机器学习(4)Hoeffding Inequality--界定概率边界
问题
假设空间的样本复杂度(sample complexity):随着问题规模的增长导致所需训练样本的增长称为sample complexity。
实际情况中,最有可能限制学习器成功的因素是训练数据的有限性。
在使用学习器的过程中,我们希望得到与训练数据拟合程度高的假设(hypothesis)。(在前面文章中提到,这样的假设我们称之为g)。
这就要求训练错误率为0。而实际上,大部分情况下,我们找不到这样的hypothesis(通过学习机得到的hypothesis)在训练集上有错误率为0。
所以退而求其次,我们只能要求通过学习机得到的hypothesis在训练集上错误率越低越好,最好接近0。
问题描述:
令D为有限的训练集,Ein(h)(in-sample error)为假设h在训练集D上的训练错误率,Eout(h)(out-of-sample error)是定义在全部数据的错误率。
(由此可知Eout(h)是不可直接求出的,因为不太可能将学习完无限的数据)。令g代表假设集中训练错误率最小的假设。
Hoeffding Inequality

Hoeffding Inequality刻画的是某个事件的真实概率与m各不同的Bernoulli试验中观察到的频率之间的差异。由上述的Hoeffding Inequality可知,
对我们是不可能得到真实的Eout(h),但我们可以通过让假设h在有限的训练集D上的错误率Ein(h)代表Eout(h)。
什么意思呢?Hoeffding Inequality告诉我们:较好拟合训练数据的假设与该假设针对整个数据集的预测,这两者的误差率相差很大的情况发生的概率其实是很小的。
Bad Sample and Bad Data
坏的样本(Bad Sample):假设h在有限的训练集D上的错误率Ein(h)=0,而真实错误率Eout(h)=1/2的情况。
坏的数据(Bad Data):Ein和Eout差别很大的情况。(通常情况下是Eout很大,Ein很小。
下面就将包含Bad data的Data用在多个h上。
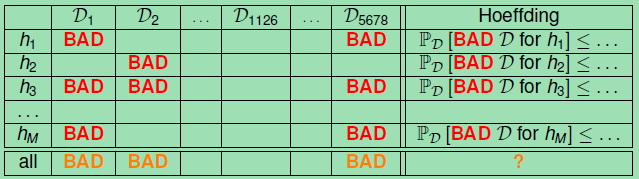
上图说明:
对于任一个假设hi,由Hoeffding可知其在所有的数据上(包括Bad Data)上出现不好的情况的总体概率是很小的。
Bound of Bad Data
由上面的表中可以得到下面的结论:

对于所有的M(假设的个数),N(数据集规模)和阈值,Hoeffding Inequality都是有效的
我们不必要知道Eout,可以通过Ein来代替Eout(这句话的意思是Ein(g)=Eout(g) is PAC).
感谢台大林老师的课。
参考:[原]【机器学习基础】理解为什么机器可以学习2——Hoeffding不等式
http://www.tuicool.com/articles/yyu2AnM
更多技术干货请关注:

机器学习(4)Hoeffding Inequality--界定概率边界的更多相关文章
- Hoeffding inequality
Hoeffding公式为 \epsilon]\leq{2e^{-2\epsilon^2N}}"> 如果把Training error和Test error分别看成和的话,Hoeffdi ...
- 机器学习笔记--Hoeffding霍夫丁不等式
Hoeffding霍夫丁不等式 在<>第八章"集成学习"部分, 考虑二分类问题\(y \in \{-1, +1\}\) 和真实函数\(f\), 假定基分类器的错误率为\ ...
- Andrew Ng机器学习公开课笔记 -- 学习理论
网易公开课,第9,10课 notes,http://cs229.stanford.edu/notes/cs229-notes4.pdf 这章要讨论的问题是,如何去评价和选择学习算法 Bias/va ...
- Machine Learning——吴恩达机器学习笔记(酷
[1] ML Introduction a. supervised learning & unsupervised learning 监督学习:从给定的训练数据集中学习出一个函数(模型参数), ...
- Coursera 机器学习基石 第4讲 学习的可行性
这一节讲述的是机器学习的核心.根本性问题——学习的可行性.学过机器学习的我们都知道,要衡量一个机器学习算法是否具有学习能力,看的不是这个模型在已有的训练数据集上的表现如何,而是这个模型在训练数据外的数 ...
- 【机器学习】Google机器学习工程的43条最佳实践
https://blog.csdn.net/ChenVast/article/details/81449509 本文档旨在帮助那些掌握机器学习基础知识的人从Google机器学习的最佳实践中获益.它提供 ...
- ML 01、机器学习概论
机器学习原理.实现与实践——机器学习概论 如果一个系统能够通过执行某个过程改进它的性能,这就是学习. ——— Herbert A. Simon 1. 机器学习是什么 计算机基于数据来构建概率统计模型并 ...
- NET平台机器学习组件-Infer.NET
NET平台机器学习组件-Infer.NET(三) Learner API—数据映射与序列化 阅读目录 关于本文档的说明 1.基本介绍 2.标准数据格式的映射 3.本地数据格式映射 4.评估数据格式映射 ...
- 机器学习 MLIA学习笔记(一)
监督学习(supervised learning):叫监督学习的原因是因为我们告诉了算法,我们想要预测什么.所谓监督,其实就是我们的意愿是否能直接作用于预测结果.典型代表:分类(classificat ...
随机推荐
- JavaScript数组去重方法及测试结果
最近看到一些人的去面试web前端,都说碰到过问JavaScript数组去重的问题,我也学习了一下做下总结. 实际上最有代表性也就三种方法:数组双重循环,对象哈希,排序后去重. 这三种方法我都做了性能测 ...
- MongoDB--GridFS 文件存储系统
GridFS是Mongo的一种专门用存储小型文件的功能. 使用于下列场景: 1.写入文件:mongofiles put 文件路径 注意,当前mongo实例链接的哪个库,将写文件在哪个实例里面的grid ...
- 在 Mac OS 上编译 FFmpeg
本文转自:在 Mac OS 上编译 FFmpeg | www.samirchen.com 安装 Xcode 和 Command Line Tools 从 App Store 上安装 Xcode,并确保 ...
- 关于MATLAB处理大数据坐标文件201763
目前已经找出26条特征 ,但是提交数据越来越少,给我的感觉是随机森林画的范围越来越小,输出的机器数据也越来越少,我自认为特征没太大问题 我已经将不懂之处列了出来,将于明天咨询大师级人物
- js函数一些小的知识点
var scope="123"; function aa(){ console.log(scope);//undefind var scope="234"; c ...
- fedora安装QQ
只看重利益的TC根本没想到要维护和更新linux版本的QQ,所幸fedora linux的中文社区 (https://repo.fdzh.org) 对大家比较照顾,还是针对fedora做了wine Q ...
- java设计模式综合项目实战视频教程
java设计模式综合项目实战视频教程 视频课程目录如下: 第01节课:本课程整体内容介绍:X-gen系统概况,包括:引入.X-gen项目背景.X-gen的HelloWorld第02节课:X-gen整体 ...
- 解决运行pytorch程序多线程问题
当我使用pycharm运行 (https://github.com/Joyce94/cnn-text-classification-pytorch ) pytorch程序的时候,在Linux服务器 ...
- 优化mysql数据库的几个步骤
析问题: 1. 开启慢查询日志. 这个步骤就是为了记录慢查询的sql,为下个步骤做准备,此步骤相关的知识点有如下: 1. show variables like '%slow_query_log%'; ...
- 7.如何发布vue项目到服务器
1.确保程序是可运行的,即npm run dev可以运行 2.把index.js修改 3.运行npm命令npm run build 4.生成的dist文件为 直接点击index.html就能运行,部署 ...