ELK系列~对fluentd参数的理解
这段时候一直在研究ELK框架,主要集成在对fluentd和nxlog的研究上,国内文章不多,主要看了一下官方的API,配合自己的理解,总结了一下,希望可以帮到刚入行的朋友们!
Fluentd(日志收集与过滤,server)
<source>
@type tcp
tag pilipa
format none
port 24224
bind 0.0.0.0
</source>
<filter docker.**>
type parser
format json
time_format %Y-%m-%dT%H:%M:%S.%L%Z
key_name log
reserve_data true
</filter>
<match **>
@type stdout
</match>
</ROOT>
Source节点
source主要是配置一个TCP,格式为所有,端口为默认的24224,绑定主机为自己IP的服务,它对应的客户端就要是TCP的,我们的nxlog就是这种协议的,架构上说就是一个c/s结构,由nxlog负责把数据发到fluentd上面。
filter节点
filter就是过滤规则,当source.tag复合filter的规则时,就执行这个filter进行过滤行为
match是fluentd收到数据后的处理, @type stdout是指在控制台输出,而我们生产环境把它输出到了elasticsearch上面( @type elasticsearch),处理的格式是json,如果在进行parser.json失败后,数据就不会正常的写入指定的数据表了,当然你可以把异常的数据存储到elasticsearch的其它表里。
自己在实践中总结的地方:
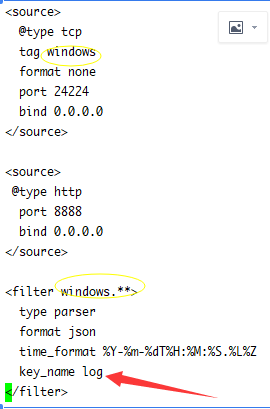
source里类型为@tcp类型时,它的tag是很重要的,我们的程序需要提供这个tag,当然如果你指定了端口,那这个tag就是当前端口的,而filter要根据这个tag去匹配自己,比如windows的tag,它会找以windows开头的fitler。
filter里的key_name,对应客户端发送消息时的主属性名称,有的是log,有的是message,有的是msg,像nxlog这种客户端它在使用tcp时key)name是message,下面说几种情况:
1 匹配了filter但没有找到key_name会有下面提示

2 没有任务key_name,会在结尾出现\r符号,我们需要去自己在output里过滤它,否则json转换失败

3 找到了对应的key_name

感谢各位的阅读!
希望本文章可以帮您快速的解决问题!
ELK系列~对fluentd参数的理解的更多相关文章
- ELK系列~Fluentd对大日志的处理过程~16K
Fluentd是一个日志收集工具,有输入端和输出端的概念,前者主要是日志的来源,你可以走多种来源方式,http,forward,tcp都可以,后者输出端主要指把日志进行持久化的过程,你可以直接把它持久 ...
- SSRS 系列 - 使用带参数的 MDX 查询实现一个分组聚合功能的报表
SSRS 系列 - 使用带参数的 MDX 查询实现一个分组聚合功能的报表 SSRS 系列 - 使用带参数的 MDX 查询实现一个分组聚合功能的报表 2013-10-09 23:09 by BI Wor ...
- ELK系列~Nxlog日志收集加转发(解决log4日志换行导致json转换失败问题)
本文章将会继承上一篇文章,主要讲通过工具来进行日志的收集与发送,<ELK系列~NLog.Targets.Fluentd到达如何通过tcp发到fluentd> Nxlog是一个日志收集工具, ...
- ELK系列~log4-nxlog-Fluentd-elasticsearch写json数据需要注意的几点
经验与实践 前两篇文章里我们介绍了nxlog的日志收集和转发<ELK系列~Nxlog日志收集加转发(解决log4日志换行导致json转换失败问题)>,今天我们主要总结一下,在与log4和f ...
- ELK系列~nxlog实现多位置文件的收集
前几天我写了几篇关于ELK日志收集,存储和分析的文章: ELK系列~NLog.Targets.Fluentd到达如何通过tcp发到fluentd ELK系列~Nxlog日志收集加转发(解决log4日志 ...
- 微软BI 之SSRS 系列 - 基于时间段参数的 MDX 查询以及时间日历 Date Picker 的时间类型参数化
今天在天善问答里看到一个问题,如果我没有理解错的话,它应该是指比如在一个报表中选取一个时间段,然后求出这个时间段的某个 Measure 的 SUM 和.并且同时求出这两个时间点对应的上一年的时间点之间 ...
- elk系列7之通过grok分析apache日志【转】
preface 说道分析日志,我们知道的采集方式有2种: 通过grok在logstash的filter里面过滤匹配. logstash --> redis --> python(py脚本过 ...
- elk系列2之multiline模块的使用【转】
preface 上回说道了elk的安装以及kibana的简单搜索语法,还有logstash的input,output的语法,但是我们在使用中发现了一个问题,我们知道,elk是每一行为一个事件,像Jav ...
- elk系列1之入门安装与基本操作【转】
preface 我们每天都要查看服务器的日志,一方面是为了开发的同事翻找日志,另一方面是巡检服务器查看日志,而随着服务器数量以及越来越多的业务上线,日志越来越多,人肉运维相当痛苦了,此时,参考现在非常 ...
随机推荐
- 201521123009 《Java程序设计》第1周学习总结
1. 本周学习总结 对Java进行了了解与简单的学习.第一次接触Java觉得比较难理解. 希望之后的深入学习可以解决目前的一些问题. 2. 书面作业 为什么java程序可以跨平台运行?执行java程序 ...
- Android之View绘制流程开胃菜---setContentView(...)详细分析
版权声明:本文出自汪磊的博客,转载请务必注明出处. 1 为什么要分析setContentView方法 作为安卓开发者相信大部分都有意或者无意看过如下图示:PhoneWindow,DecorView这些 ...
- javascript中slice() splice() concat()操作数组的方法
这三个操作数组,哪个返回一个新数组呢.上代码 splice()方法,用于插入,删除和替换. var arr=[1,2,3,4,5]; var arr1=arr.splice(1,3); console ...
- Spring写第一个应用程序
ref:http://www.importnew.com/13246.html 让我们用Spring来写第一个应用程序吧. 完成这一章要求: 熟悉Java语言 设置好Spring的环境 熟悉简单的Ec ...
- Android 之内容提供者 内容解析者 内容观察者
contentProvider:ContentProvider在Android中的作用是对外提供数据,除了可以为所在应用提供数据外,还可以共享数据给其他应用,这是Android中解决应用之间数据共享的 ...
- SQL性能优化十条经验(转)
1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE '%parm1%'-- 红色标识位置的百分号会导致相关列的索引无法使用,最好不要用. 解决办法: 其实只需要对该脚本略做改进,查询速度便会 ...
- js 递归函数的使用及常用函数
1.递归函数的使用: 公园里有一堆桃子,猴子每天吃掉一半,挑出一个坏的扔掉,第6天的时候发现还剩1个桃子,问原来有多少个桃子 var peache;function peaches(n) { if ( ...
- ThinkPHP中:add()和addAll()的区别
1.add()是记录单条插入 // 添加一条数据 $User = M("User"); // 实例化User对象 $data['name'] = 'ThinkPHP'; $data ...
- Linux入门之常用命令(10)软连接 硬链接
在Linux系统中,内核为每一个新创建的文件分配一个Inode(索引结点),每个文件都有一个惟一的inode号.文件属性保存在索引结点里,在访问文件时,索引结点被复制到内存在,从而实现文件的快速访问. ...
- 《算法导论》学习总结 — XX.第23章 最小生成树
一.什么叫最小生成树 一个无向连通图G=(V,E),最小生成树就是联结所有顶点的边的权值和最小时的子图T,此时T无回路且连接所有的顶点,所以它必须是棵树. 二.为什么要研究最小生成树问题 <算法 ...