第5章 MapReduce操作
本章通过几个案例详细讲解MapReduce程序的编写与运行。
5.1 案例分析:单词计数
假如有这样一个例子,需要统计过去10年计算机论文中出现次数最多的几个单词,以分析当前的热点研究议题是什么。那么,在将论文样本收集完毕之后,接下来应该怎样做呢?
这一经典的单词计数案例可以采用MapReduce处理。MapReduce中已经自带了一个单词计数程序WordCount,如同Java中的经典程序“Hello World”一样,WordCount是MapReduce中统计单词出现次数的Java类,是MapReduce的入门程序。该程序要求计算出文件中单词的出现次数,并将输出结果输出到HDFS文件系统中,且按照单词的字母顺序进行排序,每个单词和其出现次数占一行,单词与出现次之间有间隔。
例如,输入内容如下的文件:
hello world
hello hadoop
bye hadoop
其符合要求的输出结果如下:
bye 1
hadoop 2
hello 2
world 1
下面进一步对上述WordCount程序进行分析。
1.设计思路
WordCount对于单词计数问题的解决方案很直接:先将文件内容切分成单词,然后将所有相同的单词聚集到一起,最后计算各个单词出现的次数,将计算结果排序输出。
根据MapReduce并行设计的原则可知:解决方案中的内容切分步骤和内容不相关,可以并行化处理,每个拿到原始数据的节点只需要将输入数据切分成单词就可以了,因此可由Mapping阶段完成单词切分的任务;另外,不同单词之间的频数也不相关,所以对相同单词频数的计算也可以并行化处理,将相同的单词交由同一节点来计算频数,然后输出最终结果,该任务可由Reduce阶段完成;至于将Mapping阶段的输出结果根据不同单词进行分组,然后再发送给Reduce节点的任务,可由MapReduce中的Shuffle阶段完成。
由于MapReduce中传递的数据都是键值对形式的,而且Shuffle的排序、聚集和分发也是按照键值进行的,因此,可将Map的输出结果设置为以单词作为键,1作为值的形式,表示某单词出现了1次(输入Map的数据则采用Hadoop默认的输入格式,即文件的一行作为值,行号作为键)。由于Reduce的输入是Map的输出聚集后的结果,因此格式为<key, value-list>,也就是<word, {1,1,1,1,…}>;Reduce的输出则可由设置成与Map输出相同的形式,只是后面的数值不再是固定的1,而是具体计算出的某单词所对应的频数。
WordCount程序的执行流程如下图:
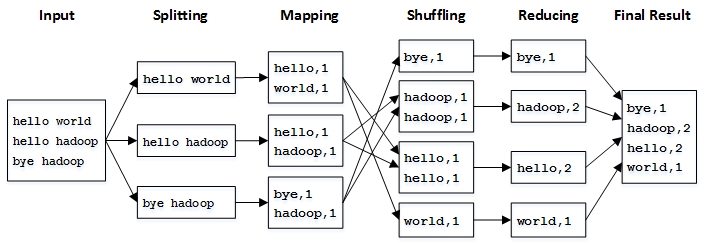
2.程序源代码
WordCount程序类的源代码如下所示:
import java.io.IOException;
import java.io.PrintStream;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount
{
public static void main(String[] args)
throws Exception
{
//初始化Configuration类
Configuration conf = new Configuration();
//通过实例化对象GenericOptionsParser可以获得程序执行所传入的参数
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
//构建任务对象
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
//设置输出结果的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; i++) {
//设置需要统计的文件的输入路径
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
//设置统计结果的输出路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[(otherArgs.length - 1)]));
//提交任务给Hadoop集群
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException
{
//统计单词总数
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
this.result.set(sum);
//输出统计结果
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException
{
//默认根据空格分割字符串
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {//循环输出每个单词与数量
this.word.set(itr.nextToken());
//输出单词与数量
context.write(this.word, one);
}
}
}
}
3.程序解读
main函数中的job.setCombinerClass(IntSumReducer.class);指定了Map规约的类,也可以不使用Reduce类而进行自定义。这里的规约combine的含义是,将Map结果进行一次本地的reduce操作,从而减轻远程reduce的压力。例如,Map阶段有只是把两个相同的hello进行规约,由此输入给reduce的就变成了<hello,2>。在实际的Hadoop集群操作中,我们是由多台主机一起进行MapReduce的,如果加入规约操作,每一台主机会在reduce之前进行一次对本机数据的规约,然后在通过集群进行reduce操作,这样就会大大节省reduce的时间,从而加快MapReduce的处理速度。
4.程序运行
下面以统计Hadoop安装目录下的LICENSE.txt文件中的单词频数为例,讲解如何运行上述单词计数程序WordCount,操作步骤如下:
(1)执行以下命令,在HDFS根目录下创建文件目录input:
hadoop fs –mkdir /input
(2)进入Hadoop安装目录,找到文件LICENSE.txt,然后执行以下命令,将其放到HDFS的/input目录下:
hadoop fs –put LICENSE.txt /input
(3)执行以下命令,运行Hadoop自带的WordCount程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input /output
需要注意的是,HDFS根目录不应存在文件夹output,程序会自动创建。若存在则会报错。
若输出以下信息,表示程序运行正常:
16/09/05 22:51:27 INFO mapred.LocalJobRunner: reduce > reduce
16/09/05 22:51:27 INFO mapred.Task: Task 'attempt_local1035441982_0001_r_000000_0' done.
16/09/05 22:51:27 INFO mapred.LocalJobRunner: Finishing task: attempt_local1035441982_0001_r_000000_0
16/09/05 22:51:27 INFO mapred.LocalJobRunner: reduce task executor complete.
16/09/05 22:51:28 INFO mapreduce.Job: map 100% reduce 100%
16/09/05 22:51:28 INFO mapreduce.Job: Job job_local1035441982_0001 completed successfully
16/09/05 22:51:28 INFO mapreduce.Job: Counters: 35
File System Counters
FILE: Number of bytes read=569202
FILE: Number of bytes written=1134222
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=30858
HDFS: Number of bytes written=8006
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Map-Reduce Framework
Map input records=289
Map output records=2157
Map output bytes=22735
Map output materialized bytes=10992
Input split bytes=104
Combine input records=2157
Combine output records=755
Reduce input groups=755
Reduce shuffle bytes=10992
Reduce input records=755
Reduce output records=755
Spilled Records=1510
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=221
Total committed heap usage (bytes)=242360320
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=15429
File Output Format Counters
Bytes Written=8006
(4)程序运行的结果以文件的形式存放在HDFS的/output目录下,执行以下命令,可以将运行结果下载到本地查看:
hadoop fs –get hdfs:/output
5.2 案例分析:数据去重
数据去重是通过并行化思想来对数据进行有意义的筛选。许多看似庞杂的任务,如统计大数据集上的数据种类个数、从网站日志中计算访问地点等都会涉及数据去重。
本例中,已知有两个文件file1.txt和file2.txt,需要对这两个文件中的数据进行合并去重,文件中的每行是一个整体。
file1.txt的内容如下:
2017-3-1 a
2017-3-2 b
2017-3-3 c
2017-3-4 d
2017-3-5 a
2017-3-6 b
2017-3-7 c
2017-3-3 c
file2.txt的内容如下:
2017-3-1 b
2017-3-2 a
2017-3-3 b
2017-3-4 d
2017-3-5 a
2017-3-6 c
2017-3-7 d
2017-3-3 c
期望的输出结果:
2017-3-1 a
2017-3-1 b
2017-3-2 a
2017-3-2 b
2017-3-3 b
2017-3-3 c
2017-3-4 d
2017-3-5 a
2017-3-6 b
2017-3-6 c
2017-3-7 c
2017-3-7 d
1.设计思路
数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。本例中,每个数据代表输入文件中的一行内容。采用Hadoop默认输入方式输入到Map的键值对<key,value>中,key是数据所在文件的位置下标,value是数据的内容。而Map阶段的任务就是将接收到的value设置为key,并直接输出(输出数据中的value任意)。Map输出的键值对经过Shuffle过程会聚集成<key,value- list>后交给Reduce,此时所有的key实际上已经做了去重处理。因此,在Reduce阶段,当Reduce接收到一个<key,value- list>时,不用管每个key有多少个value,直接将其中的key复制到输出的key中,并将value设置成空值,就可以得到数据去重的结果。
2.编写程序
在eclipse中新建一个Maven项目,在项目的pom.xml文件中加入项目的Hadoop依赖库,代码如下:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
然后,在项目中新建包com.hadoop.mr,并在包中写入数据去重的程序代码:
public class Dedup {
//map将输入中的value复制到输出数据的key上,并直接输出
public static class Map extends Mapper<Object,Text,Text,Text>{
private static Text line=new Text();//每行数据
//实现map函数
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
line=value;
context.write(line, new Text(""));
}
}
//reduce将输入中的key复制到输出数据的key上,并直接输出
public static class Reduce extends Reducer<Text,Text,Text,Text>{
//实现reduce函数
public void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = new Job(conf, "Data Deduplication");
job.setJarByClass(Dedup.class);
// 设置Map、Combine(规约)和Reduce处理类
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path("/input/"));
FileOutputFormat.setOutputPath(job, new Path("/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3.程序解读
上述程序中,程序的map函数将接收到的键值对中的value直接赋给了函数输出键值对中的key,而输出的value则被置为了空字符串。程序的reduce函数将接收到的键值对数据中的key直接作为函数输出键值对中的key,而输出的value则置为了空字符串。
4.程序运行
该程序需要在Hadoop集群环境下运行,步骤如下:
(1)在eclipse中将完成的MapReduce项目导出为jar包,命名为Dedup.jar,然后上传到Hadoop服务器的相应位置。本例将其上传到Hadoop的安装目录下。
(2)在HDFS根目录下创建input文件夹,命令如下:
hadoop fs –mkdir /input
(3)将准备好的示例文件file1.txt和file2.txt使用SSH工具上传到Hadoop安装目录下,并进入Hadoop安装目录,执行以下命令,将示例文件上传到HDFS中新建的/input目录下:
hadoop fs –put file1.txt /input
hadoop fs –put file2.txt /input
(4)在Hadoop安装目录中,执行以下命令,运行写好的MapReduce数据去重程序:
hadoop jar Dedup.jar com.hadoop.mr.Dedup
(5)程序运行完毕后,会在HDFS的根目录下生成output目录,并在output目录中生成part-r-00000文件,程序执行结果即存放于此文件中。可以执行以下命令,查看程序执行结果:
hadoop fs –cat /output/*
如果能正确显示预期结果,则表明程序编写无误。
5.3 案例分析:求平均分
本例通过对输入文件中的学生三科成绩进行计算,得出每个学生的平均成绩。输入文件中的每行内容均为一个学生的姓名和他相应的成绩,每门学科为一个文件。要求在输出中每行有两个数据,其中,第一个代表学生的姓名,第二个代表其平均成绩。
输入文件内容如下:
math.txt:
张三 88
李四 99
王五 66
赵六 77
chinese.txt:
张三 78
李四 89
王五 96
赵六 67
english.txt:
张三 80
李四 82
王五 84
赵六 86
期望输出结果如下:
张三 82
李四 90
王五 82
赵六 76
1.设计思路
我们都知道,Mapper最终处理的结果对<key,value>,会送到Reducer中进行合并,合并的时候,有相同key的<key,value>对则送到同一个 Reducer上。Reducer是所有用户定制Reducer类地基础,它的输入是key和这个key对应的所有value的一个迭代器,同时还有 Reducer的上下文。Reduce的结果由Reducer.Context的write方法输出到文件中。
MapReduce经典的WordCount(单词计数)例子是将接收到的每一个value-list进行求和,进而得到所需的结果。而本例中,我们将reduce阶段接收到的value-list进行求平均分后,作为reduce要输出的value值即可,reduce要输出的key值仍然为接收到的key。
整个求平均分的流程如下图:
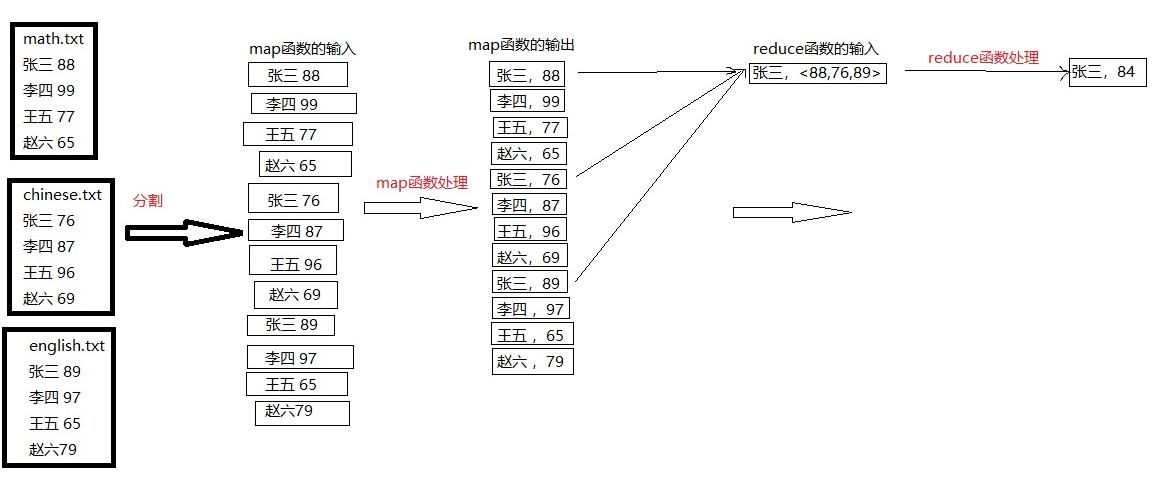
2.程序源码
项目的新建及jar包的引入见上方的数据去重案例。
完整程序源代码如下:
public class Score {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
// 实现map函数
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将输入的一行数据,处理中文乱码后转化成String
String line=new String(value.getBytes(),0,value.getLength(),"GBK");
// 将输入的一行数据首先按空格进行分割
StringTokenizer itr = new StringTokenizer(line);
// 获取分割后的字符串
String strName = itr.nextToken();// 学生姓名部分
String strScore = itr.nextToken();// 成绩部分
Text name = new Text(strName);
int scoreInt = Integer.parseInt(strScore);
// 输出姓名和成绩
context.write(name, new IntWritable(scoreInt));
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
// 实现reduce函数
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
sum += iterator.next().get();// 计算总分
count++;// 统计总的科目数
}
int average = (int) sum / count;// 计算平均成绩
//输出姓名和平均成绩
context.write(key, new IntWritable(average));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "Score Average");
job.setJarByClass(Score.class);
// 设置Map、Combine和Reduce处理类
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 将输入的数据集分割成小数据块splites,提供一个RecordReder的实现
job.setInputFormatClass(TextInputFormat.class);
// 提供一个RecordWriter的实现,负责数据输出
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path("/input/"));
FileOutputFormat.setOutputPath(job, new Path("/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
注意的问题:
Hadoop在涉及编码时默认使用的是UTF-8,如果文件编码格式是其它类型(如GBK),则会出现乱码。此时只需在mapper或reducer程序中读取Text时,进行一下转码,确保都是以UTF-8的编码方式在运行即可。转码的核心代码如下:
String line=new String(value.getBytes(),0,value.getLength(),"GBK");
若直接以String line=value.toString(); 进行转码也会输出乱码,原因是由Text这个Writable类型造成的。虽然Text是String的Writable类的封装,但它俩还是有区别的。Text是一种UTF-8格式的Writable,而Java中的String是Unicode字符。所以直接使用value.toString会默认其中的字符都是UTF-8编码过的,因而GBK编码的数据直接使用该方法就会变成乱码。
原创文章,转载请注明出处!!
第5章 MapReduce操作的更多相关文章
- Hbase第五章 MapReduce操作HBase
容易遇到的坑: 当用mapReducer操作HBase时,运行jar包的过程中如果遇到 java.lang.NoClassDefFoundError 类似的错误时,一般是由于hadoop环境没有hba ...
- Java中的函数式编程(七)流Stream的Map-Reduce操作
写在前面 Stream 的 Map-Reduce 操作是Java 函数式编程的精华所在,同时也是最为复杂的部分.但一旦你啃下了这块硬骨头,那你就真正熟悉Java的函数式编程了. 如果你有大数据的编程经 ...
- 第四章 JavaScript操作DOM对象
第四章 JavaScript操作DOM对象 一.DOM操作 DOM是Document Object Model的缩写,即文档对象模型,是基于文档编程的一套API接口,1988年,W3C发布了第一级 ...
- 第三章 JavaScript操作BOM对象
第三章 JavaScript操作BOM对象 一.window对象 浏览器对象模型(BOM)是javascript的组成之一,它提供了独立与浏览器窗口进行交换的对象,使用浏览器对象模型可以实现与HT ...
- Mapreduce操作HBase
这个操作和普通的Mapreduce还不太一样,比如普通的Mapreduce输入可以是txt文件等,Mapreduce可以直接读取Hive中的表的数据(能够看见是以类似txt文件形式),但Mapredu ...
- HBase 相关API操练(三):MapReduce操作HBase
MapReduce 操作 HBase 在 HBase 系统上运行批处理运算,最方便和实用的模型依然是 MapReduce,如下图所示. HBase Table 和 Region 的关系类似 HDFS ...
- 7.MapReduce操作Hbase
7 HBase的MapReduce HBase中Table和Region的关系,有些类似HDFS中File和Block的关系.由于HBase提供了配套的与MapReduce进行交互的API如 Ta ...
- 第2章:MapReduce
MapReduce是一个数据处理的编程模型.这个模型很简单,但也不是简单到不能够支持一些有用的语言.Hadoop能够运行以多种语言写成的MapReduce程序.在这一章中,我们将看看怎样用Java,R ...
- Hbase理论&&hbase shell&&python操作hbase&&python通过mapreduce操作hbase
一.Hbase搭建: 二.理论知识介绍: 1Hbase介绍: Hbase是分布式.面向列的开源数据库(其实准确的说是面向列族).HDFS为Hbase提供可靠的底层数据存储服务,MapReduce为Hb ...
随机推荐
- SQL点点滴滴_查询类型和索引-转载
当您考虑是否要对列创建索引时, 请估计在查询中使用列的方式, 下表介绍了索引对其有用的查询类型. 表中的示例基于 AdventureWorks2008R2 示例数据库, 在 SQL Server Ma ...
- Java学习笔记——关于位运算符的问题
我就之直接贴图了!不想排版了! 有什么问题,欢迎大家指出,帮助我提高,谢谢!
- UnicodeDecodeError: 'utf8' codec can't decode byte in position invalid start byte
在scrapy项目中,由于编码问题,下载的网页中中文都是utf-8编码,在Pipeline.py中方法process_item将结果保存到数据库中时,提示UnicodeDecodeError: 'ut ...
- CVE-2015-1642 POC
月初,玄武实验室的“每日安全动态”推送了一篇office UAF漏洞利用的文章,之前对office上UAF漏洞利用占位问题有些疑问,刚好就借助这篇文章重现了一下.其中堆喷射部分不是特别稳定,漏洞成因和 ...
- 解决zabbix3.4X图形页面中文乱码
解决zabbix3.4X页面中文乱码 1.在windows的C:\Windows\Fonts找到字体文件simkai.ttf2.在zabbix服务器上找到zabbix默认字体文件graphfont.t ...
- java里面list是引用的好例子
java里面的赋值和引用是不同的,以后要详细总结一下! 看一个例子: public static void main(String[] args) { List<String> list ...
- 树莓派(Raspberry Pi)上手小记
引言 本日志中有不少软广告,博主并没有收他们任何好处,完全是给想入手的小伙伴们指条路而已.不喜勿看,不喜勿闻,不喜勿喷. 介绍 之前两三个月突然听说了这么个东西,也没有留意,某天突然在一个微信公众号上 ...
- 【转】Impala安装json解析udf插件
背景 Impala跟Hive一样,是常用的数据仓库组件之一.熟悉Hive的同学肯定知道,Hive官方提供了get_json_object函数用于处理json字符串,但是Impala官方并没有提供类似的 ...
- 牛客网多校训练第三场 A - PACM Team(01背包变形 + 记录方案)
链接: https://www.nowcoder.com/acm/contest/141/A 题意: 有n(1≤n≤36)个物品,每个物品有四种代价pi,ai,ci,mi,价值为gi(0≤pi,ai, ...
- UVa 12169 - Disgruntled Judge(拓展欧几里德)
链接: https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...