python3爬取百度图片(2018年11月3日有效)
最终目的:能通过输入关键字进行搜索,爬取相应的图片存储到本地或者数据库
首先打开百度图片的网站,搜索任意一个关键字,比如说:水果,得到如下的界面
分析:
1、百度图片搜索结果的页面源代码不包含需要提取的图片信息,需要借助Chrome调试工具(F12调出)分析请求的URL地址
2、图片显示页面没有翻页按钮,但是页面一直往下拉会生成新的图片,这是典型的AJAX数据
F12打开调试工具,刷新网页,点击选中Network选项卡中的XHR标签(这个标签加载的就是AJAX请求),此时只能看到一条loginfo开头的信息,字面上可以理解为和登录相关的内容,先不管它

把网页往下拖动,可以看到有新的信息加载出来

这些加载出来的都是以acjson开头的信息,点击之后查看Headers、Preview、Response标签,可以看出来这里面包含了我们需要的图片信息
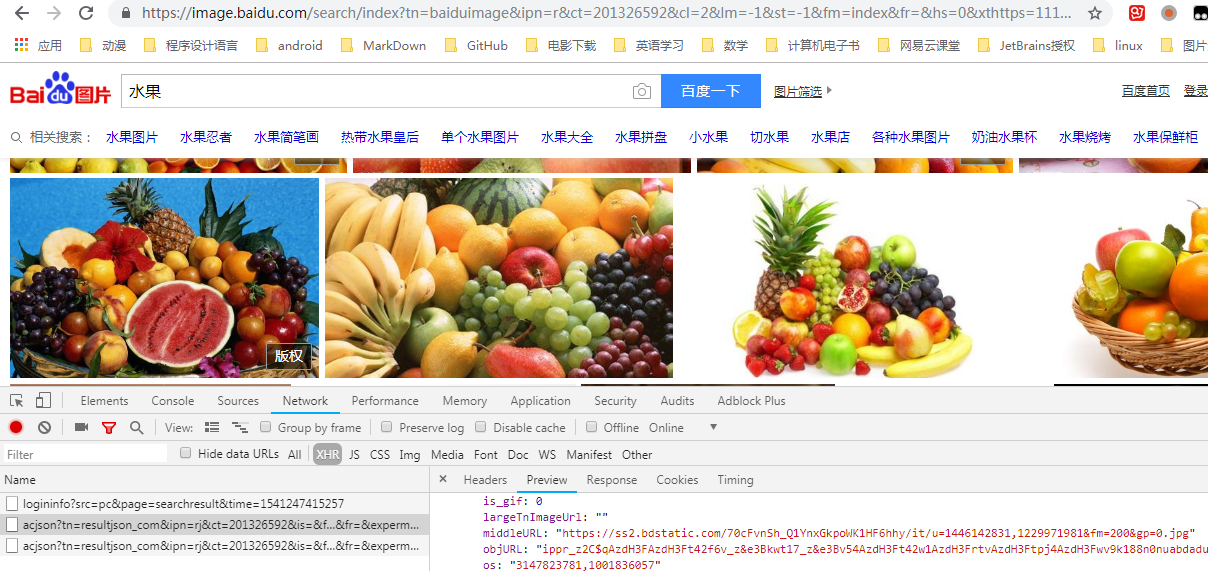
对比一下这几条信息的headers中Request URL可以得出参数中有三个值在变化,一个psm,一个pn,还有一个14。。。开头的数字,经过测试可以发现,实际上pn的值是最关键的,它影响翻页,其他两个可有可无。(对比url建议用一些在线代码对比工具,要不然眼睛要瞎)
下面开始写代码:
一、请求网页,获取html文本(百度图片有防盗链,加个Referer)
# 获取动态页面返回的文本
def get_page_html(page_url):
headers = {
'Referer': 'https://image.baidu.com/search/index?tn=baiduimage',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
try:
r = requests.get(page_url, headers=headers)
if r.status_code == 200:
r.encoding = r.apparent_encoding
return r.text
else:
print('请求失败')
except Exception as e:
print(e)
二、使用正则表达式提取真实图片的地址(选的是小图,大图在objURL里,需要经过简单的解密)
# 从文本中提取出真实图片地址
def parse_result(text):
url_real = re.findall('"thumbURL":"(.*?)",', text)
return url_real
三、请求图片的url,返回content(图片信息需要以二进制写入)
# 获取图片的content
def get_image_content(url_real):
headers = {
'Referer': url_real,
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
try:
r = requests.get(url_real, headers=headers)
if r.status_code == 200:
r.encoding = r.apparent_encoding
return r.content
else:
print('请求失败')
except Exception as e:
print(e)
四、保存图片(因为是测试,我写的是绝对地址,正常需要用相对地址)
# 将图片的content写入文件
def save_pic(url_real, content):
root = 'D://baiduimage//'
path = root + url_real.split('/')[-1]
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
with open(path, 'wb') as f:
f.write(content)
print('图片{}保存成功,地址在{}'.format(url_real, path))
else:
pass
五、定义一个主函数(百度图片每次最多请求30张,即使改了其他请求参数也最多60张)
# 主函数
def main():
keyword = input('请输入你要查询的关键字: ')
'''
按照标准, URL 只允许一部分 ASCII 字符(数字字母和部分符号),其他的字符(如汉字)是不符合 URL 标准的。
所以 URL 中使用其他字符就需要进行 URL 编码。python3中使用urllib.parse.quote进行编码
'''
keyword_quote = urllib.parse.quote(keyword)
depth = int(input("请输入要爬取的页数(每页30张图): "))
for i in range(depth):
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord+=&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&word={}&z=&ic=0&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&step_word={}&pn={}&rn=30&gsm=1e&1541136876386='.format(
keyword_quote, keyword_quote, i * 30)
html = get_page_html(url)
real_urls = parse_result(html)
for real_url in real_urls:
content = get_image_content(real_url)
save_pic(real_url, content)
六、最后写一个函数入口
# 函数入口
if __name__ == '__main__':
main()
当然,实现整个过程最好是先把整体的框架写好,那样思路最清晰。
关于百度图片的爬取就到这里,源代码地址:传送门
python3爬取百度图片(2018年11月3日有效)的更多相关文章
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- python3爬取女神图片,破解盗链问题
title: python3爬取女神图片,破解盗链问题 date: 2018-04-22 08:26:00 tags: [python3,美女,图片抓取,爬虫, 盗链] comments: true ...
- python 3 爬取百度图片
python 3 爬取百度图片 学习了:https://blog.csdn.net/X_JS612/article/details/78149627
- Python 爬虫实例(1)—— 爬取百度图片
爬取百度图片 在Python 2.7上运行 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Author: loveNight import jso ...
- selenium+chrome浏览器驱动-爬取百度图片
百度图片网页中中,当页面滚动到底部,页面会加载新的内容. 我们通过selenium和谷歌浏览器驱动,执行js,是浏览器不断加载页面,通过抓取页面的图片路径来下载图片. from selenium im ...
- Apache Struts最新漏洞 远程代码执行漏洞预警 2018年11月08日
2018年11月8日,SINE安全监控检测中心,检测到Apache Struts官方更新了一个Struts漏洞补丁,这个漏洞是Apache Struts目前最新的漏洞,影响范围较广,低于Apache ...
- CocoaPods管理iOS项目 2018年11月06日
一.创建Test工程项目 二.打开终端 当前pod版本(1.6.0.beta.2最新版本2018年11月06日)和gem源路径(https://gems.ruby-china.com): 1.cd+当 ...
- python3爬取1024图片
这两年python特别火,火到博客园现在也是隔三差五的出现一些python的文章.各种开源软件.各种爬虫算法纷纷开路,作为互联网行业的IT狗自然看的我也是心痒痒,于是趁着这个雾霾横行的周末瞅了两眼,作 ...
随机推荐
- P1338 末日的传说
题目描述 只要是参加jsoi活动的同学一定都听说过Hanoi塔的传说:三根柱子上的金片每天被移动一次,当所有的金片都被移完之后,世界末日也就随之降临了. 在古老东方的幻想乡,人们都采用一种奇特的方式记 ...
- powershell入门教程-v0.3版
powershell入门教程-v0.3版 来源 https://www.itsvse.com/thread-3650-1-1.html 参考 http://www.cnblogs.com/piapia ...
- CTSC2018 & APIO2018 颓废 + 打铁记
CTSC2018 & APIO2018 颓废 + 打铁记 CTSC 5 月 6 日 完美错过报道,到酒店领了房卡放完行李后直接奔向八十中拿胸牌.饭票和资料.试机时是九省联考的题,从来没做过,我 ...
- Android:Google出品的序列化神器Protocol Buffer使用攻略
习惯用 Json.XML 数据存储格式的你们,相信大多都没听过Protocol Buffer Protocol Buffer 其实 是 Google出品的一种轻量 & 高效的结构化数据存储格式 ...
- BZOJ4869 [Shoi2017]相逢是问候 【扩展欧拉定理 + 线段树】
题目链接 BZOJ4869 题解 这题调得我怀疑人生,,结果就是因为某些地方\(sb\)地忘了取模 前置题目:BZOJ3884 扩展欧拉定理: \[c^a \equiv c^{a \mod \varp ...
- 安徽师大附中%你赛day7 T2 乘积 解题报告
乘积 题目背景 \(\mathrm{Smart}\) 最近在潜心研究数学, 他发现了一类很有趣的数字, 叫做无平方因子数. 也就是这一类数字不能够被任意一个质数的平方整除, 比如\(6\).\(7\) ...
- HDU 2639 01背包求第k大
Bone Collector II Time Limit: 5000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others ...
- sqrti128
求平方根下取整,对于gcc type __uint128_t. ~45.5ns/op on i7-7700k@4.35G,即typical <200cyc/op. Together with u ...
- [BZOJ3275]Number解题报告|网络流
Description 有N个正整数,需要从中选出一些数,使这些数的和最大.若两个数a,b同时满足以下条件,则a,b不能同时被选1:存在正整数C,使a*a+b*b=c*c2:gcd(a,b)=1 这道 ...
- 【洛谷 P1251】 餐巾计划问题 (费用流)
题目链接 我做的网络流24题里的第一题.. 想是不可能想到的,只能看题解. 首先,我们拆点,将一天拆成晚上和早上,每天晚上会受到脏餐巾(来源:当天早上用完的餐巾,在这道题中可理解为从原点获得),每天早 ...