(数据科学学习手札18)二次判别分析的原理简介&Python与R实现
上一篇我们介绍了Fisher线性判别分析的原理及实现,而在判别分析中还有一个很重要的分支叫做二次判别,本文就对二次判别进行介绍:
二次判别属于距离判别法中的内容,以两总体距离判别法为例,对总体G1,,G2,当他们各自的协方差矩阵Σ1,Σ2不相等时,判别函数因为表达式不可化简而不再是线性的而是二次的,这时使用的构造二次判别函数进行判别类别的方法叫做二次判别法,下面分别在R和Python中实现二次判别:
R
在R中,常用的二次判别函数qda(formula,data)集成在MASS包中,其中formula形式为G~x1+x2+x3,G表示类别变量所在列的名称,~右端连接的累加式表示用来作为特征变量的元素对应的列名称,data为包含前面所述各变量的数据框,下面对鸢尾花数据进行二次判别,这里因为样本量较小,故采用bootstrap自助法进行抽样以扩充训练集与验证集,具体过程如下:
rm(list=ls())
library(MASS) #挂载鸢尾花数据
data(iris)
data <- iris #bootstrap法产生训练集
sam <- sample(1:length(data[,1]),10000,replace = T)
train_data <- data[sam,] #bootstrap法产生测试集
sam <- sample(1:length(data[,1]),2000,replace = T)
test_data <- data[sam,] #训练二次判别模型
qd <- qda(Species~.,data=train_data) #保存预测结果
pr <- predict(qd,test_data[,1:4])
#打印混淆矩阵
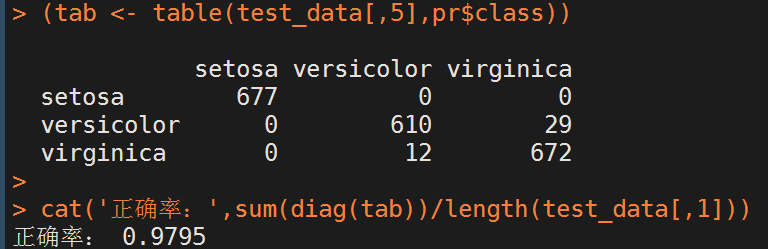
(tab <- table(test_data[,5],pr$class))
#打印分类正确率
cat('正确率:',sum(diag(tab))/length(test_data[,1]))
分类结果如下:
Python
这里和前一篇线性判别相似,我们使用sklearn包中的discriminant_analysis.QuadraticDiscriminantAnalysis来进行二次判别,依旧是对鸢尾花数据进行分类,这里和前一篇一样采用留出法分割训练集与验证集,具体代码如下:
'''Fisher线性判别分析'''
import numpy as np
from sklearn import datasets
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.model_selection import train_test_split iris = datasets.load_iris() X = iris.data
y = iris.target '''二次判别器''' '''利用sklearn自带的样本集划分方法进行分类,这里选择训练集测试集73开'''
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
'''搭建LDA模型'''
qda = QuadraticDiscriminantAnalysis()
'''利用分割好的训练集进行模型训练并对测试集进行预测'''
qd = qda.fit(X_train,y_train).predict(X_test)
'''比较预测结果与真实分类结果'''
print(np.array([qd,y_test]))
'''打印正确率'''
print('正确率:',str(round(qda.score(X_test,y_test),2)))

以上就是关于二次判别的简要内容,如有笔误之处望指出。
(数据科学学习手札18)二次判别分析的原理简介&Python与R实现的更多相关文章
- (数据科学学习手札17)线性判别分析的原理简介&Python与R实现
之前数篇博客我们比较了几种具有代表性的聚类算法,但现实工作中,最多的问题是分类与定性预测,即通过基于已标注类型的数据的各显著特征值,通过大量样本训练出的模型,来对新出现的样本进行分类,这也是机器学习中 ...
- (数据科学学习手札13)K-medoids聚类算法原理简介&Python与R的实现
前几篇我们较为详细地介绍了K-means聚类法的实现方法和具体实战,这种方法虽然快速高效,是大规模数据聚类分析中首选的方法,但是它也有一些短板,比如在数据集中有脏数据时,由于其对每一个类的准则函数为平 ...
- (数据科学学习手札16)K-modes聚类法的简介&Python与R的实现
我们之前经常提起的K-means算法虽然比较经典,但其有不少的局限,为了改变K-means对异常值的敏感情况,我们介绍了K-medoids算法,而为了解决K-means只能处理数值型数据的情况,本篇便 ...
- (数据科学学习手札29)KNN分类的原理详解&Python与R实现
一.简介 KNN(k-nearst neighbors,KNN)作为机器学习算法中的一种非常基本的算法,也正是因为其原理简单,被广泛应用于电影/音乐推荐等方面,即有些时候我们很难去建立确切的模型来描述 ...
- (数据科学学习手札26)随机森林分类器原理详解&Python与R实现
一.简介 作为集成学习中非常著名的方法,随机森林被誉为“代表集成学习技术水平的方法”,由于其简单.容易实现.计算开销小,使得它在现实任务中得到广泛使用,因为其来源于决策树和bagging,决策树我在前 ...
- (数据科学学习手札24)逻辑回归分类器原理详解&Python与R实现
一.简介 逻辑回归(Logistic Regression),与它的名字恰恰相反,它是一个分类器而非回归方法,在一些文献里它也被称为logit回归.最大熵分类器(MaxEnt).对数线性分类器等:我们 ...
- (数据科学学习手札144)使用管道操作符高效书写Python代码
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,一些比较熟悉pandas的读者 ...
- (数据科学学习手札94)QGIS+Conda+jupyter玩转Python GIS
本文完整代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 QGIS随着近些年的发展,得益于其开源免费 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
随机推荐
- mysql导入csv格式文件
今天测试导入csv格式文件,虽然简单但是如果不注意还是会出现错误,而且mysql在某些方面做的确实对新手不是很友好,记录一下:创建一个csv格式文件:[mysql@xxx1 ycrdb]$ more ...
- 修改CPAN安装源
更新CPAN镜像源的方法,以CentOS 6.5为例. 存储CPAN设置信息的文件路径为: /usr/share/perl/CPAN/Config.pm 使用vi打开文件 vi /usr/share/ ...
- selenium启动不了浏览器或者启动后不会写入网址,先更新下浏览器驱动
平时自动化习惯用Chrome浏览器.有几个月没用selenium启动IE和Firefox,今天跑兼容性测试,需要验证其他浏览器.结果遇到两个异常: 1 IE启动不了,直接报错. 2 Firefox启动 ...
- 使用 Android 客户端向 Ruby on rails 构建的 Web Application 提交 HTTP GET 和 HTTP POST 请求
最近想弄个能访问 Internet 的 Android 应用,因为求快所以用了 Ruby on Rails 来提供 HTTP 资源.这方面的资料还是比较少的,所以把尝试的过程记录下来. 1 使用 Ru ...
- HDU 2647 拓扑排序
题意:每个人的工资至少888,然后有m个条件,前者比后者要多.求最少工资. 分析: 最开始的开邻接矩阵的肯定超时,如果dfs,会出现由于刚开始不是从入度为0的点出发,后期修改不了.比较麻烦. 正确方式 ...
- springmvc时间(date)无法转入后台(@DateTimeFormat+@JsonFormat(GMT+8))
spring时间(date)无法转入后台 Type Status Report Description The server cannot or will not process the reques ...
- video object detection
先说一下,我觉得近两年最好的工作吧.其他的,我就不介绍了,因为我懂得少. 微软的jifeng dai的工作. Deep Feature Flow github: https://github.co ...
- mysql慢查询开启及分析方法
最近服务维护的公司的DB服务器,总是会出现问题,感觉需要优化一下了,登陆上去,发现慢查询日志都没有开,真是惭愧, 故果断加上慢查询日志, 经过分析sql记录,发现问题很多,开发人员很多没有对sql优化 ...
- repo配置与连接
repo是远程访问android源码的工具,和git一起使用. repo的远程安装经常被屏蔽,你懂得. sudo apt-get install curl 244 sudo apt-get - ...
- Struts-Core jar包
密码t6mp https://pan.baidu.com/share/init?surl=E--zExzI9-VY1zaT8F9i9w