机器学习数学|偏度与峰度及其python实现
机器学习数学笔记|偏度与峰度及其python实现
觉得有用的话,欢迎一起讨论相互学习~




本博客为七月在线邹博老师机器学习数学课程学习笔记
为七月在线打call!!
课程传送门
矩
- 对于随机变量X,X的K阶原点矩为
\[E(X^{k})
\] - X的K阶中心矩为
\[E([X-E(X)]^{k})
\] - 期望实际上是随机变量X的1阶原点矩,方差实际上是随机变量X的2阶中心矩
- 变异系数(Coefficient of Variation):标准差与均值(期望)的比值称为变异系数,记为C.V
- 偏度Skewness(三阶)
- 峰度Kurtosis(四阶)
偏度与峰度

利用matplotlib模拟偏度和峰度
计算期望和方差
import matplotlib.pyplot as plt
import math
import numpy as np
def calc(data):
n=len(data) # 10000个数
niu=0.0 # niu表示平均值,即期望.
niu2=0.0 # niu2表示平方的平均值
niu3=0.0 # niu3表示三次方的平均值
for a in data:
niu += a
niu2 += a**2
niu3 += a**3
niu /= n
niu2 /= n
niu3 /= n
sigma = math.sqrt(niu2 - niu*niu)
return [niu,sigma,niu3]
\]
\]
\]
- sigma表示标准差公式为
\[\sigma=\sqrt{E(x^{2})-E(x)^{2}}
\]\[用python语言表示即为sigma = math.sqrt(niu2 - niu*niu)
\] - 返回值为[期望,标准差,\(E(x^{3})\)]
- PS:我们知道期望E(X)的计算公式为
\[E(X)=\sum_{i=1}^{n}p(i)x(i)-----(1)
\]这里我们X一个事件p(i)表示事件出现的概率,x(i)表示事件所给予事件的权值.
- 我们直接利用
\[E(x)=\bar{X_{i}}----(2)
\]表示期望应当明确
- (2)公式中\(X_{i}是利用numpy中的伪随机数生成的,其均值用于表示期望\)
- 此时(1)公式中对事件赋予的权值默认为1,即公式的本来面目为
\[E(x)=\bar{(X_{i}*1)}
\]
计算偏度和峰度
def calc_stat(data):
[niu, sigma, niu3]=calc(data)
n=len(data)
niu4=0.0 # niu4计算峰度计算公式的分子
for a in data:
a -= niu
niu4 += a**4
niu4 /= n
skew =(niu3 -3*niu*sigma**2-niu**3)/(sigma**3) # 偏度计算公式
kurt=niu4/(sigma**4) # 峰度计算公式:下方为方差的平方即为标准差的四次方
return [niu, sigma,skew,kurt]
利用matplotlib模拟图像
if __name__ == "__main__":
data = list(np.random.randn(10000)) # 满足高斯分布的10000个数
data2 = list(2*np.random.randn(10000)) # 将满足好高斯分布的10000个数乘以两倍,方差变成四倍
data3 =[x for x in data if x>-0.5] # 取data中>-0.5的值
data4 = list(np.random.uniform(0,4,10000)) # 取0~4的均匀分布
[niu, sigma, skew, kurt] = calc_stat(data)
[niu_2, sigma2, skew2, kurt2] = calc_stat(data2)
[niu_3, sigma3, skew3, kurt3] = calc_stat(data3)
[niu_4, sigma4, skew4, kurt4] = calc_stat(data4)
print (niu, sigma, skew, kurt)
print (niu2, sigma2, skew2, kurt2)
print (niu3, sigma3, skew3, kurt3)
print (niu4, sigma4, skew4, kurt4)
info = r'$\mu=%.2f,\ \sigma=%.2f,\ skew=%.2f,\ kurt=%.2f$' %(niu,sigma, skew, kurt) # 标注
info2 = r'$\mu=%.2f,\ \sigma=%.2f,\ skew=%.2f,\ kurt=%.2f$' %(niu_2,sigma2, skew2, kurt2)
info3 = r'$\mu=%.2f,\ \sigma=%.2f,\ skew=%.2f,\ kurt=%.2f$' %(niu_3,sigma3, skew3, kurt3)
plt.text(1,0.38,info,bbox=dict(facecolor='red',alpha=0.25))
plt.text(1,0.35,info2,bbox=dict(facecolor='green',alpha=0.25))
plt.text(1,0.32,info3,bbox=dict(facecolor='blue',alpha=0.25))
plt.hist(data,100,normed=True,facecolor='r',alpha=0.9)
plt.hist(data2,100,normed=True,facecolor='g',alpha=0.8)
plt.hist(data4,100,normed=True,facecolor='b',alpha=0.7)
plt.grid(True)
plt.show()
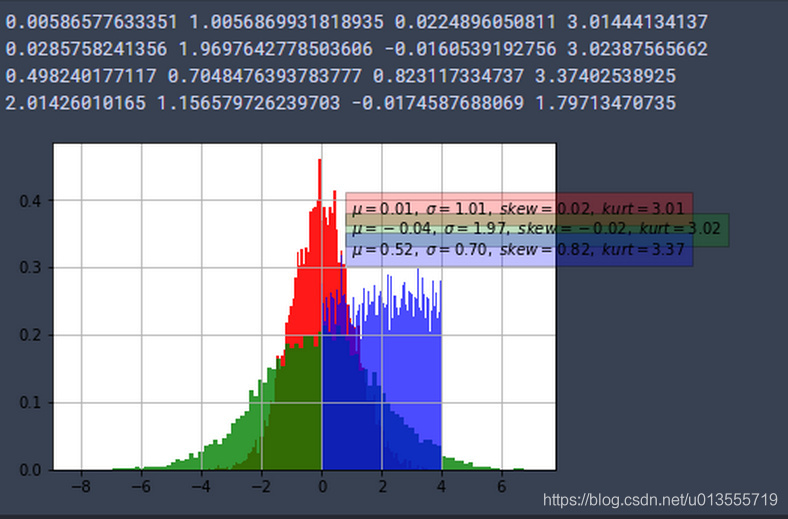
- 图形表示的是利用numpy随机数生成函数生成的随机数的统计分布,利用matplotlib.pyplot.hist绘制的直方图.即是出现数字的分布统计,并且是归一化到0~1区间后的结果.
- 即横轴表示数字,纵轴表示在1000个随机数中横轴对应的数出现的百分比.若不使用归一化横轴表示数字(normed=False),纵轴表示出现的次数.
- 若不使用归一化--纵轴表示出现次数,
- 关于matplotlib.pyplot.hist函数
n, bins, patches = plt.hist(arr, bins=10, normed=0, facecolor='black', edgecolor='black',alpha=1,histtype='b')
hist的参数非常多,但常用的就这六个,只有第一个是必须的,后面四个可选
arr: 需要计算直方图的一维数组
bins: 直方图的柱数,可选项,默认为10
normed: 是否将得到的直方图向量归一化。默认为0
facecolor: 直方图颜色
edgecolor: 直方图边框颜色
alpha: 透明度
histtype: 直方图类型,‘bar’, ‘barstacked’, ‘step’, ‘stepfilled’
返回值 :
n: 直方图向量,是否归一化由参数normed设定
bins: 返回各个bin的区间范围
patches: 返回每个bin里面包含的数据,是一个list
机器学习数学|偏度与峰度及其python实现的更多相关文章
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- 机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法
(一)认识回归 回归是统计学中最有力的工具之中的一个. 机器学习监督学习算法分为分类算法和回归算法两种,事实上就是依据类别标签分布类型为离散型.连续性而定义的. 顾名思义.分类算法用于离散型分布预測, ...
- 机器学习数学|微积分梯度jensen不等式
机器学习中的数学 觉得有用的话,欢迎一起讨论相互学习~Follow Me 原创文章,如需转载请保留出处 本博客为七月在线邹博老师机器学习数学课程学习笔记 索引 微积分,梯度和Jensen不等式 Tay ...
- 机器学习数学|Taylor展开式与拟牛顿
机器学习中的数学 觉得有用的话,欢迎一起讨论相互学习~Follow Me 原创文章,如需转载请保留出处 本博客为七月在线邹博老师机器学习数学课程学习笔记 Taylor 展式与拟牛顿 索引 taylor ...
- 数据的偏度和峰度——df.skew()、df.kurt()
我们一般会拿偏度和峰度来看数据的分布形态,而且一般会跟正态分布做比较,我们把正态分布的偏度和峰度都看做零.如果我们在实操中,算到偏度峰度不为0,即表明变量存在左偏右偏,或者是高顶平顶这么一说. 一.偏 ...
- 投入机器学习的怀抱?先学Python吧
前两天写了篇文章,给想进程序员这个行当的同学们一点建议,没想到反响这么好,关注和阅读数都上了新高度,有点人生巅峰的感觉呀.今天趁热打铁,聊聊我最喜欢的编程语言——Python. 为什么要说Python ...
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API
Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API 关键词:Local vector,Labeled point,Local matrix,Distrib ...
- 机器学习之决策树(ID3)算法与Python实现
机器学习之决策树(ID3)算法与Python实现 机器学习中,决策树是一个预测模型:他代表的是对象属性与对象值之间的一种映射关系.树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每 ...
随机推荐
- http://codeforces.com/contest/402/problem/E
E. Strictly Positive Matrix time limit per test 1 second memory limit per test 256 megabytes input s ...
- [js高手之路]html5 canvas动画教程 - 边界判断与小球粒子模拟喷泉,散弹效果
备注:本文后面的代码,如果加载了ball.js,那么请使用这篇文章[js高手之路] html5 canvas动画教程 - 匀速运动的ball.js代码. 本文,我们要做点有意思的效果,首先,来一个简单 ...
- 常用硬件设备GUID
Class GUID Device Description CDROM 4D36E965-E325-11CE-BFC1-08002BE10318 CD/DVD/Blu-ray drives DiskD ...
- FirstIDL
pro FIRSTIDL ;控制台输出 print,'first IDL' ;控制台输出 void=dialog_message('Hello,IDL world!',/information) en ...
- linux命令和awk
1.统计一下代码量 find . -name "*.py" | xargs wc -l | awk 'BEGIN {size = 0} { size+=$1} END{print ...
- iKcamp出品|微信小程序|工具安装+目录说明|基于最新版1.0开发者工具初中级教程分享
iKcamp官网:http://www.ikcamp.com 访问官网更快阅读全部免费分享课程:<iKcamp出品|全网最新|微信小程序|基于最新版1.0开发者工具之初中级培训教程分享>. ...
- vue-cli 自定义指令directive 添加验证滑块
vue项目注册登录页面遇到了一个需要滑块的功能,网上看了很多插件发现都不太好用,于是自己写了一个插件供大家参考: 用的是vue的自定义指令direcive,只需要在需要的组件里放入对应的标签嵌套即可: ...
- ZendStudio-12.5.0-win32.win32.x86_64.msi官方版本及破解工具
网上的工具试了好多,最后下载的这个工具成功了,之前的N个工具都失败了 亲自试用,表示有效!!! ZendStudio-12.5.0-win32.win32.x86_64.msi官方版本下载地址: 百 ...
- junit搭配hamcrest使用
开篇 - 快速进行软件编码,与功能测试应该是每个写代码的人,应该掌握的技能,如何进行优雅的写代码,把测试的时间压缩,腾出时间来休息.下面听我一一道来: 依赖:junit 4.4 hamcrest 1. ...
- 新型勒索软件Magniber正瞄准韩国、亚太地区开展攻击
近期,有国外研究人员发现了一种新型的勒索软件,并将其命名为Magniber,值得注意的是,这款勒索软只针对韩国及亚太地区的用户开展攻击.该勒索软件是基于Magnitude exploit kit(简称 ...