使用 URLDecoder 和 URLEncoder 对中文字符进行编码和解码
原文: https://blog.csdn.net/justloveyou_/article/details/57156039
使用 URLDecoder 和 URLEncoder 对中文字符进行编码和解码
摘要:
URLDecoder 和 URLEncoder 用于完成普通字符串 和 application/x-www-form-urlencoded MIME 字符串之间的相互转换。在本文中,我们以使用URLDecoder解决GET请求中文乱码问题为场景说明 URLDecoder/URLEncoder 的用法,并给出了 application/x-www-form-urlencoded MIME 字符串的编码规则。
一. URLDecoder/URLEncoder 使用场景概述
URLDecoder 和 URLEncoder 用于完成普通字符串 和 application/x-www-form-urlencoded MIME 字符串之间的相互转换。在介绍 application/x-www-form-urlencoded MIME 字符串之前,我们先考虑如下场景,如下图所示:

我们知道,在我们向客户端发起请求时,浏览器会根据请求URL生成相应的请求报文发送给服务器。在这个过程中,如果我们在浏览器中的地址栏中所输入的URL包含中文字符时,浏览器首先会将这些中文字符进行编码然后再发送给服务器。实际上,浏览器会将它们转换为 application/x-www-form-urlencoded MIME 字符串,如下图所示:
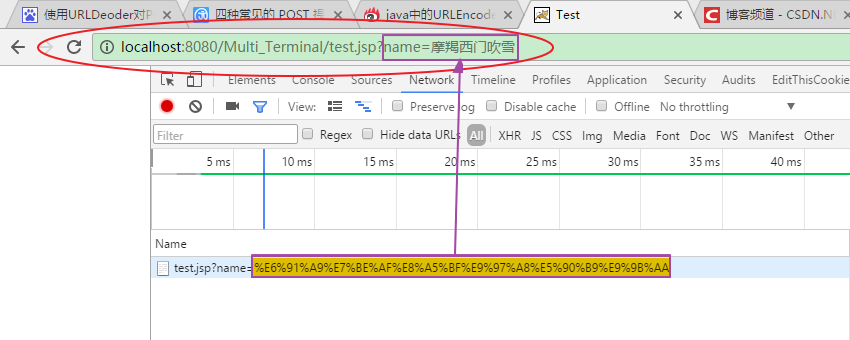
更确切的,当URL地址里包含非西欧字符的字符串时,浏览器都会将这些非西欧字符串转换成application/x-www-form-urlencoded MIME 字符串。在开发过程中,我们可能涉及将普通字符串和这种特殊字符串的相关转换,这就需要使用 URLDecoder 和 URLEncoder类进行实现,其中:
URLDecoder类包含一个decode(String s,String enc)静态方法,它可以将application/x-www-form-urlencoded MIME字符串转成普通字符串;
URLEncoder类包含一个encode(String s,String enc)静态方法,它可以将普通字符串转换成application/x-www-form-urlencoded MIME字符串。
下面程序示范了普通字符串转与 application/x-www-form-urlencoded MIME 字符串之间的转化。
public class URLDecoderTest {
public static void main(String[] args) throws Exception {
// 将application/x-www-form-urlencoded字符串转换成普通字符串
// 其中的字符串直接从上图所示窗口复制过来,chrome 默认用 UTF-8 字符集进行编码,所以也应该用对应的字符集解码
System.out.println("采用UTF-8字符集进行解码:");
String keyWord = URLDecoder.decode("%E5%A4%A9%E6%B4%A5%E5%A4%A7%E5%AD%A6+Rico", "UTF-8");
System.out.println(keyWord);
System.out.println("\n 采用GBK字符集进行解码:");
System.out.println(URLDecoder.decode("%E5%A4%A9%E6%B4%A5%E5%A4%A7%E5%AD%A6+Rico", "GBK"));
// 将普通字符串转换成application/x-www-form-urlencoded字符串
System.out.println("\n 采用utf-8字符集:");
String urlStr = URLEncoder.encode("天津大学", "utf-8");
System.out.println(urlStr);
System.out.println("\n 采用GBK字符集:");
String urlStr2 = URLEncoder.encode("天津大学", "GBK");
System.out.println(urlStr2);
}
}/* Output:
采用UTF-8字符集进行解码:
天津大学 Rico
采用GBK字符集进行解码:
澶╂触澶у Rico
采用utf-8字符集:
%E5%A4%A9%E6%B4%A5%E5%A4%A7%E5%AD%A6
采用GBK字符集:
%CC%EC%BD%F2%B4%F3%D1%A7
*///:~特别地,仅包含西欧字符的普通字符串和application/x-www-form-urlencoded MIME字符串无须转换,而包含中文字符的普通字符串则需要转换,转换的方法是每个中文字符占2个字节,每个字节可以转换成2个十六进制的数字,所以每个中文字符将转换成“%XX%XX”的形式。当然,采用不同的字符集时,每个中文字符对应的字节数并不完全相同,所以使用URLEncoder和URLDecoder进行转换时也需要指定字符集。特别地,字符串应以同样的字符集进行编码和解码,否则会产生意想不到的结果,如上述程序示例所示。
二. 解决GET请求中文乱码问题
URLDecoder的一个应用场景就是解决GET请求的中文乱码问题,如下述代码所示:
<%@page import="java.net.URLDecoder"%>
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<html>
<head>
<title>Test</title>
</head>
<body>
<%
String param1 = request.getQueryString();
String param2 = URLDecoder.decode(param1, "utf-8");
out.print(param2.split("=")[1] + "<br>");
%>
</body>
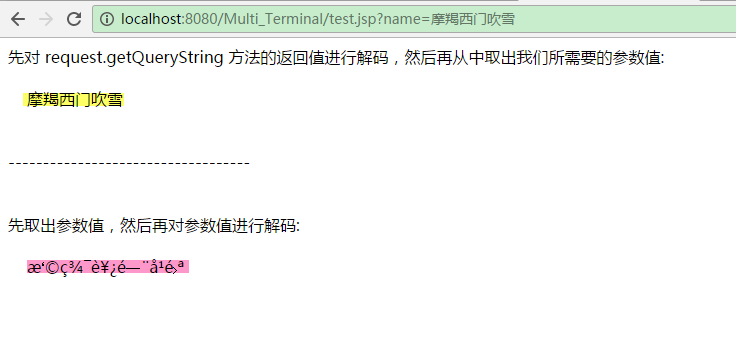
</html>特别需要注意的是,使用此方式对GET请求参数进行解码时,我们必须先对 request.getQueryString 方法的返回值(例如,“name=摩羯西门吹雪”)进行解码,然后再从中取出我们所需要的参数值。如果先取出参数值,然后再对参数值进行解码,则我们将得到乱码,如下图所示:
此外,对于包含中文字符的POST请求参数,我们只需在获取请求参数前通过以下代码语句进行转码即可:
request.setCharacterEncoding("utf-8");- 1
三. URLEncoder & URLDecoder
对 String 编码时,使用以下规则:
- 字母、数字和字符, “a” 到 “z”、”A” 到 “Z” 和 “0” 到 “9” 保持不变;
- 特殊字符 “.”、”-“、”*” 和 “_” 保持不变;
- 空格字符 ” ” 转换为一个加号 “+”。
除此之外,所有的其他字符都是不安全的。因此需要使用一些编码机制将它们转换为一个或多个字节,每个字节用一个包含 3 个字符的字符串 “%xy” 表示,其中 xy 为该字节的两位十六进制表示形式,推荐的编码机制是 UTF-8。例如,使用 UTF-8 编码机制,字符串 “The string ü@foo-bar” 将转换为 “The+string+%C3%BC%40foo-bar”,因为在 UTF-8 中,字符 ü 编码为两个字节,C3 (十六进制)和 BC (十六进制),字符 @ 编码为一个字节 40 (十六进制)。
关于 URLDecoder 类的使用,转换过程正好与 URLEncoder 类使用的过程相反,此不赘述。
关于JSP中文乱码更多的介绍,包括 页面乱码、参数乱码、表单乱码、源文件乱码 等知识,见我的另外两篇博客:《JSP中文乱码问题终极解决方案(上)》 和 《JSP中文乱码问题终极解决方案(下)》。
引用
使用 URLDecoder 和 URLEncoder 对中文字符进行编码和解码的更多相关文章
- PHP中文字符gbk编码与UTF-8编码的转换
通常PHP中上传文件,如果文件名称有中文字符,上传之后的名称是无法写入到本地的,因为上传来的编码格式一般是UTF-8的格式,这种格式是无法给文件命名并且存储到操作系统磁盘.在写入之前需要将其转换为gb ...
- [转载]Unicode中对中文字符的编码
以前写过一篇贴子是写中文在unicode中的编码范围 unicode中文范围,但写的不是很详细,今天再次研究了下unicode,并给出详细的unicode取值范围. 本次研究的unicode对象是un ...
- Java中的字节,字符与编码,解码
ASCII编码 ASCII码主要是为了表示英文字符而设计的,ASCII码一共规定了128个字符的编码(0x00-0x7F),只占用了一个字节的后面7位,最前面的1位统一规定为0. ISO-8859-1 ...
- [转]使用URLDecoder和URLEncoder对中文进行处理
一 URLEncoder HTML 格式编码的实用工具类.该类包含了将 String 转换为 application/x-www-form-urlencoded MIME 格式的静态方法.有关 HTM ...
- Java URLDecoder 和 URLEncoder 对中文进行编码和解码
URLDecoder类包含一个decode(String s,String enc)静态方法,它可以将application/x-www-form-urlencoded MIME字符串转成普通字符串: ...
- Java URLDecoder和URLEncoder对中文进行编码和解码
URLDecoder类包含一个decode(String s,String enc)静态方法,它可以将application/x-www-form-urlencoded MIME字符串转成普通字符串: ...
- 中文字符utf-8编码原则
UTF-8是一种变长字节编码方式.对于某一个字符的UTF-8编码,如果只有一个字节则其最高二进制位为0:如果是 多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的位数,其余各字 ...
- 对jsp中Url含中文字符的编码处理
有一段url="/app/index/index.jsp?userName='测试'":在传入到jsp页面后. 用 <% String userName=request.g ...
- Python中字符的编码与解码
1 文本和字节序列 我们都知道字符串,就是由一些字符组成的序列构成串,那么字符又是什么呢?计算机只能识别二进制的东西,那么计算机又为什么会显示我们的汉字,或者是某个字母呢? 由于最早发明使用计算机是美 ...
随机推荐
- u-boot.bin生成过程分析
ELF格式“u-boot”文件的生成规则如下,下面对应Makefile的执行过程分别分析各个依赖. $(obj)u-boot: depend version $(SUBDIRS) $(OBJS) $( ...
- 关于nodejs DeprecationWarning: current URL string parser is deprecated, and will be removed in a future version. To use the new parser, pass option { useNewUrlParser: true } to MongoClient.connect.
const mongoose = require('mongoose') mongoose.connect("mongodb://localhost:27017/study", { ...
- java 第五章 方法定义及调用
1.方法的定义 什么是方法 方法是完成某个功能的一组语句,通常将常用的功能写成一个方法 方法的定义 [访问控制符] [修饰符] 返回值类型 方法名( (参数类型 形式参数, ,参数类型 形式参数, , ...
- JSON初体验(二):Gson解析
今天,我们来介绍一下Gson的jar包的用法. JSON解析之Gson 特点:编码简介,谷歌官方推荐 数据之间的转换: 1.将json格式的字符串{}转换成为java对象 API: <T> ...
- PS作业
- ExtJs工具篇(1)——在Aptana3中安装ExtJS 代码提示插件
首先得下载Aptana 这个软件,我下载的是Aptana3这个版本.下载后,在"帮助"菜单中选择"安装新软件",弹出下面的对话框: 我们需要安装一个叫做&quo ...
- springmvc常用jar包
<dependency> <groupId>org.springframework</groupId> <artifactId>spring-beans ...
- 「日常训练」 Soldier and Traveling (CFR304D2E)
题意 (CodeForces 546E) 对一个无向图,给出图的情况与各个节点的人数/目标人数.每个节点的人只可以待在自己的城市或走到与他相邻的节点. 问最后是否有解,输出一可行解(我以为是必须和答案 ...
- 使用JDK自带的keytool工具生成证书
一.keytool 简介 keytool 是java用于管理密钥和证书的工具,它使用户能够管理自己的公钥/私钥对及相关证书,用于(通过数字签名)自我认证(用户向别的用户/服务认证自己)或数据完整性以及 ...
- App测试基本流程详解
1 APP测试基本流程 1.1流程图 1.2测试周期 测试周期可按项目的开发周期来确定测试时间,一般测试时间为两三周(即15个工作日),根据项目情况以及版本质量可适当缩短或延长测试时间. 1.3测试资 ...