sql 生成随机数 以及不重复随机数
背景:想在表中随机取10条记录,让取出来的数据不重复(表中必须是有个递增列,且递增从1开始间隔为1)。
数据表:
CREATE TABLE testable
(
id INT IDENTITY(1,1),
myname NVARCHAR(1000),
insertedTime DATETIME DEFAULT SYSDATETIME()
)
表中共有100条数据,如下
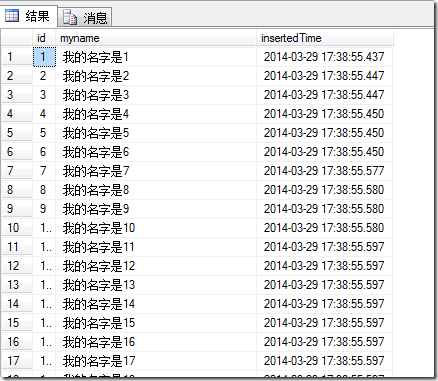 省略……
省略……
1. 首先想到的是MSSQL自带的newid()
采用这种方法时,需要将表中所有记录与newid()生成的值进行比较从而进行排序。因此,如果表中的记录较多,操作会非常缓慢。
USE Gift163DBgoSELECT TOP 14 * FROM dbo.testable ORDER BY NEWID()
缺点:1. 取出的10条数据会出现重复 2.当数据表数据很多的时候,速度将很慢 (每次重新计算newid)
2. 自定义函数返回一个表,表中记录的是随机生成的N个id值。
1)rand()生成随机数 rand()*count,CEILING,floor用法
2)如果临时表中无此数据,则放入,否则重新生成
3)直到N条记录已经生成
注意:标量函数function内不能出现rand()方法,变通下生成个view v_random,然后在函数内调用 v_random获取随机数
create view v_randomASselect CEILING(rand()*51) as random --注意51,生成的是1到51之间的数字,因为事先知道数据库中有51条记录go
自定义函数代码如下:
ALTER FUNCTION randomIntStringWithCommaSplit(@counts int) –counts 表明返回的个数RETURNS @t TABLE (filed1 int) --返回表@t,有个int类型的 field列ASBEGINDECLARE @randomInt INTDECLARE @i INTSET @i=0WHILE @i<@countsBEGINselect @randomInt= random FROM v_random--不能是 SET @randomInt=SELECT random FROM v_randomIF NOT EXISTS(SELECT TOP 1 * FROM @t WHERE filed1=@randomInt)BEGININSERT INTO @t VALUES (@randomInt)SET @i=@i+1ENDENDRETURNEND
上面函数返回的是一个表类型,表中有个int字段,存放要查找的N个不同的keyId (keyId为要查找表的递增列,且递增为1,从1开始递增)
所以返回的表中存放的数据是 dbo.Articles中的id列的值。
使用:调用上面的自定义函数返回10个不重复的id
SELECT * FROM randomIntStringWithCommaSplit(10)
下面是几次的执行结果,可以看到每个结果中都不存在重复的值(fidled1为临时表的唯一列)
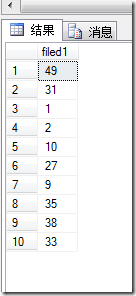
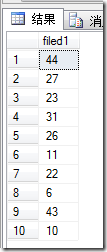
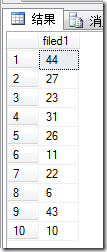
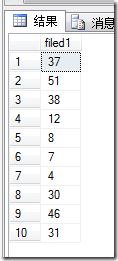
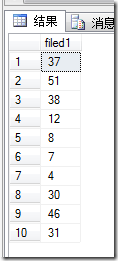
最后通过 select * from table where id in randomIntStringWithCommaSplit(10) ,这样就可以从table中随机取出10条不重复的数据来了。
3.存储过程取不重复的数据
--dbo.getRandomDataFromTable
--输入参数 @tableName nvarchar(100),--表名
---@dataCount nvarchar(100)--取N条数据
输出结果集:列id,存放N条要查询的数据
USE Gift163DBGOIF OBJECT_ID ( 'dbo.getRandomDataFromTable', 'P' ) IS NOT NULLDROP PROCEDURE dbo.getRandomDataFromTable;GOCREATE PROC [dbo].[getRandomDataFromTable]@tableName nvarchar(100),@dataCount nvarchar(100)ASBEGIN--SET NOCOUNT ON;DECLARE @t TABLE (id INT) --临时表DECLARE @i INT --临时变量DECLARE @randomInt INT --每次随机生成的整数DECLARE @tableCount INT --表的行数--先获取表中最大数据的idEXEC( 'SELECT '+@tableCount+'=COUNT(*) FROM '+@tableName+'')SET @i=0WHILE @i<@dataCountBEGINSELECT @randomInt=CEILING(RAND()*@tableCount)IF NOT EXISTS(SELECT TOP 1 * FROM @t)BEGININSERT INTO @t VALUES (@randomInt)SET @i=@i+1ENDEND--打印出取出的表的idSELECT * FROM @tENDGo
生成测试数据100条
USE Gift163DBGOif exists (select 1from sysobjectswhere id = object_id('testable')and type = 'U')drop table testablegoCREATE TABLE testable(id INT IDENTITY(1,1),myname NVARCHAR(1000),insertedTime DATETIME DEFAULT SYSDATETIME())//插入100条数据DECLARE @i INTSET @i=1WHILE @i<100BEGININSERT INTO tesTable (myname) VALUES ('我的名字是'+CONVERT(NVARCHAR, @i) ) --将 varchar 值 '我的名字是' 转换成数据类型 int 时失败。SET @i=@i+1End
调用上面的存储过程从表testable取10条不重复id
USE Gift163DBgoexec getRandomDataFromTable 'testable',10
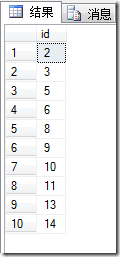
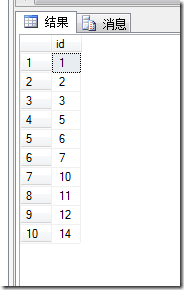
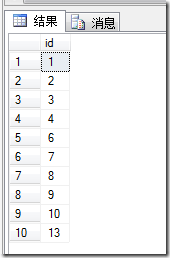
自定义的存储过程不会出现重复的记录
4.改进的存储过程,最终存储过程
输入参数3个:表名,表的递增列名 , 要取的N条数据
USE Gift163DBGOIF OBJECT_ID ( 'dbo.getRandomDataFromTable', 'P' ) IS NOT NULLDROP PROCEDURE dbo.getRandomDataFromTable;GOCREATE PROC [dbo].[getRandomDataFromTable]@tableName nvarchar(100),@identityKey NVARCHAR(100),@dataCount nvarchar(100)ASBEGIN--SET NOCOUNT ON;--DECLARE @t TABLE (id INT) --临时表DECLARE @i INT --临时变量DECLARE @randomInt INT --每次随机生成的整数DECLARE @tableCount INT --表的行数--先获取表中最大数据的idDECLARE @str NVARCHAR(3000)SET @str='SELECT @tableCount=COUNT(*) FROM '+@tableNameexec sp_executesql @str, N'@tableCount int output', @tableCount outputcreate TABLE #sdf (id int)SET @i=0WHILE @i<@dataCount AND @i<@tableCountBEGINSELECT @randomInt=CEILING(RAND()*@tableCount)IF NOT EXISTS(SELECT TOP 1 * FROM #sdf WHERE id=@randomInt)BEGININSERT INTO #sdf VALUES (@randomInt)SET @i=@i+1ENDEND--取出数据DECLARE @str2 NVARCHAR(2000)SET @str2=' SELECT * FROM '+@tableName+' where '+@identitykey+' in '+' (select id from #sdf )'PRINT @str2--select id from @tEXEC (@str2)--exec sp_executesql @str2,N'@t TABLE',@t OUTPUTEND
调用存储过程:随机取10条数据
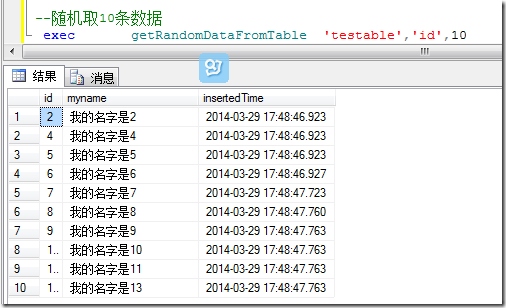
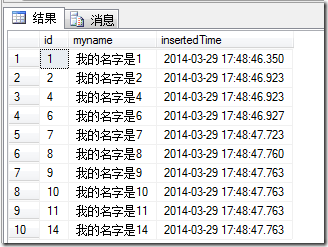
最终的存储过程不管你随机取多少条数据(只要每次取的数据数目小于表中行数) 就可以保证每次取的数据不会重复。当然前提是,取的表必须有个递增列,而且以1开始,递增1.
sql 生成随机数 以及不重复随机数的更多相关文章
- 动态生成16位不重复随机数、随机创建2位ID
/** 1. * 动态生成16位不重复随机数 * * @return */ public synchronized static String generate16() { StringBuffer ...
- js【生成规定数量不重复随机数】、【冒泡排序】、【鸡尾酒排序】、【选择排序】、【插入排序】、【未完工的二分插入排序】------【总结】
[生成规定数量不重复随机数] function creatRandom( num ){ var randomLen = num, ranArr = [], thisRan = null, whileO ...
- sql 生成某个范围内的随机数
从i-j的范围内的随机数,那么公式为FLOOR(i+RAND()*(j-i+1))
- SQL - 生成指定范围内的随机数
今天按照公司需求,需要做一个sql作业来对数据库定时触发,其中有个难点,就是在sql中需要在1-n中随机出来一个结果. google了半天,找到一个比较好的方式. 写下这个sql: DECLARE @ ...
- 【转】 SQL - 生成指定范围内的随机数
DECLARE @Result INT DECLARE @Upper INT DECLARE @Lower INT SET @Lower = 1 SET @Upper = 10 SELECT @Res ...
- Java数组实现随机生成N-M之间不重复的随机数
接收一个整形数组,使用Math.Random每次在规定的数字范围内随机产生数字,然后嵌套for循环依次判断是否有重复值,如果有既外循环变量减一,直到把数组装满为止. /** * 随机生成 N--M的不 ...
- C#生成不重复随机数列表
C#生成不重复(随机数 http://www.jbxue.com/tags/suijishu.html)列表实例的代码.例子: ; Random rnd = ; i < ...
- PHP函数:生成N个不重复的随机数
思路:将生成的随机数存入数组,再在数组中去除重复的值,即可生成一定数量的不重复随机数. 程序: <?php /* * array unique_rand( int $min, int $max, ...
- [转载]C# Random 生成不重复随机数
Random 类 命名空间:System 表示伪随机数生成器,一种能够产生满足某些随机性统计要求的数字序列的设备. 伪随机数是以相同的概率从一组有限的数字中选取的.所选数字并不具有完全的随机性,因为它 ...
随机推荐
- https://blog.newrelic.com/2014/05/02/25-php-developers-follow-online/
w https://blog.newrelic.com/2014/05/02/25-php-developers-follow-online/ 1. Rob Allen. Zend Framework ...
- 贪玩ML系列之一个BP玩一天
手写串行BP算法,可调batch_size 既要:1.输入层f(x)=x 隐藏层sigmoid 输出层f(x)=x 2.run函数实现单条数据的一次前馈 3.train函数读入所有数据for循环处理 ...
- Oracle 11g数据库详解
常见异常: ORA-14025:不能为实体化视图或实体化视图日志指定PARTITION ORA-14026:PARTITION和CLUSTER子句互相排斥 ORA-14027:仅可以指定一个PARTI ...
- idea导入项目出现Unable to import maven project: See logs for details提示(转载)
摘要: 从git上面check多工程项目后,maven不能正常下载相应的依赖,最后查询国外网站,找出错误原因.按照此步骤,可以自动配置好每个工程的module. 删除项目根目录下.idea文件夹 关闭 ...
- golang strings.Split的疑问
先看下面的代码 func main() { fmt.Println("Hello, 世界") cc:=[...]int{} b:="" a:=strings.S ...
- 修改hostname不重启机器并生效
1.依次执行: vi /etc/sysconfig/network 这种修改方式不会马上生效,需要重启服务器后生效,所以继续执行下面命令 echo ***(例如:node13 ...
- 如何实现关系表的级联删除(ON DELETE CASCADE的用法)
以下面两张表为例: SQL> desc person 名称 是否为空? 类型 --------------------- ...
- NUnit.Framework的使用方法演示
using NUnit.Framework; namespace CheckExcel { [TestFixture] public class TestExcelHelper { /// <s ...
- s5_day13作业
#对之前文件进行的增删改查操作实现日志操作,日志输出用户进行过的操作. def log(): import logging logger_obj=logging.getLogger() logger_ ...
- NIO服务端和客户端通信demo
代码转自 https://www.jianshu.com/p/a9d030fec081 服务端: package nio; import java.io.IOException; import jav ...