C中级 消息队列设计
引言 - 补充好开始
消息队列在游戏服务器层应用非常广泛. 应用于各种耗时的IO操作业务上.消息队列可以简单理解为
[消息队列 = 队列 + 线程安全]本文参照思路如下, 最后献上一个大神们斗法的场景O(∩_∩)O哈哈~
回调还是消息队列 -> 架构的选择
skynet 全局消息队列 -> skynet_mq.c
消息队列血案 https://www.douban.com/note/470290075/
消息队列最方便之处在于让异步编程变得简单高效.(异步搞成同步). 多数应用于如下方面,消息收发处理,
DB消息写入, 日志系统等等. 运用在密集型IO处理业务中. 关于消息队列的套路太多了,
下面所要分析的消息队列, 算不上高效但绝不低效. 但是安全省内存. 可以用于实战.
用到的原子锁接口 scatom.h (2017年5月10日15:05:42)
#ifndef _H_SIMPLEC_SCATOM
#define _H_SIMPLEC_SCATOM /*
* 作者 : wz
*
* 描述 : 简单的原子操作,目前只考虑 VS(CL) 小端机 和 gcc
* 推荐用 posix 线程库
*/ #define _INT_USLEEP_LOCK (1) // 如果 是 VS 编译器
#if defined(_MSC_VER) #include <Windows.h> //忽略 warning C4047: “==”:“void *”与“LONG”的间接级别不同
#pragma warning(disable:4047) // v 和 a 都是 long 这样数据
#define ATOM_FETCH_ADD(v, a) InterlockedExchangeAdd((LONG volatile *)&(v), (LONG)(a)) #define ATOM_ADD_FETCH(v, a) InterlockedAdd((LONG volatile *)&(v), (LONG)(a)) #define ATOM_SET(v, a) InterlockedExchange((LONG volatile *)&(v), (LONG)(a)) #define ATOM_CMP(v, c, a) ((LONG)(c) == InterlockedCompareExchange((LONG volatile *)&(v), (LONG)(a), (LONG)(c))) /*
* 对于 InterlockedCompareExchange(v, c, a) 等价于下面
* long tmp = v ; v == a ? v = c : ; return tmp;
*
* 咱们的 ATOM_FETCH_CMP(v, c, a) 等价于下面
* long tmp = v ; v == c ? v = a : ; return tmp;
*/
#define ATOM_FETCH_CMP(v, c, a) InterlockedCompareExchange((LONG volatile *)&(v), (LONG)(a), (LONG)(c)) #define ATOM_LOCK(v) \
while(ATOM_SET(v, )) \
Sleep(_INT_USLEEP_LOCK) #define ATOM_UNLOCK(v) ATOM_SET(v, 0) // 保证代码不乱序优化后执行
#define ATOM_SYNC() MemoryBarrier() // 否则 如果是 gcc 编译器
#elif defined(__GNUC__) #include <unistd.h> /*
* type tmp = v ; v += a ; return tmp ;
* type 可以是 8,16,32,64 bit的类型
*/
#define ATOM_FETCH_ADD(v, a) __sync_fetch_add_add(&(v), (a)) /*
* v += a ; return v;
*/
#define ATOM_ADD_FETCH(v, a) __sync_add_and_fetch(&(v), (a)) /*
* type tmp = v ; v = a; return tmp;
*/
#define ATOM_SET(v, a) __sync_lock_test_and_set(&(v), (a)) /*
* bool b = v == c; b ? v=a : ; return b;
*/
#define ATOM_CMP(v, c, a) __sync_bool_compare_and_swap(&(v), (c), (a)) /*
* type tmp = v ; v == c ? v = a : ; return v;
*/
#define ATOM_FETCH_CMP(v, c, a) __sync_val_compare_and_swap(&(v), (c), (a)) /*
* 加锁等待,知道 ATOM_SET 返回合适的值
* _INT_USLEEP 是操作系统等待纳秒数,可以优化,看具体操作系统
*
* 使用方式
* int lock = 0;
* ATOM_LOCK(lock);
*
* // to do think ...
*
* ATOM_UNLOCK(lock);
*
*/
#define ATOM_LOCK(v) \
while(ATOM_SET(v, )) \
usleep(_INT_USLEEP_LOCK) // 对ATOM_LOCK 解锁, 当然 直接调用相当于 v = 0;
#define ATOM_UNLOCK(v) __sync_lock_release(&(v)) // 保证代码不乱序
#define ATOM_SYNC() __sync_synchronize() #endif // !_MSC_VER && !__GNUC__ /*
* 试图加锁, 使用例子 if(ATOM_TRYLOCK(v)) {
// 已经有人加锁了, 处理返回事件
...
} // 得到锁资源, 开始处理
... ATOM_UNLOCK(v); * 返回1表示已经有人加锁了, 竞争锁失败.
* 返回0表示得到锁资源, 竞争锁成功
*/
#define ATOM_TRYLOCK(v) ATOM_SET(v, 1) #endif // !_H_SIMPLEC_SCATOM
到这里不妨再扯一点. 盲目的使用消息队列也是存在缺点的, 因为消息队列是存在开销的, 堆上内存的来回分配.
线程的无脑轮序. 有机会我在日志系统上再做一次对比分析. 每一个设计思路的选择, 一定要切合业务.
前言 - 我们来谈一谈设计
首先看消息队列接口设计. 创建, 销毁, 入队, 出队, 队长度 这些操作. 主要体现在 mq.h 中
#ifndef _H_SIMPLEC_MQ
#define _H_SIMPLEC_MQ typedef struct mq * mq_t; //
// mq_create - 创建一个消息队列类型
// return : 返回创建好的消息队列对象, NULL表示失败
//
extern mq_t mq_create(void); //
// mq_delete - 删除创建消息队列, 并回收资源
// mq : 消息队列对象
// return : void
//
extern void mq_delete(mq_t mq); //
// mq_push - 消息队列中压入数据
// mq : 消息队列对象
// msg : 压入的消息
// return : void
//
extern void mq_push(mq_t mq, void * msg); //
// mq_pop - 消息队列中弹出消息,并返回
// mq : 消息队列对象
// return : 返回队列尾巴, 队列为empty返回NULL
//
extern void * mq_pop(mq_t mq); //
// mq_len - 得到消息队列的长度,并返回
// mq : 消息队列对象
// return : 返回消息队列长度
//
extern int mq_len(mq_t mq); #endif // !_H_SIMPLEC_MQ
要不来个题外话, 为什么不用 /**/ 多行注释, 而采用 // 多行注释呢. 其实原因是 Visual Studio 中 /**/ 多行注释复制会
错位. 就喜欢用// 注释, 显得有美感. 有兴趣的朋友可以参照上面注释写法虽然繁琐, 但是加深的业务的理解.
扯个淡, C 中有几种注释的方式. 哈哈, 是不是也可以做个面试题.
那我们开始扯扯详细设计思路吧, 一切从结构开始
//
// 队列empty <=> tail == -1 ( head = 0 )
// 队列full <=> head == cap
//
struct mq {
int lock; // 消息队列锁
int cap; // 消息队列容量, 必须是2的幂
int head; // 消息队列头索引
int tail; // 消息队列尾索引
void ** queue; // 具体的使用消息
};
它是个环形的队列,
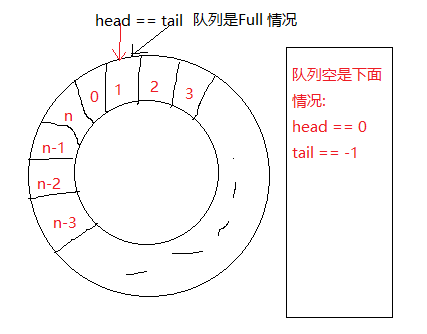
这么做的好处是, 能够使用完所有的空间, 存在真的满情况. 云大大的消息队列是假满,
每次满的时候立即扩充内存. 永远存在内存冗余. 再介绍一个思路. 当消息量多了, 需要扩容这里采用的算法是.
1) realloc 扩充内存
2) 整理消息内存移动到 head = 0头部开始
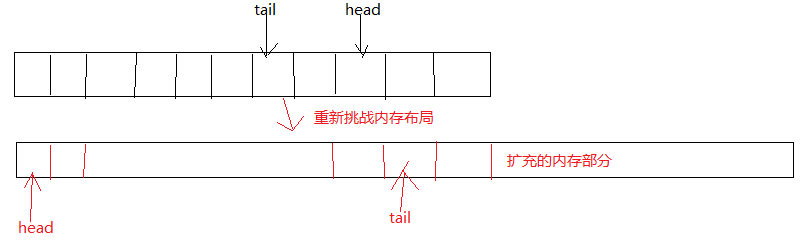
其实这里有个更简单的做法 两次malloc , 移动内存位置. 但是 realloc 对内存重新申请做了优化. 毕竟内存IO申请操作更加恶心复杂.
扯淡一点, 代码不值钱, 思路值钱. 或者说最值钱的自己. 最值得投资的也是自己. 前提是能给别人带来快乐.
正文 - 正儿八经的实现
最终的设计版本 mq.c
#include <assert.h>
#include <scatom.h>
#include <mq.h> // 2 的 幂
#define _INT_MQ (1 << 6) //
// 队列empty <=> tail == -1 ( head = 0 )
// 队列full <=> head == cap
//
struct mq {
int lock; // 消息队列锁
int cap; // 消息队列容量, 必须是2的幂
int head; // 消息队列头索引
int tail; // 消息队列尾索引
void ** queue; // 具体的使用消息
}; //
// mq_create - 创建一个消息队列类型
// return : 返回创建好的消息队列对象, NULL表示失败
//
inline mq_t
mq_create(void) {
struct mq * q = malloc(sizeof(struct mq));
assert(q);
q->lock = ;
q->cap = _INT_MQ;
q->head = ;
q->tail = -;
q->queue = malloc(sizeof(void *) * _INT_MQ);
return q;
} //
// mq_delete - 删除创建消息队列, 并回收资源
// mq : 消息队列对象
// return : void
//
inline void
mq_delete(mq_t mq) {
if (mq) {
free(mq->queue);
free(mq);
}
} // add two cap memory, memory is do not have assert
static void
_expand_queue(struct mq * mq) {
int i, j, cap = mq->cap << ;
void ** nqueue = realloc(mq->queue, sizeof(void *) * cap);
assert(nqueue); // 开始移动内存位置
for (i = ; i < mq->head; ++i) {
void * tmp = mq->queue[i];
for (j = i; j < mq->cap; j += mq->head)
mq->queue[j] = mq->queue[(mq->head + j) & (mq->cap - )];
mq->queue[j & (mq->cap - )] = tmp;
} mq->head = ;
mq->tail = mq->cap;
mq->cap = cap;
mq->queue = nqueue;
} //
// mq_push - 消息队列中压入数据
// mq : 消息队列对象
// msg : 压入的消息
// return : void
//
void
mq_push(mq_t mq, void * msg) {
int tail;
assert(mq && msg);
ATOM_LOCK(mq->lock); tail = (mq->tail + ) & (mq->cap - );
// 队列为full的时候申请内存
if (tail == mq->head && mq->tail >= )
_expand_queue(mq);
else
mq->tail = tail; mq->queue[mq->tail] = msg; ATOM_UNLOCK(mq->lock);
} //
// mq_pop - 消息队列中弹出消息,并返回
// mq : 消息队列对象
// return : 返回队列尾巴, 队列为empty返回NULL
//
void * mq_pop(mq_t mq) {
void * msg = NULL;
assert(mq); ATOM_LOCK(mq->lock); if (mq->tail >= ) {
msg = mq->queue[mq->head];
if(mq->tail != mq->head)
mq->head = (mq->head + ) & (mq->cap - );
else {
// 这是empty,情况, 重置
mq->tail = -;
mq->head = ;
}
} ATOM_UNLOCK(mq->lock); return msg;
} //
// mq_len - 得到消息队列的长度,并返回
// mq : 消息队列对象
// return : 返回消息队列长度
//
int
mq_len(mq_t mq) {
int head, tail, cap;
assert(mq); ATOM_LOCK(mq->lock); cap = mq->cap;
head = mq->head;
tail = mq->tail; ATOM_UNLOCK(mq->lock); tail -= head - ;
return tail < ? tail + cap : tail;
}
从上面设计也能看出来, 一遇到全局的立马加自旋锁. 一种最保守也是最安全的做法. 绝逼不会错. 不要问为啥.
因为最终在大大们的争吵中选了正确的易维护的代码思路. 这里再扯一下, 在库设计中很多为 unsigned, signed
的取舍而费脑筋. 我有个经验如果不存在 - or -- 操作, unsigned 是最优的. 存在大量 - or -- 操作可以使用
signed这样容易维护. 这块是bug 高发区.
后记 - 解决问题, 从大道理开始
男人哭吧不是罪 http://www.xiami.com/song/374995



C中级 消息队列设计的更多相关文章
- ActiveMQ学习总结(8)——消息队列设计精要
消息队列已经逐渐成为企业IT系统内部通信的核心手段.它具有低耦合.可靠投递.广播.流量控制.最终一致性等一系列功能,成为异步RPC的主要手段之一. 当今市面上有很多主流的消息中间件,如老牌的Activ ...
- Python 番外 消息队列设计精要
消息队列已经逐渐成为企业IT系统内部通信的核心手段.它具有低耦合.可靠投递.广播.流量控制.最终一致性等一系列功能,成为异步RPC的主要手段之一.当今市面上有很多主流的消息中间件,如老牌的Active ...
- 基于redis的延迟消息队列设计
需求背景 用户下订单成功之后隔20分钟给用户发送上门服务通知短信 订单完成一个小时之后通知用户对上门服务进行评价 业务执行失败之后隔10分钟重试一次 类似的场景比较多 简单的处理方式就是使用定时任务 ...
- 基于redis的延迟消息队列设计(转)
需求背景 用户下订单成功之后隔20分钟给用户发送上门服务通知短信 订单完成一个小时之后通知用户对上门服务进行评价 业务执行失败之后隔10分钟重试一次 类似的场景比较多 简单的处理方式就是使用定时任务 ...
- 别再用 Redis List 实现消息队列了,Stream 专为队列而生
上回说到使用 Redis 的 List 实现消息队列有很多局限性,比如: 没有良好的 ACK 机制: 没有 ConsumerGroup 消费组概念: 消息堆积. List 是线性结构,想要查询指定数据 ...
- Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇
目前业界流行的分布式消息队列系统(或者可以叫做消息中间件)种类繁多,比如,基于Erlang的RabbitMQ.基于Java的ActiveMQ/Apache Kafka.基于C/C++的ZeroMQ等等 ...
- ENode 1.0 - 消息队列的设计思路
开源地址:https://github.com/tangxuehua/enode 上一篇文章,简单介绍了enode框架内部的整体实现思路,用到了staged event-driven architec ...
- enode框架step by step之消息队列的设计思路
enode框架step by step之消息队列的设计思路 enode框架系列step by step文章系列索引: enode框架step by step之开篇 enode框架step by ste ...
- 为什么要用消息队列 及 自己如何设计一个mq架构
1. 解耦:如左图, 系统a因为业务需求需要调用系统b,后续因为业务需求可能需要改代码调用系统c,甚至还要考虑被调用的系统挂了访问超时的问题.耦合性太高! 如右图, 系统a产生一条数据发送到消息队列里 ...
随机推荐
- poj 1018 Communication System (枚举)
Communication System Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 22380 Accepted: ...
- hdu ACM Steps Section 1 花式A+B 输入输出格式
acm与oi很大的一个不同就是在输入格式上.oi往往是单组数据,而acm往往是多组数据,而且题目对数据格式往往各有要求,这8道a+b(吐槽..)涉及到了大量的常用的输入输出格式.https://wen ...
- [Ahoi2005]COMMON 约数研究 【欧拉线性筛的应用】
1968: [Ahoi2005]COMMON 约数研究 Time Limit: 1 Sec Memory Limit: 64 MB Submit: 2939 Solved: 2169 [Submi ...
- 从零开始学Linux系统(三)安装CentOS-7及软件包管理操作
推荐博文: VirtualBox安装CentOS7步骤详解: https://my.oschina.net/AaronDMC/blog/840753 如何安装CentOS7字符界面 :http://b ...
- Redux的应该注意的问题
1. Store中的State修改不能直接修改原有的State,若直接修改State,则redux中的所有操作都将指向 内存中的同一个state,将无法获取每一次操作前后的state,就无法追溯sta ...
- CentOS7搭建 Hadoop + HBase + Zookeeper集群
摘要: 本文主要介绍搭建Hadoop.HBase.Zookeeper集群环境的搭建 一.基础环境准备 1.下载安装包(均使用当前最新的稳定版本,截止至2017年05月24日) 1)jdk-8u131 ...
- Java的四种引用?用到的场景?
在JDK 1.2以前的版本中,若一个对象不被任何变量引用,那么程序就无法再使用这个对象.也就是说,只有对象处于可触及(reachable)状态,程序才能使用它.从JDK 1.2版本开始,把对象的引用分 ...
- Dumpsdecrypted
Dumps decrypted mach-o files from encrypted iPhone applications from memory to disk. This tool is ne ...
- 搭建JavaWeb应用开发环境
下载和安装Tomcat服务器 下载Tomcat安装程序包:http://tomcat.apache.org/,下载一个zip版本,解压到本地即完成了Tomcat的安装. 测试是否安装成功:进入Tomc ...
- js script type 部分属性值分析
1. text/javascript: (1)<script type="text/javascript" src="Js/jquery-1.10.2.min.js ...