web頁面優化以及SEO
轉載:https://blog.csdn.net/xustart7720/article/details/79960591
浏览器访问优化
浏览器请求处理流程如下图:
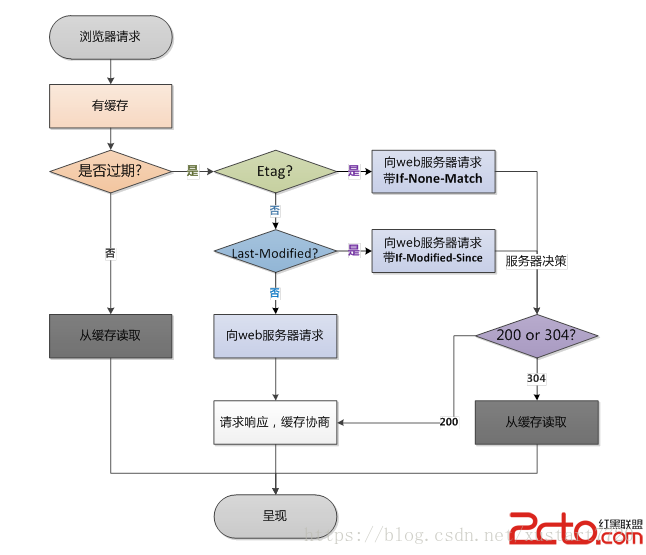
Etag:實體標籤。ETag是HTTP协议提供的若干机制中的一种Web缓存验证机制,并且允许客户端进行缓存协商。这就使得缓存变得更加高效,而且节省带宽。如果资源的内容没有发生改变,Web服务器就不需要发送一个完整的响应。ETag也可用于乐观并发控制[1],作为一种防止资源同步更新而相互覆盖的方法。--<w3schol>
web頁面優化
1、减少http请求,合理设置 HTTP缓存
http协议是无状态的应用层协议,意味着每次http请求都需要建立通信链路、进行数据传输,而在服务器端,每个http都需要启动独立的线程去处理。这些通信和服务的开销都很昂贵,减少http请求的数目可有效提高访问性能。
减少http的主要手段是合并CSS、合并javascript、合并图片。将浏览器一次访问需要的javascript和CSS合并成一个文件,这样浏览器就只需要一次请求。图片也可以合并,多张图片合并成一张,如果每张图片都有不同的超链接,可通过CSS偏移响应鼠标点击操作,构造不同的URL。
缓存的力量是强大的,恰当的缓存设置可以大大的减少 HTTP请求。假设某网站首页,当浏览器没有缓存的时候访问一共会发出 78个请求,共 600多 K数据,而当第二次访问即浏览器已缓存之后访问则仅有 10个请求,共 20多 K数据。 (这里需要说明的是,如果直接 F5刷新页面的话效果是不一样的,这种情况下请求数还是一样,不过被缓存资源的请求服务器是 304响应,只有 Header没有Body ,可以节省带宽 )
怎样才算合理设置 ?原则很简单,能缓存越多越好,能缓存越久越好。例如,很少变化的图片资源可以直接通过 HTTP Header中的Expires设置一个很长的过期头 ;变化不频繁而又可能会变的资源可以使用 Last-Modifed来做请求验证。尽可能的让资源能够在缓存中待得更久。关于 HTTP缓存的具体设置和原理此处就不再详述了。
一:減少http請求,合併小內容多請求的內容。
2、使用浏览器缓存
对一个网站而言,CSS、javascript、logo、图标这些静态资源文件更新的频率都比较低,而这些文件又几乎是每次http请求都需要的,如果将这些文件缓存在浏览器中,可以极好的改善性能。通过设置http头中的cache-control和expires的属性,可设定浏览器缓存,缓存时间可以是数天,甚至是几个月。
在某些时候,静态资源文件变化需要及时应用到客户端浏览器,这种情况,可通过改变文件名实现,即更新javascript文件并不是更新javascript文件内容,而是生成一个新的JS文件并更新HTML文件中的引用。
使用浏览器缓存策略的网站在更新静态资源时,应采用逐量更新的方法,比如需要更新10个图标文件,不宜把10个文件一次全部更新,而是应该一个文件一个文件逐步更新,并有一定的间隔时间,以免用户浏览器忽然大量缓存失效,集中更新缓存,造成服务器负载骤增、网络堵塞的情况。
3、启用压缩
在服务器端对文件进行压缩,在浏览器端对文件解压缩,可有效减少通信传输的数据量。如果可以的话,尽可能的将外部的脚本、样式进行合并,多个合为一个。文本文件的压缩效率可达到80%以上,因此HTML、CSS、javascript文件启用GZip压缩可达到较好的效果。但是压缩对服务器和浏览器产生一定的压力,在通信带宽良好,而服务器资源不足的情况下要权衡考虑。
4、 CSS Sprites
合并 CSS图片,减少请求数的又一个好办法。
5、Lazy Load Images(懶加載圖片,瀑布流加載機制)
这条策略实际上并不一定能减少 HTTP请求数,但是却能在某些条件下或者页面刚加载时减少 HTTP请求数。对于图片而言,在页面刚加载的时候可以只加载第一屏,当用户继续往后滚屏的时候才加载后续的图片。这样一来,假如用户只对第一屏的内容感兴趣时,那剩余的图片请求就都节省了。
6、CSS放在页面最上部,javascript放在页面最下面
浏览器会在下载完成全部CSS之后才对整个页面进行渲染,因此最好的做法是将CSS放在页面最上面,让浏览器尽快下载CSS。如果将 CSS放在其他地方比如 BODY中,则浏览器有可能还未下载和解析到 CSS就已经开始渲染页面了,这就导致页面由无 CSS状态跳转到 CSS状态,用户体验比较糟糕,所以可以考虑将CSS放在HEAD中。
Javascript则相反,浏览器在加载javascript后立即执行,有可能会阻塞整个页面,造成页面显示缓慢,因此javascript最好放在页面最下面。但如果页面解析时就需要用到javascript,这时放到底部就不合适了。
Lazy Load Javascript(只有在需要加载的时候加载,在一般情况下并不加载信息内容。)随着 Javascript框架的流行,越来越多的站点也使用起了框架。不过,一个框架往往包括了很多的功能实现,这些功能并不是每一个页面都需要的,如果下载了不需要的脚本则算得上是一种资源浪费 -既浪费了带宽又浪费了执行花费的时间。目前的做法大概有两种,一种是为那些流量特别大的页面专门定制一个专用的 mini版框架,另一种则是 Lazy Load。
7、异步请求 Callback(就是将一些行为样式提取出来,慢慢的加载信息的内容)
在某些页面中可能存在这样一种需求,需要使用 script标签来异步的请求数据。类似:
<code class="hljs javascript"> Javascript:
/*Callback 函数*/
function myCallback(info){
//do something here
}
HTML:
Callback返回的内容 :
myCallback('Hello world!');</code>
像以上这种方式直接在页面上写
8、减少cookie传输
一方面,cookie包含在每次请求和响应中,太大的cookie会严重影响数据传输,因此哪些数据需要写入cookie需要慎重考虑,尽量减少cookie中传输的数据量。另一方面,对于某些静态资源的访问,如CSS、script等,发送cookie没有意义,可以考虑静态资源使用独立域名访问,避免请求静态资源时发送cookie,减少cookie传输次数。
9、Javascript代码优化
(1). DOM
a. HTML Collection(HTML收集器,返回的是一个数组内容信息)
在脚本中 document.images、document.forms 、getElementsByTagName()返回的都是 HTMLCollection类型的集合,在平时使用的时候大多将它作为数组来使用,因为它有 length属性,也可以使用索引访问每一个元素。不过在访问性能上则比数组要差很多,原因是这个集合并不是一个静态的结果,它表示的仅仅是一个特定的查询,每次访问该集合时都会重新执行这个查询从而更新查询结果。所谓的 “访问集合” 包括读取集合的 length属性、访问集合中的元素。
因此,当你需要遍历 HTML Collection的时候,尽量将它转为数组后再访问,以提高性能。即使不转换为数组,也请尽可能少的访问它,例如在遍历的时候可以将 length属性、成员保存到局部变量后再使用局部变量。
b. Reflow & Repaint
除了上面一点之外, DOM操作还需要考虑浏览器的 Reflow和Repaint ,因为这些都是需要消耗资源的。
(2). 慎用 with
with(obj){ p = 1}; 代码块的行为实际上是修改了代码块中的 执行环境 ,将obj放在了其作用域链的最前端,在 with代码块中访问非局部变量是都是先从 obj上开始查找,如果没有再依次按作用域链向上查找,因此使用 with相当于增加了作用域链长度。而每次查找作用域链都是要消耗时间的,过长的作用域链会导致查找性能下降。
因此,除非你能肯定在 with代码中只访问 obj中的属性,否则慎用 with,替代的可以使用局部变量缓存需要访问的属性。
(3). 避免使用 eval和 Function
每次 eval 或 Function 构造函数作用于字符串表示的源代码时,脚本引擎都需要将源代码转换成可执行代码。这是很消耗资源的操作 —— 通常比简单的函数调用慢 100倍以上。
eval 函数效率特别低,由于事先无法知晓传给 eval 的字符串中的内容,eval在其上下文中解释要处理的代码,也就是说编译器无法优化上下文,因此只能有浏览器在运行时解释代码。这对性能影响很大。
Function 构造函数比 eval略好,因为使用此代码不会影响周围代码 ;但其速度仍很慢。
此外,使用 eval和 Function也不利于Javascript 压缩工具执行压缩。
(4). 减少作用域链查找
前文谈到了作用域链查找问题,这一点在循环中是尤其需要注意的问题。如果在循环中需要访问非本作用域下的变量时请在遍历之前用局部变量缓存该变量,并在遍历结束后再重写那个变量,这一点对全局变量尤其重要,因为全局变量处于作用域链的最顶端,访问时的查找次数是最多的。
低效率的写法:
<code class=" hljs javascript">// 全局变量
var globalVar = 1;
function myCallback(info){
for( var i = 100000; i--;){
//每次访问 globalVar 都需要查找到作用域链最顶端,本例中需要访问 100000 次
globalVar += i;
}
}
</code>
更高效的写法:
<code class=" hljs javascript">// 全局变量
var globalVar = 1;
function myCallback(info){
//局部变量缓存全局变量
var localVar = globalVar;
for( var i = 100000; i--;){
//访问局部变量是最快的
localVar += i;
}
//本例中只需要访问 2次全局变量
在函数中只需要将 globalVar中内容的值赋给localVar 中
globalVar = localVar;
}</code>
此外,要减少作用域链查找还应该减少闭包的使用。
(5). 数据访问
Javascript中的数据访问包括直接量 (字符串、正则表达式 )、变量、对象属性以及数组,其中对直接量和局部变量的访问是最快的,对对象属性以及数组的访问需要更大的开销。当出现以下情况时,建议将数据放入局部变量:
a. 对任何对象属性的访问超过 1次
b. 对任何数组成员的访问次数超过 1次
另外,还应当尽可能的减少对对象以及数组深度查找。
(6). 字符串拼接
在 Javascript中使用”+” 号来拼接字符串效率是比较低的,因为每次运行都会开辟新的内存并生成新的字符串变量,然后将拼接结果赋值给新变量。与之相比更为高效的做法是使用数组的 join方法,即 将需要拼接的字符串放在数组中最后调用其 join方法得到结果。不过由于使用数组也有一定的开销,因此当需要拼接的字符串较多的时候可以考虑用此方法。
10、CSS选择符优化
在大多数人的观念中,都觉得浏览器对 CSS选择符的解析式从左往右进行的,例如
#toc A { color: #444; }这样一个选择符,如果是从右往左解析则效率会很高,因为第一个 ID选择基本上就把查找的范围限定了,但实际上浏览器对选择符的解析是从右往左进行的。如上面的选择符,浏览器必须遍历查找每一个 A标签的祖先节点,效率并不像之前想象的那样高。根据浏览器的这一行为特点,在写选择符的时候需要注意很多事项,有兴趣的童鞋可以去了解一下。
CDN加速
CDN(content distribute network,内容分发网络)的本质仍然是一个缓存,而且将数据缓存在离用户最近的地方,使用户以最快速度获取数据,即所谓网络访问第一跳,反向代理 ,如下图。
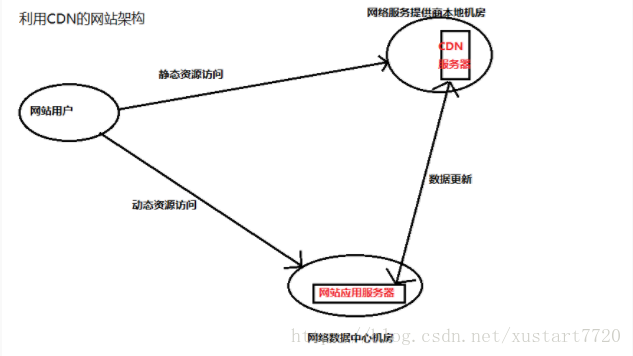
传统代理服务器位于浏览器一侧,代理浏览器将http请求发送到互联网上,而反向代理服务器位于网站机房一侧,代理网站web服务器接收http请求。如下图所示:
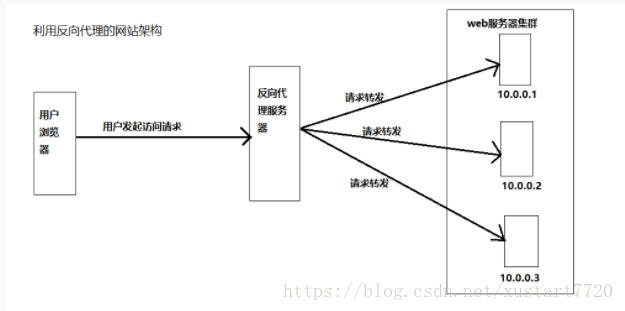
网站安全的作用,来自互联网的访问请求必须经过代理服务器,相当于web服务器和可能的网络攻击之间建立了一个屏障。
除了安全功能代理服务器也可以通过配置缓存功能加速web请求。当用户第一次访问静态内容的时候,静态内容就被缓存在反向代理服务器上,这样当其他用户访问该静态内容的时候,就可以直接从反向代理服务器返回,加速web请求响应速度,减轻web服务器负载压力。事实上,有些网站会把动态内容也缓存在代理服务器上,比如维基百科及某些博客论坛网站,把热门词条、帖子、博客缓存在反向代理服务器上加速用户访问速度,当这些动态内容有变化时,通过内部通知机制通知反向代理缓存失效,反向代理会重新加载最新的动态内容再次缓存起来。
此外,反向代理也可以实现负载均衡的功能,而通过负载均衡构建的应用集群可以提高系统总体处理能力,进而改善网站高并发情况下的性能。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
一、搜索引擎工作原理
当我们在输入框中输入关键词,点击搜索或查询时,然后得到结果。深究其背后的故事,搜索引擎做了很多事情。
在搜索引擎网站,比如百度,在其后台有一个非常庞大的数据库,里面存储了海量的关键词,而每个关键词又对应着很多网址,这些网址是百度程序从茫茫的互联网上一点一点下载收集而来的,这些程序称之为“搜索引擎蜘蛛”或“网络爬虫”。这些勤劳的“蜘蛛”每天在互联网上爬行,从一个链接到另一个链接,下载其中的内容,进行分析提炼,找到其中的关键词,如果“蜘蛛”认为关键词在数据库中没有而对用户是有用的便存入数据库。反之,如果“蜘蛛”认为是垃圾信息或重复信息,就舍弃不要,继续爬行,寻找最新的、有用的信息保存起来提供用户搜索。当用户搜索时,就能检索出与关键字相关的网址显示给访客。
一个关键词对用多个网址,因此就出现了排序的问题,相应的当与关键词最吻合的网址就会排在前面了。在“蜘蛛”抓取网页内容,提炼关键词的这个过程中,就存在一个问题:“蜘蛛”能否看懂。如果网站内容是flash和js,那么它是看不懂的,会犯迷糊,即使关键字再贴切也没用。相应的,如果网站内容是它的语言,那么它便能看懂,它的语言即SEO。
二、SEO简介
全称:Search English Optimization,搜索引擎优化。自从有了搜索引擎,SEO便诞生了。
存在的意义:为了提升网页在搜索引擎自然搜索结果中的收录数量以及排序位置而做的优化行为。简言之,就是希望百度等搜索引擎能多多我们收录精心制作后的网站,并且在别人访问时网站能排在前面。
分类:白帽SEO和黑帽SEO。白帽SEO,起到了改良和规范网站设计的作用,使网站对搜索引擎和用户更加友好,并且网站也能从搜索引擎中获取合理的流量,这是搜索引擎鼓励和支持的。黑帽SEO,利用和放大搜索引擎政策缺陷来获取更多用户的访问量,这类行为大多是欺骗搜索引擎,一般搜索引擎公司是不支持与鼓励的。本文针对白帽SEO,那么白帽SEO能做什么呢?
1. 对网站的标题、关键字、描述精心设置,反映网站的定位,让搜索引擎明白网站是做什么的;
2. 网站内容优化:内容与关键字的对应,增加关键字的密度;
3. 在网站上合理设置Robot.txt文件;
4. 生成针对搜索引擎友好的网站地图;
5. 增加外部链接,到各个网站上宣传;
三、前端SEO
通过网站的结构布局设计和网页代码优化,使前端页面既能让浏览器用户能够看懂,也能让“蜘蛛”看懂。
(1) 网站结构布局优化:尽量简单、开门见山,提倡扁平化结构。
一般而言,建立的网站结构层次越少,越容易被“蜘蛛”抓取,也就容易被收录。一般中小型网站目录结构超过三级,“蜘蛛”便不愿意往下爬,“万一天黑迷路了怎么办”。并且根据相关调查:访客如果经过跳转3次还没找到需要的信息,很可能离开。因此,三层目录结构也是体验的需要。为此我们需要做到:
1. 控制首页链接数量
网站首页是权重最高的地方,如果首页链接太少,没有“桥”,“蜘蛛”不能继续往下爬到内页,直接影响网站收录数量。但是首页链接也不能太多,一旦太多,没有实质性的链接,很容易影响用户体验,也会降低网站首页的权重,收录效果也不好。
因此对于中小型企业网站,建议首页链接在100个以内,链接的性质可以包含页面导航、底部导航、锚文字链接等等,注意链接要建立在用户的良好体验和引导用户获取信息的基础之上。
2.扁平化的目录层次,尽量让“蜘蛛”只要跳转3次,就能到达网站内的任何一个内页。扁平化的目录结构,比如:“植物”–> “水果” –> “苹果”、“桔子”、“香蕉”,通过3级就能找到香蕉了。
3.导航优化
导航应该尽量采用文字方式,也可以搭配图片导航,但是图片代码一定要进行优化,<img>标签必须添加“alt”和“title”属性,告诉搜索引擎导航的定位,做到即使图片未能正常显示时,用户也能看到提示文字。
其次,在每一个网页上应该加上面包屑导航,好处:从用户体验方面来说,可以让用户了解当前所处的位置以及当前页面在整个网站中的位置,帮助用户很快了解网站组织形式,从而形成更好的位置感,同时提供了返回各个页面的接口,方便用户操作;对“蜘蛛”而言,能够清楚的了解网站结构,同时还增加了大量的内部链接,方便抓取,降低跳出率。
4. 网站的结构布局----不可忽略的细节
1)页面头部:logo及主导航,以及用户的信息。
2)页面主体:左边正文,包括面包屑导航及正文;右边放热门文章及相关文章,好处:留住访客,让访客多停留,对“蜘蛛”而言,这些文章属于相关链接,增强了页面相关性,也能增强页面的权重。
3)页面底部:版权信息和友情链接。
特别注意:分页导航写法,推荐写法:“首页 1 2 3 4 5 6 7 8 9 下拉框”,这样“蜘蛛”能够根据相应页码直接跳转,下拉框直接选择页面跳转。而下面的写法是不推荐的,“首页 下一页 尾页”,特别是当分页数量特别多时,“蜘蛛”需要经过很多次往下爬,才能抓取,会很累、会容易放弃。
5.控制页面的大小,减少http请求,提高网站的加载速度。
一个页面最好不要超过100k,太大,页面加载速度慢。当速度很慢时,用户体验不好,留不住访客,并且一旦超时,“蜘蛛”也会离开。
(2) 网页代码优化
1.<title>标题:只强调重点即可,尽量把重要的关键词放在前面,关键词不要重复出现,尽量做到每个页面的<title>标题中不要设置相同的内容。
2.<meta keywords>标签:关键词,列举出几个页面的重要关键字即可,切记过分堆砌。
3.<meta description>标签:网页描述,需要高度概括网页内容,切记不能太长,过分堆砌关键词,每个页面也要有所不同。
4.<body>中的标签:尽量让代码语义化,在适当的位置使用适当的标签,用正确的标签做正确的事。让阅读源码者和“蜘蛛”都一目了然。比如:h1-h6是用于标题类的,<nav>标签是用来设置页面主导航的等。
5.<a>标签:页内链接,要加“title” 属性加以说明,让访客和 “蜘蛛” 知道。而外部链接,链接到其他网站的,则需要加上el="nofollow"属性, 告诉 “蜘蛛” 不要爬,因为一旦“蜘蛛”爬了外部链接之后,就不会再回来了。
6.正文标题要用<h1>标签:“蜘蛛” 认为它最重要,若不喜欢<h1>的默认样式可以通过CSS设置。尽量做到正文标题用<h1>标签,副标题用<h2>标签, 而其它地方不应该随便乱用 h 标题标签。
7.<br>标签:只用于文本内容的换行,比如:
<p>
第一行文字内容<br/>
第二行文字内容<br/>
第三行文字内容
</p>
8.表格应该使用<caption>表格标题标签
9.<img>应使用 “alt” 属性加以说明
10.<strong>、<em>标签 : 需要强调时使用。<strong>标签在搜索引擎中能够得到高度的重视,它能突出关键词,表现重要的内容,<em>标签强调效果仅次于<strong>标签。
<b>、<i>标签: 只是用于显示效果时使用,在SEO中不会起任何效果。
11、文本缩进不要使用特殊符号 应当使用CSS进行设置。版权符号不要使用特殊符号 ©; 可以直接使用输入法,拼“banquan”,选择序号5就能打出版权符号©。
12、巧妙利用CSS布局,将重要内容的HTML代码放在最前面,最前面的内容被认为是最重要的,优先让“蜘蛛”读取,进行内容关键词抓取。
13.重要内容不要用JS输出,因为“蜘蛛”不认识
14.尽量少使用iframe框架,因为“蜘蛛”一般不会读取其中的内容
15.谨慎使用display:none :对于不想显示的文字内容,应当设置z-index或设置到浏览器显示器之外。因为搜索引擎会过滤掉display:none其中的内容。
16. 不断精简代码
17.js代码如果是操作DOM操作,应尽量放在body结束标签之前,html代码之后。
web開發面試題---性能優化及SEO:
https://baijiahao.baidu.com/s?id=1589713089431651995&wfr=spider&for=pc.
web性能優化及SEO:
http://rrd.me/edssf
網址縮短:
http://www.8cc7.com/
SEO優化網站:
http://www.bluecai.com/
web頁面優化以及SEO的更多相关文章
- web语义化之SEO和ARIA
在快速理解web语义化的时候,只知道web语义化有利于SEO和便于屏幕阅读器阅读,但并不知道它是如何有利于SEO和便于阅读器阅读的,带着这个疑问,进行了一番探索总结. SEO 什么是SEO? SEO( ...
- Web缓存和静态化
Web缓存和静态化 目录 Web缓存基础... 1 什么是Web缓存... 1 Web缓存的类型... 1 为何要使用Web缓存... 1 重验证... 1 更新... 2 浏览器缓存... 2 工作 ...
- bzoj 1096: [ZJOI2007]仓库建设 斜率優化
1096: [ZJOI2007]仓库建设 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 2242 Solved: 925[Submit][Statu ...
- 前端web应用的组件化(二) 徐飞
Web应用的组件化(二) https://github.com/xufei/blog/issues/7 管控平台 在上一篇中我们提到了组件化的大致思路,这一篇主要讲述在这么做之后,我们需要哪些外围手段 ...
- Web应用的组件化(二)——管控平台 #7
Web应用的组件化(二) 管控平台 在上一篇中我们提到了组件化的大致思路,这一篇主要讲述在这么做之后,我们需要哪些外围手段去管控整个开发过程.从各种角度看,面对较大规模前端开发团队,都有必要建立这么一 ...
- 一次 C# 查詢數據庫 算法優化的案例
最近有次在修改某段程式時,發現一段程式算法看起來簡單. 但背後因為多次查詢數據庫,導致效能問題. 這段程式主要是利用 EPPLUS 讀取 Excel 資料,檢查資料是否已存在數據庫中,若有就將已存在的 ...
- oracle批量插入優化方案
今天聽DBA説如果從一個表批量查詢出一批數據之後批量插入另外一張表的優化方案: 1)不寫歸檔日誌: 2)採用獨佔 關於insert /*+ append */我們需要注意以下三點: a.非歸檔模式下, ...
- 从徐飞的文章《Web应用的组件化开发(一)中窥视web应用开发的历史
Web应用的组件化开发(一) 原文来自 徐飞 基本思路 1. 为什么要做组件化? 无论前端也好,后端也好,都是整个软件体系的一部分.软件产品也是产品,它的研发过程也必然是有其目的.绝大多数软件产品是追 ...
- UGUI 深度優化提升手遊效能
https://hackmd.io/s/S1z1ByaGb#UGUI-%E6%B7%B1%E5%BA%A6%E5%84%AA%E5%8C%96%E6%8F%90%E5%8D%87%E6%89%8B%E ...
随机推荐
- 三、docker学习笔记——安装postgresql
1.docker pull postgres 2.docker run --name postgres -e POSTGRES_PASSWORD=123456 -p 5432:5432 -d post ...
- Asp.net让某一页设置成gb2312或utf-8的方法
有些需求,一定要用到utf-8格式,在web.config里面设置<globalization requestEncoding="utf-8" ...
- 面向对象编程——parent—this
PHP5 中使用 parent::来引用父类的方法. parent:: 可用于调用父类中定义的成员方法. parent::的追溯不仅于直接父类. PHP5 中为解决变量的命名冲突和不确定性问题,引入关 ...
- 【jQuery】jQuery中的事件捕获与事件冒泡
在介绍之前,先说一下JavaScript中的事件流概念.事件流描述的是从页面中接受事件的顺序. 一.事件冒泡( Event Bubbling) IE 的事件流叫做事件冒泡,即 ...
- leveldb分析——单元测试工具
leveldb中自己实现了一个简单的单元测试工具,下面是一个对CRC类测试的一个例子 class CRC { }; TEST(CRC, Extend) { ASSERT_EQ(Value(), Ext ...
- June 23rd 2017 Week 25th Friday
Life doesn't get easier, you just get stronger. 生活从未变得轻松,是你在一点一点变得坚强. So in the same way we can get ...
- SAP S/4HANA使用ABAP获得生产订单的状态
在S/4HANA里,我们如何根据一个销售订单的行项目,查看对应的生产订单状态? 双击行项目: 点击Schedule line: 这里就能看到生产订单的ID和状态了. 其中订单的状态存储在表vsaufk ...
- java学习第一步,使用IntelliJ IDEA编写自己的第一个java程序
首先下载java的jdk,然后说一下IDEA的配置 IntelliJ IDEA目前公认的最好的java开发工具,不过一般的学校的教学还是使用eclipse来进行java的开发.所以老师一般只会教你如何 ...
- 理解JavaScript中的去抖函数
何为去抖函数?在学习JavaScript去抖函数之前我们需要先弄明白这个概念.很多人都会把去抖跟节流两个概念弄混,但是这两个概念其实是很好理解的. 去抖函数(Debounce Function),是一 ...
- Django应用的打包和应用的安装和卸载
将应用打包需要安装: setuptools 安装和卸载应用需要安装: pip 举例polls是一个应用包. polls文件夹中包含所有有关应用的文件. 打包应用: 首先,在你的Django项目之外,为 ...