grep&正则表达式
v\:* {behavior:url(#default#VML);}
o\:* {behavior:url(#default#VML);}
w\:* {behavior:url(#default#VML);}
.shape {behavior:url(#default#VML);}
闫珂
闫珂
2
308
2017-08-08T07:10:00Z
2017-08-08T07:10:00Z
9
594
3386
28
7
3973
16.00
Clean
Clean
false
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:普通表格;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-para-margin:0cm;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:10.5pt;
mso-bidi-font-size:11.0pt;
font-family:等线;
mso-ascii-font-family:等线;
mso-ascii-theme-font:minor-latin;
mso-fareast-font-family:等线;
mso-fareast-theme-font:minor-fareast;
mso-hansi-font-family:等线;
mso-hansi-theme-font:minor-latin;
mso-font-kerning:1.0pt;}
table.MsoTableGrid
{mso-style-name:网格型;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-priority:39;
mso-style-unhide:no;
border:solid windowtext 1.0pt;
mso-border-alt:solid windowtext .5pt;
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-border-insideh:.5pt solid windowtext;
mso-border-insidev:.5pt solid windowtext;
mso-para-margin:0cm;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:10.5pt;
mso-bidi-font-size:11.0pt;
font-family:等线;
mso-ascii-font-family:等线;
mso-ascii-theme-font:minor-latin;
mso-fareast-font-family:等线;
mso-fareast-theme-font:minor-fareast;
mso-hansi-font-family:等线;
mso-hansi-theme-font:minor-latin;
mso-font-kerning:1.0pt;}
目录
TOC \o "1-3" \h \z \u grep文本过滤工具
grep文本过滤工具
命令:grep
格式:grep [OPTIONS] PATTERN
选项: --color=auto 将匹配的结果着色显示
-v 反向匹配
-i 忽略大小写
-n 显示的结果前增加行号
-c 仅显示匹配到结果的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
相当于 &> /dev/null
-A# 显示关键字行及向后#行
-B# 显示关键字行及向前#行
-C# 显示关键字向前#行,当前行,及向后#行
-e 关键字1 -e 关键字2 实现多个选项间的逻辑or关系
-w 匹配整个单词
-E 使用扩展正则表达式 或egrep
-F 不使用正则表达式 或 fgrep
Patten格式:引用变量或文本用“”or‘’引起来,
引用命令则用``(反引号)引起来。
正则表达式
正则表达式是由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能。支持程序有grep,sed,awk,vim,less,nginx,varnish……它分为基本正则表达式和扩展正则表达式两类,用于grep中,则grep后支持基本正则表达式,grep -E或egrep后支持扩展正则表达式。
字符匹配
|
字符 |
含义 |
|
. |
匹配单个字符 |
|
[] |
匹配指定范围内的任意单个字符 |
|
[^] |
匹配指定范围外的任意单个字符 |
|
[:alnum:] |
所有字母和数字 |
|
[:alpha:] |
所有大小写字母(a-z&A-Z) |
|
[:lower:] |
小写字母(a-z) |
|
[:upper:] |
大写字母(A-Z) |
|
[:digit:] |
十进制数字(0-9) |
|
[:xdigit:] |
十六进制数字 |
|
[:blank:] |
空白字符(空格和制表符tab) |
|
[:space:] |
水平和垂直的空白字符(比[:black:]范围广) |
|
[:punct:] |
标点符号 |
|
[:graph:] |
可打印的非空白字符 |
|
[:print:] |
可打印字符 |
|
[:cntrl:] |
不可打印的控制字符(退格、删除、警铃……) |
匹配次数
匹配次数用于要指定次数的字符后面,用于指定前面的字符要出现的次数。
|
字符 |
含义 |
|
* |
匹配前面的字符任意次,包括0次 (贪婪模式:尽可能长的匹配) |
|
.* |
匹配任意长度的任意字符 |
|
\? |
匹配其前面的字符0次或1次 |
|
\+ |
匹配其前面的字符至少1次 |
|
\{n\} |
匹配其前面的字符n次 |
|
\{m,n\} |
匹配其前面的字符至少m次,至多n次 |
|
\{,n\} |
匹配其前面的字符至多n次 |
|
\{n,\} |
匹配其前面的字符至少n次 |
位置锚定
位置锚定用于定位出现的位置。
|
字符 |
含义 |
|
^ |
行首锚定,用于模式的最左侧 |
|
$ |
行尾锚定,用于模式的最右侧 |
|
^PATTERN$ |
用于模式匹配整行 ^$ 空行 ^[[:space:]]$ 空白行 |
|
\< or \b |
词首锚定,用于单词模式的左侧 |
|
\> or \b |
词尾锚定,用于单词模式的右侧 |
|
\<PATTERN\> |
匹配整个单词 |
后向引用
说到后向引用,我们先要了解一个概念——分组。分组就是用()把一个或多个字符捆绑在一起,当做一个整体进行处理,当然,在我们的基本正则表达式中,()需要用\来转义,所以,用法如下:
\(root\)\+ 代表匹配root至少一次
在分组括号中的模式匹配到的内容会被正则表达式引擎记录与内部的变量中,这些变量的命名方式为:\1,\2,\3……
\n就是从左侧起第n个左括号以及与之匹配的有括号之间的模式所匹配到的字符。
eg:\(string1\+\(string2\)*\)
\1 :string1\+\(string2\)*
\2 :string2
后向引用:引用前面的分组括号中的模式所匹配的字符,而非模式本身。
单说概念大家应该不会很明白,那我们来看一个例子,因为后向引用很重要,所以我们就说细致一点。(敲黑板!划重点!)
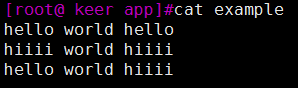
这个是我们的文件,如果我们想匹配所有行,应该怎么做呢?就用到我们上面所说到的正则表达式的知识。

我们把这个命令单独拉出来说:grep "^h.\{4\}.*h.\{4\}$" example
^h.\{4\}表示匹配以h后加任意4个字符为开头,.*表示匹配任意多个字符,h.\{4\}$表示匹配以h后加任意4个字符为结尾。hello和hiiii都是以h后跟4个任意字符组成的,所以上述命令就可以匹配所有的行。
那么,如果我只想匹配开头和结尾单词一样的行呢?也就是职匹配前两行。这个时候,我们就要用到后向引用了,如下:

上述命令就可以完成我们的需求,我们来详细的说一下这个命令。
分为两部分:红框内:\(h.\{4\}\) 蓝框内:\1
先说红框内的,这个和我们上一个示例没有区别,只是加了\(\)括起来,含义还是不变,依然表示h后跟任意4个字符。
那么蓝框内呢?是什么意思?
“\1”表示的就是从左侧起第1个左括号以及与之匹配的有括号之间的模式所匹配到的字符。上述我们只有一对括号,所以蓝框内的“\1”表示的就是红框内“\(h.\{4\}\)”所匹配到的内容。如果没看明白,那么看看下面这张图吧:

现在可以明白为什么要添加括号分组了吗?因为当我们添加了括号分组,“h.\{4\}”就成为整个正则中第1个分组中的正则,当“h.\{4\}”匹配到的结果为hello时,“\1”引用的就是hello,当“h.\{4\}”匹配到的结果是hiiii时,“\1”引用的就是hiiii。
这个就是所谓的后项引用了。当然,\2,\3的内容相信也就不言而喻了。
扩展的正则表达式
命令:egrep = grep -E
格式:egrep [OPTIONS] PATTERN [FILE...]
扩展的正则表达式与正则表达式的元字符大致一样。为什么叫他扩展的正则表达式呢?因为在扩展正则表达式中,除了词首词尾锚定和后项引用以外,其他的元字符都可以直接引用,不需要加“\”转义。
小练习
讲了这么多东西,我们来做一些题练练手吧~提供的答案仅为参考,因为不同的解题思路,你的解题步骤也会有所不同喏,小伙伴们尽情发挥吧(〃'▽'〃)
1、统计当前连接本机的每个远程主机IP的连接数,并按从大到小排序
netstat -tun |grep "[0-9]" |tr -s " " ":" |cut -d: -f6 |sort |uniq -c |sort -n
2、显示/etc/passwd文件中不以/bin/bash结尾的行
cat /etc/passwd | grep -v /bin/bash$
3、找出/etc/passwd中的两位或三位数
cat /etc/passwd |grep "\b[0-9]\{2,3\}\b"
4、显示CentOS7的/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面存非空白字符的行
cat /etc/grub2.cfg |grep "^[[:space:]]\+[^[:space:]].*$"
5、 使用egrep取出/etc/rc.d/init.d/functions中其基名
echo /etc/rc.d/init.d/functions | egrep -o "[^/]+/?$"
6、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一个小括号的行
cat /etc/rc.d/init.d/functions |egrep "^.*[^[:space:]]\(\)"
7、统计last命令中以root登录的每个主机IP地址登录次数
last |grep ^root |egrep -o "([0-9]{1,3}\.){3}[0-9]{1,3}" |sort |uniq -c
8、显示ifconfig命令结果中所有IPv4地址
ifconfig | egrep -o "\<(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4]0-9]|25[0-5])\.){3}([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\>"
9、显示三个用户root、mage、wang的UID和默认shell
cat /etc/passwd |egrep "^(root|mage|wang)\b" |cut -d: -f3,
10、只利用df、grep和sort,取出磁盘各分区利用率,并从大到小排序
df |grep sd |grep -Eo "[0-9]{1,3}%" |sort -nr
grep&正则表达式的更多相关文章
- (转)linux grep 正则表达式
转自:http://www.cnblogs.com/xiaouisme/archive/2012/11/09/2762543.html -------------------------------- ...
- linux grep 正则表达式
grep正则表达式元字符集: ^ 锚定行的开始 如:'^grep'匹配所有以grep开头的行. $ 锚定行的结束 如:'grep$'匹配所有以grep结尾的行. . 匹配一个非换行符的字符 如:'gr ...
- LINUX中,find结合grep正则表达式,快速查找代码文件。
###目的###LINUX中,find结合grep正则表达式快速查找代码. 例如经常有需求:查找当前目录下所有.h文件中,"public开头,中间任意字符,以VideoFrameReceiv ...
- grep 正则表达式用引号括起来和元字符加反斜杠转义的测试
grep 正则表达式用引号括起来和元字符加反斜杠转义的测试 实验在 grep 命令中的表达式:不加引号,加单引号,加双引号的区别,以及部分元字符前加与不加 `\’ 进行转义的区别.实验环境为“实验楼( ...
- find+grep+正则表达式
目录 find+grep+正则表达式 1.find 2.grep 3.正则表达式 find+grep+正则表达式 1.find 根据文件的名称或者属性查找文件. # 自己在 /root/adc目录下长 ...
- grep 正则表达式
本文转自:http://www.jb51.net/article/31207.htm 正则表达式只是一种表示法,只要工具支持这种表示法, 那么该工具就可以处理正则表达式的字符串.vim.grep.aw ...
- Linux 命令——grep | 正则表达式
感觉讲的很详细,瞬间懂了grep,正则. from: here 简介 grep (global search regular expression(RE) and print out the line ...
- vim 和grep 正则表达式相似和区别
正则表达式由两种基本字符类型组成:原义(正常)文本字符和元字符.元字符使正则表达式具有处理能力.所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符 ...
- 文本处理三剑客之grep&正则表达式
grep是一个文本过滤工具,它支持正则表达式,能把搜索匹配到的行打印出来.grep的全称是Global Regular Expression Print(全局正则表达式)使用权限是所有用户. 一.gr ...
随机推荐
- 写移动端必备的meta标签
<meta name="renderer" content="webkit" /> <meta http-equiv="X-UA-C ...
- Spring思维导图(一)
关于Spring Spring是一个开源框架,是为了解决企业应用程序开发复杂性而创建的.框架的主要优势之一就是其分层架构,分层架构允许您选择使用哪一个组件,同时为 J2EE 应用程序开发提供集成的框架 ...
- [填坑]树上差分 例题:[JLOI2014]松鼠的新家(LCA)
今天算是把LCA这个坑填上了一点点,又复习(其实是预习)了一下树上差分.其实普通的差分我还是会的,树上的嘛,也是懂原理的就是没怎么打过. 我们先来把树上差分能做到的看一下: 1.找所有路径公共覆盖的边 ...
- 从理解开始 谈谈px rem 和 em 的区别与联系
概述 古语有云,没有规矩则不成方圆.秦灭六国之后为了促进国内生产力的发展,也是大力推进全国度量衡的统一.车同轨,书同文.与"尺寸"相关的问题(手动滑稽),从古至今一直为人们所关注. ...
- JavaScript基础知识(二)
一.JavaScript事件详解 1.事件流:描述的是在页面中结束事件的顺序 事件传递有两种方式:冒泡与捕获. 事件传递定义了元素事件触发的顺序. 如果你将 <p> 元素插入到 <d ...
- python学习之字符串(下)
----------------------------------------------实际应用中的其他常见的字符串方法 >>>line = "the knights ...
- 关于write()和fsync()
--关于write()和fsync() ----------------------------转载 write ssize_t write(int fd, const void *buf, si ...
- JDBC数据库连接JAVA和一些基本语句
连接JDBC 1)JDBC简介 - JDBC就是Java中连接数据库方式 - 我们可以通过JDBC来执行SQL语句. 2)获取数据库连接 ...
- Azkaban3.x集群部署(multiple executor mode)
介绍 Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,用于在一个工作流内以一个特定的顺序运行一组工作和流程.Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于 ...
- 关于Java String 类型转换时null的问题(转)
关于Java String 类型转换时null的问题 开发中经常遇到从集合类List.Map中取出数据转换为String的问题,这里如果处理不好,经常会遇到空指针异常java.lang.NullPoi ...