HDFS原理
1 . NameNode 概述
a、 NameNode 是 HDFS 的核心。
b、 NameNode 也称为 Master。
c、 NameNode 仅存储 HDFS 的元数据:文件系统中所有文件的目录树,并跟踪整个集群中的文件。
d、 NameNode 不存储实际数据或数据集。数据本身实际存储在 DataNodes 中。
e、 NameNode 知道 HDFS 中任何给定文件的块列表及其位置。使用此信息NameNode 知道如何从块中构建文件。
f、 NameNode 并不持久化存储每个文件中各个块所在的 DataNode 的位置信息,这些信息会在系统启动时从数据节点重建。
g、 NameNode 对于 HDFS 至关重要,当 NameNode 关闭时,HDFS / Hadoop 集群无法访问。
h、 NameNode 是 Hadoop 集群中的单点故障。
i、 NameNode 所在机器通常会配置有大量内存(RAM)。

2 . DataNode 概述
a、 DataNode 负责将实际数据存储在 HDFS 中。
b、 DataNode 也称为 Slave。
c、 NameNode 和 DataNode 会保持不断通信。
d、 DataNode 启动时,它将自己发布到 NameNode 并汇报自己负责持有的块列表。
e、 当某个 DataNode 关闭时,它不会影响数据或群集的可用性。NameNode 将安排由其他 DataNode 管理的块进行副本复制。
f、 DataNode 所在机器通常配置有大量的硬盘空间。因为实际数据存储在DataNode 中。
g、 DataNode 会定期(dfs.heartbeat.interval 配置项配置,默认是 3 秒)向NameNode 发送心跳,如果 NameNode 长时间没有接受到 DataNode 发送的心跳, NameNode 就会认为该 DataNode 失效。
h、 block 汇报时间间隔取参数 dfs.blockreport.intervalMsec,参数未配置的话默认为 6 小时.
3 . HDFS的工作机制
NameNode 负责管理整个文件系统元数据;DataNode 负责管理具体文件数据块存储;Secondary NameNode 协助 NameNode 进行元数据的备份。
HDFS 的内部工作机制对客户端保持透明,客户端请求访问 HDFS 都是通过向NameNode 申请来进行。
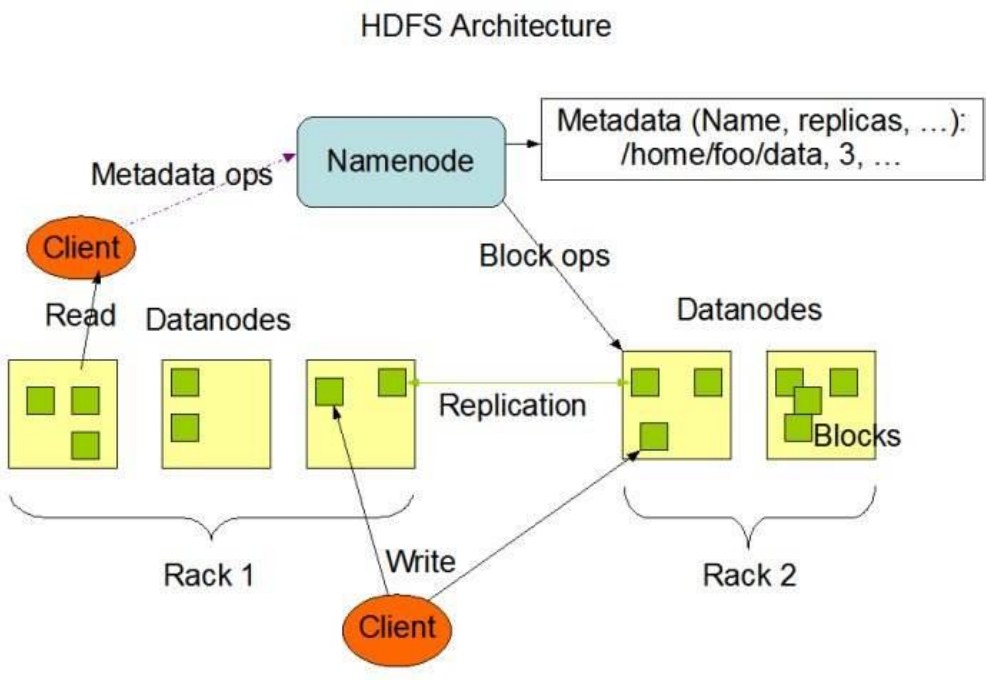
3.1 . HDFS 写数据流程
详细步骤解析:
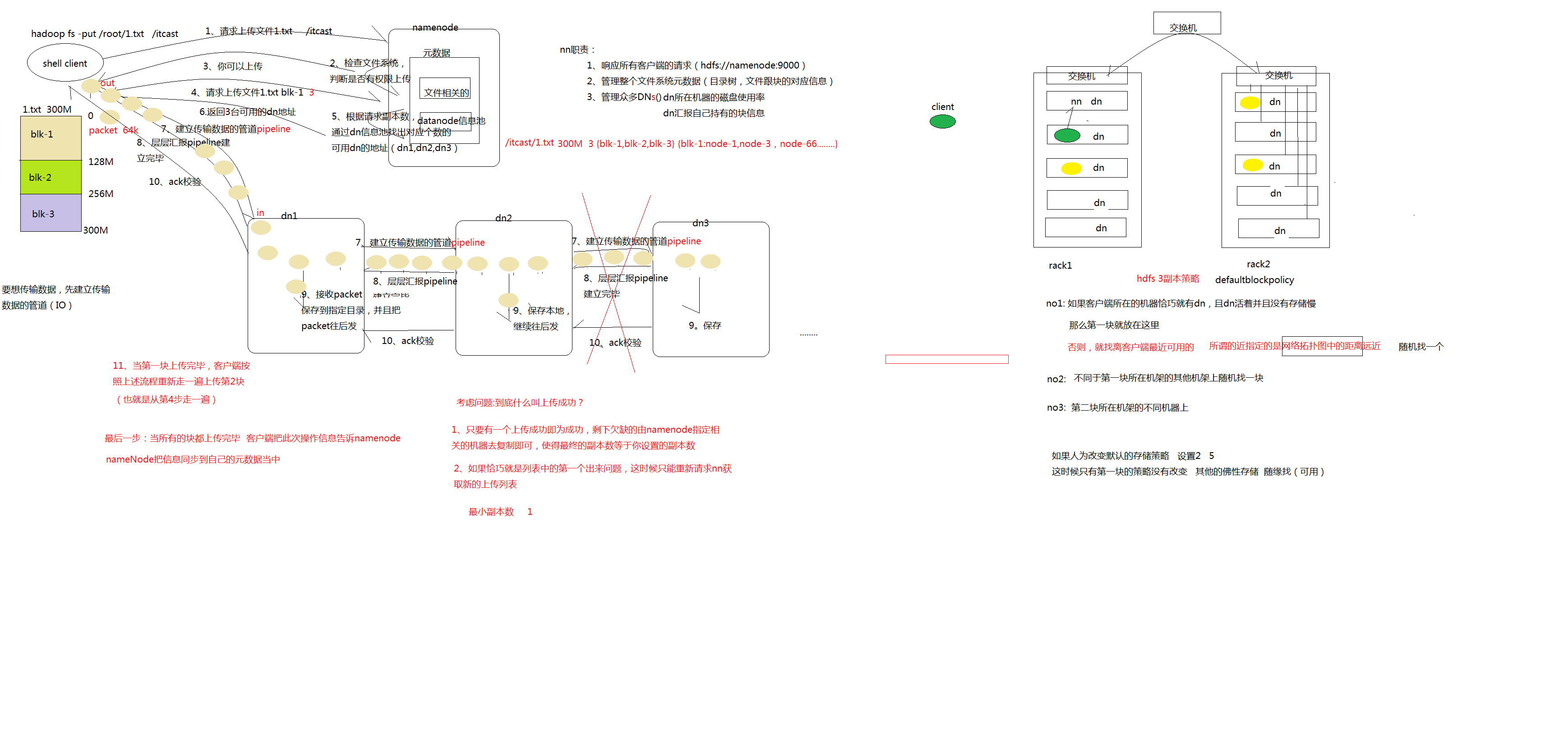
1、 client 发起文件上传请求,通过 RPC 与 NameNode 建立通讯,NameNode检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
2、 client 请求第一个 block 该传输到哪些 DataNode 服务器上;
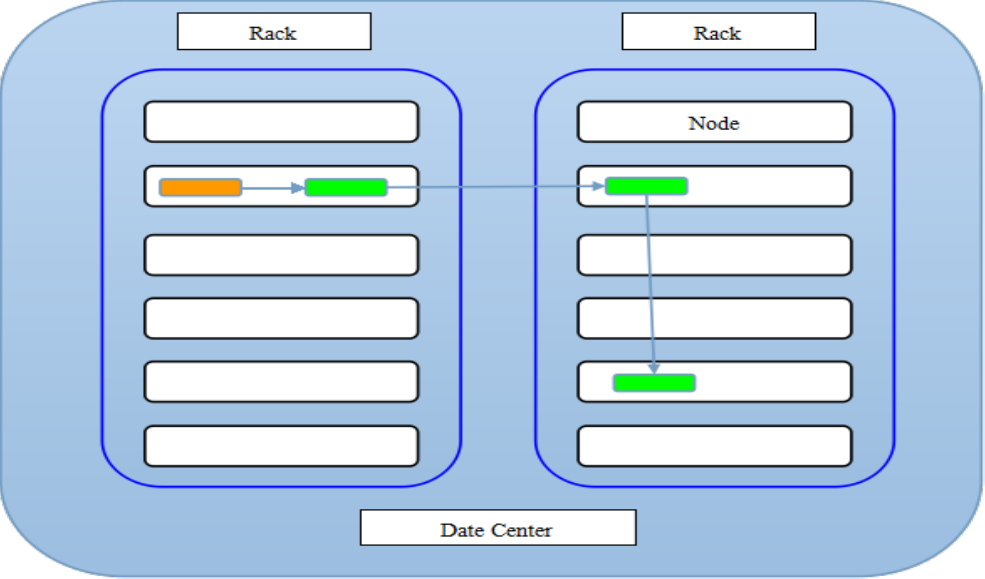
3、 NameNode 根据配置文件中指定的备份数量及副本放置策略进行文件分配,返回可用的 DataNode 的地址,如:A,B,C;
注:默认存储策略由 BlockPlacementPolicyDefault 类支持。也就是日常生活中提到最经典的 3 副本策略 。
1st replica 如果写请求方所在机器是其中一个 datanode,则直接存放在本地,否则随机在集群中选择一个 datanode.
2nd replica 第二个副本存放于不同第一个副本的所在的机架.
3rd replica 第三个副本存放于第二个副本所在的机架,但是属于不同的节点
4、 client 请求 3 台 DataNode 中的一台 A 上传数据(本质上是一个 RPC 调用,建立 pipeline),A 收到请求会继续调用 B,然后 B 调用 C,将整个pipeline 建立完成,后逐级返回 client;
5、 client 开始往 A 上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),以 packet 为单位(默认 64K),A 收到一个 packet 就会传给 B,B 传给 C;A 每传一个 packet 会放入一个应答队列等待应答。
6、 数据被分割成一个个 packet 数据包在 pipeline 上依次传输,在pipeline 反方向上,逐个发送 ack(命令正确应答),最终由 pipeline中第一个 DataNode 节点 A 将 pipeline ack 发送给 client;
7、 当一个 block 传输完成之后,client 再次请求 NameNode 上传第二个block 到服务器。
详细步骤图:
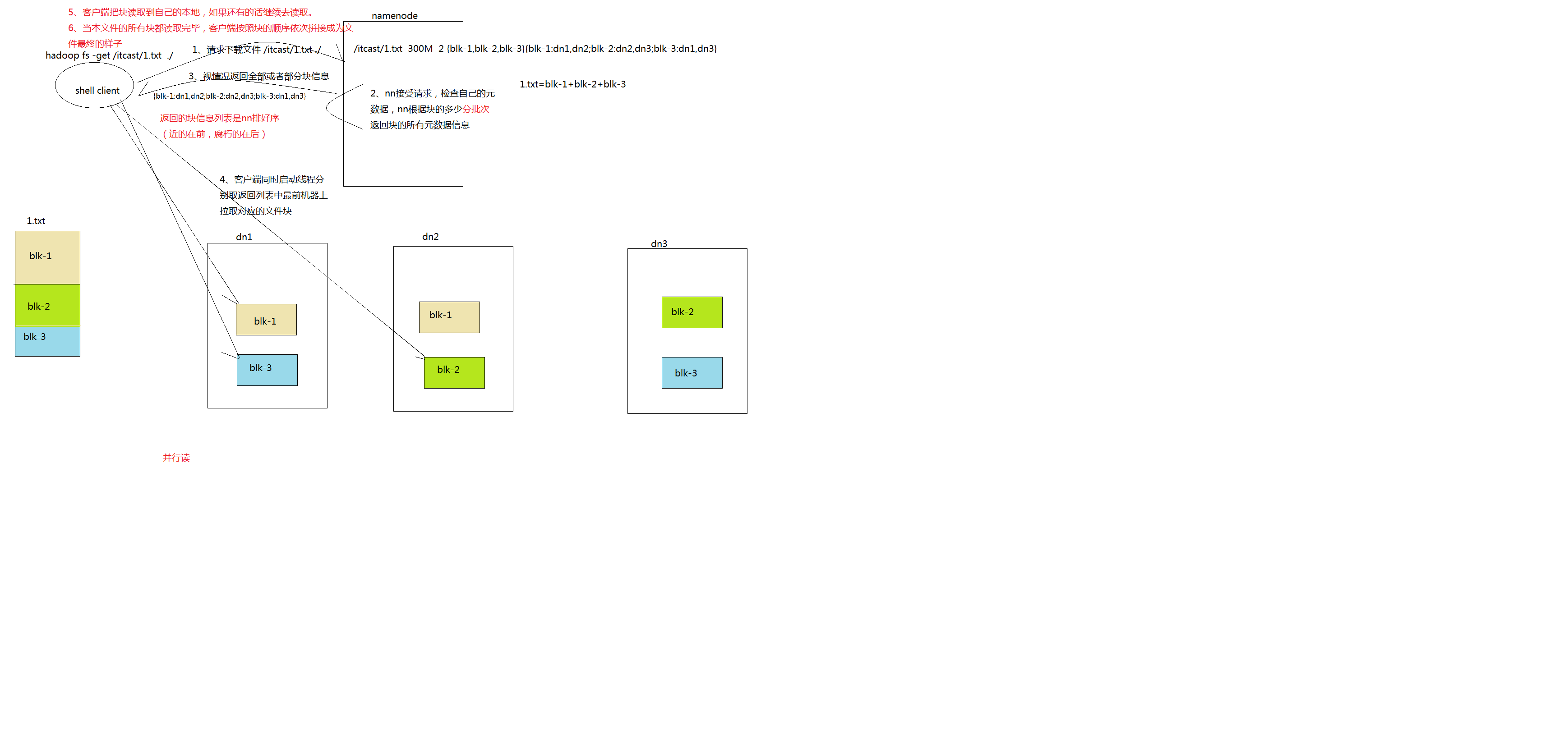
3.2 . HDFS 读数据流程
详细步骤解析:
1、 Client 向 NameNode 发起 RPC 请求,来确定请求文件 block 所在的位置;
2、 NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode 都会返回含有该 block 副本的 DataNode 地址;
3、 这些返回的 DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
4、 Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是DataNode,那么将从本地直接获取数据;
5、 底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
6、 当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
7、 读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
8、 read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据;
9、 最终读取来所有的 block 会合并成一个完整的最终文件。
详细步骤图:
HDFS原理的更多相关文章
- HDFS原理介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Googl ...
- HDFS 原理、架构与特性介绍--转载
原文地址:http://www.uml.org.cn/sjjm/201309044.asp 本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前H ...
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- 【Hadoop】HDFS原理、元数据管理
1.HDFS原理 2.元数据管理原理
- HDFS 原理、架构与特性介绍
本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前HDFS架构详尽分析 HDFS架构 •NameNode •DataNode •Senc ...
- HDFS原理及操作
1 环境说明 部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放 Hadoop等组件运行包.因为该目录用于安装had ...
- hadoop学习之HDFS原理
HDFS原理 HDFS包括三个组件: NameNode.DataNode.SecondaryNameNode NameNode的作用是存储元数据(文件名.创建时间.大小.权限.与block块映射关系等 ...
- 读Hadoop3.2源码,深入了解java调用HDFS的常用操作和HDFS原理
本文将通过一个演示工程来快速上手java调用HDFS的常见操作.接下来以创建文件为例,通过阅读HDFS的源码,一步步展开HDFS相关原理.理论知识的说明. 说明:本文档基于最新版本Hadoop3.2. ...
- 【转载】经典漫画讲解HDFS原理
分布式文件系统比较出名的有HDFS 和 GFS,其中HDFS比较简单一点.本文是一篇描述非常简洁易懂的漫画形式讲解HDFS的原理.比一般PPT要通俗易懂很多.不难得的学习资料. 1.三个部分: 客户 ...
随机推荐
- python StringIO&BytesIO
StringIO StringIO就是在内存中读写str 要把str写入StringIO,先创建一个StringIO >>> from io import StringIO>& ...
- vbs notepad输入中文字符
结合网上的写法,总结了一下 Set wshobj=WScript.CreateObject("WScript.Shell") #code就是想输入的中文或中英文的结合code=&q ...
- C# 时间格式(血淋淋的教训啊。。。)
今天做项目是,调用其他项目的接口,需要传递时间及包含时间的一些其他参数的签名.总是返回时间格式粗误. 我的时间格式为:var CallTime = DateTime.Now.ToString(&quo ...
- mem系函数总结
memset(); 原型: void *memset(void *s, int ch, size_t n); 含义: 将s所指向的某一块内存中的每个字节的内容全部设置为ch指定的ASCII值,块的 ...
- 深入理解PHP传参原理(PHP5.2)
首先说下今天想到的一个问题.在编写php扩展的时候,似乎参数(即传给zend_parse_parameters的变量)是不需要free的.举例: PHP_FUNCTION(test) { char* ...
- Java关于日期时间的工具类
import java.sql.Timestamp; import java.text.ParseException; import java.text.ParsePosition; import j ...
- Oracle中序列的操作以及使用前对序列的初始化
Oracle中序列的操作以及使用前对序列的初始化 一 创建序列 create sequence myseq start with 1 increment by 1 nomaxvalue minva ...
- Windows彻底卸载系统自带的office
由于自带office导致按照新的office会提示要先卸载原来32位的office,又在控制面板或软件管理工具中找不到office,用如下方法删除 1.在C盘删除office文件夹 2.删除注册表 1 ...
- PHP------Jquery的用法
Jquery Jquery实际上相当于一个升级版的JS,Jquery里面封装了很多的东西,Jquery的功能要比JS强大,用起来比JS方便.Jquery和JS都属于JS,只不过Jquery是封装了一个 ...
- Mac安装composer爬过的坑
1.首先安装brew/usr/bin/ruby -e "$(curl -fsSLhttps://raw.githubusercontent.com/Homebrew/install/mast ...