大数据学习之Hadoop环境搭建
一、Hadoop的优势
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3) 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
二、Hadoop组成
1)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
2)Hadoop MapReduce:一个分布式的离线并行计算框架。
3)Hadoop YARN:作业调度与集群资源管理的框架。
4)Hadoop Common:支持其他模块的工具模块。
2.1 HDFS(Hadoop Distributed File System)架构概述
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
2.2 YARN架构概述
1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
2.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
三、Hadoop环境搭建
1 虚拟机网络模式设置为NAT

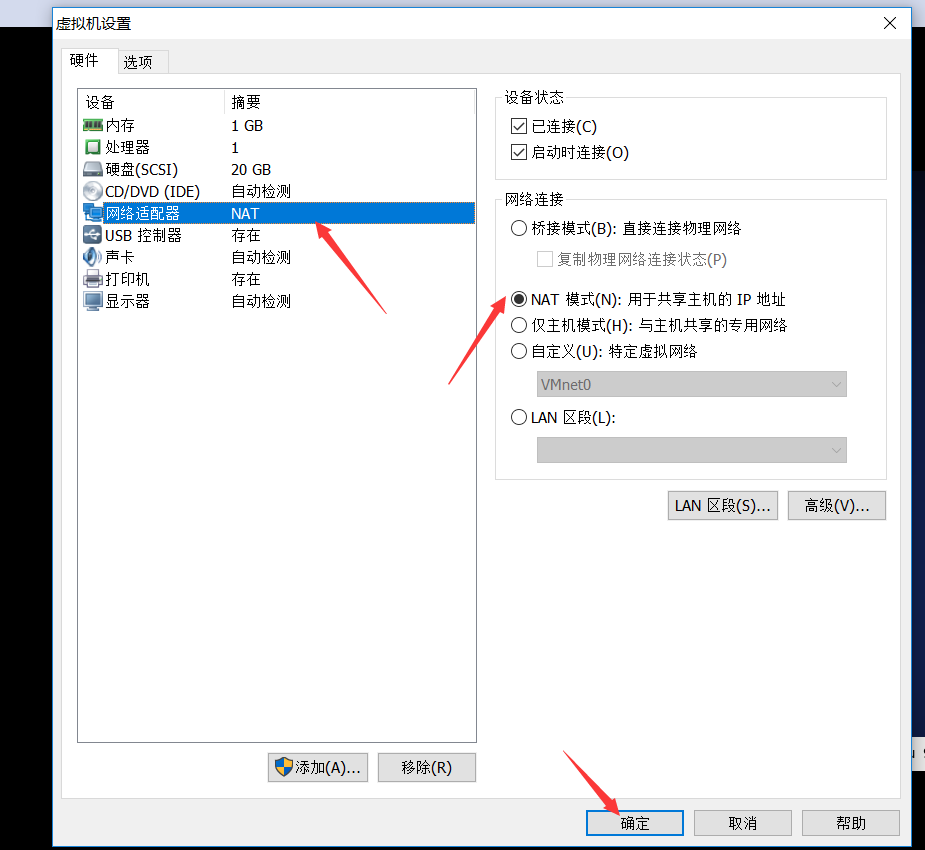
最后,重新启动系统。
2.修改为静态ip
1)使用命令 vim /etc/sysconfig/network-scripts/ifcfg-eth0
2)修改选项有五项:
IPADDR=192.168.110.61
GATEWAY=192.168.110.2
ONBOOT=yes
BOOTPROTO=static
DNS1=192.168.110.2
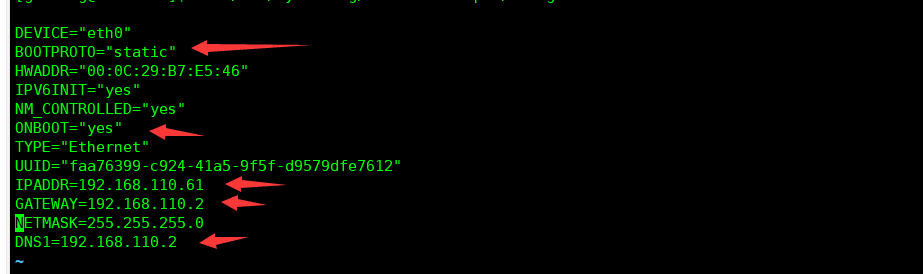
修改完成后保存退出(:wq )
3)执行service network restart
4)如果报错,reboot,重启虚拟机
3.修改主机名
1)修改linux的hosts文件
(1)进入Linux系统查看本机的主机名。通过hostname命令查看

(2)如果感觉此主机名不合适,我们可以进行修改。通过编辑/etc/sysconfig/network文件

(3)修改后保存退出
(4)编辑
vim /etc/hosts

(5)并重启设备,重启后,查看主机名,已经修改成功
4.关闭防火墙
1)查看防火墙开机启动状态
chkconfig iptables --list
2)关闭防火墙
chkconfig iptables off
5.安装jdk
1)卸载现有jdk
(1)查询安装jdk的版本:
java -version
(2)查询是否安装java软件:
rpm -qa|grep java
(3)如果安装的版本低于1.7,卸载该jdk:
rpm -e 软件包
2)用filezilla工具将jdk导入到usr目录下面的java文件夹下面
3)在linux系统下的usr目录中查看软件包是否导入成功(使用.gz包或者.rpm包,本处使用.rpm包)。

4).gz包使用命令 tar -zxf jdk***.gz 解压到当前目录; .rpm包使用命令 rpm -ivh jdk***.rpm 进行安装.
5)配置jdk环境变量
(1) 先获取jdk路径:使用命令pwd

(2)打开/etc/profile文件:
vi /etc/profile
在profie文件末尾添加jdk路径:
#set java environment
JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
JRE_HOME=/usr/java/jdk1.8.0_171-amd64/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
(3)保存后退出:
:wq
(4)让修改后的文件生效:

6)重启(如果java –version可以用就不用重启):
7) 测试jdk安装成功

四、安装Hadoop
1)通过用filezilla工具将Hadoop导入/usr/local/src/中,官方下载地址:http://mirrors.shu.edu.cn/apache/hadoop/common/

2)解压安装文件 tar -zxf hadoop-2.7.6.tar.gz
3)配置hadoop中的hadoop-env.sh
(1)Linux系统中获取jdk的安装路径:

(2)进入 hadoop-2.7.6/etc/hadoop/中 ,修改hadoop-env.sh文件中JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.7.0_79
4)将hadoop添加到环境变量
(1)获取hadoop安装路径:

(2)打开/etc/profile文件:
在profie文件末尾添加hadoop路径:
#HADOOP_HOME
export HADOOP_HOME=/usr/local/src/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(3)保存后退出:
:wq
(4)让修改后的文件生效:

(5)使用hadoop查看是否安装成功,如果hadoop命令不能使用则重启再查看。
大数据学习之Hadoop环境搭建的更多相关文章
- 大数据之路- Hadoop环境搭建(Linux)
前期部署 1.JDK 2.上传HADOOP安装包 2.1官网:http://hadoop.apache.org/ 2.2下载hadoop-2.6.1的这个tar.gz文件,官网: https://ar ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 《OD大数据实战》Hue环境搭建
官网: http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6/ 一.Hue环境搭建 1. 下载 http://archive.cloude ...
- 大数据学习笔记——Hadoop编程之SequenceFile
SequenceFile(Hadoop序列文件)基础知识与应用 上篇编程实战系列中本人介绍了基本的使用HDFS进行文件读写的方法,这一篇将承接上篇重点整理一下SequenceFile的相关知识及应用 ...
- 大数据学习笔记——Hadoop高可用完全分布式模式完整部署教程(包含zookeeper)
高可用模式下的Hadoop集群搭建 本篇博客将会在之前写过的Linux的完整部署的基础上进行,暂时不会涉及到伪分布式或者完全分布式模式搭建,由于HA模式涉及到的配置文件较多,维护起来也较为复杂,相信学 ...
- 《OD大数据实战》MongoDB环境搭建
一.MongonDB环境搭建 1. 下载 https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.6.tgz 2. 解压 tar -zxvf ...
- 《OD大数据实战》HBase环境搭建
一.环境搭建 1. 下载 hbase-0.98.6-cdh5.3.6.tar.gz 2. 解压 tar -zxvf hbase-0.98.6-cdh5.3.6.tar.gz -C /opt/modul ...
随机推荐
- win+ R下的常见命令
-------------------------电脑运行常见命令----------------------------- Windows+R输入cmd 运行net start mssqlserve ...
- SqlParameter.Value = NULL 引发的数据库异常
摘自:http://www.cnblogs.com/ccweb/p/3403492.html using (SqlCommand cmd = new SqlCommand()) { cmd.Conne ...
- API 网关
使用 API 网关 链接:https://github.com/oopsguy/microservices-from-design-to-deployment-chinese译者:Oopsguy ...
- POJ-1061 青蛙的约会---扩展欧几里得算法
题目链接: https://cn.vjudge.net/problem/POJ-1061 题目大意: 两只青蛙在网上相识了,它们聊得很开心,于是觉得很有必要见一面.它们很高兴地发现它们住在同一条纬度线 ...
- Windows彻底卸载系统自带的office
由于自带office导致按照新的office会提示要先卸载原来32位的office,又在控制面板或软件管理工具中找不到office,用如下方法删除 1.在C盘删除office文件夹 2.删除注册表 1 ...
- [19/03/27-星期三] 容器_Iterator(迭代器)之遍历容器元素(List/Set/Map)&Collections工具类
一.概念 迭代器为我们提供了统一的遍历容器的方式 /* *迭代器遍历 * */ package cn.sxt.collection; import java.security.KeyStore.Ent ...
- 2019.1.4 SSH框架整合步骤(一)
SSH整合 1.三大框架整合原理 Spring与Struts2整合就是将Action对象交给Spring容器负责创建 Spring与Hibernate整合就是将sessionFactory交给Spri ...
- 视图 b
- [转]C#打造一个开源webgis(一)系统架构
搭建一个GIS系统,为了能同时适应C/S和B/S架构,建议是做成自己的地图服务api方式,这样,一个或多个系统,就能通过统一的地图服务接口提供,而通信可以采用http的resful方式,而一个webG ...
- Etherlab debian安装记录
debian wheezy 7.11(虚拟机安装选择桥接网卡) #set ustc source #apt-get install sudo #nano /etc/sudoers;add userNa ...