【Python3 爬虫】04_urllib.request.urlretrieve
urllib模块提供的urlretrieve()函数,urlretrieve()方法直接将远程的数据下载到本地
urllib语法
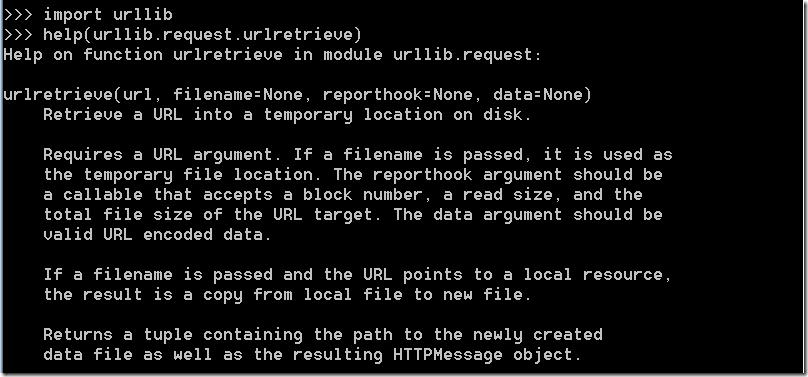
参数url:传入的网址,网址必须得是个字符串
参数filename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
参数reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
参数data:指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
下面整个例子是将hao6v的页面抓取到本地
# -*- coding:UTF-8 -*- from urllib import request """
urlretrieve参数说明:
1.传入网址,网址的类型一定是字符串 2.传入的,本地的网页保存路径+文件名 3.一个函数的调用,我们可以随便定义这个函数,但是必须得有3个参数
①到目前为此传递的数据块数量
②是每个数据块的大小,单位是byte,字节
③远程文件的大小
""" def callback(a1,a2,a3): """
@a1:目前为此传递的数据块数量
@a2:每个数据块的大小,单位是byte,字节
@a3:远程文件的大小
"""
download_pg = 100.0*a1*a2/a3
if download_pg > 100:
download_pg = 100 print("%.2f%%" %download_pg,) url = "http://www.hao6v.com/"
local = "C:\\Users\\Administrator\\Desktop\\hellobi.html"
request.urlretrieve(url,local,callback)
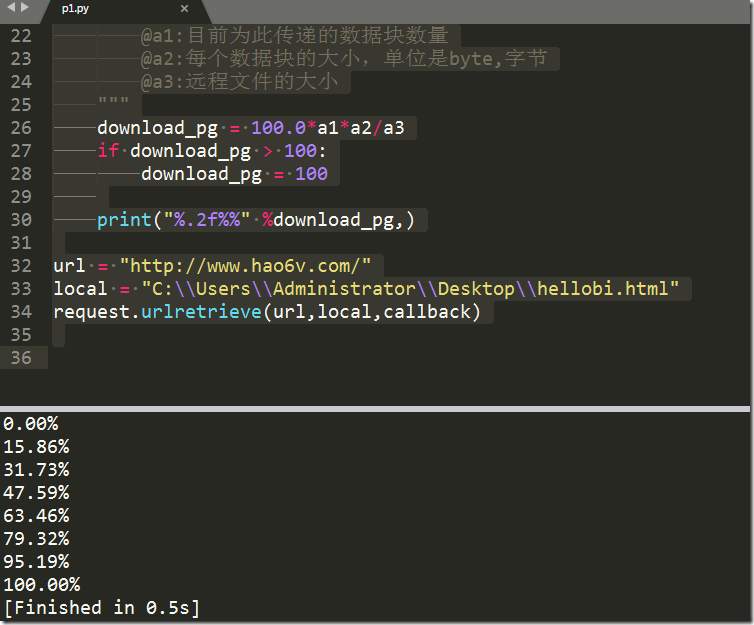
从上图我们可以看出,我们已经把网页成功爬取到本地,在本地桌面可以看到该页面,使用浏览器打开以后跟原页面一模一样(如果有CSS,则页面效果存在差异)
【Python3 爬虫】04_urllib.request.urlretrieve的更多相关文章
- python3.6 urllib.request库实现简单的网络爬虫、下载图片
#更新日志:#0418 爬取页面商品URL#0421 更新 添加爬取下载页面图片功能#0423 更新 添加发送邮件功能# 优化 爬虫异常处理.错误页面及空页面处理# 优化 爬虫关键字黑名单.白名单,提 ...
- python实战——网络爬虫之request
Urllib库是python中的一个功能强大的,用于操做URL,并在做爬虫的时候经常要用到的库,在python2中,分为Urllib和Urllib2两个库,在python3之后就将两个库合并到Urll ...
- python3爬虫.4.下载煎蛋网妹子图
开始我学习爬虫的目标 ----> 煎蛋网 通过设置User-Agent获取网页,发现本该是图片链接的地方被一个js函数代替了 于是全局搜索到该函数 function jandan_load_im ...
- 【Python3 爬虫】14_爬取淘宝上的手机图片
现在我们想要使用爬虫爬取淘宝上的手机图片,那么该如何爬取呢?该做些什么准备工作呢? 首先,我们需要分析网页,先看看网页有哪些规律 打开淘宝网站http://www.taobao.com/ 我们可以看到 ...
- python3爬虫:下载网易云音乐排行榜
#!/usr/bin/python3# -*- encoding:utf-8 -*- # 网易云音乐批量下载 import requestsimport urllib # 榜单歌曲批量下载# r = ...
- Python3 爬虫之 Scrapy 核心功能实现(二)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的搭建过程请参照本人的另一篇博客:Python3 爬虫之 Scrap ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- python3爬虫 爬取动漫视频
起因 因为本人家里有时候网速不行,所以看动漫的时候播放器总是一卡一卡的,看的太难受了.闲暇无聊又F12看看.但是动漫网站却无法打开控制台.这就勾起了我的兴趣.正好反正无事,去寻找下视频源. 但是这里事 ...
- python3 爬虫五大模块之五:信息采集器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
随机推荐
- 利其器之webstorm快捷键
总结几个webstorm常用的快捷键(macbook下) 最实用: command + option + 左/右箭头 定位到历史记录中上次/下次编辑的位置 command + b ...
- 【转】学一点Git--20分钟git快速上手
看到一篇不错的Git的简单入门教程,转过来给自己留个底. 原文地址:http://www.cnblogs.com/shuidao/p/3535299.html 在Git如日中天的今天,不懂git都不好 ...
- 如何成为云计算大数据Spark高手
Spark是发源于美国加州大学伯克利分校AMPLab的集群计算平台,它立足于内存计算,性能超过Hadoop百倍,从多迭代批量处理出发,兼收并蓄数据仓库.流处理和图计算等多种计算范式,是罕见的全能选手. ...
- Codeforces Round #406 (Div. 2) D. Legacy (线段树建图dij)
D. Legacy time limit per test 2 seconds memory limit per test 256 megabytes input standard input out ...
- c++基础学习之函数与参数
1.传值参数 //传值参数 int Abc(int a,int b,int c) { ; } a,b和c是函数Abc 的形式参数formal parameter,类型均为整型.如果在如下语句中调用函数 ...
- 在MYSQL中插入当前时间,就象SQLSERVER的GETDATE()一样,以及对mysql中的时间日期操作。
在看sql教程的时候,我学的是mysql,但是教程上面的一点在mysql里面是不支持的,所以就找了其他的替代的办法 sql教程上面是这样的: 通过使用类似 GETDATE() 这样的函数,DEFAUL ...
- [Atcoder Grand Contest 002] Tutorial
Link: AGC002 传送门 A: …… #include <bits/stdc++.h> using namespace std; int a,b; int main() { sca ...
- 【二分】【动态规划】Codeforces Round #393 (Div. 1) B. Travel Card
水dp,加个二分就行,自己看代码. B. Travel Card time limit per test 2 seconds memory limit per test 256 megabytes i ...
- 【贪心】bzoj3709 [PA2014]Bohater
把怪分成两类看: 一.回血>损血 则若先杀损血少的再杀损血多的,则为当前这一步提供了更高的可能性.因为血量是单增的,所以尽量用较少的血量去干♂耗血较少的怪物. 二.回血<损血 则若先杀回血 ...
- ubuntu下python3及idle3的安装
一.使用以下命令检查自己的系统下是否有python3 python3 --version 如果出现类似“command not found",则说明你需要安装python3.如果能够出现py ...