关于Web服务器的认识
马上就要毕业了,也要开始找工作了,大学写了这么多代码了,却没有好好总结一下常用的概念很是遗憾额,就通过这篇博客记录一下我最常用的一些知识好了。
说到Web服务器,有很多文章都介绍的很好,之前看到一篇非常不错的,对我帮助很大,可惜现在找不到原文了,看到博客园有人转载,我就在这里也记一下好了,在此非常感谢作者的分析,受益匪浅。
那么在说Web服务器之前,先说说线程、进程、以及并发连接数。
1.进程与线程
进程是具有一定独立功能的程序,关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。从逻辑角度来看,多线程的意义在于一个应用程序(进程)中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用来实现,而是作为进程来调度和管理以及资源分配。这就是进程和线程的重要区别,进程和线程的主要差别在于,进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。下面我们来说一说并发连接数。
2.并发连接数
(1).什么是最大并发连接数呢?
最大并发连接数是服务器同一时间能处理最大会话数量。
(2).何为会话?
我们打开一个网站就是一个客户端浏览器与服务端的一个会话,而我们浏览网页是基于http协议。
(3).HTTP协议如何工作?
HTTP支持两种建立连接的方式:非持久连接和持久连接(HTTP1.1默认的连接方式为持久连接)。
(4).浏览器与Web服务器之间将完成下列7个步骤
建立TCP连接
Web浏览器向Web服务器发送请求命令
Web浏览器发送请求头信息
Web服务器应答
Web服务器发送应答头信息
Web服务器向浏览器发送数据
Web服务器关闭TCP连接
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,但是浏览器一般其头信息加入了这行代码 Connection:keep-alive,TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接目的,节省了为每 个请求建立新连接所需的时间,还节约了网络带宽。
3.并发连接数的计算方法
用户下载服务器上的文件,则为一个连接,用户文件下载完毕后这个连接就消失了。有时候用户用迅雷的多线程方式下载的话,这一个用户开启了5个线程的话,就算是5个连接。
用户打开你的页面,就算停留在页面没有对服务器发出任何请求,那么在用户打开一面以后的15分钟内也都要算一个在线。
上面的情况用户继续打开同一个网站的其他页面,那么在线人数按照用户最后一次点击(发出请求)以后的15分钟计算,在这个15分钟内不管用户怎么点击(包括新窗口打开)都还是一人在线。
当用户打开页面然后正常关闭浏览器,用户的在线人数也会马上清除。
二、Web服务器提供服务的方式
Web服务器由于要同时为多个客户提供服务,就必须使用某种方式来支持这种多任务的服务方式。一般情况下可以有以下三种方式来选择,多进程方式、多线程方式及异步方式。其中,多进程方式中服务器对一个客户要使用一个进程来提供服务,由于在操作系统中,生成一个进程需要进程内存复制等额外的开销,这样在客户较多时的性能就会降低。为了克服这种生成进程的额外开销,可以使用多线程方式或异步方式。在多线程方式中,使用进程中的多个线程提供服务, 由于线程的开销较小,性能就会提高。事实上,不需要任何额外开销的方式还是异步方式,它使用非阻塞的方式与每个客户通信,服务器使用一个进程进行轮询就行了。
虽然异步方式最为高效,但它也有自己的缺点。因为异步方式下,多个任务之间的调度是由服务器程序自身来完成的,而且一旦一个地方出现问题则整个服务器就会出现问题。因此,向这种服务器增加功能,一方面要遵从该服务器自身特定的任务调度方式,另一方面要确保代码中没有错误存在,这就限制了服务器的功能,使得异步方式的Web服务器的效率最高,但功能简单,如Nginx服务器。
由于多线程方式使用线程进行任务调度,这样服务器的开发由于遵从标准,从而变得简单并有利于多人协作。然而多个线程位于同一个进程内,可以访问同样的内存空间,因此存在线程之间的影响,并且申请的内存必须确保申请和释放。对于服务器系统来讲,由于它要数天、数月甚至数年连续不停的运转,一点点错误就会逐渐积累而最终导致影响服务器的正常运转,因此很难编写一个高稳定性的多线程服务器程序。但是,不是不能做到时。Apache的worker模块就能很好的支持多线程的方式。
多进程方式的优势就在于稳定性,因为一个进程退出的时候,操作系统会回收其占用的资源,从而使它不会留下任何垃圾。即便程序中出现错误,由于进程是相互隔离的,那么这个错误不会积累起来,而是随着这个进程的退出而得到清除。Apache的prefork模块就是支持多进程的模块。
三、多进程、多线程、异步模式的对比
Web服务器总的来说提供服务的方式有三种,多进程方式,多线程的方式,异步方式。其中效率最高的是异步的方式,最稳定的是多进程方式,占用资源较少的是多线程的方式。
1.多进程
此种架构方式中,web服务器生成多个进程并行处理多个用户请求,进程可以按需或事先生成。有的web服务器应用程序为每个用户请求生成一个单独的进程来进行响应,不过,一旦并发请求数量达到成千上万时,多个同时运行的进程将会消耗大量的系统资源。(即每个进程只能响应一个请求或多个进程对应多个请求)
优点:
最大的优势就在于稳定性,一个进程出错不会影响其它进程。如,服务器同时连接100个请求对就的是100个进程,其中一个进程出错,只会杀死一个进程,还有99个进程继续响应用户请求。每个进程响应一个请求
缺点:
进程量大,进程切换次数过多,导致CPU资源使用效率低,每个进程的地址空间是独立的,很多空间中重复的数据,所以内存使用效率低,进程切换由于内核完成,占用CPU资源。
2.多线程
在多线程方式中,每个线程来响应一下请求,由于线程之间共享进程的数据,所以线程的开销较小,性能就会提高。
优点:
线程间共享进程数据,每个线程响应一个请求,线程切换不可避免(切换量级比较轻量),同一进程的线程可以共享进程的诸多资源,对内存的需求较之进程有很大下降,读可以共享,写不可以共享
缺点:
线程快速切换时会带来线程抖动,多线程会导致服务器不稳定
3.异步方式
一个进程或线程响应多个请求,不需要任何额外开销的,性能最高,占用资源最少。但也有问题一但进程或线程出错就会导致整个服务器的宕机。
四、Web 服务请求过程
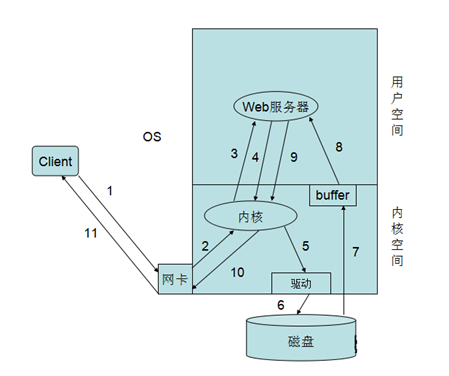
在上面的讲解中我们说明,Web服务器的如何提供服务的,有多进程的方式、多线程的方式还有异步方式我们先简单这么理解,后面我们慢慢说,现在我们不管Web服务器是如何提供服务的,多进程也好、多线程好,异步也罢。下面我们来说一下,一个客户端的具体请求Web服务的具体过程,从上图中我们可以看到有11步,下面我们来具体说一下,
1.首先我们客户端发送一个请求到Web服务器,请求首先是到网卡。2.网卡将请求交由内核空间的内核处理,其实就是拆包了,发现请求的是80端口。3.内核便将请求发给了在用户空间的Web服务器,Web服务器接受到请求发现客户端请求的index.html页面。4.Web服务器便进行系统调用将请求发给内核。5.内核发现在请求的是一页面,便调用磁盘的驱动程序,连接磁盘。6.内核通过驱动调用磁盘取得的页面文件。7.内核将取得的页面文件保存在自己的缓存区域中便通知Web进程或线程来取相应的页面文件。8.Web服务器通过系统调用将内核缓存中的页面文件复制到进程缓存区域中。9.Web服务器取得页面文件来响应用户,再次通过系统调用将页面文件发给内核。10.内核进程页面文件的封装并通过网卡发送出去。11.当报文到达网卡时通过网络响应给客户端
简单来说就是:用户请求-->送达到用户空间-->系统调用-->内核空间-->内核到磁盘上读取网页资源->返回到用户空间->响应给用户。上述简单的说明了一下,客户端向Web服务请求过程,在这个过程中,有两个I/O过程,一个就是客户端请求的网络I/O,另一个就是Web服务器请求页面的磁盘I/O。 下面我们就来说说Linux的I/O模型。
五、Linux I/O 模型
1.I/O模型分类
说明:我们都知道web服务器的进程响应用户请求,但无法直接操作I/O设备,其必须通过系统调用,请求kernel来协助完成I/O动作,如下图:
对于数据输入而言,即等待(wait)数据输入至buffer需要时间,而从buffer复制(copy)数据至进程也需要时间
根据等待模式不同,I/O动作可分为五种模式。
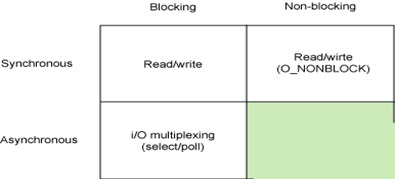
1.阻塞I/O,2.非阻塞I/O,3.I/O复用(select和poll),4.信号(事件)驱动I/O(SIGIO),5.异步I/O(Posix.1的aio_系列函数)
2.I/O模型的相关术语
(1).阻塞和非阻塞:
阻塞和非阻塞指的是执行一个操作是等操作结束再返回,还是马上返回。比如你去车站接朋友,这是一个操作。可以有两种执行方式。第一种,你这人特实诚,老早就到了车站一直等到车来了接到朋友为止。第二种,你到了车站,问值班的那趟车来了没有,“还没有”,你出去逛一圈,可能过会回来再问。第一种就是阻塞方式,第二种则是非阻塞的。我认为阻塞和非阻塞讲得是做事方法,是针对做事的人而言的。
(2).同步和异步:
同步和异步又是另外一个概念,它是事件本身的一个属性。比如老板让你去搬一堆石头,而且只让你一个人干,你只好自己上阵,最后的结果是搬完了,还是你砸到脚了,只有搬完了你才知道。这就是同步的事件。如果老板还给你个小弟,你就可以让小弟去搬,搬完了告你一声。这就变成异步的了。其实异步还可以分为两种:带通知的和不带通知的。前面说的那种属于带通知的。有些小弟干活可能主动性不是很够,不会主动通知你,你就需要时不时的去关注一下状态。这种就是不带通知的异步。 对于同步的事件,你只能以阻塞的方式去做。而对于异步的事件,阻塞和非阻塞都是可以的。非阻塞又有两种方式:主动查询和被动接收消息。被动不意味着一定不好,在这里它恰恰是效率更高的,因为在主动查询里绝大部分的查询是在做无用功。对于带通知的异步事件,两者皆可。而对于不带通知的,则只能用主动查询。
(3).I/O
回到I/O,不管是I还是O,对外设(磁盘)的访问都可以分成请求和执行两个阶段。请求就是看外设的状态信息(比如是否准备好了),执行才是真正的I/O操作。在Linux 2.6之前,只有“请求”是异步事件,2.6之后才引入AIO把“执行”异步化。别看Linux/Unix是用来做服务器的,这点上比Windows落后了好多,IOC(Windows上的AIO)在Win2000上就有了。
(4).总结
Linux上的前四种I/O模型的“执行”阶段都是同步的,只有最后一种才做到了真正的全异步。第一种阻塞式是最原始的方法,也是最累的办法。当然累与不累要看针对谁。应用程序是和内核打交道的。对应用程序来说,这种方式是最累的,但对内核来说这种方式恰恰是最省事的。还拿接人这事为例,你就是应用程序,值班员就是内核,如果你去了一直等着,值班员就省事了。当然现在计算机的设计,包括操作系统,越来越为终端用户考虑了,为了让用户满意,内核慢慢的承担起越来越多的工作,IO模型的演化也是如此。非阻塞I/O ,I/O复用,信号驱动式I/O其实都是非阻塞的,当然是针对“请求”这个阶段。非阻塞式是主动查询外设状态。I/O复用里的select,poll也是主动查询,不同的是select和poll可以同时查询多个fd(文件句柄)的状态,另外select有fd个数的限制。epoll是基于回调函数的。信号驱动式I/O则是基于信号消息的。这两个应该可以归到“被动接收消息”那一类中。最后就是伟大的AIO的出现,内核把什么事都干了,对上层应用实现了全异步,性能最好,当然复杂度也最高。
六、Linux I/O 模型具体说明
首先我们先来看一下,基本 Linux I/O 模型的简单矩阵,从图中我们可以看到的模型有,同步阻塞I/O(阻塞I/O)、同步非阻塞I/O(非阻塞I/O )、异步阻塞I/O(I/O复用),异步非阻塞I/O(有两种,信号驱动I/O和异步I/O)。好了现在就来具体说一说吧。
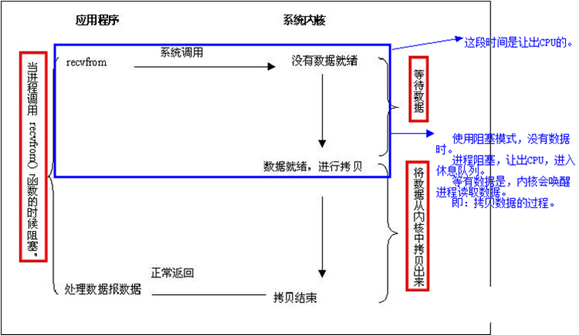
1.阻塞I/O
说明:应用程序调用一个IO函数,导致应用程序阻塞,等待数据准备好。 如果数据没有准备好,一直等待数据准备好了,从内核拷贝到用户空间,IO函数返回成功指示。这个不用多解释吧,阻塞套接字。下图是它调用过程的图示:(注,一般网络I/O都是阻塞I/O,客户端发出请求,Web服务器进程响应,在进程没有返回页面之前,这个请求会处于一直等待状态)
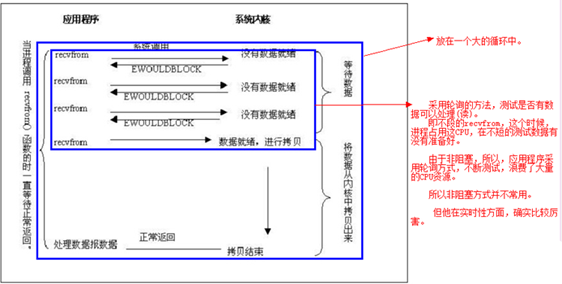
2.非阻塞I/O
我们把一个套接口设置为非阻塞就是告诉内核,当所请求的I/O操作无法完成时,不要将进程睡眠,而是返回一个错误。这样我们的I/O操作函数将不断的测试数据是否已经准备好,如果没有准备好,继续测试,直到数据准备好为止。在这个不断测试的过程中,会大量的占用CPU的时间,所有一般Web服务器都不使用这种I/O模型。具体过程如下图:
3.I/O复用(select和poll)
I/O复用模型会用到select或poll函数或epoll函数(Linux2.6以后的内核开始支持),这两个函数也会使进程阻塞,但是和阻塞I/O所不同的的,这两个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。具体过程如下图:
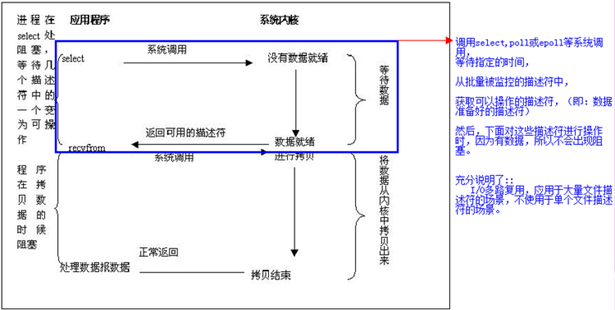
4.信号驱动I/O(SIGIO)
首先,我们允许套接口进行信号驱动I/O,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。具体过程如下图:
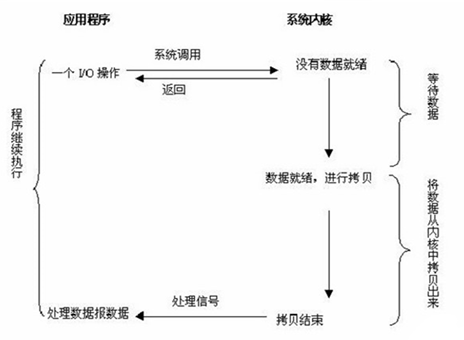
综上可以看出,越往后,阻塞越少,理论上效率也是最优。其五种I/O模型中,前三种属于同步I/O,后两者属于异步I/O。
同步I/O:
1.阻塞I/O,2.非阻塞I/O,3.I/O复用(select和poll)
异步I/O:
1.信号驱动I/O(SIGIO) (半异步),2.异步I/O(Posix.1的aio_系列函数) (真正的异步)
异步 I/O 和 信号驱动I/O的区别:
信号驱动 I/O 模式下,内核可以复制的时候通知给我们的应用程序发送SIGIO 消息。异步 I/O 模式下,内核在所有的操作都已经被内核操作结束之后才会通知我们的应用程序。
七、Linux I/O模型的具体实现
1.主要实现方式有以下几种:
select,poll,epoll,kqueue,/dev/poll,iocp
其中iocp是Windows实现的,select、poll、epoll是Linux实现的,kqueue是FreeBSD实现的,/dev/poll是SUN的Solaris实现的。select、poll对应第3种(I/O复用)模型,iocp对应第5种(异步I/O)模型,那么epoll、kqueue、/dev/poll呢?其实也同select属于同一种模型,只是更高级一些,可以看作有了第4种(信号驱动I/O)模型的某些特性,如callback机制。
2.为什么epoll、kqueue、/dev/poll比select高级?
答案是,他们无轮询。因为他们用callback取代了。想想看,当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll、kqueue、/dev/poll做的。这样子说可能不好理解,那么我说一个现实中的例子,假设你在大学读书,住的宿舍楼有很多间房间,你的朋友要来找你。select版宿管大妈就会带着你的朋友挨个房间去找,直到找到你为止。而epoll版宿管大妈会先记下每位同学的房间号,你的朋友来时,只需告诉你的朋友你住在哪个房间即可,不用亲自带着你的朋友满大楼找人。如果来了10000个人,都要找自己住这栋楼的同学时,select版和epoll版宿管大妈,谁的效率更高,不言自明。同理,在高并发服务器中,轮询I/O是最耗时间的操作之一,select、epoll、/dev/poll的性能谁的性能更高,同样十分明了。
3.Windows or *nix (IOCP or kqueue、epoll、/dev/poll)?
诚然,Windows的IOCP非常出色,目前很少有支持asynchronous I/O的系统,但是由于其系统本身的局限性,大型服务器还是在UNIX下。而且正如上面所述,kqueue、epoll、/dev/poll 与 IOCP相比,就是多了一层从内核copy数据到应用层的阻塞,从而不能算作asynchronous I/O类。但是,这层小小的阻塞无足轻重,kqueue、epoll、/dev/poll 已经做得很优秀了。
4.总结一些重点
只有IOCP(windows实现)是asynchronous I/O,其他机制或多或少都会有一点阻塞。select(Linux实现)低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善epoll(Linux实现)、kqueue(FreeBSD实现)、/dev/poll(Solaris实现)是Reacor模式,IOCP是Proactor模式。Apache 2.2.9之前只支持select模型,2.2.9之后支持epoll模型,Nginx 支持epoll模型,Java nio包是select模型
(完) by JonnyF
关于Web服务器的认识的更多相关文章
- 闲来无聊,研究一下Web服务器 的源程序
web服务器是如何工作的 1989年的夏天,蒂姆.博纳斯-李开发了世界上第一个web服务器和web客户机.这个浏览器程序是一个简单的电话号码查询软件.最初的web服务器程序就是一个利用浏览器和web服 ...
- 使用 Nodejs 搭建简单的Web服务器
使用Nodejs搭建Web服务器是学习Node.js比较全面的入门教程,因为要完成一个简单的Web服务器,你需要学习Nodejs中几个比较重要的模块,比如:http协议模块.文件系统.url解析模块. ...
- Ubuntu下利用Mono,Jexus搭建Asp.Net(MVC) Web服务器
最近在Ubuntu上搭建了Asp.Net的Web服务器,其中遇到很多问题,整理一下思路,以备后用. 搭建环境以及配套软件 Ubuntu: 11.10 Mono:3.0.6 下载地址(http://do ...
- Raspkate - 基于.NET的可运行于树莓派的轻量型Web服务器
最近在业余时间玩玩树莓派,刚开始的时候在树莓派里写一些基于wiringPi库的C语言程序来控制树莓派的GPIO引脚,从而控制LED发光二极管的闪烁,后来觉得,是不是可以使用HTML5+jQuery等流 ...
- 一不小心写了个WEB服务器
开场 Web服务器是啥玩意? 是那个托管了我的网站的机器么? No,虽然那个也是服务器,但是我们今天要说的Web服务器主要是指像IIS这样一类的,用于处理request并返回response的工具,没 ...
- NodeJs+http+fs+request+cheerio 采集,保存数据,并在网页上展示(构建web服务器)
目的: 数据采集 写入本地文件备份 构建web服务器 将文件读取到网页中进行展示 目录结构: package.json文件中的内容与上一篇一样:NodeJs+Request+Cheerio 采集数据 ...
- 前端学HTTP之WEB服务器
前面的话 Web服务器每天会分发出数以亿计的Web页面,它是万维网的骨干.本文主要介绍WEB服务器的相关内容 总括 Web服务器会对HTTP请求进行处理并提供响应.术语“Web服务器”可以用来表示We ...
- 基于轻量型Web服务器Raspkate的RESTful API的实现
在上一篇文章中,我们已经了解了Raspkate这一轻量型Web服务器,今天,我们再一起了解下如何基于Raspkate实现简单的RESTful API. 模块 首先让我们了解一下"模块&quo ...
- 自己实现一个简易web服务器
一个web服务器是网络应用中最基础的环节. 构建需要理解三个内容: 1.http协议 2.socket类 3.服务端实现原理 1.1 HTTP http请求 一般一个http请求包括以下三个部分: 1 ...
- apachetop 实时监测web服务器运行状况
apachetop 实时监测web服务器运行状况 我们经常会需要知道服务器的实时监测服务器的运行状况,比如哪些 URL 的访问量最大,服务器每秒的请求数,哪个搜索引擎正在抓取我们网站?面对这些问题 ...
随机推荐
- 架构和模式的区别:三层架构和MVC在应用开发中的位置
架构是系统层面的,可以是多层架构,也可以是事件驱动架构,也可以是微服务架构. 模式是GUI应用的一种职责分离设计. 三层架构(包含多层架构)和 MVC模式(包含MVP, MVVM) 没什么关系,它们不 ...
- xml编辑器
cstring转cha型方法在mfc中用过可行 int CstringToch(CString str, char *ch) { assert(ch); memset(ch, 0, sizeof(ch ...
- vue.js 使用小结
2016年12月10日 17:18:42 星期六 情景: 主要介绍 v-for 循环时对变量的处理方法 主要以table标签为例 1. 为 tr 标签动态添加属性 <tr v-for=" ...
- appium实现截图和清空EditText
前些日子,配置好了appium测试环境,至于环境怎么搭建,参考:http://www.cnblogs.com/tobecrazy/p/4562199.html 知乎Android客户端登陆:htt ...
- Reverse Core 第三部分 - 21章 - Windows消息钩取
@author: dlive @date: 2016/12/19 0x01 SetWindowsHookEx() HHOOK SetWindowsHookEx( int idHook, //hook ...
- ffmpeg 常用命令
mp4中的h264编码,而h264有两种封装: 一种是annexb模式,传统模式,有startcode,SPS和PPS是在ES中:另一种是mp4模式,一般mp4.mkv.avi会没有startcode ...
- 编译器--__attribute__ ((packed))
1. __attribute__ ((packed)) 的作用就是告诉编译器取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐,是GCC特有的语法.这个功能是跟操作系统没关系,跟编译器有关,g ...
- 【笔记】mysql两条数据的某个属性值互换
update groupuser as g1 join groupuser as g2 on (g1.user_id=1 and g2.user_id = 2) or(g1.user_id = 2 a ...
- TO BUY
// book 人月神话 // hardware 乐视.凯酷一生黑 HHKB 白无刻 Filco 奶酪绿 G600 // Book 重构 改善既有代码的设计 java与模式 人月神话(40周年中文纪念 ...
- Spring——集成JPA
配置文件如下:<applicationContext.xml> <?xml version="1.0" encoding="UTF-8"?&g ...