巨蟒python全栈开发flask2
内容回顾:
上节回顾:
Flask
.response
三剑客:
render_template 模板
redirect 重定向 - URL地址
"" 字符串 HTTPResponse
Flask封装
.send_file(文件路径) # 打开并返回文件内容 - Content-Type:文件类型 文件长度(单位是byte)
.jsonify(字典) # 返回标准Json格式的字符串 - Content-Type:application/json
.request
记住 request.method 当前的请求方式
.url中获取数据 request.args 本质上可以理解为字典 to_dict()
.FormData中获取数据 request.form 本质上可以理解为字典 to_dict()
#<input name="uname" value=""> k==uname v== {uname:}
.获取请求体中的原始数据 request.data b""
.以JSON格式获取请求体中的数据 request.json 前提:请求头中带有 Content-Type:application/json
本质上可以理解为字典
.request.values 知道就行 url 和 FormData 中获取数据
.获取文件数据 request.files 返回的是一个FileStorage对象 save(文件路径) 保存获取的文件内容
FileStorage.filename 默认是文件本身的名字(可以修改)
扩展: request.cookie 获取客户端的 cookie
.Jinja2
{{}} 引用 执行
{%%} 逻辑代码 if for macro
.Session
from flask import request,session #注意在这里request和session是同级的两个东西
app.secret_key = "session序列化和反序列化时所需要的字符串" #中文也是字符串,我们轻易不要修改这个内容
session["key"] = "value"
if session.get("key") #必须这样拿,否则报keyerror错误
在Flask session 存放在客户端的cookie 中默认名称为 session:加密字符串 #注意,加密也只是相对的
并不是所有表操作都是ORM 扩展记忆:
form - Model -fORM
from
<form></form>
小技巧:
快速导包:alenter
form
alt+鼠标拖动 ,竖着选
在处理之前,我们先配置环境

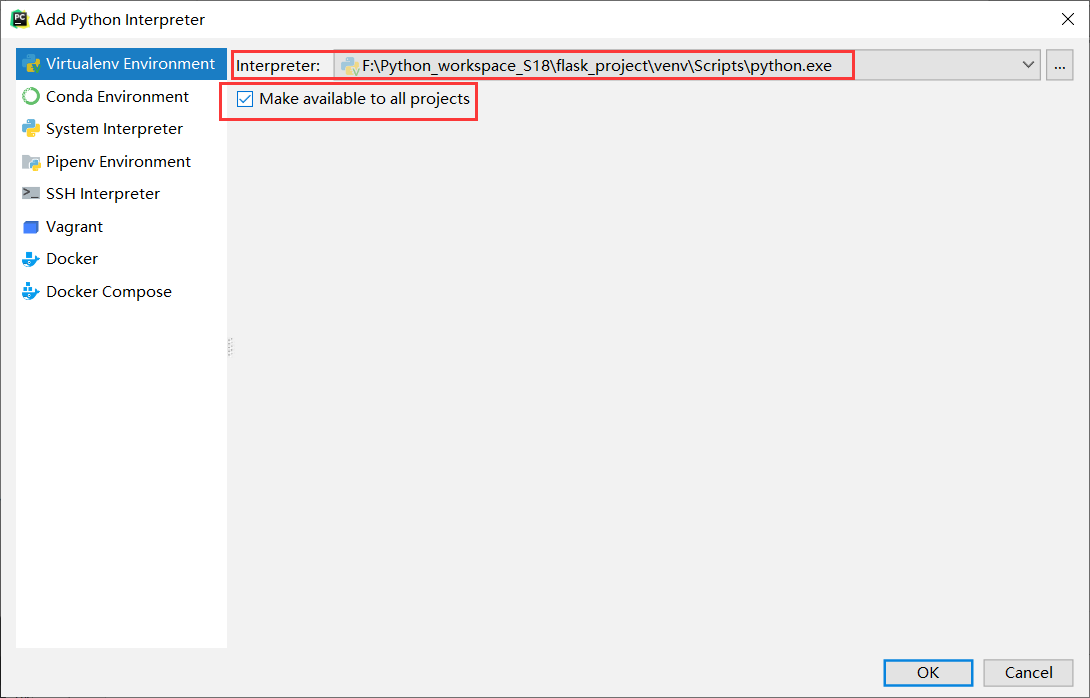
上边的勾号表示,把这个环境添加到所有的项目
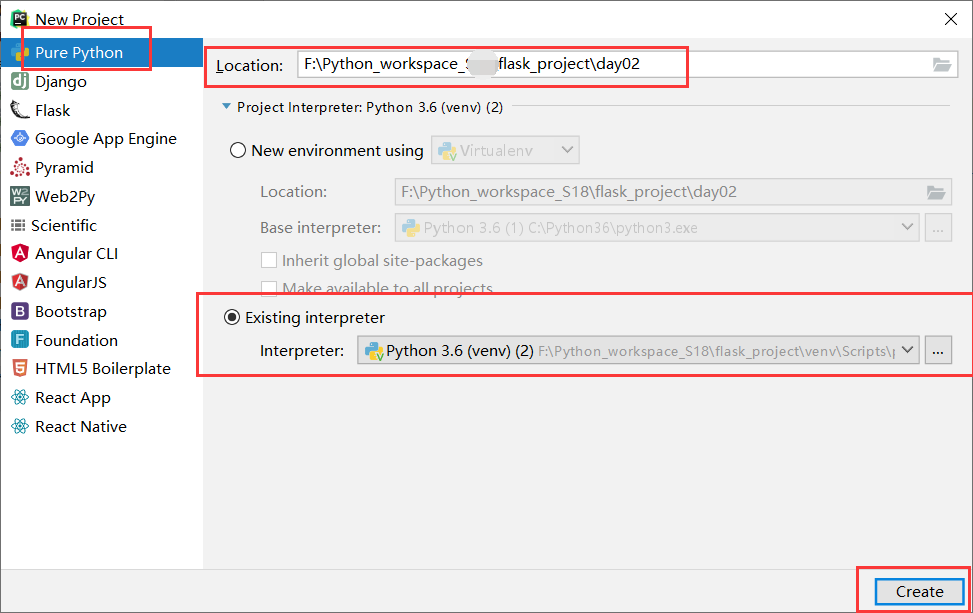
点击"Create",我们就创建了这个day02的环境
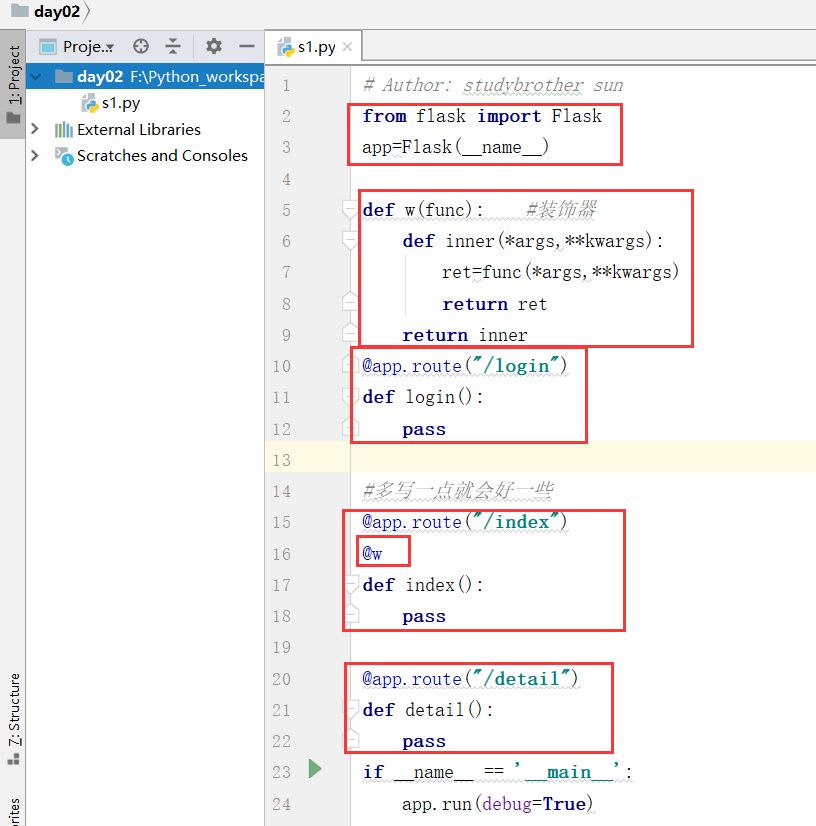
浏览器中运行,得到下面的结果:


分析:这个视图函数,没有一个返回值是有效的.
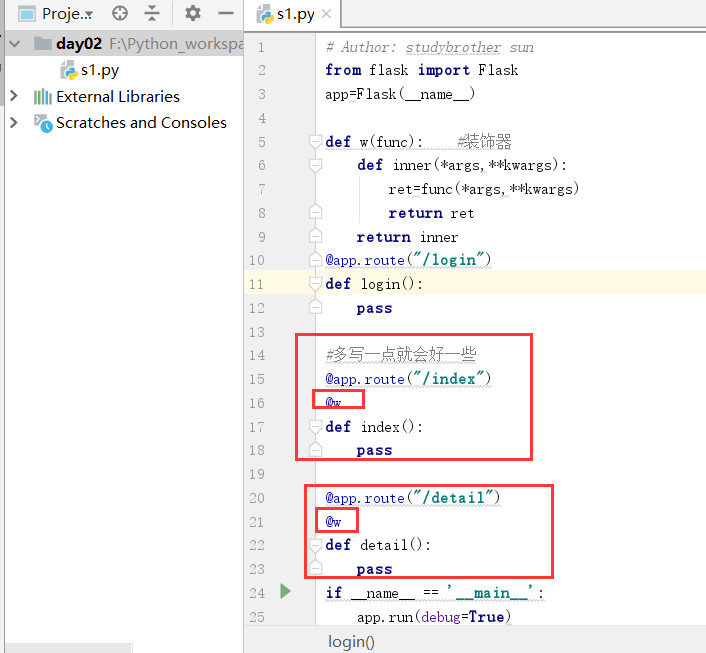
在上图中,我们分别在detail详细信息和index首页加上信息.
运行之后,出现下面的结果:

我们现在感觉的是"视图函数重名"这个问题.
分析重名的原因:
原因:我们需要将detail传递到@w中,我们得到的是inner内部函数,有些面试官是知道的,我们要大胆说一下.
我们需要将想法说出来,我们的目的就是说出来,找工作.
我们写装饰器,实际的目的是:

我们重新写一个py文件
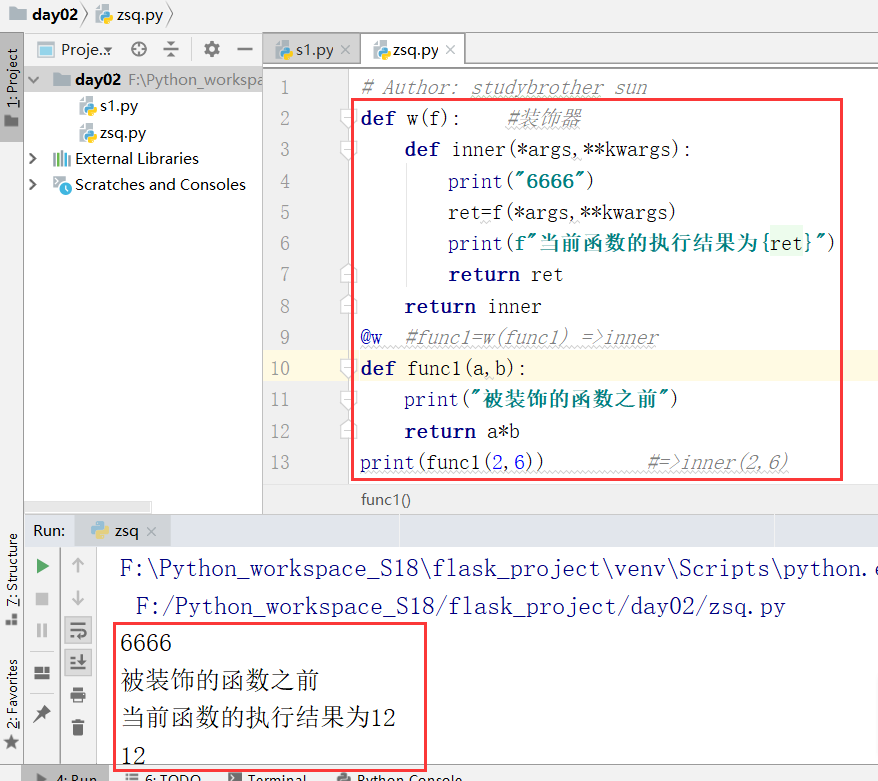

加上装饰器之后,我们的func1.__name__得到的结果是内部函数名字inner

没有加装饰器之前,我们得到的是func1

注意点:视图函数名不能重复:(mapping)
在所有的web框架mapping一般就是路由指向的问题.
1.endpoint重名&&endpoint对应视图函数原理
解决昨天双重装饰器的问题:
解决方案一:functools是解决函数问题的一堆方法

这样,我们就会保留原来的视图函数名字.
当然,我们启动原来的项目名也是可以启动的
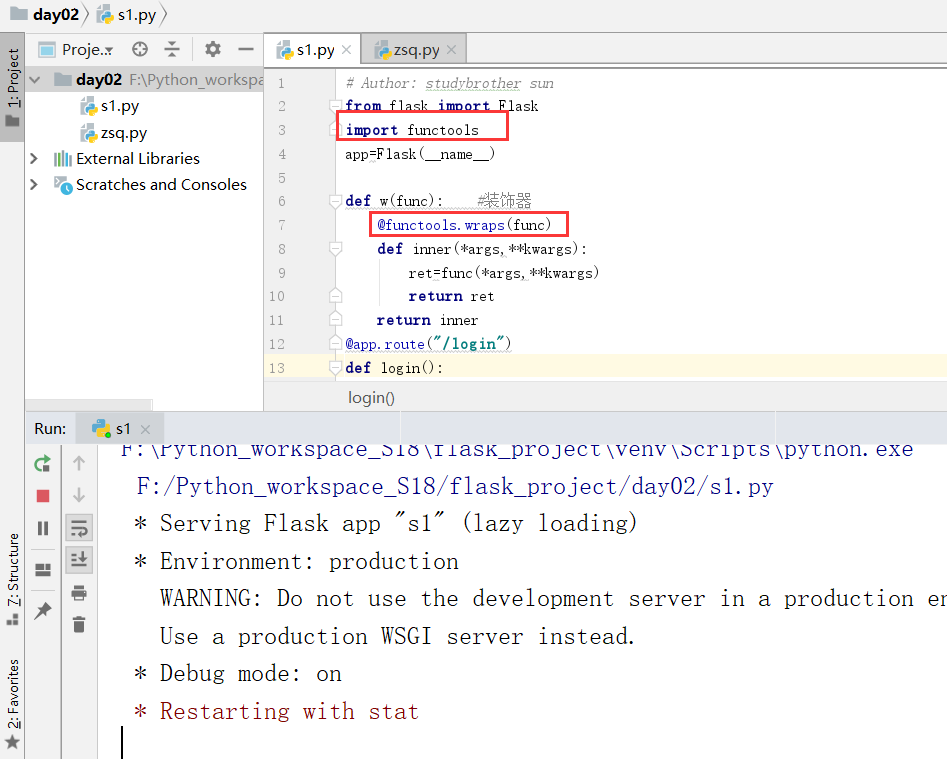
如果不用的话,就会报mapping的错误
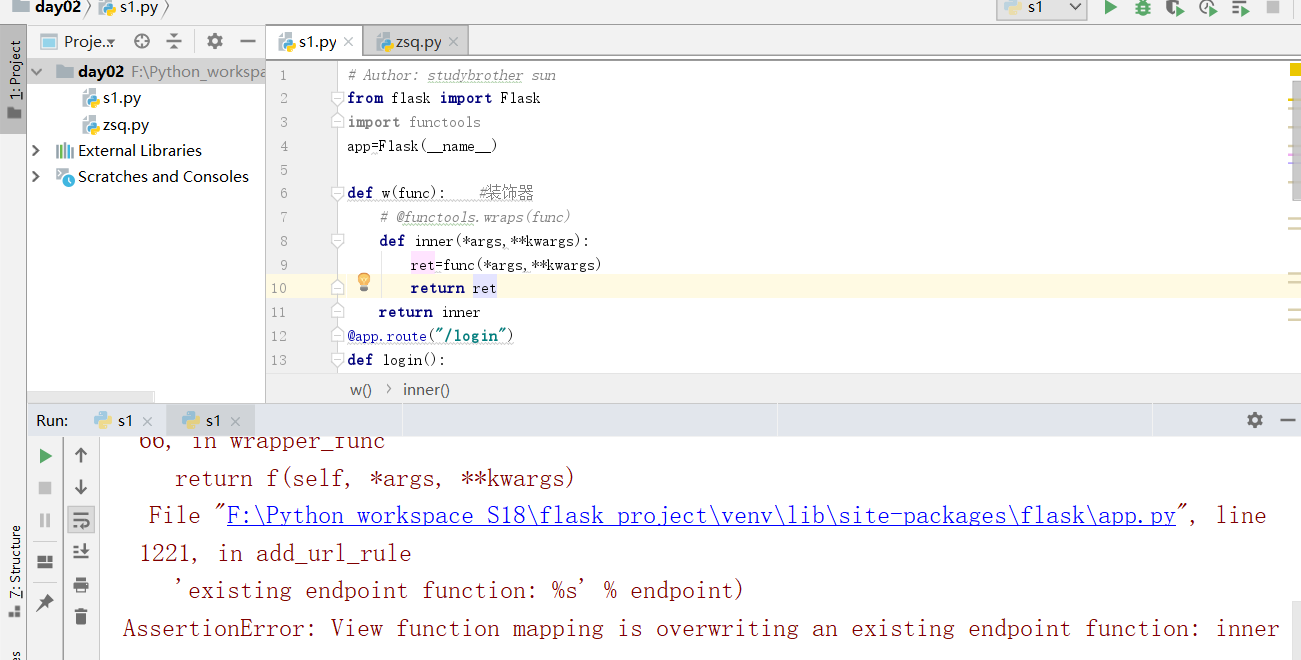
方案二解决问题:
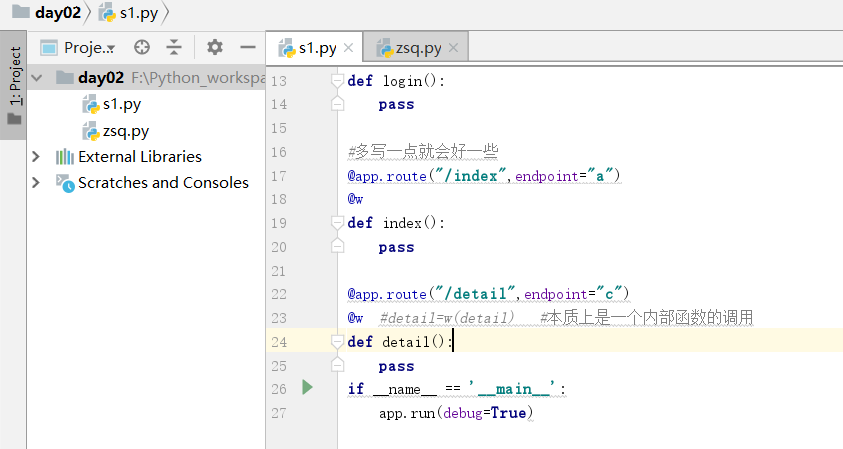
我们加上endpoint
这个时候就不报错了.
如果不写装饰器,刚才被同一个装饰器装饰的视图函数,就可以在上边不写endpoint了.
如果将endpoint写成同一个名字,就会重名,我们可以大胆假设一下这个问题,也就是endpoint的重名

注释掉内部函数,这样写没有问题,
如果写成同一个endpoint就会出现同样的一个问题.因此我们假设是正确的,就是endpoint的问题

还有一个问题,就算视图函数重复,但是endpoint不一样也是不会报错的
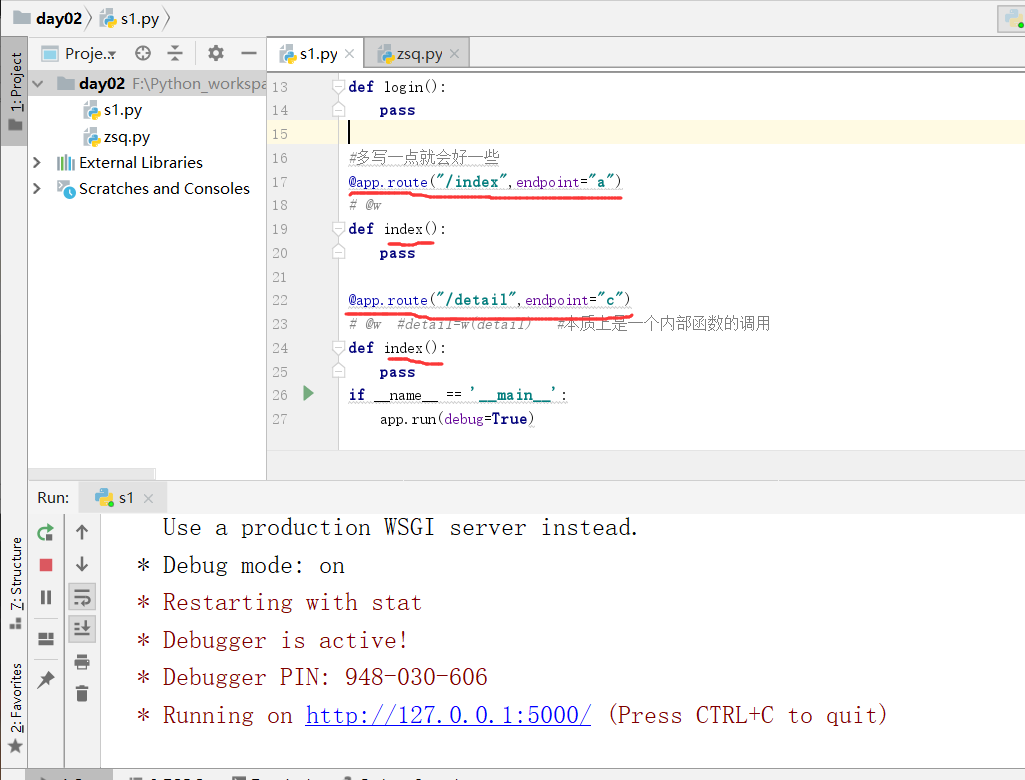
下面我们得到的是内部源码函数,下面是一些分析

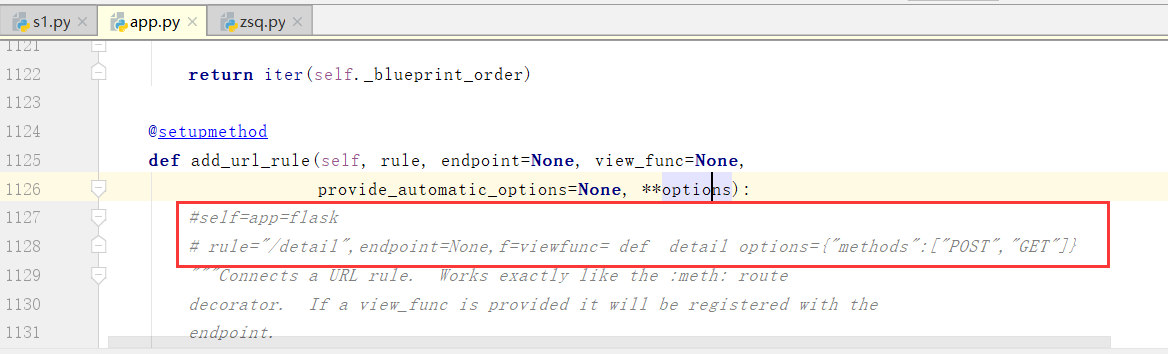
从源码中,我们看到有两种写路由的方法


下面我们看一下那个函数_endpoint_from_view_func
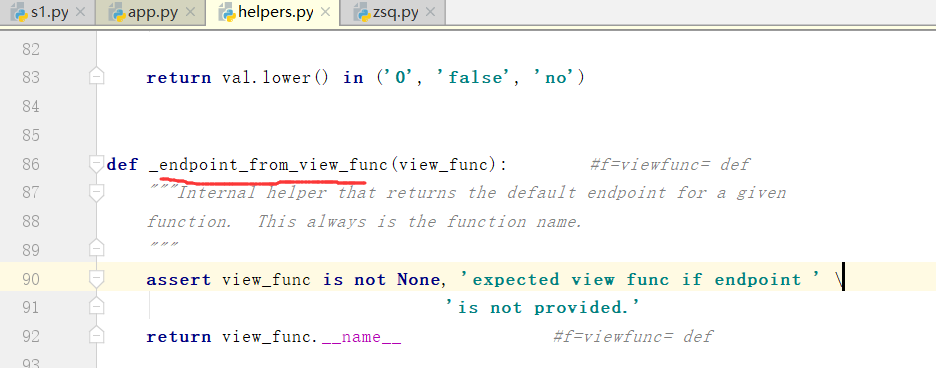
我们看到,最后返回的结果是当前视图函数,返回的名字.

也就是说,最后返回的结果是我们自己定义的detail函数名字.
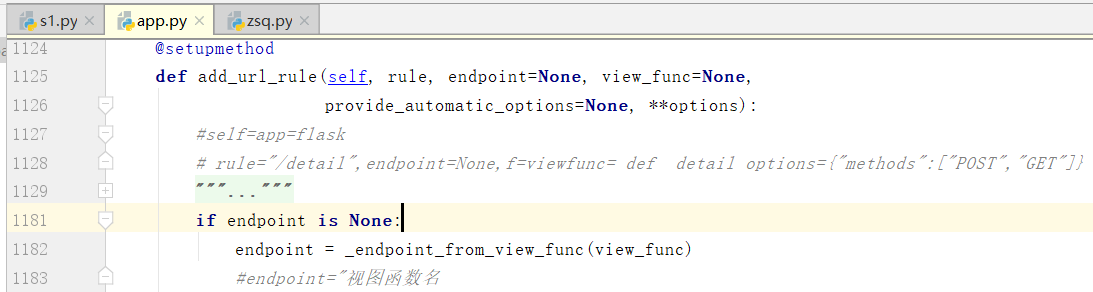
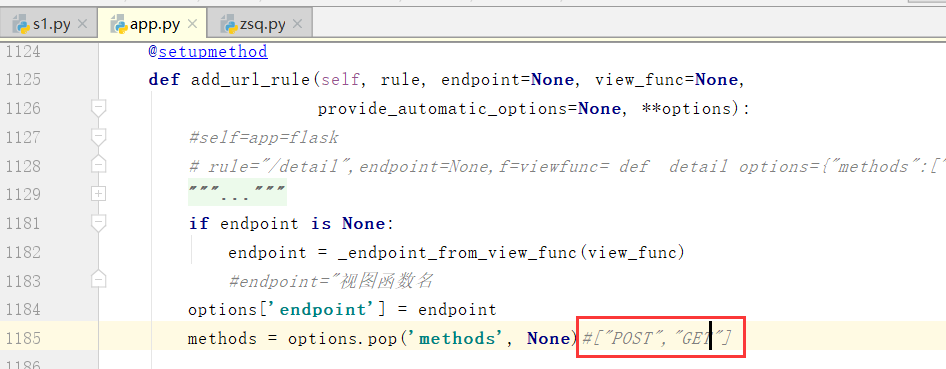
下面是原来写的函数


没有方法的话,我们默认就是get方法处理

不用管isinstance,methods里边说明不需要管大小写,set帮助我们去重和实现大小写里边的转换

这个表示视图函数是否被允许

这个代表的是url_map路径

下面我们跟踪一下view_functions

上边显示的应该默认情况是空的集合或者字典
.get代表是字典
for...代表的就是集合
得到None之后,就可以直接忽略,下面的内容
这个时候,我们得到是,前面是视图函数,后边是内存地址
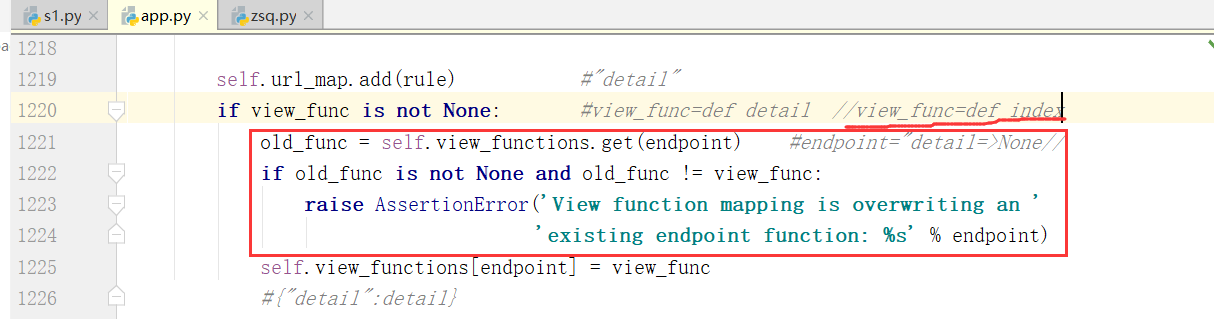
新的函数名字是index,这个时候就会触发这个异常了
添加两个相同的当然可以,但是没有意义,见下图

这个时候我们写了两个路由访问的是一个函数,没有意义,但是这是天机路由的第二种方式

上图中显示的运行时可以的
总结:
.解决昨天双重装饰器的问题
实际上是endpoint的重名导致
源码如下
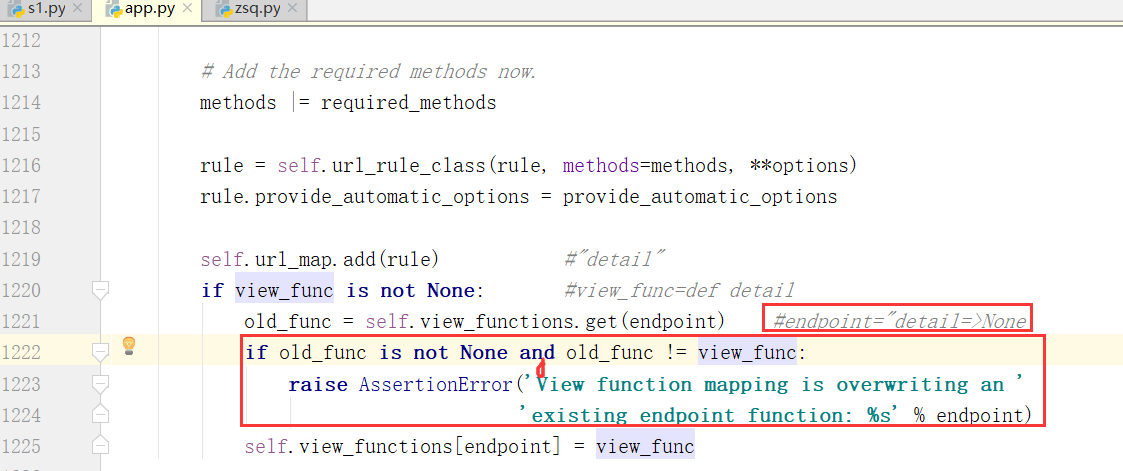
if view_func is not None: # view_func = def detail # view_func = def index
old_func = self.view_functions.get(endpoint) # endpoint = "detail"
if old_func is not None and old_func != view_func:
raise AssertionError('View function mapping is overwriting an '
'existing endpoint function: %s' % endpoint)
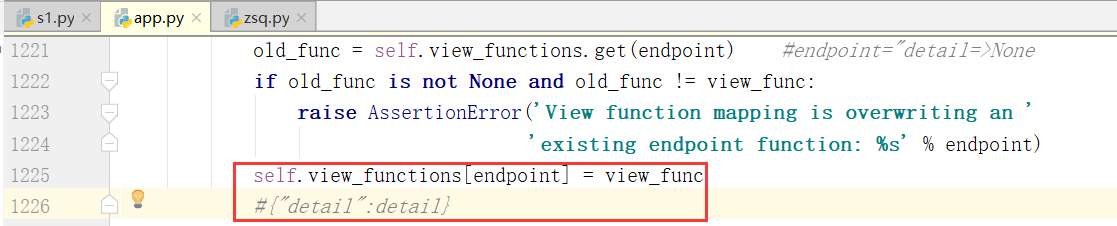
self.view_functions[endpoint] = view_func
.Flask路由
.添加路由的方式
@app.route("/my_de")
def detail()
app.add_url_rule("/my_de",view_func=detail)
2.Flask路由(写正则,只会徒增烦恼)
.Flask路由
.添加路由的方式
@app.route("/my_de")
def detail()
app.add_url_rule("/my_de",view_func=detail) .methods 可迭代对象 [] ()
允许请求进入视图函数的方式 种HTTP请求方式(具体请求方式,百度查看一下)
methods可以是列表也可以是元组,目的就是迭代里边的元素
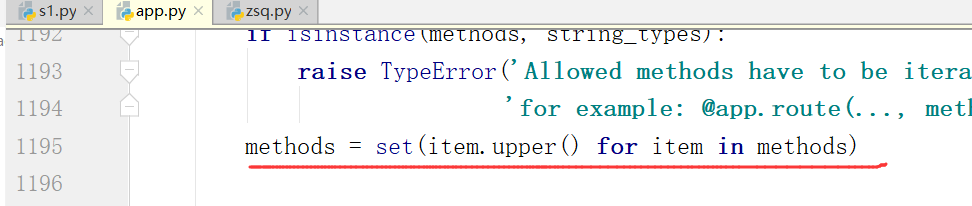 '
'
还有一个我们需要知道的是如果methods一开始None,我们会赋值一个GET给他
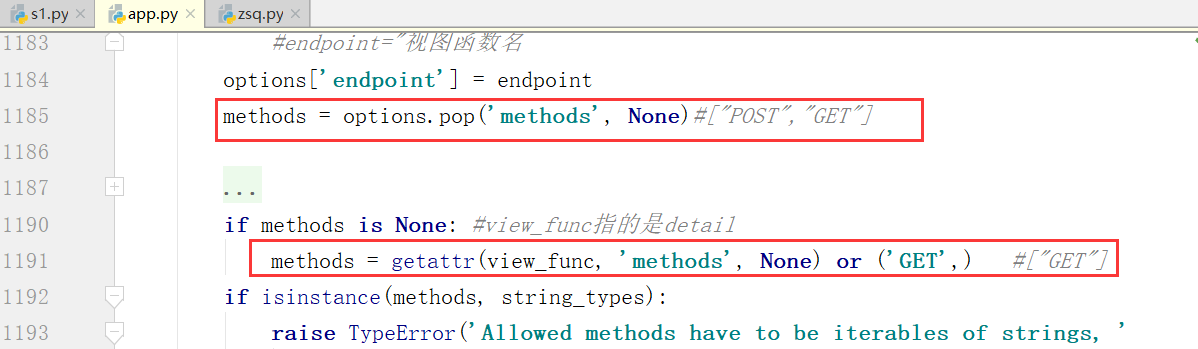
下图中判断的是不是同一种类型.

找到这个变量,一个代表的python2,另一个代表的是python3

如果是上边的两种类型,就会给下面的列表形式的提示

找一下八种方式:

点击views进去,查看一下源码
可以查看到下面的八种请求方式.,当然除了这八种方式,我们还可以自定义请求方式,现在能力不够的话,就先不要自己定义了(毕竟这是打破规则的方式)



这样,我们就相当于django中的反向解析,url_for("index")=>/index
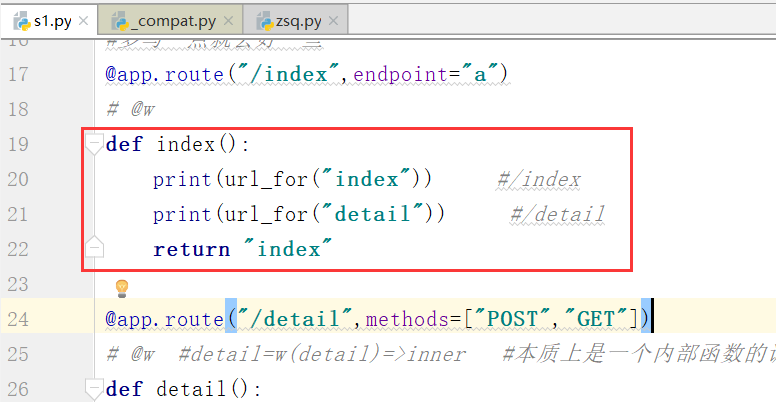
中间出现了下面的一种错误:
werkzeug.routing.BuildError: Could not build url for endpoint 'index'. Did y
原因可能是当时写的两个视图函数,

上图中,我们运行:
得到下面的结果:

服务端打印出,下面相对应的结果

这里边也就是和url_for和django中的反向解析是一样的.
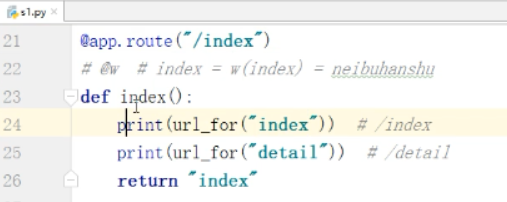
流向: 21行的index指向23行的index
以及24行的index指向21行的index,再由21行的index指向23行的index
因此我们知道了endpoint是一个非常牛的指向机制,如果指向机制出现了重名就不能实现了.
对比身份证件指向的是户口所在的地方.再指向人等等id号码
身份证倒数第二位男单女双

.endpoint 路由Mapping 地址对应视图函数:
与其对应 - url_for 用来反向解析URL地址
url_for(endpoint) # /路由地址
需要知道的,当别人说起我们需要知道的内容:
知道的:
.strict_slashes=True 是否严格遵循路由匹配 - "/"结尾 默认值是 True 必须严格遵循
.defaults={"nid":} 默认路由参数 - 视图函数中必须有一个nid(key)的形参接收
.redirect_to="/index" 永久重定向 /? - 不进入试图函数处理,直接跳转
4中如果是False是不要严格匹配的意思,例如下面不遵循严格匹配会报下面的错误.



运行:
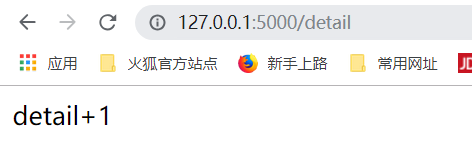
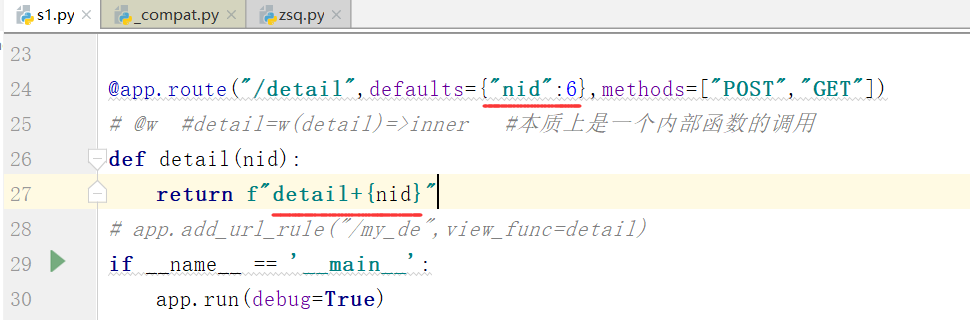
默认参数,运行:

如果在函数和返回值中不写

运行,报下面的错误,也就是缺少nid

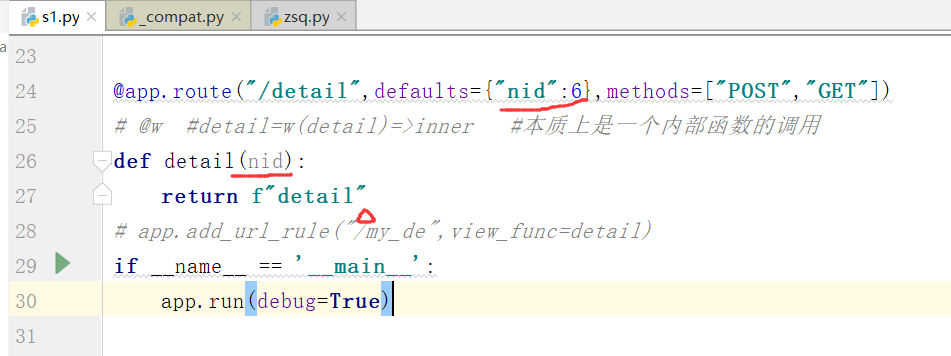
我们将nid在函数中接收一下,但是不用也是可以的
运行:




我们访问detail,重定向到index
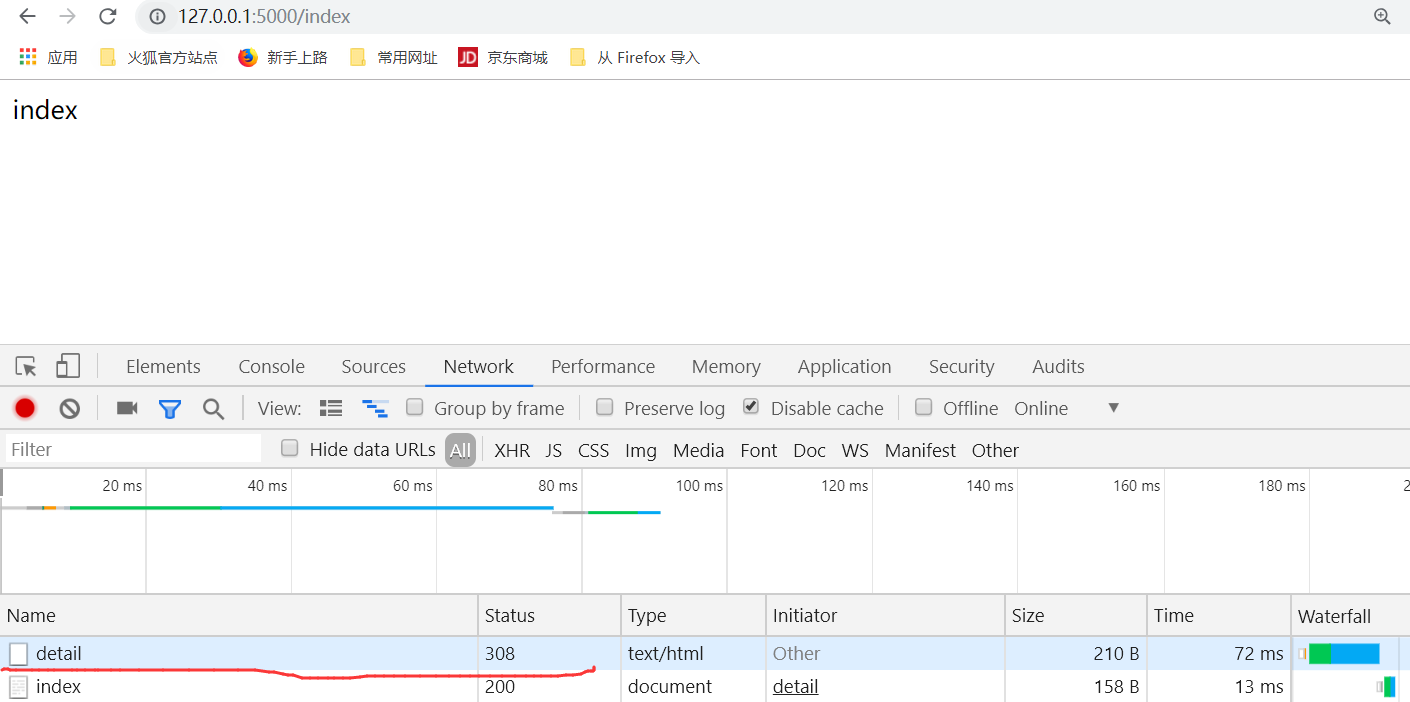
并且我们看到了重定向到了index,detail的状态码是308重定向
知道的:
.strict_slashes=True 是否严格遵循路由匹配 - "/"结尾 默认值是 True 必须严格遵循
.defaults={"nid":} 默认路由参数 - 视图函数中必须有一个nid(key)的形参接收
.redirect_to="/index" 永久重定向 /? - 不进入试图函数处理,直接跳转
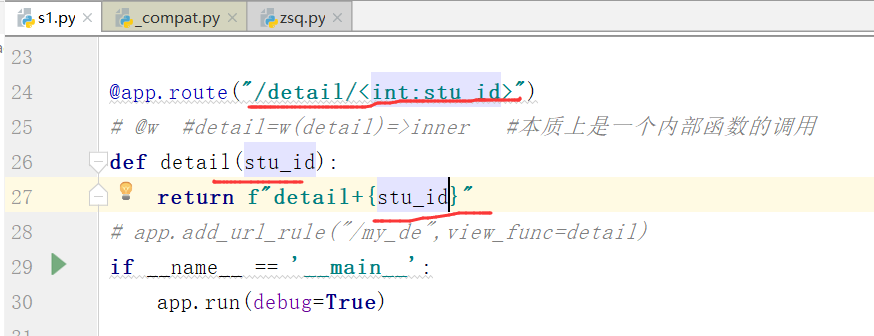
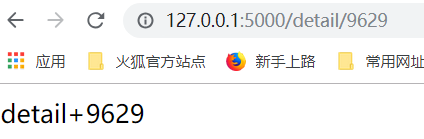
上边我们是int类型必须写阿拉伯数字才行,写字母会报错
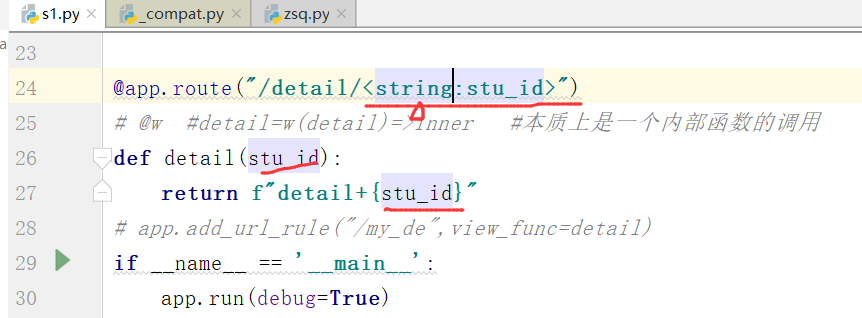
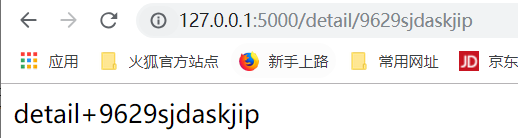
我们也可以修改成string类型
我们不懈类型也可以不懈,代表任何类型.

除非是特别要求比如翻页等需要处理int等类型.
必须的必:
.动态参数路由
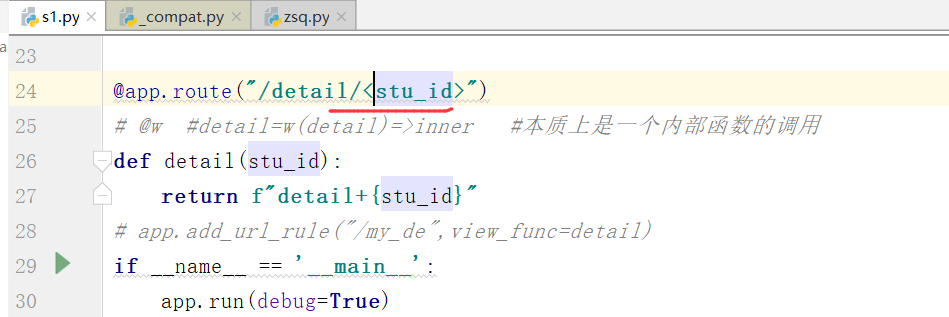
@app.route("/detail/<stu_id>") 可以在 路由地址 之后增加参数的传递
视图函数中必须有一个 stu_id(key) 的形参接收
例如:
@app.route("/getimg/<path>/<filename>")
def getimg(path,filename):
file_path = os.path.join(path,filename)
return send_file(file_path)
如果我们不写这个stu_id
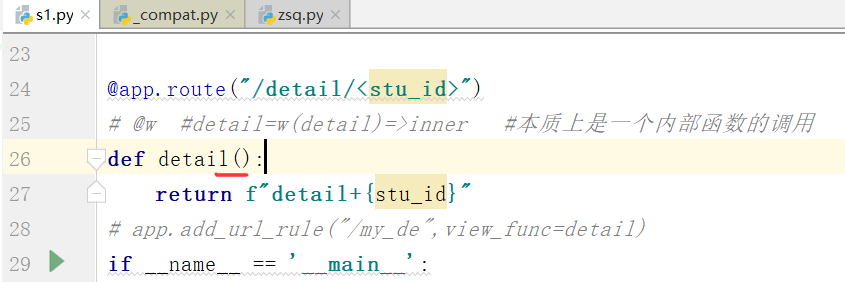

必须在函数的参数中接收这个参数,但是用不用是无所谓的.
最有用的东西

这个时候,我们就可以访问地址了
我们可以加上多个动态参数
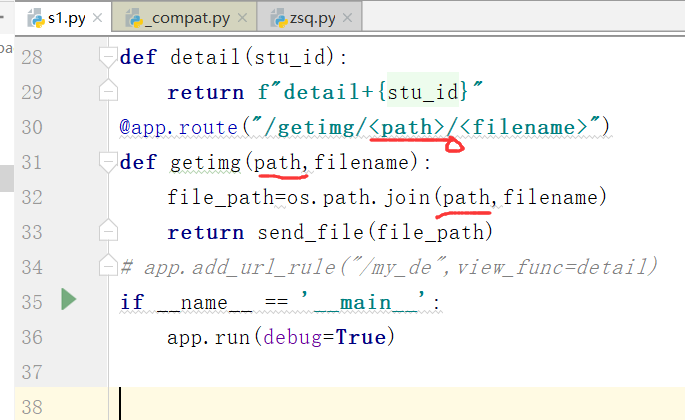
也就是说,这是一个访问路径的限制
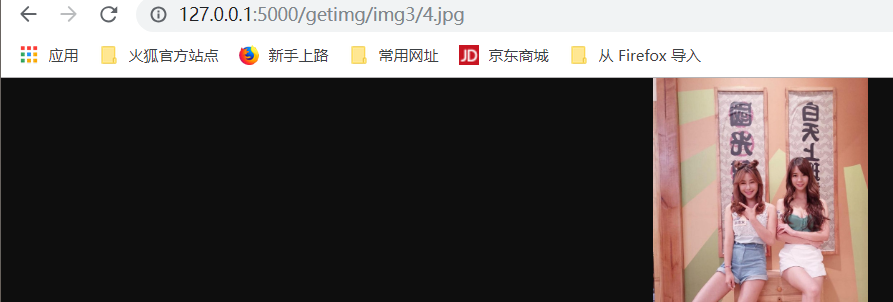

我们可以指定到具体的目录,不能跨目录
上边的path指的是参数名字
必须的必:
.动态参数路由
@app.route("/detail/<stu_id>") 可以在 路由地址 之后增加参数的传递
视图函数中必须有一个 stu_id(key) 的形参接收
例如:
@app.route("/getimg/<path>/<filename>")
def getimg(path,filename):
file_path = os.path.join(path,filename)
return send_file(file_path)
难点在于flask的精髓,尽可能理解,
老师总结,之所以有现在的一点点成就,就是python中的源码以及flask源码给老师很多的启示.,这个很重要.
sanic也可以看,但是先看好django和flask再说
下面我们进入flask初始化配置模块
3.Flask初始化配置
1.Flask初始化配置
app=Flask(__name__)
2.Flask对象配置
app.config == app.default_config 查看默认配置 及 配置项
这是我的新想法,发微信

点击Flask,看一下Flask初始化了多少参数
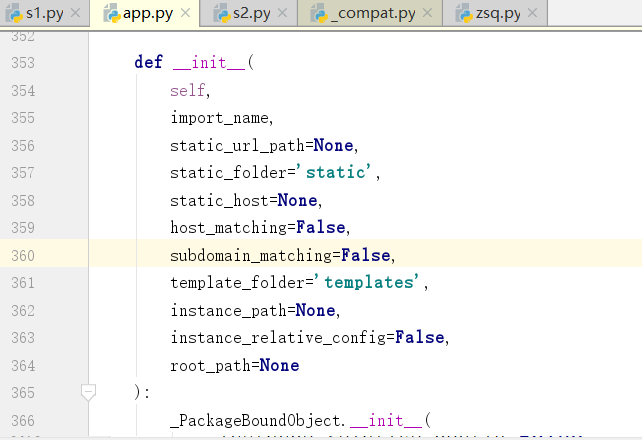
类的初始化,先走__new__,再走__init__,源码中没有,所以先找的就是init了
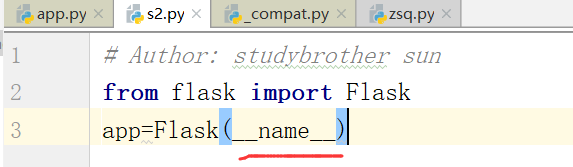
__name__的目的是为了锁定目录来用的.
我们也可以写成下图中的样子,只不过这样就没有任何意义了

我们先创建一个index页面
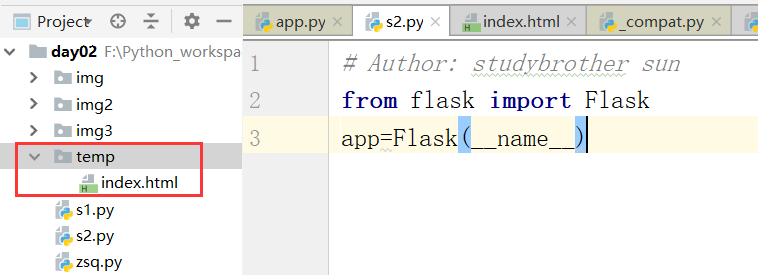

接下来,我们运行,
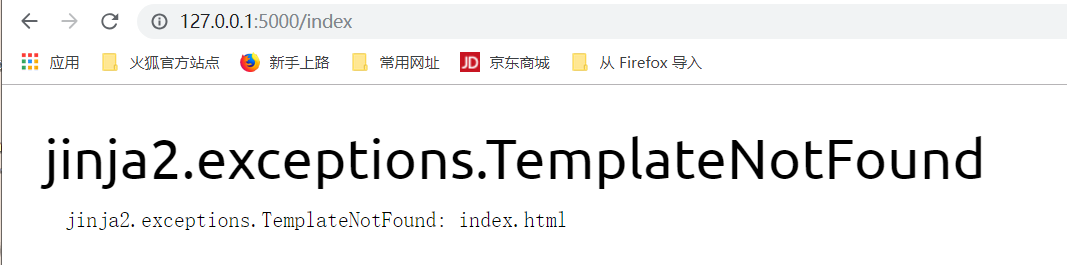
上图中,报错的原因是,模板没有找到.
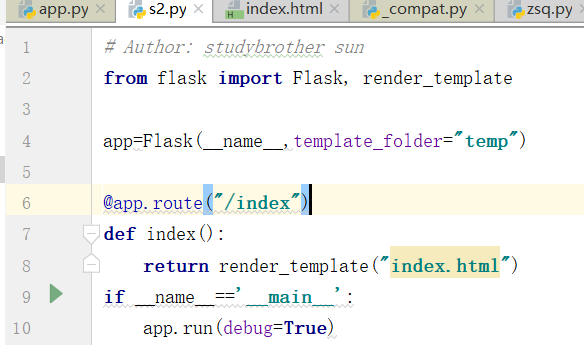
我们需要这样写才能够找到路径,

上图红线的地方,表示的是默认路径的写法.

在模板中写一点东西,这时候,我们再运行

总结:template_folder写的目的是改变模板的存放目录
上边,我们已经写了三个静态文件.
如何操作?

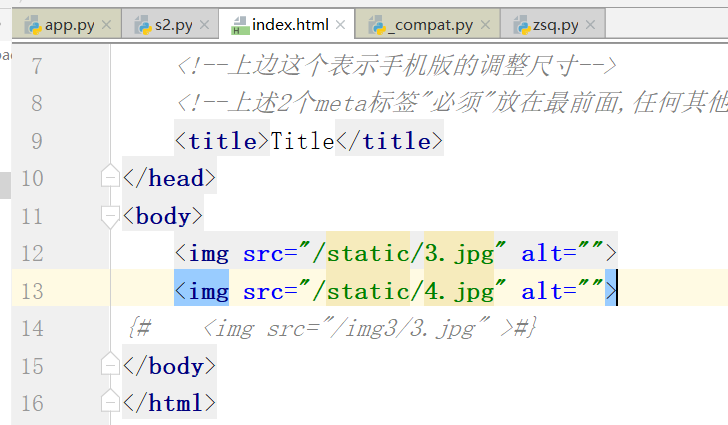
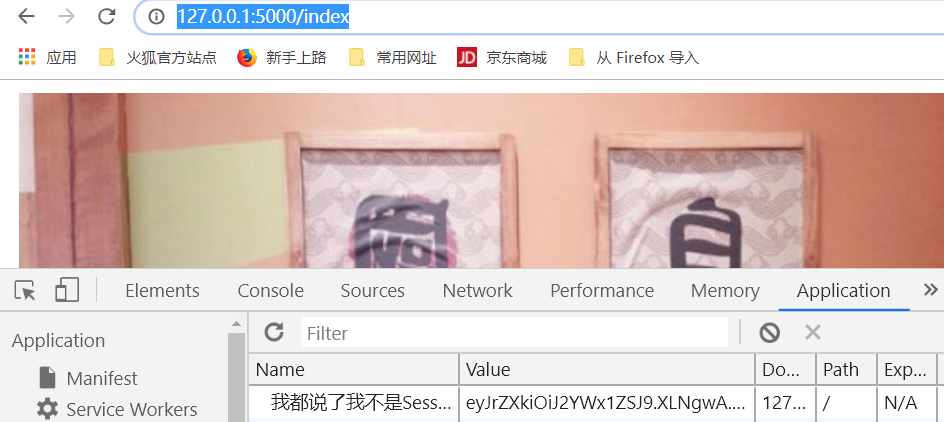
运行,这个时候,我们访问不到这两张图片
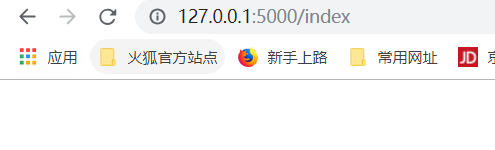
这个时候,如果我们想要访问怎么处理img和static之间的关系?可能是上百万张图片的关系????
这个时候,我们再看一下源码,看到了除了static_folder之外,还有一个static_url_path
这个时候,我们再次重启,看一下运行结果,下图中已经出现了,只不过这个时候是,两张竖着排的照片.


也就是说,上边的方式是,我们的存放路径是static_folder,访问路径是/static
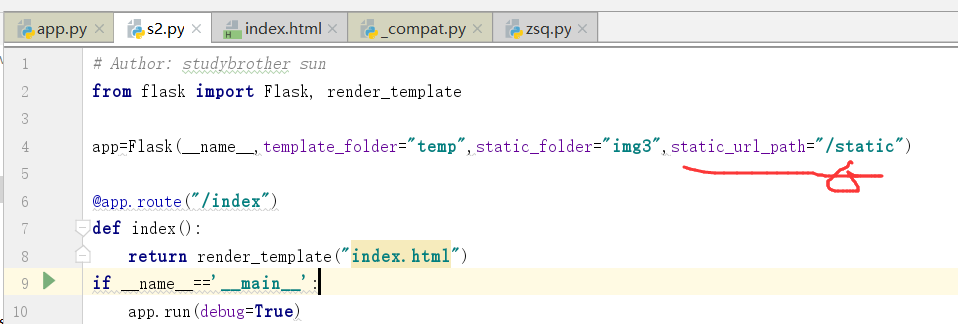
.Flask配置
.Flask初始化配置
app=Flask(__name__)
.template_folder="tem" 指定模板存放路径
.static_folder="img3" 指定静态文件的存放路径
.static_url_path="/static" 指定静态文件访问路径
# if static_url_path is None
# static_url_path = "/" + static_folder = /img3
# /static
下面三个参数只是个单纯的参数:
static_host=None, 静态文件的存放服务器
host_matching=False, False 主机位匹配 www.oldboyedu.com.icu:999
注意如果开启host_matching,那么我们的nginx就会失效了,nginx做服务的转发和主机位的匹配
subdomain_matching=False, 遵循子域名匹配
初始化,



主域名:

下图便是子域名:

最后三个参数,对我们一般是没用处,当用到再说]
django中的网关接口:uwsgi
flask中的网关接口:werkzeug,其实这个接口底层实现的也是wsgi,
因为有nginx,可以不需要后边的三个参数,但是没有也可以自己做,但是效率会低一些,作为一个全能框架必须需要的东西.
前后单不分离,可能会用到static_host参数
4.Flask对象的配置 Flask Config
我们看一下config里边的源码.我们看到有下图这个个东西.

我们再看一下下上图表示的是什么?
我们再看一下make_config
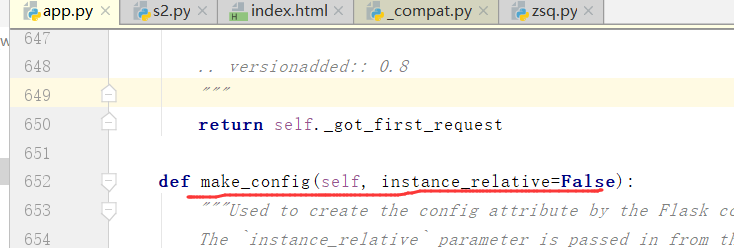
我们看到的是,将默认值变成字典
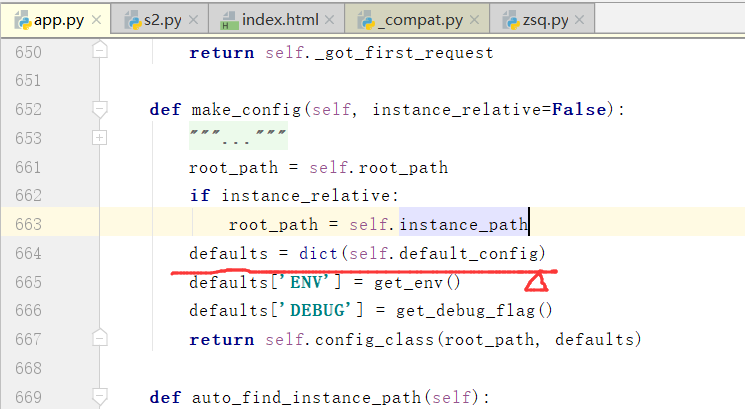
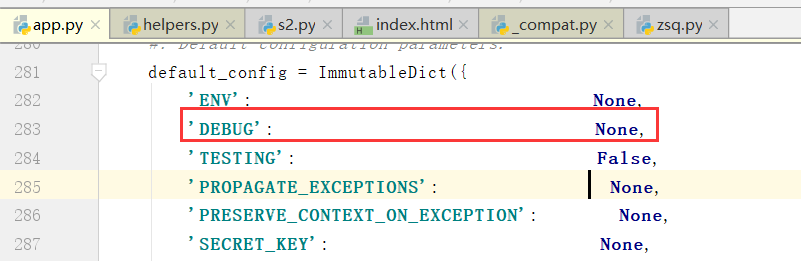
我们看一下default_config里边的一些参数:ENV是新版本添加的参数,也就是虚拟环境的配置

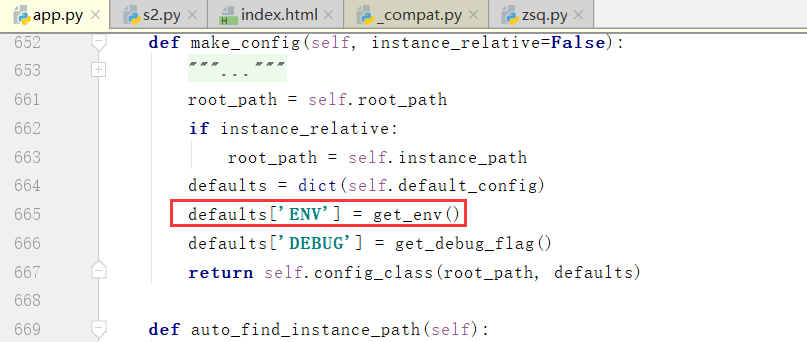
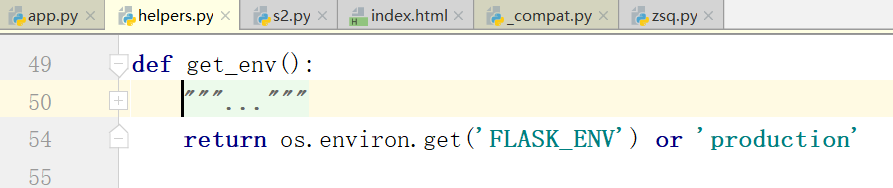
我们在源码中的这个位置会拿到虚拟环境的东西
我们再看一下这个自定义配置


我们再找到的是self对象调用的config
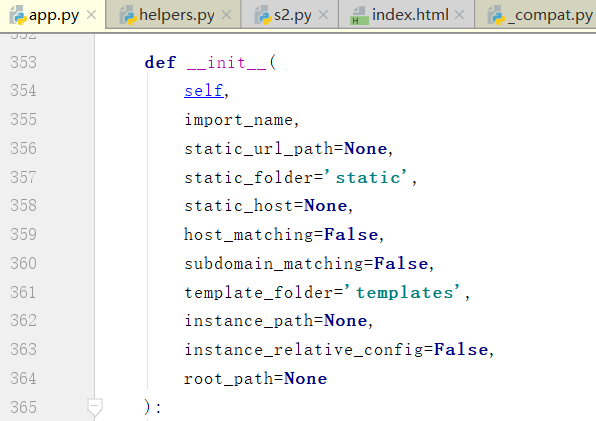
也就是说,我们可以直接定义config

我们可以修改成debug=True如何修改?好像这里边是个字典,我们可以尝试一下
我们将debug=True写在上边

两个道理是一样的.,这个时候依然可以重新启动代码
这里边还有一个参数TESTING

DEBUG和TESTING本质上两只没有太大的区别
testing&&debug都会在控制台还是那个打印,
debug更改代码会重启,testing更改代码不会重启
testing是项目已经写完了,开始测试了,才会开启的
debug的级别会很高,会把异常抛到页面上边

运行:

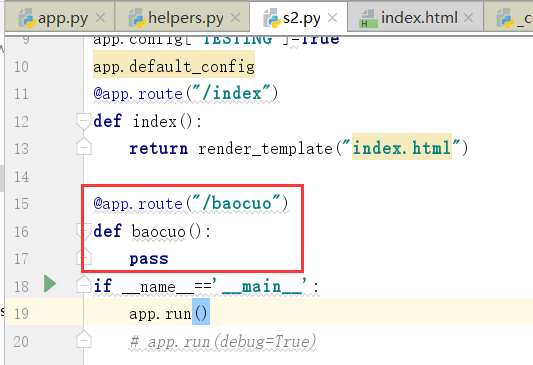
这个时候会报服务器错误.
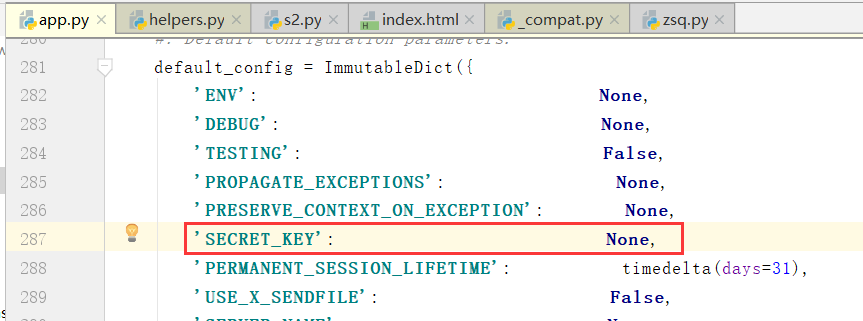
secret_key与session有关系

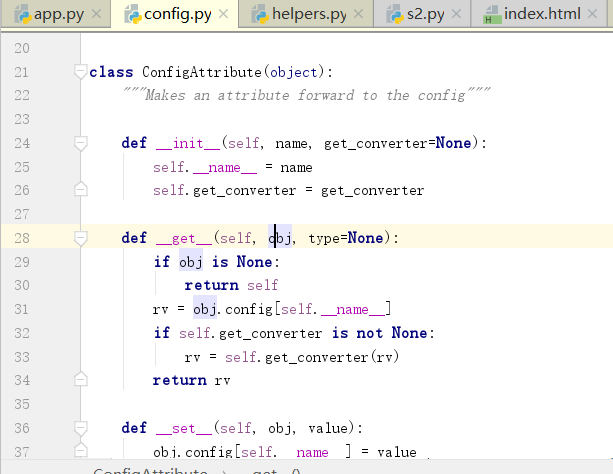
点击进入 ConfigAttribute
在执行setattr会有这个东西

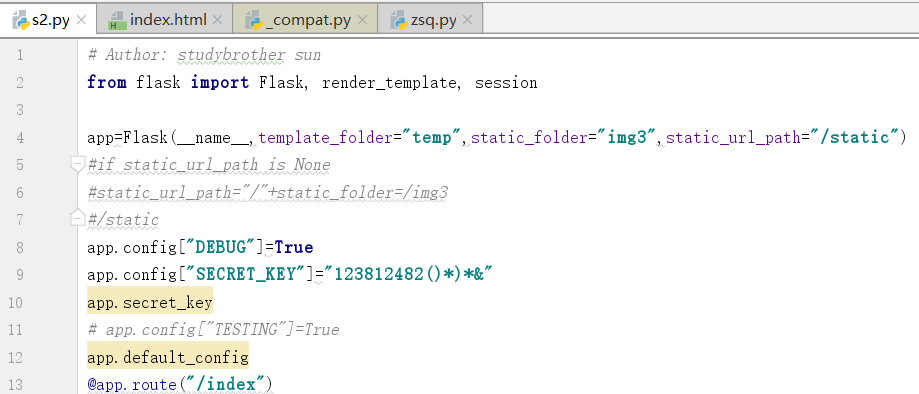

运行,这个时候就出现了两张图片

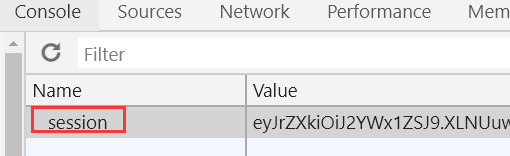
这个时候,我们就可以看到了一个session了
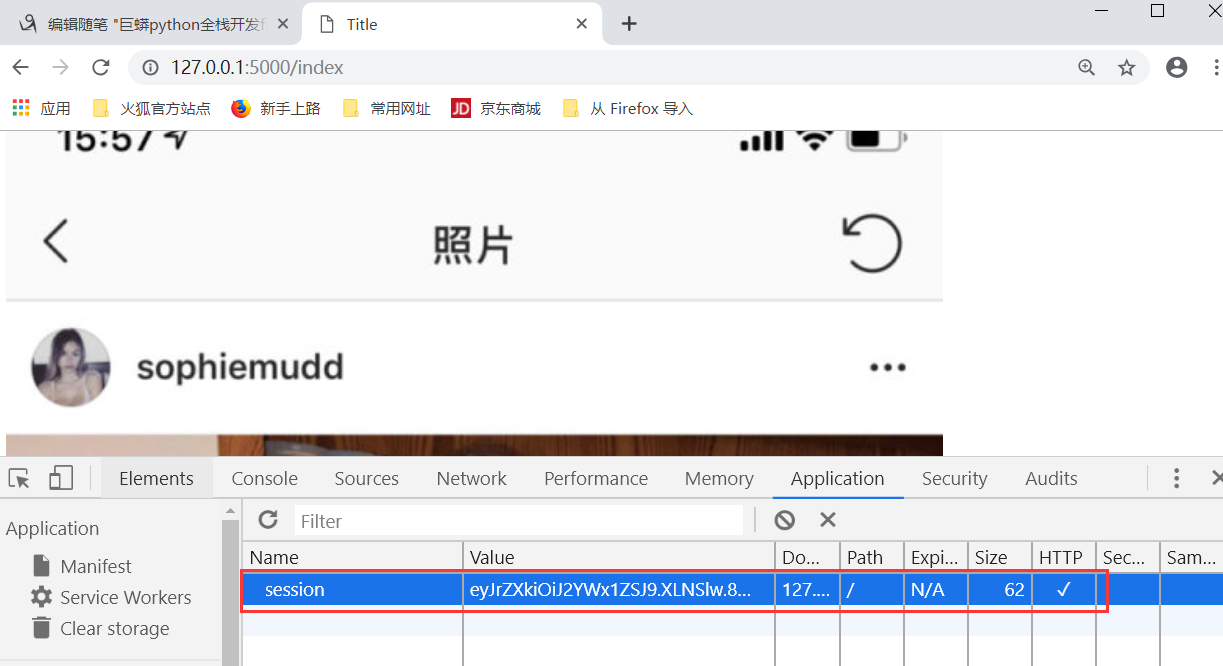

生命周期31天
server_name这个配置也没有太大意义
session_cookie_name指的是sessions存储在cookie中的名字

下面我们修改一下

运行:
没刷出来了,原因在于自己将名字写错了
也可以写中文
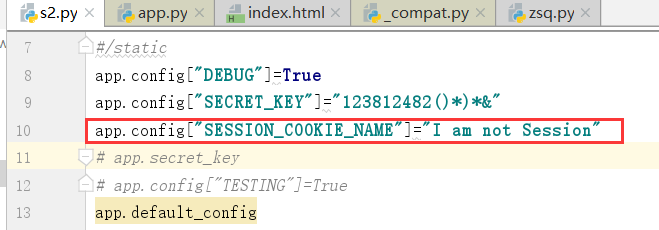

注意:第三方组件也是通过config配置来的.

表示的是,在哪个域名下面开启session_cookie

差不多就行了.

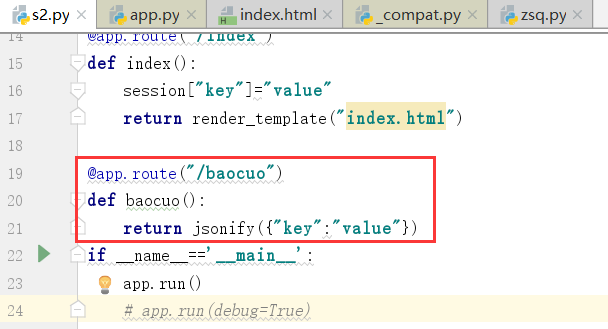
运行,这个时候,我们访问,可以拿到一个字符串

这个时候,我们可以看到响应头里边有一个application/json
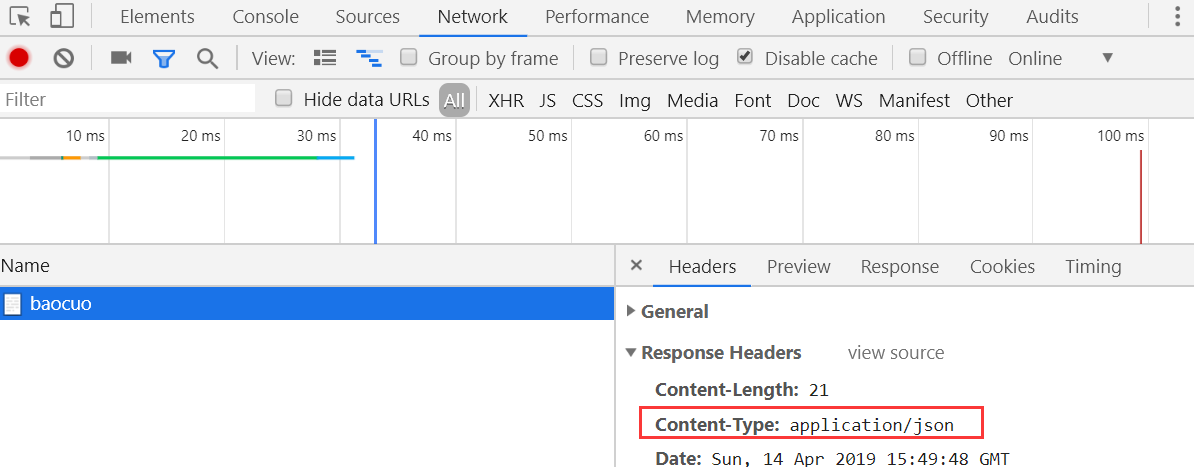
下面,我们修改一下:

这个时候,我们再次访问一下:
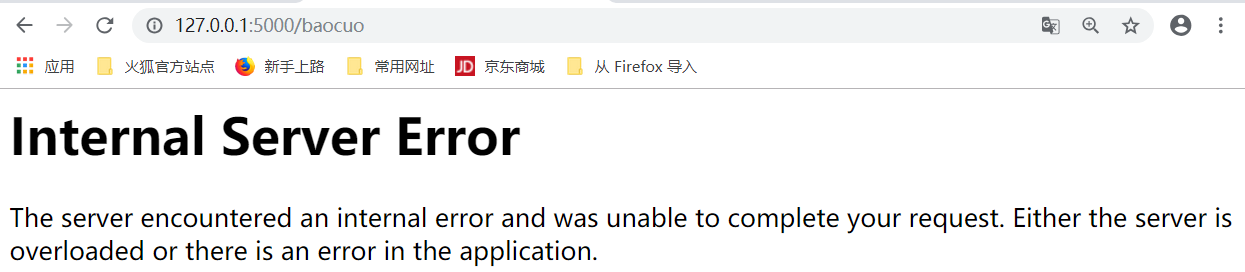
这个时候,请求就会下载

并且会下载这个baocuo,原因:浏览器无法识别Content-Type
图片//音频//视频
打开下载到本地的结果:

打不开,这就是擅自修改了这个配置的结果.

上图我们可以修改成这个样子.这样,运行出来的结果就是下图的样子

也就是说,我们可以按照需求定制这个内容
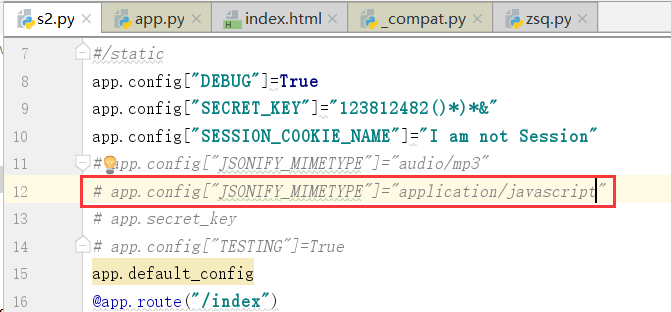
默认是最下面这个

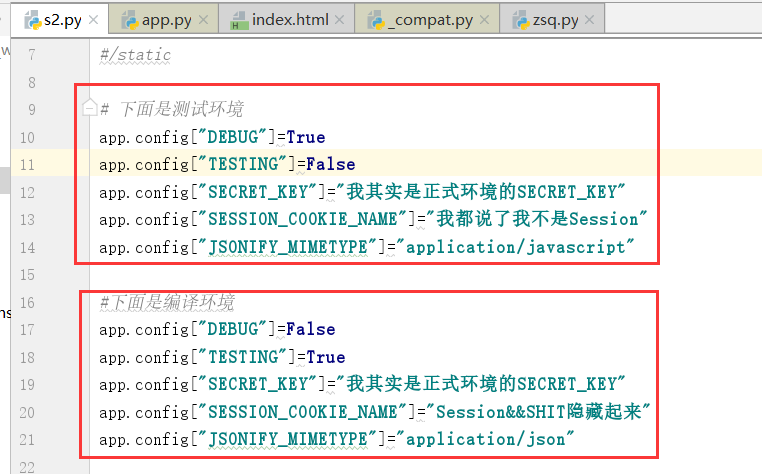
重点在于,我们如何应用这个配置

这个时候,我们需要对配置进行更改
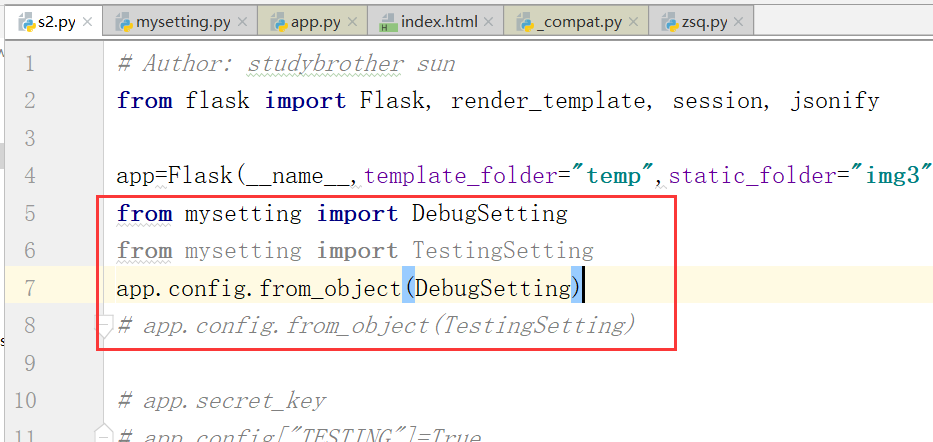
上边,我们是对加载的方式进行了相关的配置
运行:
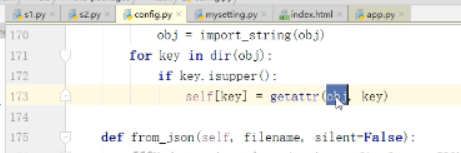
obj指的是mysetting

传递过来一个配置的类.
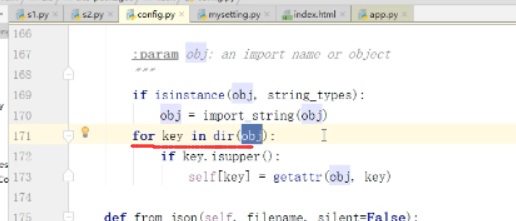
上图中的for指的是将所有的属性都拿出来.
如果配置是大写,我们需要在self中放入的东西(注意:源码中的写法是很精妙的)
self指的是config,config到的from_object

config里边是这样写的
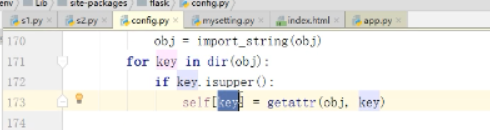
key是大写的DEBUG,这样就通过反射找到了
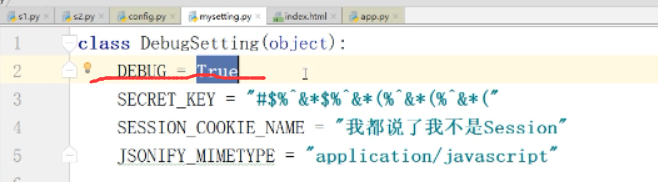
注意,有时候需要重新运行代码,才能够出来代码.
.Flask对象配置
app.config == app.default_config 查看默认配置 及 配置项 class Obj(object):
DEBUG = True app.config.from_object(Obj) # 记住(因为是类所以大写)
5.Flask蓝图&&目录结构(课程最后会讲解sqlachmy)
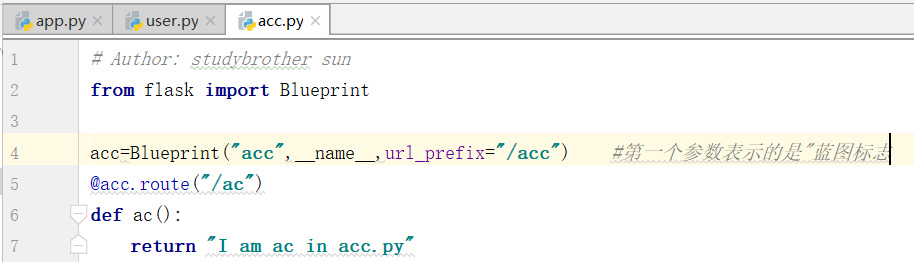
下面,我们新建一个app.py和一个user.py,在app.py里边写上四行代码,具体如下所示


这个时候,我们重启一下代码:
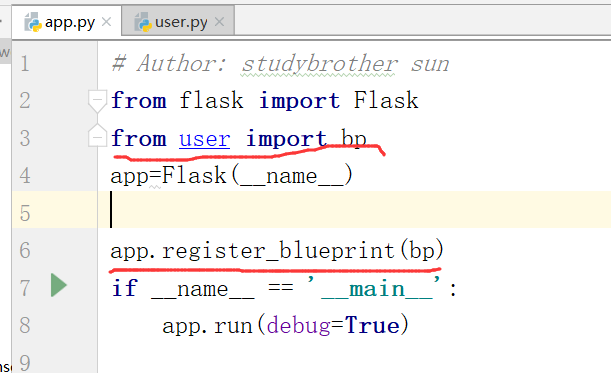
这个时候,我们运行app.py

如果访问地址变成下面的内容,得到下面的结果:

这个时候,我们需要加上地址前缀url_prefix
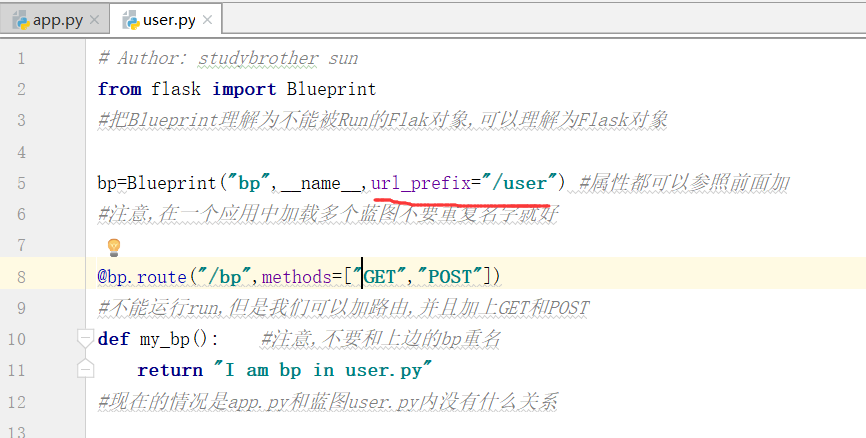
注意,上图中的文字部分
运行,可以得到下面的结果了
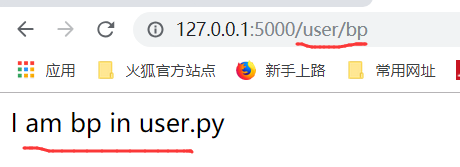
下面,我们再写一个蓝图
运行app,这个时候,我们依然是访问不了的.


运行:这次应该可以访问了


下面我们再新建一个蓝图项目:
下面我们简单学习下,flask怎样正常创建项目
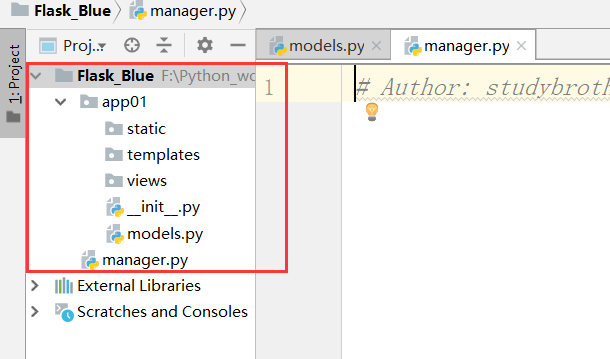
首先在Flask_Blue项目下面创建app01包,再在app01包下面创建目录文件static//templates//views//models.py
再在Flask_Blue下面创建manager.py文件
创建的目录如下图所示:
这样就和django差不多,但是还是有区别的
django是一个大应用的,而我们这里是分散的小应用的.
下面开始写__init__.py需要做的事情:
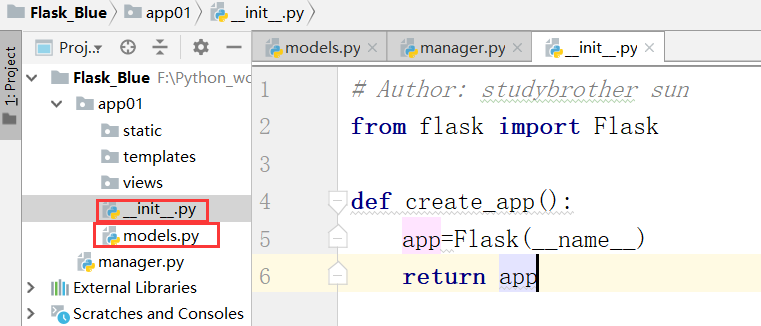
现在,我们还没有学models.py就先不用管,上边我们写完__init__.py,下面我们开始在manager.py处理
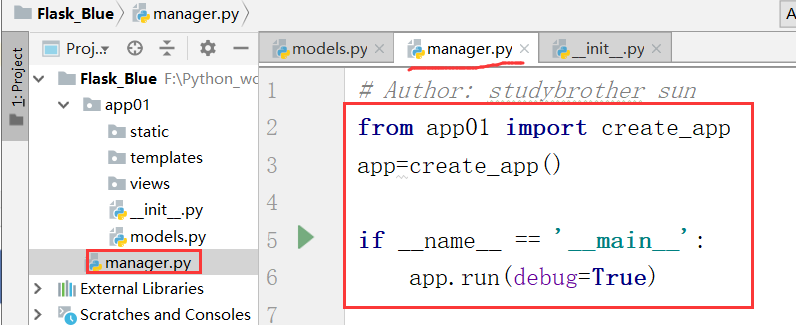
现在,我们运行manager,就相当于运行flask

测试可以,我们可以停止一下
视图函数,我们写在views文件里边

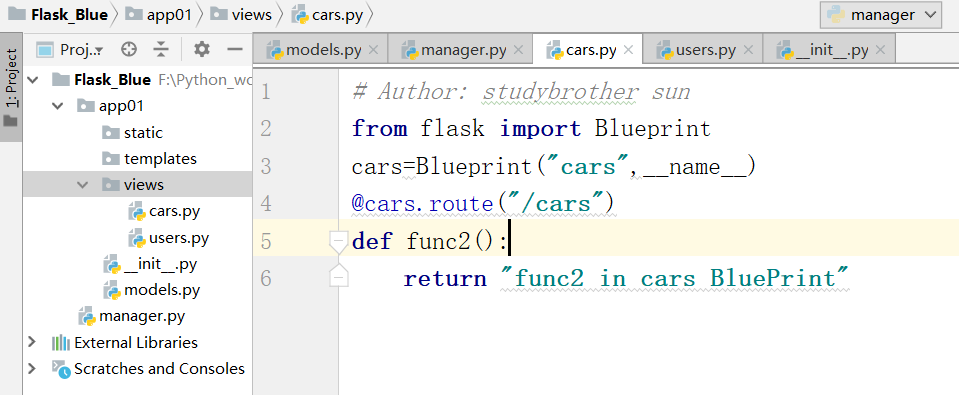
这个时候,我们再在,__init__.py里边写一些内容:
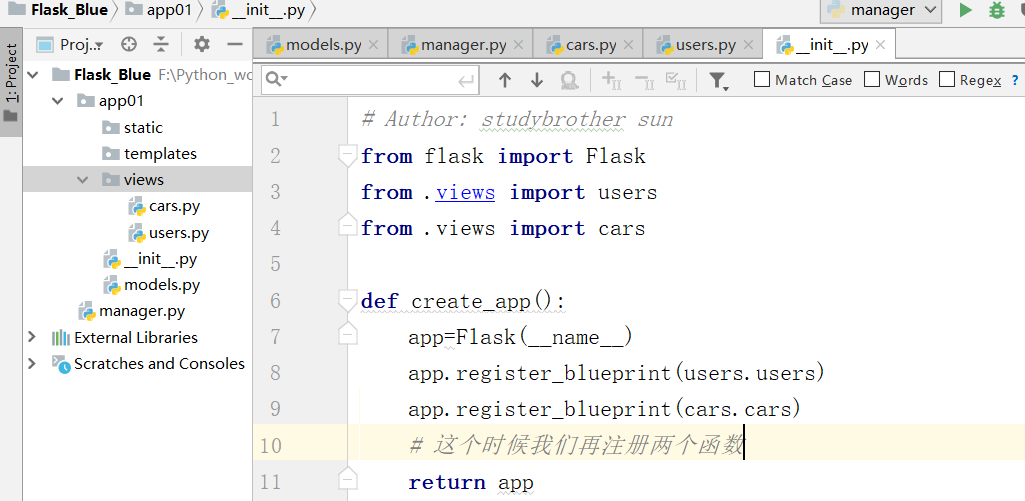
第一个cars指的是文件,第二个cars指的是蓝图对象.
这个时候,运行


上边就是一种模板描写的方式.
.Flask蓝图
Blueprint:
from flask import Blueprint
# 把Blueprint理解为 不能被 Run 的 Flask 对象 bp = Blueprint("bp",__name__,url_prefix="/user") @bp.route("/bp",methods=["GET","Post"])
def my_bp():
return "I am bp in user.py" app.py:
from flask import Flask
from user import bp
from acc import acc
app = Flask(__name__) app.register_blueprint(bp)
app.register_blueprint(acc) if __name__ == '__main__':
app.run(debug=True) .蓝图结构:
参考上边的截图
今日作业:
.使用蓝图做增删改查 add.py update.py delete.py select.py
.用所学进行增删改查在内存中进行
.应用Flask配置 Config
巨蟒python全栈开发flask2的更多相关文章
- 巨蟒python全栈开发linux之centos1
1.linux服务器介绍 2.linux介绍 3.linux命令学习 linux默认有一个超级用户root,就是linux的皇帝 注意:我的用户名是s18,密码是centos 我们输入密码,点击解锁( ...
- 巨蟒python全栈开发-第20天 核能来袭-约束 异常处理 MD5 日志处理
一.今日主要内容 1.类的约束(对下面人的代码进行限制;项目经理的必备技能,要想走的长远) (1)写一个父类,父类中的某个方法要抛出一个异常 NotImplementedError(重点) (2)抽象 ...
- 巨蟒python全栈开发linux之centos6
1.nginx复习 .nginx是什么 nginx是支持反向代理,负载均衡,且可以实现web服务器的软件 在129服务器中查看,我们使用的是淘宝提供的tengine,也是一种nginx服务器 我们下载 ...
- 巨蟒python全栈开发linux之centos3
1.作业讲解 (1)递归创建文件夹/tmp/oldboy/python/{alex,wusir,nvshen,xiaofeng} 下面中的路径没有必要换,在哪里创建都行,根目录下或者tmp目录下或者其 ...
- 巨蟒python全栈开发django5:组件&&CBV&FBV&&装饰器&&ORM增删改查
内容回顾: 补充反向解析 Html:{% url ‘别名’ 参数 %} Views:reverse(‘别名’,args=(参数,)) 模板渲染 变量 {{ 变量名 }} 逻辑相关 {% %} 过滤器: ...
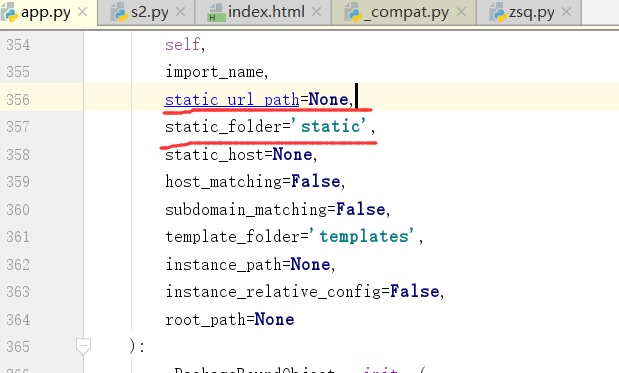
- 巨蟒python全栈开发-第11阶段 ansible_project2
一个NB的网站: https://www.toolfk.com/ CDN:将用户的需求送到最近的节点:内容分发网络 有些是专门做CDN的工具 常用的markdown是需要知道的,短信有字数限制. we ...
- 巨蟒python全栈开发-第4天 列表&元组&range
今日内容大纲 1. 什么是列表 定义: 能装对象的对象 在python中使用[]来描述列表, 内部元素用逗号隔开. 对数据类型没有要求 列表存在索引和切片. 和字符串是一样的. 2. 相关的增删改查操 ...
- 巨蟒python全栈开发-第13天 内置函数 匿名函数lambda
一.今日内容总览 1.内置函数(1):并不是每一个内置函数都是那么常用 上菜:内置函数部分//思维导图:https://www.processon.com/view/link/5b4ee15be4b0 ...
- 巨蟒python全栈开发-第14天 内置函数2 递归 二分查找
一.今日内容总览 1.内置函数补充 repr() 显示出字符串的官方表示形式 chr() arscii码中的字,转换成位置 ord() arscii码中的位置,转换成字2.递归 自己调用自己 两个口: ...
随机推荐
- 【LeetCode-面试算法经典-Java实现】【101-Symmetric Tree(对称树)】
[101-Symmetric Tree(对称树)] [LeetCode-面试算法经典-Java实现][全部题目文件夹索引] 原题 Given a binary tree, check whether ...
- 开始使用Bootstrap
bootstrap使用到的图标字体文件格式有 .woff,IIS7下需要添加MIME映射:.woff application/x-font-woff
- 에러 처리 HandleErrorAttribute
ExceptionInfo info = new ExceptionInfo(); info.Success = false; info.Message = filterContext.Excepti ...
- applicationCache
<html manifest="/m.appcache"> window.applicationCache.onupdateready = function (e) { ...
- struts2 在拦截器进行注入(依据Action是否实现自己定义接口)
比如:经常在Action中都须要获取当前登录的User,就须要获取Session.然后从Session获取当前登录的User,由于这些步骤都是反复操作,能够想办法在拦截器中进行实现.能够自己定义一个接 ...
- Bash中的括号(一)
初学Bash脚本编程,里面的各种括号,绝对是一个大坑,为了救人救己,以防再度入坑,特记录如下: 一.单小括号: 1.创建子Shell.单个小括号用来创建一个子shell,子shell允许你在不影响当前 ...
- CentOS6.x修改主机名,关闭防火墙
一.centos默认主机名为localhost,不方便管理,此次,我修改为noi. 1.修改网络配置文件:/etc/sysconfig/network 首先,备份一下源文件,注意date命令和加号之间 ...
- Atitit. html 使用js显示本地图片的设计方案.doc
Atitit. html 使用js显示本地图片的设计方案.doc 1. Local mode 是可以的..web模式走有的不能兰.1 2. IE8.0 显示本地图片 img.src=本地图片路径无 ...
- poj 1182 食物链 并查集的又一个用法
食物链 Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 41584 Accepted: 12090 Descripti ...
- SysTick—系统定时器
本章参考资料<ARM Cortex™-M4F 技术参考手册> -4.5 章节 SysTick Timer(STK), 和4.48 章节 SHPRx,其中 STK 这个章节有 SysTick ...