern 让多线程使用一个逻辑上全局接入点来获取thread-specific数据,并且每次获取时不会引起锁开销。
2 Motivation
2.1 Context and Forces
Thread-Specific-Storage pattern 应该应用在多线程经常获取的对象是逻辑上全局但物理上是线程间专有,互不相同。例如,操作系统提供 errno 反应错误信息。当系统调用发生错误时, OS设置 errno 报告错误并返回错误记录状态。当应用检测到错误状态并查看 errno 来决定是哪个错误类型发生。例如,下面代码是从非阻塞TcpSocket写入接受缓存:
// One global errno per-process.
extern int errno;
void *worker (SOCKET socket)
{
// Read from the network connection
// and process the data until the connection
// is closed.
for (;;) {
char buffer[BUFSIZ];
int result = recv (socket, buffer, BUFSIZ, );
// Check to see if the recv() call failed.
if (result == -) {
if (errno != EWOULDBLOCK)
// Record error result in thread-specific data.
printf ("recv failed, errno = %d", errno);
} else
// Perform the work on success.
process_buffer (buffer);
}
}
如果 recv 返回 -1, 代码查看 errno != EWOULDBLOCK 并打印错误信息,recv>0处理接收缓存。
2.2 Common Traps and Pitfalls
虽然上面显示的“全局错误变量”方法对于单线程应用程序来说效果很好,但在多线程应用程序中会出现细微的问题。特别是,抢占式多线程系统中的竞争条件可能导致由一个线程中的方法设置的errno值被其他线程中的应用程序错误地解释。因此,如果多个线程同时执行worker函数,则可能由于竞争条件而错误地设置errno的全局版本。
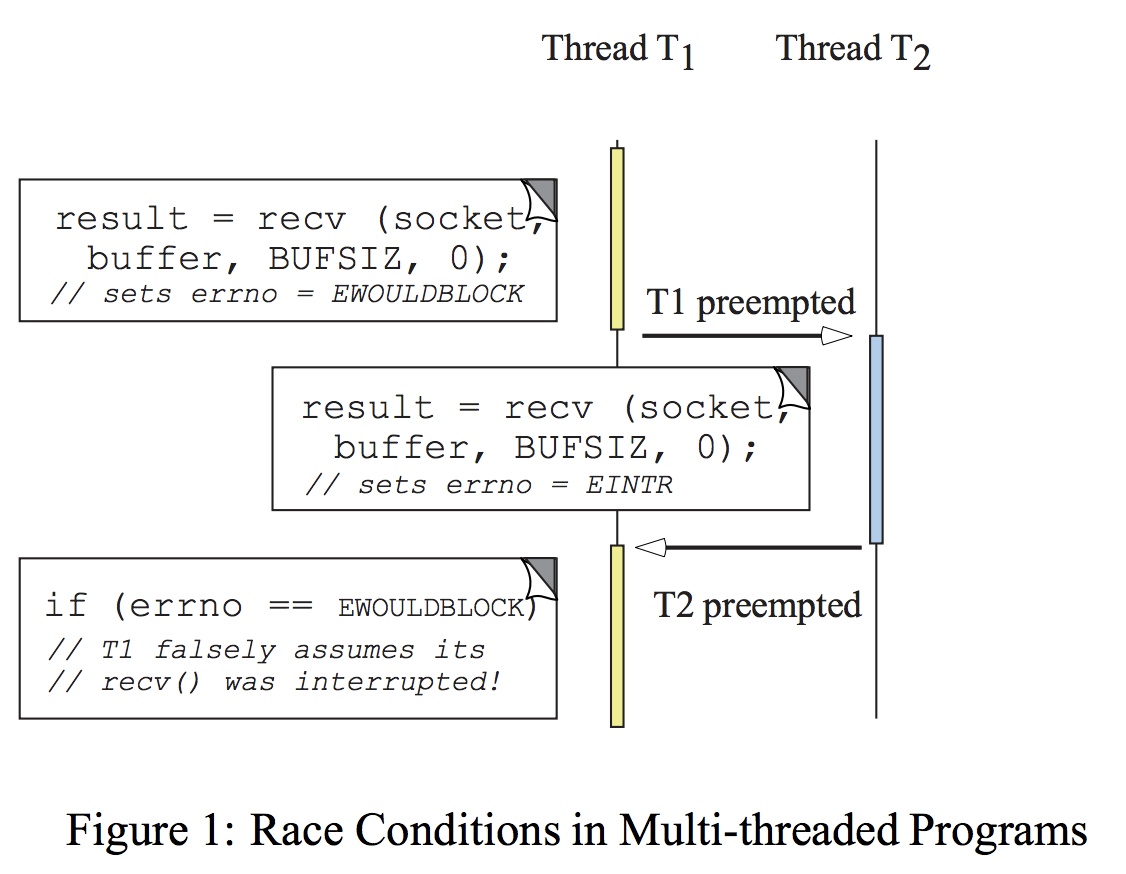
例如,两个线程(T1 和 T2) 执行 recv调用,T1的recv返回-1并设置 errno为 EWOULDBLOC,说明在一时刻没有数据在socket中。在T1查看这一状态前,T1被抢占,T2运行,假设T2产生中断,设置 errno为EINTR。如果T2这时立即被抢占,T1运行时错误的认为它的recv调用产生了中断,并执行错误行为。这个程序是错误的和不可移植的,因为它的行为取决于线程执行的顺序。
问题的根本是设置和检测这个全局errno变量有两个步骤:(1)recv调用设置这个变量;(2)应用检测这个变量。所以简单的对errno包装锁并不能解决竞争问题,因为set/test包裹多个操作(不是原子性的)。
解决这个问题的一个方法是创建一个更高级的锁机制。例如,recv调用内部获取一个errno mutex,当应用检测完recv返回的errno后,由应用来释放锁。然而,这个方法出现意料之外的没有释放锁,,将导致饥饿和死锁。此外,如果应用程序必须在每次调用库之后检查错误状态,那么即使不使用多个线程,额外的锁定开销也会显着降低性能。
2.3 Solution: Thread-Specific Storage
(1)Efficiency:特定于线程的存储允许线程内的顺序方法以原子方式访问特定于线程的对象,而不会导致每次访问的锁定开销.
(2) Simplify application programming:特定于线程的存储对于应用程序程序员来说很容易使用,因为系统开发人员可以通过数据抽象或宏在源代码级别使用特定于线程的存储完全透明.
(3) Highly portably:特定于线程的存储在大多数多线程OS平台上都可用,并且可以在缺少它的平台方便地实现.
3 Applicability适用性
当应用程序有以下特征时适用Thread-Specific Storage 模式:
(1)它最初是在假定单个控制线程的情况下编写的,并且在不更改现有API的情况下被移植到多线程环境.(2)它包含多个抢占式控制线程,可以以任意调度顺序并发执行.
(3)每个控制线程调用共享仅与该线程共同的数据的方法序列.
(4)必须通过与其他线程“逻辑”共享的全局可见访问点访问每个线程内的对象共享的数据,但每个线程的“物理”唯一性.
(5) 数据在方法之间隐式传递,而不是通过参数显式传递.
当应用程序有以下特征时,不要适用Thread-Specific Storage pattern:
(1)多个线程在单个任务上协作,需要并发访问共享数据。例如,多线程应用程序可以在内存数据库中同时执行读取和写入。在这种情况下,线程必须共享非特定于线程的记录和表。如果使用特定于线程的存储来存储数据库,则线程无法共享数据。因此,必须使用同步原语(例如,互斥锁)来控制对数据库记录的访问,以便线程可以在共享数据上进行协作。
(2)维护数据的物理和逻辑分离更直观,更有效。例如,通过将数据作为参数显式传递给所有方法,可以使线程仅在每个线程内访问数据。在这种情况下,可能不需要ThreadSpecific存储模式。
4 Structure and Participants
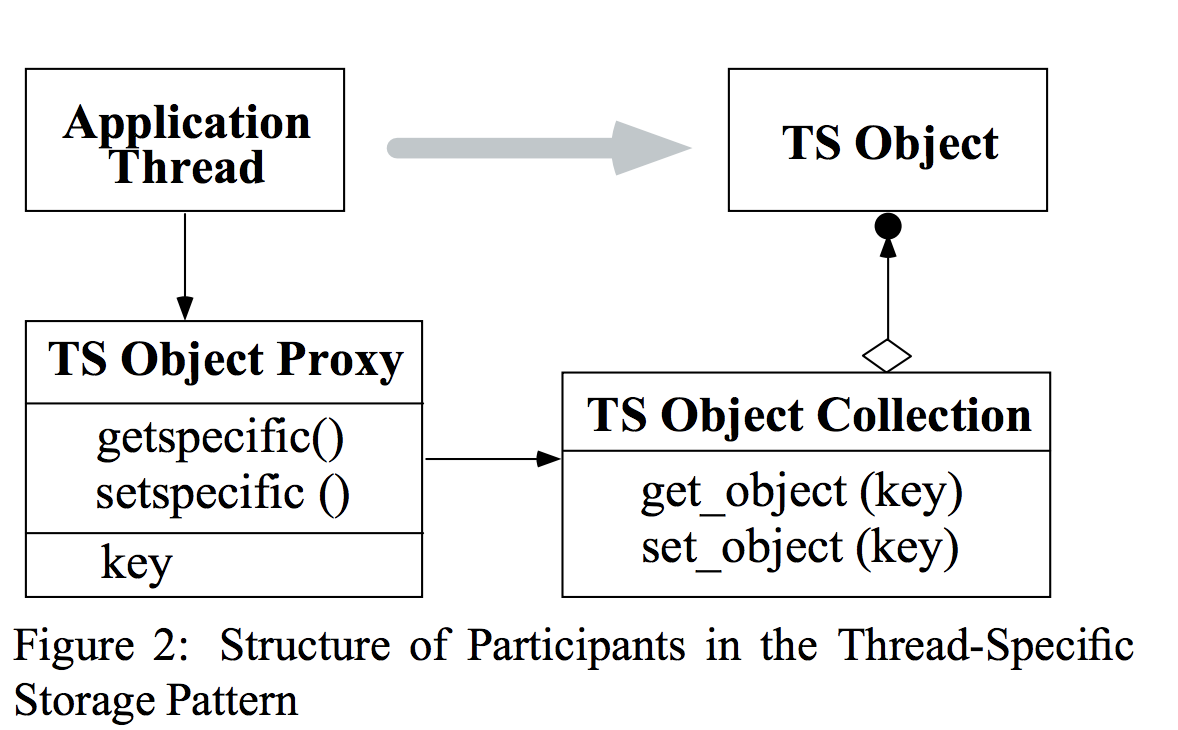
Application Threads
Application threads 使用 TS Object Proxies来获取在线程特化存储中的TS Objects。
Thread-Specific(TS) Object Proxy
TS Object Proxy 定义了TS Object 的接口,它通过 getspecific 和 setspecific方法,负责为每个应用线程提供获取独立的对象。
A TS Object Proxy 实例是一个类型的对象,它调解对一个线程特定的TS Object访问。例如,多线程使用同一个TS Object Proxy来获取线程特定的errno变量。TS Object Collection 使用key-value存储,使用getspecific 和 setspecific方法来创建并传递给集合。
TS Object Proxites 的目的是隐藏keys和TS Object Collections. 如果没有代理,Application Threads 会获取集合和明确使用keys。
Thread-Specific(TS) Object
一个 TS Object 是一个线程的thread-specific Object 实例,例如 ,一个线程特定的errno是一个type int 对象。它被 TS Object Collection管理,只能通过TS Object Proxy获取。
Thread-Specific(TS)Object Collection
在复杂的多线程应用程序中,线程的errno值可能是驻留在特定于线程的存储中的许多类型的数据之一。因此,对于线程检索其特定于线程的错误数据,它必须使用key。此key必须与errno关联,以允许线程访问TS Object Collection中的正确条目。
TS Object Collection 包含了所有与某个线程有关的线程特定对象的集合。每个线程有唯一的一个TS Object Collection。 TS Object Collection 将key 映射到线程特定的TS Objects. 一个TS Object Proxy使用key来从TS Object Collection使用get_object(key)和 set_object(key)取出一个特定的TS Object 。
5 Collaborations
图3中的交互图说明了特定于线程的存储模式中参与者之间的以下协作:
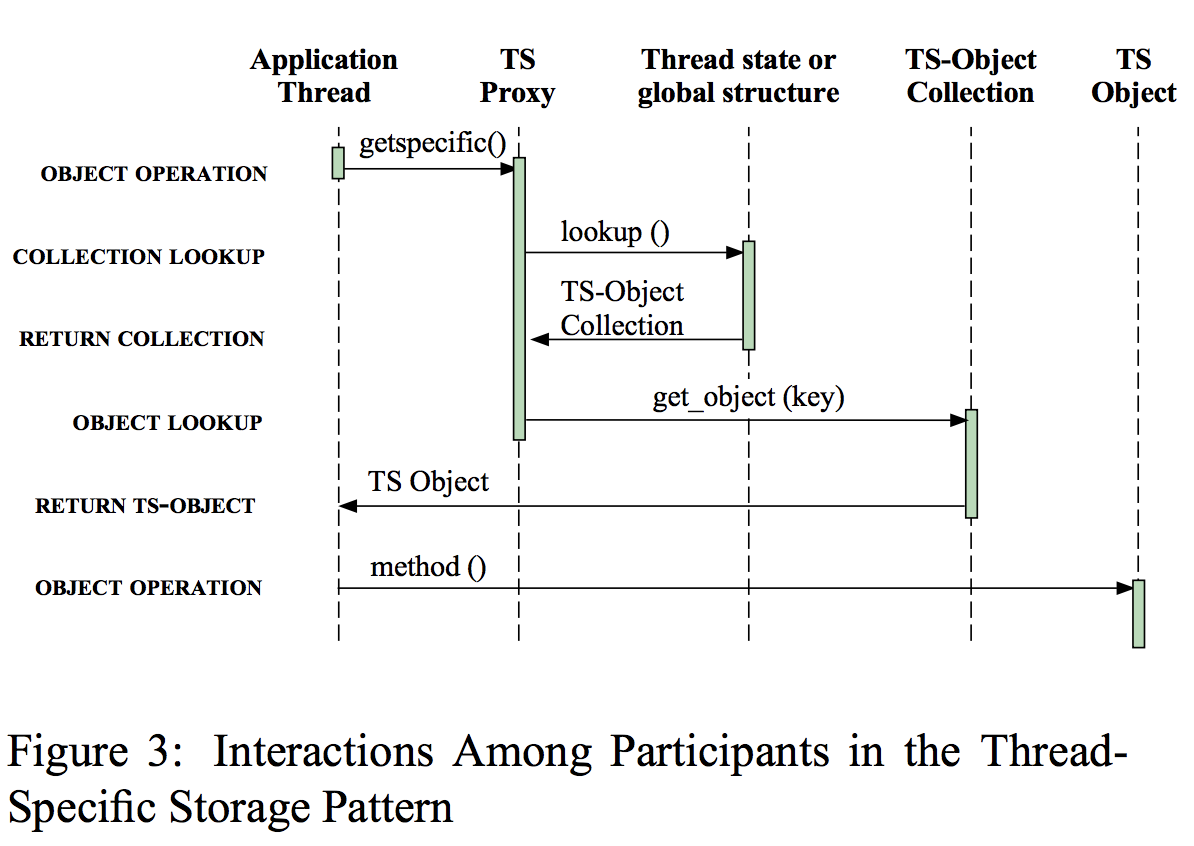
(1)定位 TS Object Collection:每个应用线程的方法使用TS Object Proxy的getspecific和setspecific获取TS Object Collection,它存储在线程内或由线程ID索引的全局结构中
(2)从thread-specific存储获取TS Object:一旦获取TS Object Collection,TS Oject Proxy使用key从集合检索出TS Object
(3)Set/get TS Object state:应用程序线程使用普通的C ++方法调用对TS对象进行操作。不需要锁定,因为该对象由仅在调用线程内访问的指针引用。
6 Consequences
6.1 Benefits
使用特定于线程的存储模式有几个好处,包括:
Efficiency:
可以实现特定于线程的存储模式,以便不需要锁定特定于线程的数据。例如,通过将errno放入特定于线程的存储中,每个线程都可以可靠地设置和测试该线程内方法的完成状态,而无需使用复杂的同步协议。这消除了线程内共享数据的锁定开销,这比获取和释放互斥锁更快.
使用简单:
特定于线程的存储对于应用程序员来说很容易使用,因为系统开发人员可以通过数据抽象或宏在源代码级别使用特定于线程的存储。
7 Implementation
特定于线程的存储模式可以以各种方式实现。本节介绍实现模式所需的每个步骤。步骤总结如下:
(1)建立TS Object Collections:
如果操作系统不提供特定于线程的存储的实现,则可以使用任何可用的机制来实现它,以维护TS对象集合中的数据结构的一致性。
(2)封装thread-specific storage的细节:
特定于线程的存储的接口通常是弱类型且容易出错的。因此,一旦特定于线程的存储的实现可用,使用C ++编程语言功能(例如模板和重载)来隐藏OO API背后的线程特定存储的低级细节。
7.1 设计TS Object 集合
集合是一个指针表指向TS Objects,索引是keys,在通过键访问特定于线程的对象之前,线程必须找到其TS对象集合。因此,第一个设计挑战是确定如何定位和存储TS对象集合.
TS对象集合可以(1)存储在所有线程外部,或者(2)存储在每个线程内部。下面描述和评估每种方法:
(1)所有线程外部:
此方法定义了每个线程的ID到其TS Object Collection表的全局映射(如图4所示)。找到正确的集合可能需要使用读取器/写入器锁来防止竞争条件。但是,一旦找到了集合,就不需要额外的锁定,因为在TS对象集合中只能有一个线程处于活动状态。
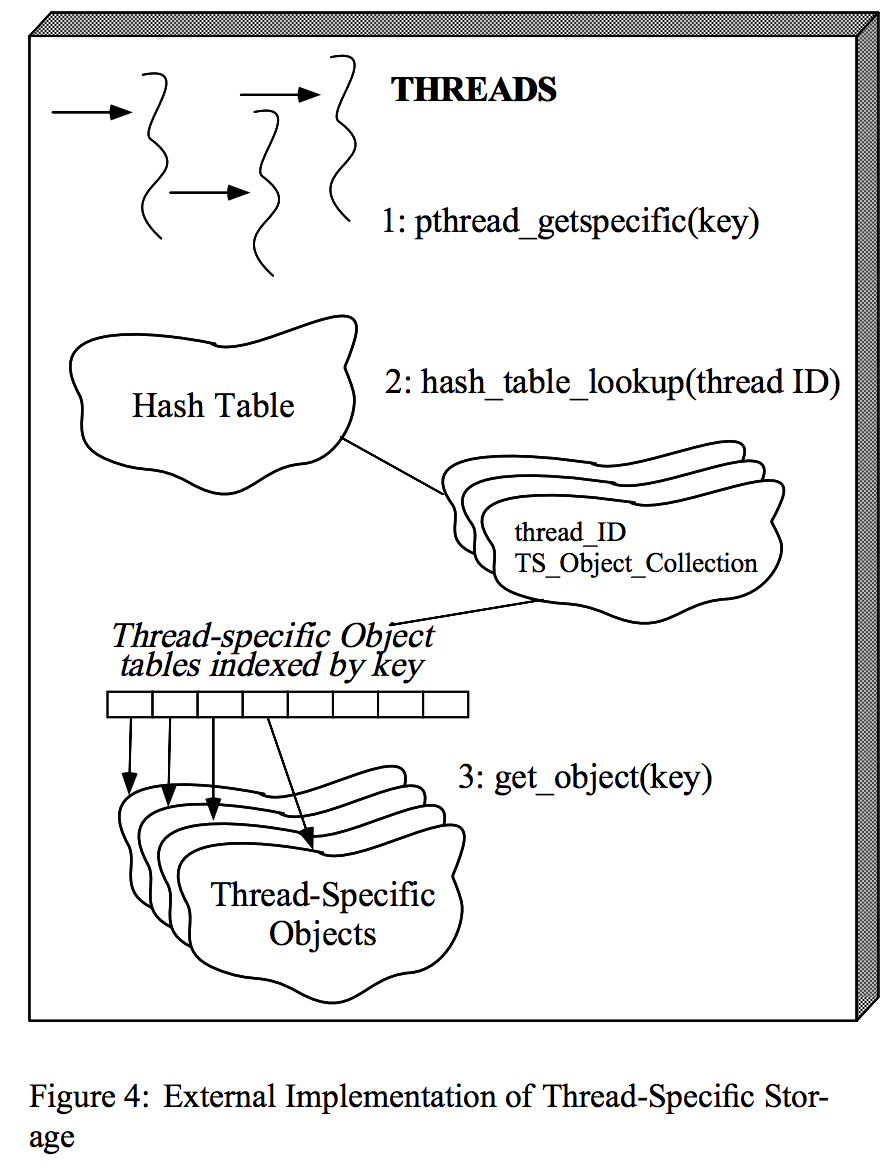
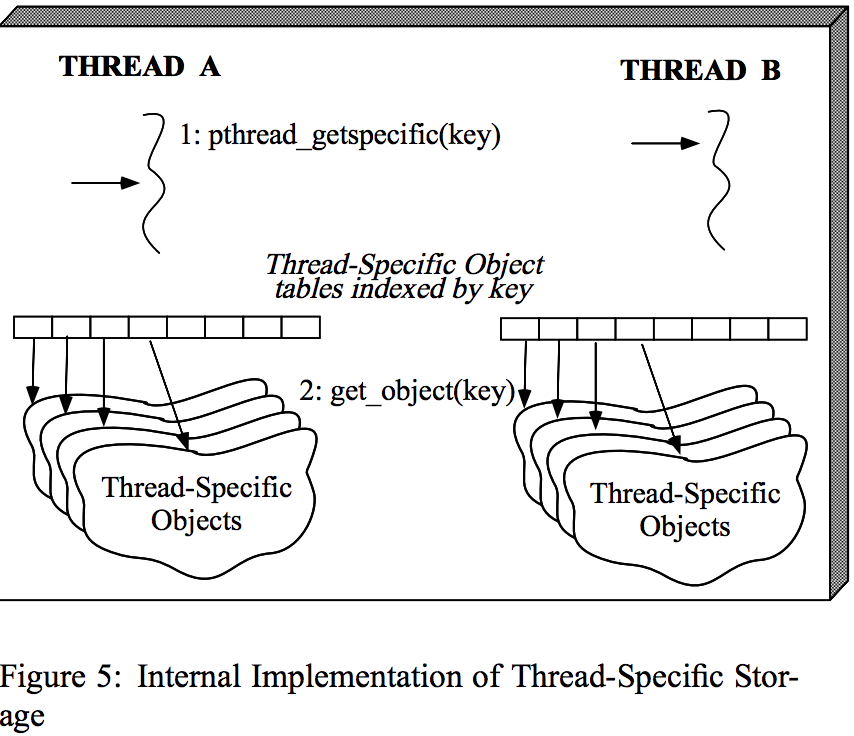
(2)每个线程内部:此方法要求进程中的每个线程以其其他内部状态(例如运行时线程堆栈,程序计数器,通用寄存器和线程ID)存储TS对象集合。当线程访问特定于线程的对象时,通过使用相应的键作为线程内部TS对象集合的索引来检索该对象(如图5所示)。这种方法不需要额外的锁定。
对于外部和内部实现,如果特定于线程的键的范围相对较小,则可以将TS对象集合存储为固定大小的数组。例如,POSIX Pthread标准定义了必须由符合实现支持的最小键数POSIX THREAD KEYS MAX。如果大小是固定的(例如,对于128个键,这是POSIX的默认值),则通过使用对象的键简单地索引到TS对象集合数组,查找时间可以是O(1),如图5所示。
但是,线程专用键的范围可能很大。例如,Solaris线程没有预定义的键数限制。因此,Solaris使用可变大小的数据结构,这可能会增加管理TS对象集合所需的时间。
线程ID的范围可以从非常小到非常大。这对内部实现没有任何问题,因为线程ID与线程状态中包含的相应TS对象集合隐式关联。
但是,对于外部实现,拥有一个固定大小的数组可能是不切实际的,该数组的每个可能的线程ID值都有一个条目。相反,让线程使用动态数据结构将线程ID映射到TS对象集合是更节省空间的。例如,一种方法是在线程ID上使用散列函数来获取散列表桶中的偏移量,该散列表桶包含将线程ID映射到其对应的TS对象集合的元组链(如图4所示)。
内部方法将TS对象集合与本地存储在本地,而外部方法将它们全局存储。根据外部表的实现,全局位置可以允许线程访问其他线程的TS对象集合。虽然这似乎打破了特定于线程的存储的全部要点,但是如果特定于线程的存储实现通过回收未使用的keys来提供自动垃圾收集,那么它将非常有用。此功能对于将键数限制为较小值的实现尤为重要.
但是,使用外部表会增加每个特定于线程的对象的访问时间,因为如果修改了全局可访问表(例如,在创建新key时),则需要同步机制(例如读取器/写入器锁)来避免竞争条件。另一方面,在每个线程的状态下将TS对象集合保持在本地需要更多的每线程存储,尽管总内存消耗不少。
8 boost::thread_specific_ptr
boost库提供thread_specific_ptr实现thread-specific-storage机制
// #include <boost/thread/tss.hpp> namespace boost
{
template <typename T>
class thread_specific_ptr
{
public:
thread_specific_ptr();
explicit thread_specific_ptr(void (*cleanup_function)(T*));
~thread_specific_ptr(); T* get() const;
T* operator->() const;
T& operator*() const; T* release();
void reset(T* new_value=);
};
}
thread_specific_ptr();
Requires:
-
delete this->get()is well-formed. - Effects:
-
Construct a
thread_specific_ptrobject for storing a pointer to an object of typeTspecific to each thread. The defaultdelete-based cleanup function will be used to destroy any thread-local objects whenreset()is called, or the thread exits. - Throws:
-
boost::thread_resource_errorif an error occurs.
explicit thread_specific_ptr(void (*cleanup_function)(T*));
- Requires:
-
cleanup_function(this->get())does not throw any exceptions. - Effects:
-
Construct a
thread_specific_ptrobject for storing a pointer to an object of typeTspecific to each thread. The suppliedcleanup_functionwill be used to destroy any thread-local objects whenreset()is called, or the thread exits. - Throws:
-
boost::thread_resource_errorif an error occurs.
thread_specific_ptr();
- Requires:
-
All the thread specific instances associated to this thread_specific_ptr (except maybe the one associated to this thread) must be null.
- Effects:
-
Calls
this->reset()to clean up the associated value for the current thread, and destroys*this. - Throws:
-
Nothing.
- Remarks:
-
The requirement is due to the fact that in order to delete all these instances, the implementation should be forced to maintain a list of all the threads having an associated specific ptr, which is against the goal of thread specific data.
T* get() const;
- Returns:
-
The pointer associated with the current thread.
- Throws:
-
Nothing.
 |
Note |
|---|---|
|
The initial value associated with an instance of |
T* operator->() const;
- Returns:
-
this->get() - Throws:
-
Nothing.
T& operator*() const;
- Requires:
-
this->getis notNULL. - Returns:
-
*(this->get()) - Throws:
-
Nothing.
void reset(T* new_value=0);
- Effects:
-
If
this->get()!=new_valueandthis->get()is non-NULL, invokedelete this->get()orcleanup_function(this->get())as appropriate. Storenew_valueas the pointer associated with the current thread. - Postcondition:
-
this->get()==new_value - Throws:
-
boost::thread_resource_errorif an error occurs.
T* release();
Effects:
-
Return
this->get()and storeNULLas the pointer associated with the current thread without invoking the cleanup function. - Postcondition:
-
this->get()==0 - Throws:
-
Nothing.
Thread-Specific-Storage for C/C++的更多相关文章
- 线程存储(Thread Specific Data)
线程中特有的线程存储, Thread Specific Data .线程存储有什么用了?他是什么意思了? 大家都知道,在多线程程序中,所有线程共享程序中的变量.现在有一全局变量,所有线程都可以使用它, ...
- 线程本地存储TLS(Thread Local Storage)的原理和实现——分类和原理
原文链接地址:http://www.cppblog.com/Tim/archive/2012/07/04/181018.html 本文为线程本地存储TLS系列之分类和原理. 一.TLS简述和分类 我们 ...
- 线程本地存储(Thread Local Storage, TLS)简单分析与使用
在多线程编程中, 同一个变量, 如果要让多个线程共享访问, 那么这个变量可以使用关键字volatile进行声明; 那么如果一个变量不想使多个线程共享访问, 那么该怎么办呢? 呵呵, 这个办法就是TLS ...
- 线程本地存储TLS(Thread Local Storage)的原理和实现——分类和原理
本文为线程本地存储TLS系列之分类和原理. 一.TLS简述和分类 我们知道在一个进程中,所有线程是共享同一个地址空间的.所以,如果一个变量是全局的或者是静态的,那么所有线程访问的是同一份,如果某一个线 ...
- 线程局部存储TLS(thread local storage)
同一全局变量或者静态变量每个线程访问的是同一变量,多个线程同时访存同一全局变量或者静态变量时会导致冲突,尤其是多个线程同时需要修改这一变量时,通过TLS机制,为每一个使用该全局变量的线程都提供一个变量 ...
- TLS Thread Local Storage
https://blog.csdn.net/yusiguyuan/article/details/22938671 https://blog.csdn.net/simsunny22/article/d ...
- Boost Thread学习笔记五
多线程编程中还有一个重要的概念:Thread Local Store(TLS,线程局部存储),在boost中,TLS也被称作TSS,Thread Specific Storage.boost::thr ...
- Inversion of Control Containers and the Dependency Injection pattern(转)
In the Java community there's been a rush of lightweight containers that help to assemble components ...
- Java 控制反转和依赖注入模式【翻译】【整理】
Inversion of Control Containers and the Dependency Injection pattern --Martin Fowler 本文内容 Component ...
- Inversion of Control Containers and the Dependency Injection pattern
https://martinfowler.com/articles/injection.html One of the entertaining things about the enterprise ...
随机推荐
- CF Dima and To-do List
B. Dima and To-do List time limit per test 1 second memory limit per test 256 megabytes input standa ...
- 多实例部署多个tomcat
注意点: 1.多实例tomcat的更新维护,需要考虑如何能“优雅”地对所有实例进行升级: 2.尽量不要影响应用程序,在更新tomcat时,一不小心就把conf目录等全部覆盖,所以尽量要把配置文件和安装 ...
- 基于svg.js实现对图形的拖拽、选择和编辑操作
本文主要记录如何使用 svg.js 实现对图形的拖拽,选择,图像渲染及各类形状的绘制操作. 1.关于SVG SVG 是可缩放的矢量图形,使用XML格式定义图像,可以生成对应的DOM节点,便于对单个图形 ...
- 拖动条SeekBar
1TextView tv=(TextView)findViewById(R.id.TV); 2 tv.setMovementMethod(ScrollingMovementMethod.getInst ...
- vue 数组重复,循环报错
Vue.js默认不支持往数组中加入重复的数据.可以使用track-by="$index"来实现.
- Windows API-----top level window
原文地址: http://blog.163.com/cumt_xl/blog/static/19071504420136911838683/ Q: What is a top-level window ...
- Python 2 和Python 3的区别
print input urlopen print print在版本2的使用方法是: print 'this is version 2' 也可以是 print('this is version 2') ...
- 二维码Zxing&Zbar
二维码Zxing&Zbar 前言:该项目主要介绍了二维码扫描.闪光灯开启.本地二维码图片识别.二维码生成.分别是zxing和zbar(网格二维码)分别实现,具体效果运行项目apk... 开发环 ...
- GIT团队合作探讨之二--Pull Request
pull request是github/bitbucket给开发人员实现便利合作提供的一个feature.他们提供一个用户友好的web界面在进代码之前来讨论这些变更. 简单说,pull request ...
- MVC5中Model设置属性注解
ASP.NET MVC5中Model层开发,使用的数据注解有三个作用: 数据映射(把Model层的类用EntityFramework映射成对应的表) 数据验证(在服务器端和客户端验证数据的有效性) 数 ...