Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5、PyCharm开发工具、Windows 10 操作系统、谷歌浏览器
目的:爬取豆瓣电影排行榜中电影的title、链接地址、图片、评价人数、评分等
网址:https://movie.douban.com/chart
语法要点:
xpath语法:
谷歌浏览器安装 xpath helper插件:帮助我们从elements中定位数据
1、选择节点(标签)
(1)、/html/head/meta:能够选中html下的所有的meta标签
(2)、//li:当前页面上的所有的li标签
(3)、/html/head//link:head下的所有link标签
2、//:能够从任意节点开始选择
(1)、//li:当前页面上的所有的li标签
(2)、/html/head//link:head下的所有的link标签
3、@符号的用途
(1)、选择具体某个元素://div[@class='feed']/ul/li,选择class='feed'的div下的ul下的li
(2)、a/@href:选择a的href的值
4、获取文本
(1)、/a/text():获取a下的文本
(2)、/a//text():获取a下的所有文本
示例:
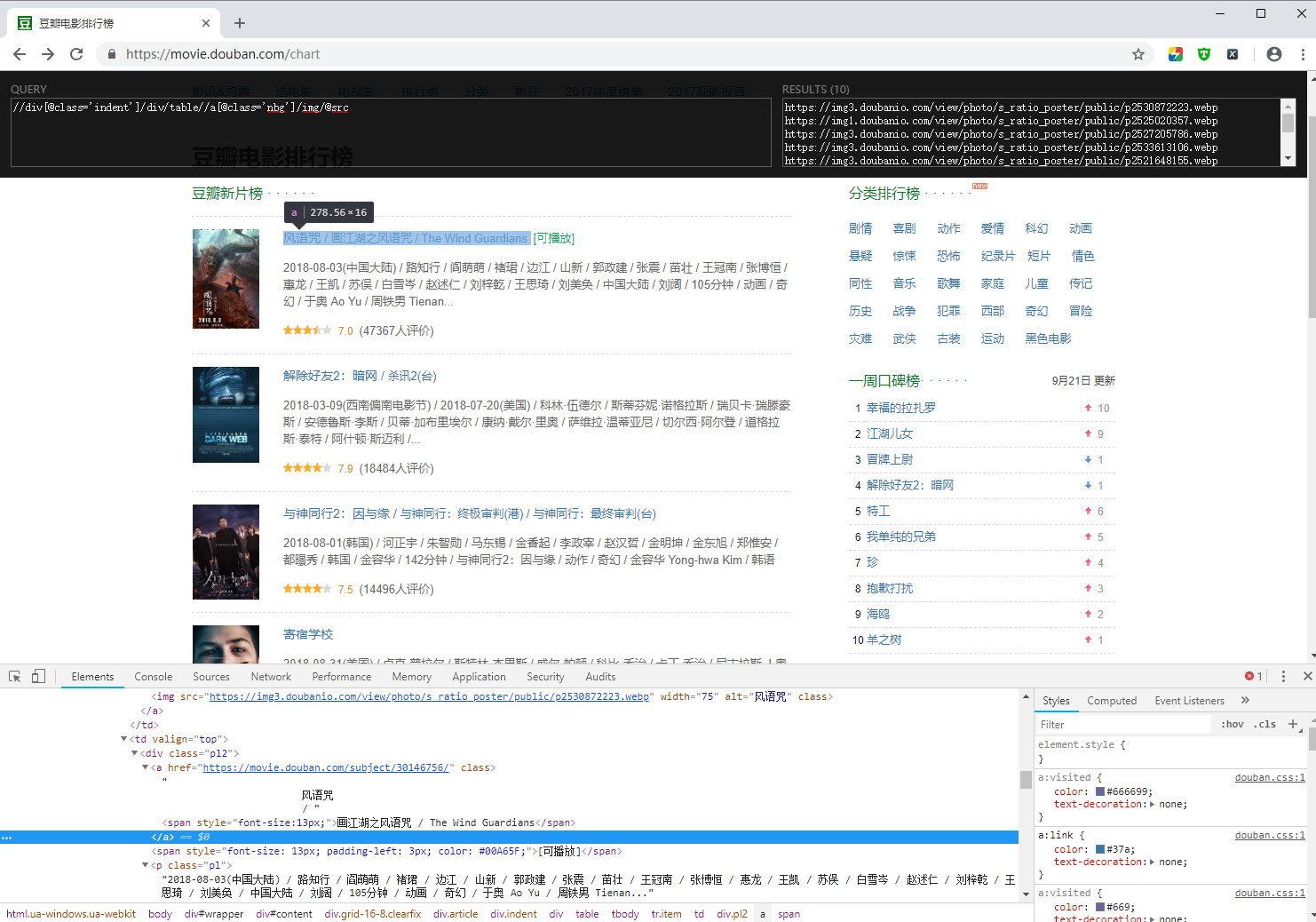
lxml语法:
1、安装:pip install lxml
2、使用
from lxml import etree
element = etree.HTML("html字符串")
element.xpath("")
代码:
from lxml import etree
import requests url = "https://movie.douban.com/chart" headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
response = requests.get(url,headers=headers)
html_str = response.content.decode() #print(html_str) html = etree.HTML(html_str)
print(html) #1.获取所有的电影的URL地址
#url_list = html.xpath("//div[@class='indent']/div/table//div[@class='pl2']/a/@href")
#print(url_list) #2.所有图片的地址
#img_list = html.xpath("//div[@class='indent']/div/table//a[@class='nbg']/img/@src")
#print(img_list)
ret1 = html.xpath("//div[@class='indent']/div/table")
print(ret1)
for table in ret1:
item = {}
item["title"] = table.xpath(".//div[@class='pl2']/a/text()")[0].replace("/","").strip()
item["href"] = table.xpath(".//div[@class='pl2']/a/@href")[0]
item["img"] = table.xpath(".//a[@class='nbg']/img/@src")[0]
item["comment_num"] = table.xpath(".//span[@class='pl']/text()")[0]
item["rating_num"] = table.xpath(".//span[@class='rating_nums']/text()")[0]
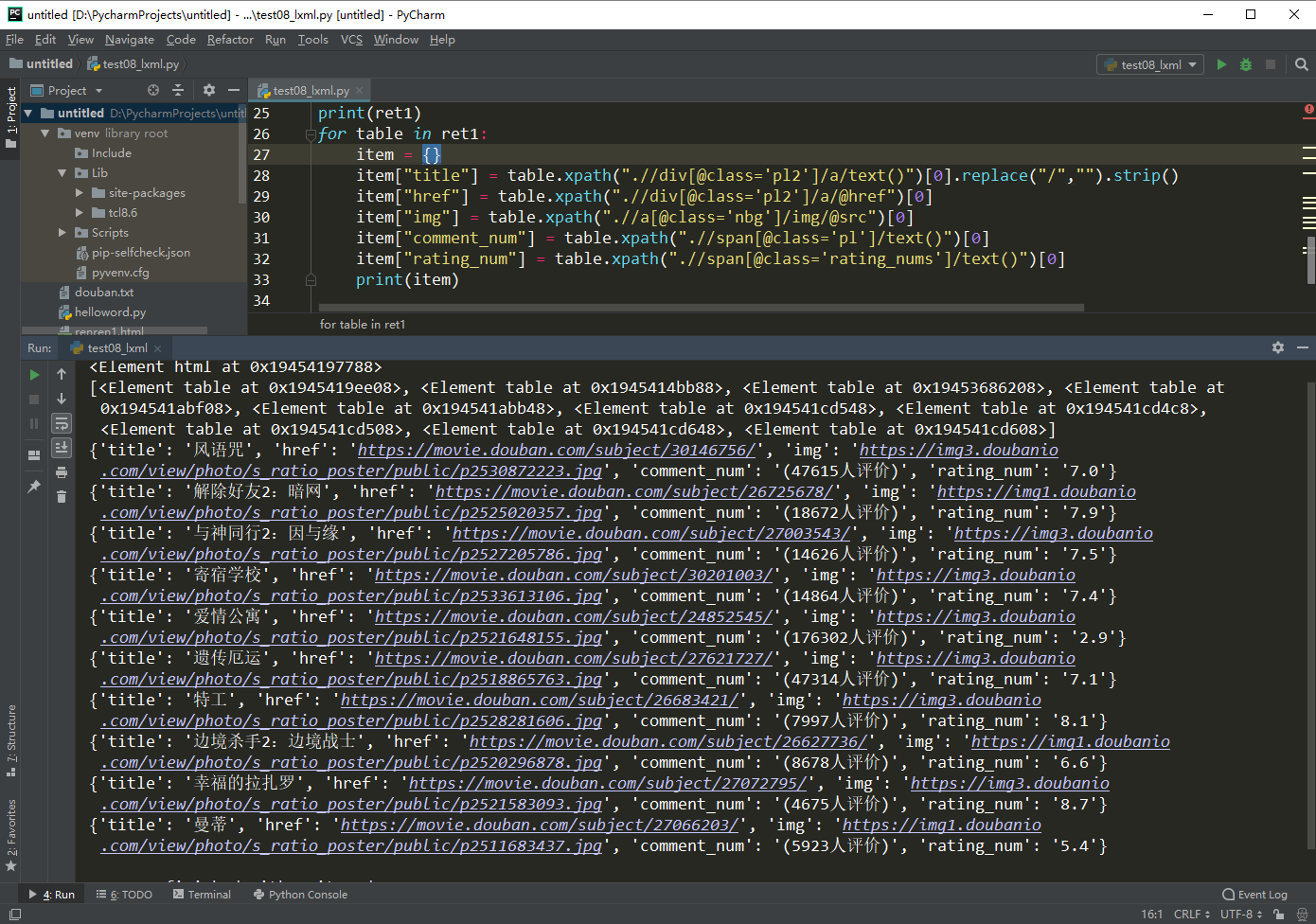
print(item)
运行效果:
Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块的更多相关文章
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- python爬虫-爬取豆瓣电影数据
#!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:27# 文件 :spider_05.py# IDE :PyChar ...
- Python爬虫爬取豆瓣电影名称和链接,分别存入txt,excel和数据库
前提条件是python操作excel和数据库的环境配置是完整的,这个需要在python中安装导入相关依赖包: 实现的具体代码如下: #!/usr/bin/python# -*- coding: utf ...
- Python爬虫-爬取豆瓣电影Top250
#!usr/bin/env python3 # -*- coding:utf-8-*- import requests from bs4 import BeautifulSoup import re ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
随机推荐
- 【Mysql】—— 报错:Can't call commit when autocommit=true
java.sql.SQLException: Can't call commit when autocommit=true at com.mysql.jdbc.SQLError.createSQLEx ...
- ORA-01795: 列表中的最大表达式数为1000的解决方法
IN中的数据量不能超过1000条. 解决方案:把条件分成多个少于1000的IN即: DELETEFROMT_MM_SECTION_SITE_UPDATEWHERE T.T_MM_SECTION_SL_ ...
- NodeJS服务器端平台实践记录
[2015 node.js learning notes]by lijun 01-note Nodejs是服务器端的javascript,是一种单线程.异步I/O.事件驱动型的javascript:其 ...
- UVA 12333 大数,字典树
题意:给一个数字,看他最小是第几个菲波那切数列的前缀. 分析: 大数模板就是吊哦. 将菲波那切数列前500个数字放到字典树上.注意插入的时候不能像普通一样,只在尾节点处标记,而是一路标记下去. #in ...
- 动态规划(DP),0-1背包问题
题目链接:http://poj.org/problem?id=3624 1.p[i][j]表示,背包容量为j,从i,i+1,i+2,...,n的最优解. 2.递推公式 p[i][j]=max(p[i+ ...
- python+requests实现接口测试 - get与post请求使用
简介:Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满足 ...
- Android学习笔记_14_对JSON格式数据的处理
public class ParseJsonTest extends AndroidTestCase{ public void testJson() throws Exception { String ...
- Python—面向对象 封装03
接着上面的一篇继续往下: 如何隐藏 在python中用双下划线开头的方式将属性隐藏起来(设置成私有的) class A: __x = 1 # _A__x = 1 def __init__(self, ...
- 自动诊断档案库(ADR)学习
(1)ADR概述 Oracle 11g的FDI(Fault Diagnosability Infrastructure)是自动化诊断方面的一个增强,其核心组件为自动诊断库(Automatic Diag ...
- 如何使用 SSL 证书配置端口
创建使用自承载的 Windows Communication Foundation (WCF) 服务时WSHttpBinding类,使用传输安全,还必须使用 X.509 证书配置端口. 如果不是在创建 ...