Coursera在线学习---第九节(1).异常数据检测(Anomaly Detection)
一、如何构建Anomaly Detection模型?

二、如何评估Anomaly Detection系统?
1)将样本分为6:2:2比例
2)利用交叉验证集计算出F1值,可以用F1值选取概率阈值ξ,选取使得F1值最大的那个ξ。
3)同时也可以根据训练集、交叉验证集、测试集来同样选取使用哪些特征变量更好。方法就是不断更换特征组合构建模型,利用交叉验证集计算F1值,并看测试集的效果等等。

三、什么时候用异常数据检测法,什么时候用有监督的分类方法?
1)一般来讲,当样本中有大量正常样本数据,而仅仅有少量异常点数据时,这个时候建议构建Anomaly Detection模型。因为异常样本太少,无法进行有效的监督训练;而此时因为有大量的正样本数据,可以有效的拟合高斯模型。当正样本与负样本数量都比较大的时候,可以采用有监督的学习方法,这就是两种方法的不同之处。
2)另一种不同在于,异常数据点的出现情况往往是多种多样、不可预测的。所以,这个时候只对正常数据样本拟合模型即可,不符合该模型的数据均可视为异常数据点。而有监督的学习方法需要有明确的正样本与负样本标签,让机器明白无误的去训练学习。
四、应用举例
网络欺骗登陆检测。如果收集了大量的网站欺骗行为数据,可以选择用监督方法来实现检测。如果少量欺骗行为数据,还是用Anomaly Detection方法比较好。
五、样本数据的分布转换
如果原始样本数据符合高斯分布(也叫正态分布),则可以直接拟合高斯模型。如果原始样本不符合高斯分布,则可以采用log(x)、log(x+c)、X^(1/2)、X^(1/3)等方法对原始样本进行转换,使其符合高斯分布。可以采用hist(x)画直方图看分布状态。


六、如何筛选特征变量?
尽量选取一些浮动不是特别大的变量,如果浮动大了,必然是异常数据了。也可以新增一些组合特征变量,比如:x1/x2,x1^2/x2等。
七、拟合多元高斯分布模型。
有这样一种情况,比如:x1与x2正常情况下是正相关的,但是出现了一个异常数据,就是x1突然变得很大,而x2则不是特别大。这种情况如果采用上述方法单独拟合模型,则检测不出该异常点,因为两个变量数据在各自分布中都是正常的。所以,一种方法就是新增特征组合x1/x2,另一种方法就是采用多元高斯分布。
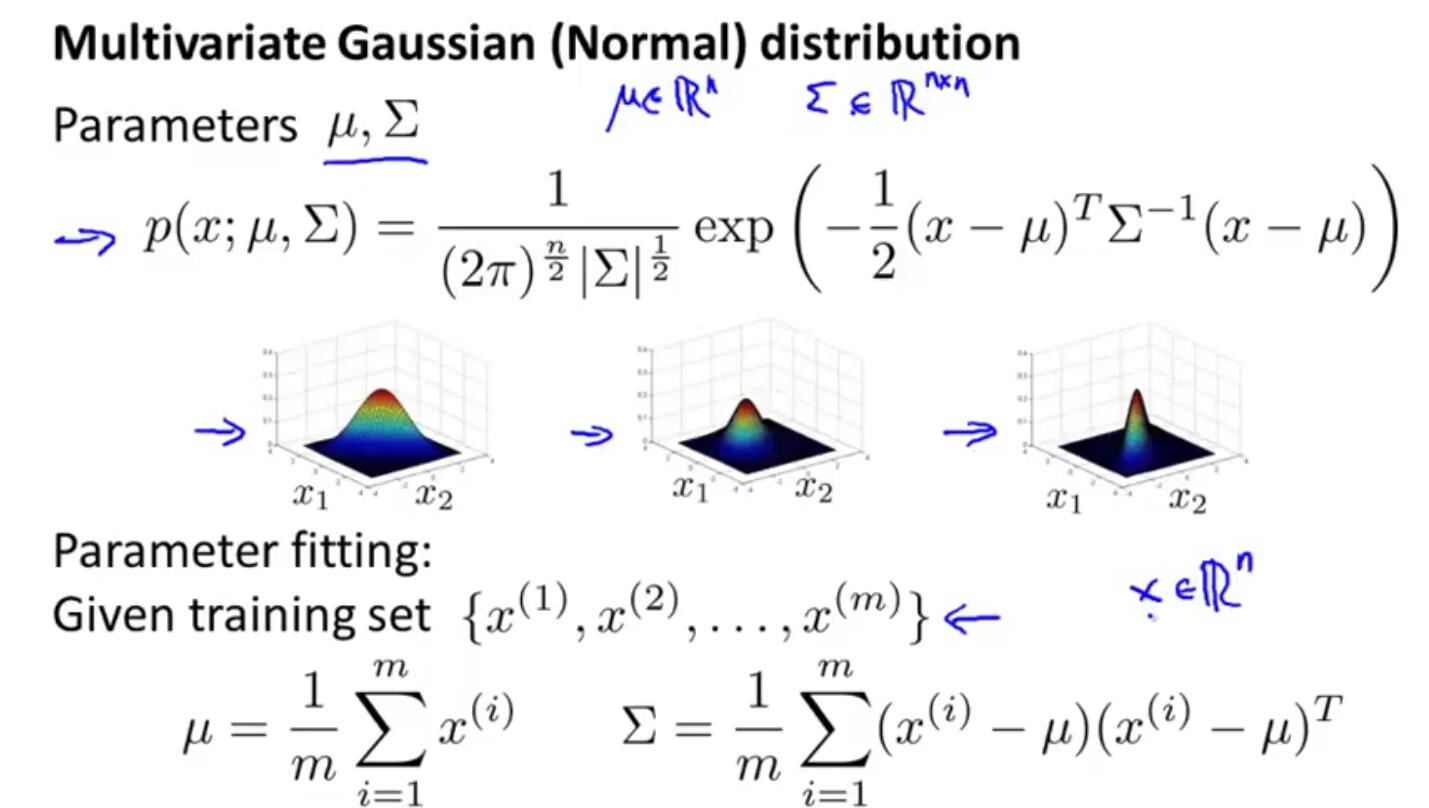
八、什么时候用一元高斯模型,什么时候用多元高斯模型?
一般来说,一元高斯模型用的较多,而多元高斯模型用的不多。但是,对于特征变量x1,x2的一些异常组合情况,多元高斯模型能够检测出来。一元高斯模型如果也想检测出该异常数据,需要增加新的特征组合。
综合来说,一元高斯模型计算量小一些,当特征维度n较大时,采用一元模型较好。而多元高斯模型需要计算矩阵,代价太大,而且还要求m>n(m为样本数量),否则矩阵为不可逆矩阵。当m约等于10倍n的数量之上时,用多元模型较好。
Coursera在线学习---第九节(1).异常数据检测(Anomaly Detection)的更多相关文章
- Coursera在线学习---第九节(2).推荐系统
一.基于内容的推荐系统(Content Based Recommendations) 所谓基于内容的推荐,就是知道待推荐产品的一些特征情况,将产品的这些特征作为特征变量构建模型来预测.比如,下面的电影 ...
- Coursera在线学习---第一节.梯度下降法与正规方程法求解模型参数比较
一.梯度下降法 优点:即使特征变量的维度n很大,该方法依然很有效 缺点:1)需要选择学习速率α 2)需要多次迭代 二.正规方程法(Normal Equation) 该方法可以一次性求解参数Θ 优点:1 ...
- Coursera在线学习---第二节.Octave学习
1)两个矩阵相乘 A*B 2)两个矩阵元素位相乘(A.B矩阵中对应位置的元素相乘) A.*B 3)矩阵A的元素进行平方 A.^2 4)向量或矩阵中的元素求倒数 1./V 或 1./A 5) ...
- 异常检测(Anomaly Detection)
十五.异常检测(Anomaly Detection) 15.1 问题的动机 参考文档: 15 - 1 - Problem Motivation (8 min).mkv 在接下来的一系列视频中,我将向大 ...
- [C10] 异常检测(Anomaly Detection)
异常检测(Anomaly Detection) 问题的动机 (Problem Motivation) 异常检测(Anomaly detection)问题是机器学习算法中的一个常见应用.这种算法的有趣之 ...
- 机器学习(十一)-------- 异常检测(Anomaly Detection)
异常检测(Anomaly Detection) 给定数据集
- 基于高斯分布的异常检测(Anomaly Detection)算法
记得在做电商运营初期,每每为我们频道的促销活动锁取得的“超高”销售额感动,但后来随着工作的深入,我越来越觉得这里面水很深.商家运营.品类运营不断的通过刷单来获取其所需,或是商品搜索排名,或是某种kpi ...
- 吴恩达机器学习笔记(九) —— 异常检测(Anomaly detection)
主要内容: 一.模型介绍 二.算法过程 三.算法性能评估及ε(threshold)的选择 四.Anomaly detection vs Supervised learning 五.Multivaria ...
- Coursera在线学习---第十节.大规模机器学习(Large Scale Machine Learning)
一.如何学习大规模数据集? 在训练样本集很大的情况下,我们可以先取一小部分样本学习模型,比如m=1000,然后画出对应的学习曲线.如果根据学习曲线发现模型属于高偏差,则应在现有样本上继续调整模型,具体 ...
随机推荐
- Python的time,datetime,string相互转换
#把datetime转成字符串 def datetime_toString(dt): return dt.strftime("%Y-%m-%d-%H") #把字符串转成dateti ...
- 第二章 持续集成jenkins工具使用之系统基本设置
Jenkin系统初始化成功后,会进入用户设置页面,设置用户信息后即可进入系统,如果没有设置用户,jenkins系统默认的用户是admin,密码administrator 1.1 Con ...
- Maven 3-Maven依赖版本冲突的分析及解决小结 (阿里,美团,京东面试)
举例A依赖于B及C,而B又依赖于X.Y,而C依赖于X.M,则A除引B及C的依赖包下,还会引入X,Y,M的依赖包(一般情况下了,Maven可通过<scope>等若干种方式控制传递依赖).这里 ...
- [转]matlab中squeeze函数的用法,numel的用法
squeeze的作用是移除单一维. 如果矩阵哪一个维数是1,B=squeeze(A)就将这个维数移除. 考虑2-by-1-by-3 数组Y = rand(2,1,3). 这个数组有单一维 —就是每页仅 ...
- 【bzoj5108】[CodePlus2017]可做题 拆位+乱搞
题目描述 给出一个长度为 $m$ 的序列 $a$ ,编号为 $a_1\sim a_m$,其中 $n$ 个位置的数已经确定,剩下的位置的数可以任意指定.现在令 $b$ 表示 $a$ 的前缀异或和,求 $ ...
- 【转】c# 类反射简单操作
转:http://www.jb51.net/article/25863.htm 首先建立一个测试的类 复制代码代码如下: public class MyClass { public int one ...
- [51nod1325]两棵树的问题
description 题面 solution 点分治+最小割. 点分必选的重心,再在树上dfs判交,转化为最大权闭合子图. 可以做\(k\)棵树的情况. code #include<iostr ...
- BZOJ5011 & 洛谷4065 & LOJ2275:[JXOI2017]颜色——题解
https://www.lydsy.com/JudgeOnline/problem.php?id=5011 https://www.luogu.org/problemnew/show/P4065 ht ...
- 实验三 Java敏捷开发与XP实践
北京电子科技学院(BESTI) 实 验 报 告 课程:Java程序设计 班级:1353 姓名:陈巧然 ...
- GCJ2008 APAC local onsites C Millionaire
自己Blog的第一篇文章,嗯... 接触这道题,是从<挑战程序设计竞赛>这本书看来的,其实头一遍读题解,并没有懂.当然现在已经理解了,想想当初可能是因为考虑两轮的那张概率图的问题.于是决定 ...