Android异步处理技术
前言:
在移动端开发中,我们必须正确处理好主线程和子线程之间的关系,耗时操作必须在子线程中完成,避免阻塞主线程,导致ANR。异步处理技术是提高引用性能,解决主线程和子线程之间通信问题的关键。
通常在如下两种情况下会弹出ANR对话框:
- 5s内无法响应用户输入事件(例如键盘输入, 触摸屏幕等).
- BroadcastReceiver在10s内无法结束.
造成以上两种情况的首要原因就是在主线程(UI线程)里面做了太多的阻塞耗时操作, 例如文件读写, 数据库读写, 网络查询等等,避免ANR,其实就是不能在主线程中进行耗时操作,这就需要用到异步处理技术了。
异步处理技术有很多种,常见的有Thread、AsyncTask、Handler&Looper、Executor等。一个完整的异步处理技术的继承树如下所示:
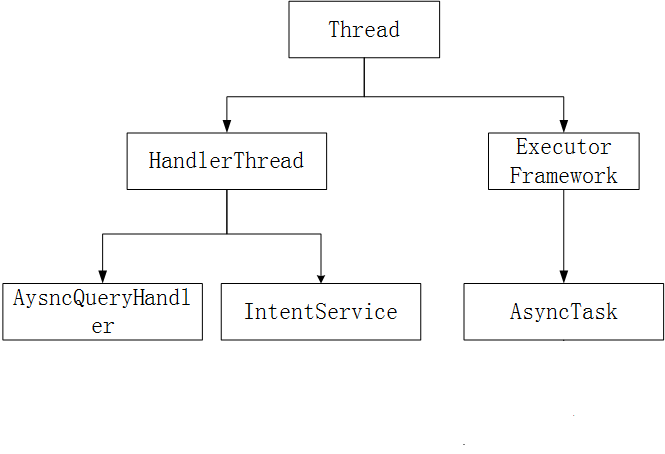
下面我们就根据继承树的结构并结合具体使用和源码一一展开介绍。
一、Thread
线程作为Java语言的一个概念,是实际执行任务的基本单元,Thread是异步处理技术的基础。它的使用相当简单,简单的讲,创建线程的方法有两种:
1.继承Thread类并重写run方法
语句如下
public class Mythread extends Thread {
@Override
public void run() {
//实现具体的逻辑,如文件读写,网络请求等
}
public void startThread(){
Mythread mythread = new Mythread();
mythread.start();//使用start启动线程
}
}
2.实现Runnable接口并实现run方法
public class MyRunnable implements Runnable {
@Override
public void run() {
//实现具体的逻辑,如文件读写,网络请求等
}
public void startThread(){
MyRunnable runnable = new MyRunnable();
Thread thread = new Thread(runnable);
thread.start();//同样利用start启动线程
}
}
这里需要注意的一点是,如果我们没有利用start方法去启动线程,而是直接调用run方法,那这将不会是一个异步操作,而只是一个简单的方法调用,其操作还是在主线程上进行的。
3.Android中的线程分类
此外,我们再扩展一下Android应用中线程的概念。Android引用中的各类线程其本质都是基于Linux系统的pthreads,在应用层可以分为三种类型的线程。
1.主线程:主线程也被称为UI线程,它随着应用的启动而启动,主线程用来运行Android组件,同时刷新屏幕上的UI元素。Android系统如果检测到非主线程在更新UI组件,则会抛出CallFromWrongThreadException异常。为什么只有主线程才能操作UI,这是因为Android的UI工具包并不是线程安全的。主线程中创建的Handler会顺序执行接收到的消息,包括从其他线程中发送的消息。因此,如果消息队列中前面的消息没有很快执行完,那么就会阻塞队列中的 其他消息的及时处理。
2.Binder线程:Binder线程用于不同进程之间的线程通信(其原理在前面文章中有提到),每个进程都维护了一个Binder线程池,用于处理其他进程中线程发送的消息。这些进程包括系统服务、Intents、ContentProvider和Service等。在大部分情况下,应用不需要关心Binder线程,因为系统会优先将请求转换为使用主线程。一个典型的应用场景就是应用提供给其他进程通过AIDL接口绑定的Service。
3.后台线程,在应用中显示创建的线程都是后台线程,也就是当刚创建处理的时候,折现线程的执行体是空的,需要手动添加任务。
为什么有主线程和后台线程的区别,在Linux层面上,主线程和后台线程是一样的,在Android框架中通过WindowManager赋予了主线程只能处理UI更新、后台线程不能直接操作UI的限制。
二、HandlerThread
HandlerThread是一个集成了Looper和MessageQueue的线程,当启动HandlerThread的同时,会生成Looper和MessageQueue,然后等待消息进行处理。
先看一下这个类的结构
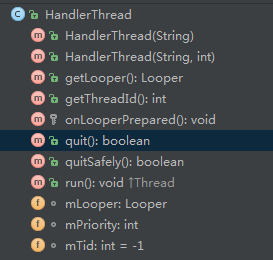
既然是集成自Thread类,我们先来看一下它的run方法的源码
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}
可以发现,HandlerThread内部集成了Looper,通过Looper.prepare()新建了一个Looper。
具体最后会调用到以下方法:
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
其中 sThreadLocal是ThreadLocal<Looper>类型的变量。
使用HandlerThread的好处在于开发者不需要自己去创建并维护Looper,它的用法和普通线程是一致的
HandlerThread handlerThread = new HandlerThread("myHandlerThread");
handlerThread.start();
Handler myHandler = new Handler(handlerThread.getLooper()){
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
//处理接收到的消息
}
};
HandlerThread内部只有一个消息队列,队列中的消息是顺序执行的,因而是线程安全的,当然其吞吐量会有一定影响,队列中的任务可能会被前面没有执行完的任务阻塞。
这个时候有人可能会有这样的疑问,那有没有可能出现发送消息的时候Looper还没有准备好呀。这一点我们通过源码,看到其内部的机制就能确保创建Looper和发送消息之间不存在竞态条件。
/**
* This method returns the Looper associated with this thread. If this thread not been started
* or for any reason is isAlive() returns false, this method will return null. If this thread
* has been started, this method will block until the looper has been initialized.
* @return The looper.
*/
public Looper getLooper() {
if (!isAlive()) {
return null;
} // If the thread has been started, wait until the looper has been created.
synchronized (this) {
while (isAlive() && mLooper == null) {
try {
wait();
} catch (InterruptedException e) {
}
}
}
return mLooper;
}
当线程已经启动,Looper还没有准备好的时候,线程会进行wait状态。
在HandlerLooper中还有一个方法声明,onLooperPrepared(),这个方法可以被重写,用于在HandlerThread开始接受消息之前进行某些初始化操作。
import android.os.Handler;
import android.os.HandlerThread;
import android.os.Message;
import android.os.Process; /**
* Created by HustZhb on 2017/8/3.
* 描述:
*/
public class MyHandlerThread extends HandlerThread{ private Handler mHandler; public MyHandlerThread() {
super("MyHandlerThread", Process.THREAD_PRIORITY_BACKGROUND);
} @Override
protected void onLooperPrepared() {
super.onLooperPrepared();
mHandler = new Handler(getLooper()){
@Override
public void handleMessage(Message msg) {
switch (msg.what){
case 1:
//处理message
break;
case 2:
//处理message
break;
default:
break;
}
}
}; } public void publishedMehthod1(){
mHandler.sendEmptyMessage(1);
}
public void publishMehthod2(){
mHandler.sendEmptyMessage(2);
}
}
上述例子在onLooperPrepared函数中创建了与HandlerThread关联的Handler实例,同样对外隐藏了我们的Handler实例。
三、AsyncQueryHandler
而在HandlerThread的基础上,AsyncQueryHandler是用于在ContentProvider上执行异步的CRUD操作的工具类,其中CRUD操作被放到一个单独的子线程中进行,当操作获取到结构后通过message的形式传递给调用AsyncQueryHandler的线程,通常就是主线程。
AsyncQueryHandler是一个抽象类,它继承自Handler,通过封装ContentResolver、HandlerThread和Handler等实现对ContentProvider的异步操作。
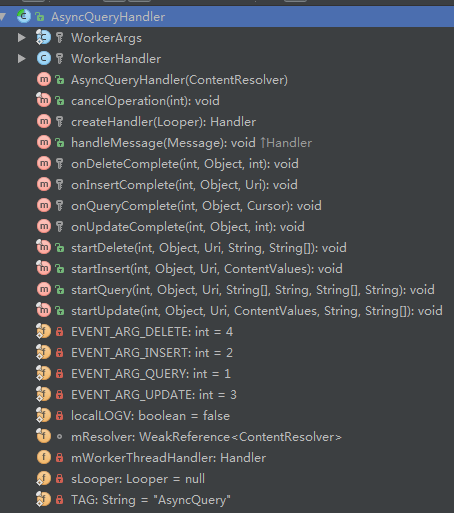
通过这个类结构,我们陷入就可以发现其中似乎封装了如下四个方法来操作ContentProvider,同样又封装了对应的四个回调函数。具体如下所示:
四个CRUD方法
//删除操作
public final void startDelete(int token, Object cookie, Uri uri,
String selection, String[] selectionArgs) {
// Use the token as what so cancelOperations works properly
Message msg = mWorkerThreadHandler.obtainMessage(token);
msg.arg1 = EVENT_ARG_DELETE; WorkerArgs args = new WorkerArgs();
args.handler = this;
args.uri = uri;
args.cookie = cookie;
args.selection = selection;
args.selectionArgs = selectionArgs;
msg.obj = args; mWorkerThreadHandler.sendMessage(msg);
} //插入操作
public final void startInsert(int token, Object cookie, Uri uri,
ContentValues initialValues) {
// Use the token as what so cancelOperations works properly
Message msg = mWorkerThreadHandler.obtainMessage(token);
msg.arg1 = EVENT_ARG_INSERT; WorkerArgs args = new WorkerArgs();
args.handler = this;
args.uri = uri;
args.cookie = cookie;
args.values = initialValues;
msg.obj = args; mWorkerThreadHandler.sendMessage(msg);
} //查找操作
public void startQuery(int token, Object cookie, Uri uri,
String[] projection, String selection, String[] selectionArgs,
String orderBy) {
// Use the token as what so cancelOperations works properly
Message msg = mWorkerThreadHandler.obtainMessage(token);
msg.arg1 = EVENT_ARG_QUERY; WorkerArgs args = new WorkerArgs();
args.handler = this;
args.uri = uri;
args.projection = projection;
args.selection = selection;
args.selectionArgs = selectionArgs;
args.orderBy = orderBy;
args.cookie = cookie;
msg.obj = args; mWorkerThreadHandler.sendMessage(msg);
} //更新操作
public final void startUpdate(int token, Object cookie, Uri uri,
ContentValues values, String selection, String[] selectionArgs) {
// Use the token as what so cancelOperations works properly
Message msg = mWorkerThreadHandler.obtainMessage(token);
msg.arg1 = EVENT_ARG_UPDATE; WorkerArgs args = new WorkerArgs();
args.handler = this;
args.uri = uri;
args.cookie = cookie;
args.values = values;
args.selection = selection;
args.selectionArgs = selectionArgs;
msg.obj = args; mWorkerThreadHandler.sendMessage(msg);
}
其实现逻辑都是类似的,通过新建一个WorkerArgs来实现配置参数,并将这个配置后的实例传递到msg.obj,然后通过handler发送消息。最后应该是在WorkerHandler中的handleMessage中来调用ContentResolver的对应方法。
具体代码如下:
@Override
public void handleMessage(Message msg) {
final ContentResolver resolver = mResolver.get();
if (resolver == null) return; WorkerArgs args = (WorkerArgs) msg.obj; int token = msg.what;
int event = msg.arg1; switch (event) {
case EVENT_ARG_QUERY:
Cursor cursor;
try {
cursor = resolver.query(args.uri, args.projection,
args.selection, args.selectionArgs,
args.orderBy);
// Calling getCount() causes the cursor window to be filled,
// which will make the first access on the main thread a lot faster.
if (cursor != null) {
cursor.getCount();
}
} catch (Exception e) {
Log.w(TAG, "Exception thrown during handling EVENT_ARG_QUERY", e);
cursor = null;
} args.result = cursor;
break; case EVENT_ARG_INSERT:
args.result = resolver.insert(args.uri, args.values);
break; case EVENT_ARG_UPDATE:
args.result = resolver.update(args.uri, args.values, args.selection,
args.selectionArgs);
break; case EVENT_ARG_DELETE:
args.result = resolver.delete(args.uri, args.selection, args.selectionArgs);
break;
}
// passing the original token value back to the caller
// on top of the event values in arg1.
Message reply = args.handler.obtainMessage(token);
reply.obj = args;
reply.arg1 = msg.arg1; if (localLOGV) {
Log.d(TAG, "WorkerHandler.handleMsg: msg.arg1=" + msg.arg1
+ ", reply.what=" + reply.what);
} reply.sendToTarget();
}
}
这里我们可以发现在调用完CRUD操作后,它将结果填充到了reply这个Message对象上,发回到调用方。
四个可重写的回调方法
protected void onQueryComplete(int token, Object cookie, Cursor cursor) {
// Empty
}
protected void onInsertComplete(int token, Object cookie, Uri uri) {
// Empty
}
protected void onUpdateComplete(int token, Object cookie, int result) {
// Empty
}
protected void onDeleteComplete(int token, Object cookie, int result) {
// Empty
}
我们可以根据实际的需求来实现下面的回调方法,从而得到上面的CRUD操作的返回结果。
四、IntentService
IntentService想必大家也不陌生,相比较于Service而言,Service的各个生命周期都是运行在主线程的,因此它本身并不具备异步的能力,所以一般我们在使用Service的时候需要在其中的onStartCommand方法中自己手动新建一个子线程,并且,在子线程的run方法中最后调用stopSelf方法结束自身来确保结束服务。
而这样的写法增加了出错的可能性,忘开线程或者忘记调用stopSelf方法。虽有为了更好的实现一个异步的、可自动停止的服务,Android专门引入了一个Service的子类 IntentService来实现这种操作。
IntentService具有和Service一样的生命周期,同时也提供了后台线程中处理异步任务的机制。与HandlerThread类似,IntentService也是在一个后台线程中顺序执行所有的任务。我们可以通过给Context.startService传递一个Intent类型的参数可以启动IntentService的异步执行,如果此时IntentService正在运行,那么这个新的Intent将会进入到队列中进行排队,知道后台线程处理完队列前面的任务。如果此时IntentService没有在运行,那么将会启动一个新的IntentService,当后台线程队列中所有任务处理后,IntentService将自动结束它的生命周期。
IntentService本身是一个抽象类,使用它之前需要继承并实现其中的onHandleIntent(Intent)方法,在这个方法中实现具体的后台处理业务逻辑,同时在子类的构造方法中需要调用弗雷的有参构造函数。传入子类的名字。
import android.app.IntentService;
import android.content.Intent;
import android.support.annotation.Nullable; public class SimpleIntentService extends IntentService {
/**
* Creates an IntentService. Invoked by your subclass's constructor.
*
* @param name Used to name the worker thread, important only for debugging.
*/
public SimpleIntentService(String name) {
super(SimpleIntentService.class.getName());
setIntentRedelivery(true);
} @Override
protected void onHandleIntent(@Nullable Intent intent) {
//这个方法是在后台线程中调用的
} }
当我们需要启动这个IntentService的时候,我们只需要进行以下操作。
Intent intentService = new Intent(this,SimpleIntentService.class);
startService(intentService);
当然,其中有一步是不能够遗忘的,IntentServie作为Service的子类,它同样需要在AndroidManifest文件中注册这个类。
(这里我们在其构造器中写入了一行setIntentRedelivery(true),这边先不解释,下面结合源码会提到)
下面结合源码来看一个它内部的实现。首先先放一张它的类结构图。
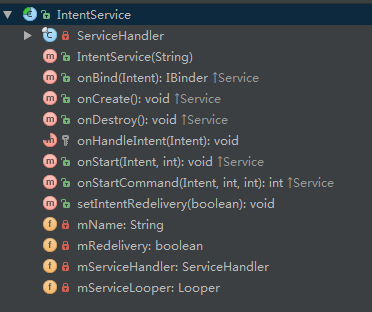
下面是一个完整的源码
public abstract class IntentService extends Service {
private volatile Looper mServiceLooper;
private volatile ServiceHandler mServiceHandler;
private String mName;
private boolean mRedelivery;
private final class ServiceHandler extends Handler {
public ServiceHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
onHandleIntent((Intent)msg.obj);
stopSelf(msg.arg1);
}
}
public IntentService(String name) {
super();
mName = name;
}
public void setIntentRedelivery(boolean enabled) {
mRedelivery = enabled;
}
@Override
public void onCreate() {
super.onCreate();
HandlerThread thread = new HandlerThread("IntentService[" + mName + "]");
thread.start();
mServiceLooper = thread.getLooper();
mServiceHandler = new ServiceHandler(mServiceLooper);
}
@Override
public void onStart(@Nullable Intent intent, int startId) {
Message msg = mServiceHandler.obtainMessage();
msg.arg1 = startId;
msg.obj = intent;
mServiceHandler.sendMessage(msg);
}
@Override
public int onStartCommand(@Nullable Intent intent, int flags, int startId) {
onStart(intent, startId);
return mRedelivery ? START_REDELIVER_INTENT : START_NOT_STICKY;
}
@Override
public void onDestroy() {
mServiceLooper.quit();
}
@Override
@Nullable
public IBinder onBind(Intent intent) {
return null;
}
@WorkerThread
protected abstract void onHandleIntent(@Nullable Intent intent);
}
代码的逻辑很简答,在onCreate方法中,我们可以清晰地看到IntentService是通过HandlerThread来实现后台任务的处理,
@Override
public void onCreate() {
super.onCreate();
HandlerThread thread = new HandlerThread("IntentService[" + mName + "]");
thread.start();
mServiceLooper = thread.getLooper();
mServiceHandler = new ServiceHandler(mServiceLooper);
}
此外,还有一点需要知道的,刚才在继承IntentService的例子中,我们在其构造器中写入了一行setIntentRedelivery(true),这一行代码的作用是什么呢?
从字面上看是设置Intent重现投递为真。其效果是IntentService的onStartCommand方法将返回 START_REDELIVER_INTENT,这时,如果onHandleIntent方法返回之前进程死亡,那么在进程重新启动的时候,intent会重新投递。
@Override
public int onStartCommand(@Nullable Intent intent, int flags, int startId) {
onStart(intent, startId);
return mRedelivery ? START_REDELIVER_INTENT : START_NOT_STICKY;
}
五、Executor FrameWork
1.概述
下面我们来介绍在Java并发开发中经常用到的一个框架Java Executor框架。我们知道创建和销毁对象是存在开销的,如果应用中频繁出现线程的创建和销毁会影响到应用的性能,使用Java Executor 框架可以通过线程池等机制解决这个问题。
1.创建工作线程池,同时通过队列来控制这些线程执行的任务的个数
2.检测导致线程意外终止的错误
3.等待线程执行完成并获取执行结果
4.批量执行线程,并通过固定的顺序获取执行结果
5.在合适的时机启动后台线程,从而保证线程执行结果可以很快反馈给用户。
Executor框架主要由以下三部分组成:
1.任务 包括被执行任务需要实现的接口:Runnable接口或者Callable接口
2.任务的执行 包括任务执行机制的核心接口Executor,以及继承自Executor的ExecutorService接口(Executor框架中有两个类实现了ExecutorService接口,ThreadPoolExecutor和ScheduledThreadExecutor)
3.异步计算的结构 包括接口Future和实现Future接口的Future的FutureTask类。
2.Executor框架中的重要组成部分
1)Executor框架的基础是一个Executor的接口,Executor的主要作用是分离任务的创建和执行,最终实现上述功能。
public interface Executor {
void execute(Runnable command);
}
2)ThreadPoolExecutor是线程池的核心实现类,用来执行被提交的任务。
3)ScheduledThreadPoolExecutor是一个实现类,可以在给定的延迟后执行命令,或者定期执行命令。ScheduledThreadPoolExecutor比Timer更灵活,功能也更加强大。
4)Future接口和实现Future接口的FutureTask类,代表异步计算的结果。
5)Runnable和Callable接口的实现类,可以被ThreadPoolExecutor和ScheduledThreadPoolExecutor执行。
主线程首先要创建一个实现Runnable接口或者Callable接口的任务对象,工具类Executors可以把一个Runnbale对象封装为Callable对象。(Executors.callable(Runnbale task )或 Executor.callable(Runnbale task, Object result)),然后将Runnbale对象直接交给ExecutorService执行(ExecutorService.execute(Runnbale command))或是将Runnbale对象或Callable对象提交给ExecutorServie执行(ExecutorService.submit(Runnable task)或ExecutorService.submit(Callable<T> task))
如果执行的是submit方法,ExecutorService将返回一个实现Future接口的对象,(FutureTask对象),由于FutureTask实现了Runnbale,我们也可以自己创建FutureTask,然后直接交给ExecutorService运行。最后主线程可以执行FutureTask.get()方法来等待任务执行完成,主线程也可以使用FutureTask.cancel来取消任务的执行。
3.核心类ThreadPoolExecutor详解
前面我们提到了ThreadPoolExecutor是框架中核心类,下面就展开详细的介绍。
1)构造函数
先从构造函数入手,下述源码是ThreadPoolExecutor一个常用的构造函数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
上述参数解释如下:
- corePoolsize:线程中的核心线程数,默认情况下核心线程会在线程池一直存活,即使处于空闲状态。如果将ThreadPoolExecutor的allowCoreThreadTimeOut属性设置为ture,那么闲置的核心线程在等待新任务时会有超时策略,时间间隔由keepAliveTime指定。
- maximumPoolSize:线程池所能容纳的最大线程数,当活动线程数达到这个数值后,后续的新任务将会被阻塞。
- keepAliveTiem:非核心线程显示时的超时时长,超过这个时长,非核心线程会被回收,核心线程如上所示。
- unit:用于指定keepAliveTime参数的时间单位
- workQueue:线程池的任务队列,通过线程池的execute方法提交的Runnable对象存储在这个参数中。
- threadFactory:线程工厂,为线程池提供创建新线程的能力。ThreadFactory是一个借口,只有一个方法 Thread newThread(Runnbale r)。
除了上述参数以外,看上面常用的构造函数内部通过this调用其他构造器,其中还有一个参数defaultHandler,ThreadPoolExecutor还有一个参数RejectedExecutionHandler handler,当线程池无法执行新任务的时候(可能是因为任务队列已满或无法成功过执行任务),。这是ThreadPoolExecutor会调用handler的rejectedExecution方法来通知调用者,默认情况会直接抛出一个RejectedExecutionException。
2)ThreadPoolExecutor的执行规则
ThreadPoolExecutor执行任务时大致遵从下述规则:
1.如果线程池中的线程数量未达到核心线程的数量,那么直接启动一个核心线程
2.如果线程池中的线程数量已经达到或者超过核心线程的数量,那么任务会被插入到任务队列中排队等待执行。
3.如果在步骤2中无法将任务插入到任务队列中,这往往是因为任务队列已满,这是如果先吃数量未达到线程池规定的最大值,会立即启动一个非核心线程来执行任务。
4.如果步骤3中的线程数量已经达到线程池规定的最大值,那么就拒绝执行此任务,ThreadPoolExecutor会调用RejectedExecutionHandler的rejectedExecution方法来通知调用者。
3)线程池的分类
ThreadPoolExecutor通常都是通过工厂类Executors来创建,主要有以下三种ThreadPoolTExecutor;
1.FixedThreadPool
2.SingleThreadPool
3.CacheThreadPool
4.ScheduledThreadPool
接下来重点介绍各个线程池。
1.FixedThreadPool 可重用固定线程数的线程池
下面是它的源码实现
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
其corePool和maximumPool值都被设置为创建FixedThreadPoolExecutor时指定的参数nThreads。keepAliveTime为0,即多余的空闲线程会被立即停止,任务队列采用LinkedBlockingQueue
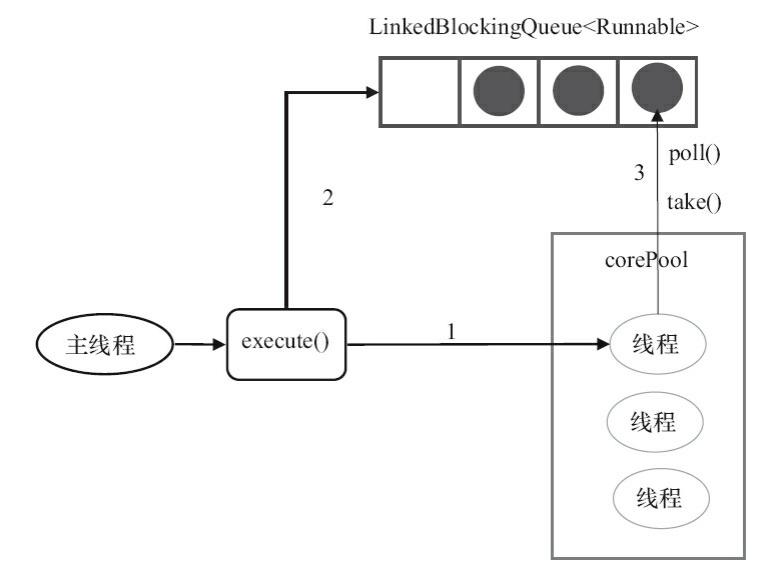
1)如果当前运行的线程数少于corePoolSize,则创建新线程来执行任务
2)当当前线程数等于corePoolSize时,将任务加入到LinkedBlockingQueue中
3)线程执行完1中的任务后,会在循环中反复从LinkedBlockingQueue中获取任务来执行。
2.SingleThreadPoolExecutor
SingleThreadPoolExecutor是使用单个工作线程的Executor,下面是它的源码实现
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
可见其核心线程数和最大线程数都为1,任务队列同样采用的是LinkedBlockingQueue。从这个角度讲,当我们把刚才的FixedThreadPoolExecutor传入的nThreads为1 时,它就和SingleThreadPoolExecutor一致。
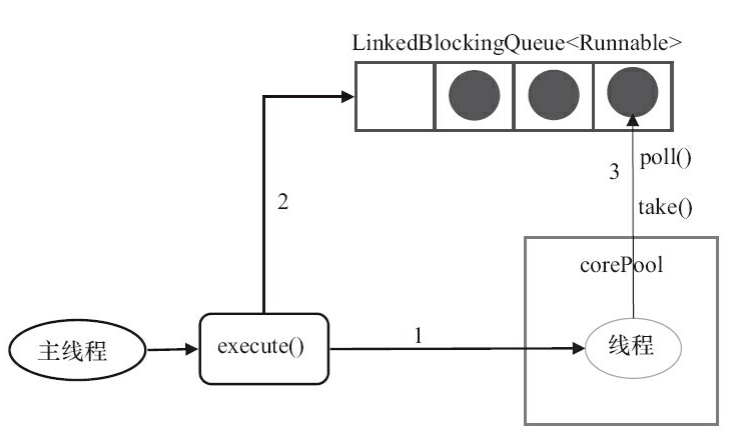
1)如果当前运行的线程数少于corePoolSize,即线程池中无运行线程,则创建新线程来执行任务
2)当当前线程数等于corePoolSize(1)时,将任务加入到LinkedBlockingQueue中
3)线程执行完1中的任务后,会在循环中反复从LinkedBlockingQueue中获取任务来执行。
3.CachedThreadPoolExecutor
CachedThreadPoolExecutor是一个根据需要创建新线程的线程池,照例贴源码:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
可以发现CachedThreadPoolExecutor它没有核心线程,而将maximumPoolSize的值设为Interger.MAX_VALUE,即为无界的。将keepAliveTime设置为60L,则意味着当CachedThreadPoolExecutor的空闲线程等待新任务的最长时间是60s,否则就会被终止。
CachedThreadPoolExecutor使用的是没有容量的SychronousQueue作为线程池的工作队列,但由于其最大线程数无界,这就意味着如果主线程提交任务的速度高于线程处理任务的速度,就会不断创建新线程,在极端情况下CachedThreadPool会因为创建过度线程耗尽CPU和内存资源。
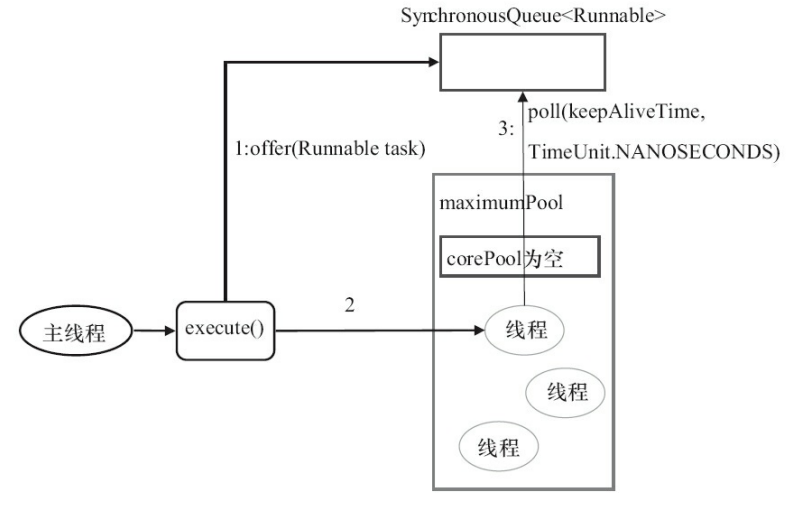
CachedThreadPoolExecutor的execute过程和前面两个有点不同,具体如下
1)首先执行SynchronousQueue.offer,提交一个任务给工作队列,如果当前的maximumPool中有空闲线程正在执行SynchronousQueue.poll,那么即匹配成功,主线程将任务交给空闲线程执行,execute方法执行完成,否则执行步骤2
2)当初始maximumPool为空或者没有空闲线程时,将没有线程执行SynchronousQueue.poll,这样配对将失败,此时线程池会新建一个线程执行任务怒,execute方法执行完成。
3)当步骤2中创建的线程将任务执行完后,会执行SynchronousQueue.poll,这个poll操作会让空闲线程最多在SychronousQueue中等待60s,如果60s内主线程没有提供新任务,空闲线程将终止。
4.ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor继承自ThreadPoolExecutor,主要用于在给定延迟之后运行任务或者定期执行任务。这点上与Timer类似,但ScheduledThreadPoolExecutor功能更强大,更灵活,不同于Timer对应于单个后台线程,ScheduledThreadPoolExecutor可以在构造函数中指定多个对应的后台线程数。
private static final long DEFAULT_KEEPALIVE_MILLIS = 10L;
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue());
}
该线程池只需要指定核心线程数,其最大线程数无界,其超时时间为10ms,并且它使用的工作队列是DelayedWorkQueue,DelayedWorkQueue是一个无界队列,所以其最大线程数没有意义。
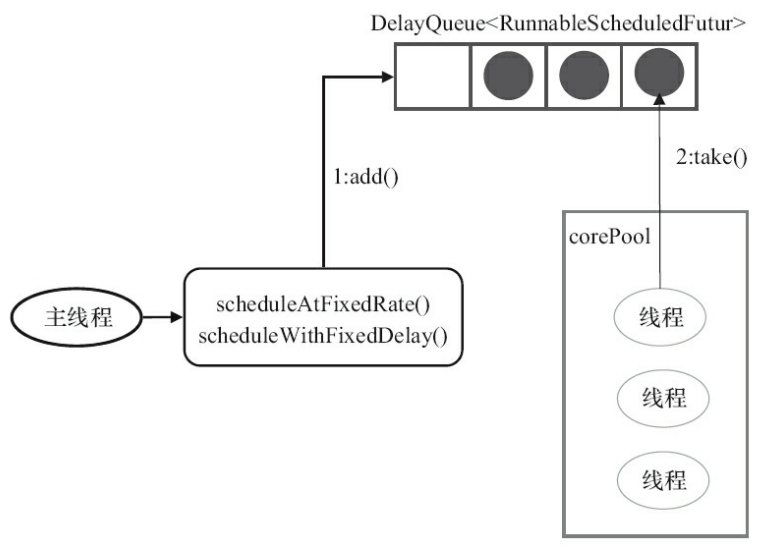
1) 当调用ScheduledThreadPoolExecutor的ScheduledThreadPoolExecutor的scheduleAtFixedRate()或scheduleWithFixedDelay()方法时,会从ScheduledThreadPoolExecutor的DelayQueue中添加一个实现了RunnbaleScheduledFuture接口的ScheduledFutureTask。
2)线程池中的线程从DelayQueue中获取ScheduledFutureTask,然后执行任务。
我们先来看一下ScheduledFutureTask的结构
private class ScheduledFutureTask<V>
extends FutureTask<V> implements RunnableScheduledFuture<V> {
ScheduledFutureTask(Runnable r, V result, long triggerTime,
long period, long sequenceNumber) {
super(r, result);
this.time = triggerTime;
this.period = period;
this.sequenceNumber = sequenceNumber;
}
}
它继承自FutureTask,它主要包括三个成员变量。如下
time:表示任务将被执行的具体时间
sequenceNumber:表示任务被添加到ScheduledThreadPoolExecutor中的序号
period:表示任务执行的间隔周期
然后我们是将这个task提交到了DelayQueue中,DelayQueue封装了一个PriorityQueue,它会对队列中的ScheduledFutureTask进行排序。排序时,time小的在前面。如果time相同,则比较sequenceNumber,sequenceNumber小的排前面。
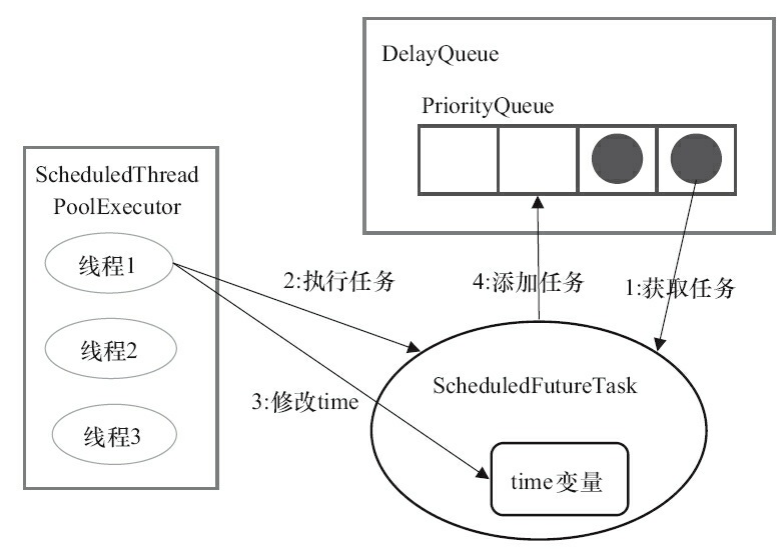
ScheduledThreadPoolExecutor的任务执行步骤
1.线程1从DelayQueue获取到期的任务(ScheduledFutureTask的time大于等于当前时间)
2.线程1 执行这个任务
3.线程1修改任务的time,变更为下次将被执行的时间
4.将修改后的任务放回到DelayQueue中。
上述获取任务和添加任务都是线程安全的(使用可重入锁 ReentrantLock)
六、AsyncTask
AsyncTask是在Executor框架基础上的再封装,它实现将耗时任务移动到工作线程中执行,同时提供了方便的接口实现工作线程和主线程之间的通信。使用AsyncTask一般都会用到如下方法:
import android.os.AsyncTask;
public class FullTask extends AsyncTask<Params,Progress,Result>{
@Override
protected void onPreExecute() {
super.onPreExecute();
}
@Override
protected Result doInBackground(Params... params) {
return null;
}
@Override
protected void onProgressUpdate(Progress... values) {
super.onProgressUpdate(values);
}
@Override
protected void onPostExecute(Result result) {
super.onPostExecute(result);
}
@Override
protected void onCancelled() {
super.onCancelled();
}
}
下面给出一个具体的例子直观地展示它的基本用法。
import android.os.AsyncTask;
import java.net.URL;
public class DownloadFilesTask extends AsyncTask<URL,Integer,Long>{
@Override
protected Long doInBackground(URL... urls) {
int count = urls.length;
long totalSize =0;
for(int i=0;i<count;i++){
totalSize += DownLoader.downloadFile(urls[i]);
publishProgress((int)((i/(float)count)*100));
if(isCancelled()){
break;
}
}
return totalSize;
}
@Override
protected void onProgressUpdate(Integer... progress) {
setProgressPercent(progress[0]);
}
@Override
protected void onPostExecute(Long result) {
showDialog("Downloader" + result+" bytes");
}
}
上述程序模拟了一个文件下载过程,当要执行上述下载任务时,可以通过如下方式来完成:
new DownloadFileTask().execute(url1,url2,url3);
在上述程序中,doInBackground用来执行具体的下载任务并通过publishProgress方法来更新下载进度,同时还要判断下载任务是否被外界取消了。当下载任务完成时,它返回结果,即下载的总字节数。这里需要注意的是doInBackground是在线程池中执行。
而onProgressUpdate用于更新界面中下载的进度。运行在主线程中,当publishProgress方法被调用的时候,它就会被调用。当下载任务完成后,onPostExecute方法会被调用,它也是运行在主线程中。这个时候我们可以给出一些相应的提示,提醒用户下载完成。
综上所述,onPreExecute()用于开始后台任务前的UI准备。onProgressUpdate用于任务进行时的UI操作,onPostExecute用于任务完成后的UI操作。而doInBackground则用于后台任务的执行。
注意点:
1.AsyncTask的类必须在主线程中加载。
2.AsyncTask的对象必须在主线程中创建。
3.execute方法必须在UI线程中调用
4.不要在程序直接调用onPreExecute()、onProgressUpdate()、onPostExecute()和doInbackground()
5.AsyncTask对象只能执行一次,即只能调用一次execute方法
6.在android3.0开始,execute()方法采用一个线程串行执行任务,而executeOnExecutor()方法可以并行执行任务。
下面结合源码,我们简单了解一下AsyncTask的原理。
我们首先看它的构造函数:
public AsyncTask() {
mWorker = new WorkerRunnable<Params, Result>() {
public Result call() throws Exception {
mTaskInvoked.set(true);
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
//noinspection unchecked
Result result = doInBackground(mParams);
Binder.flushPendingCommands();
return postResult(result);
}
};
mFuture = new FutureTask<Result>(mWorker) {
@Override
protected void done() {
try {
postResultIfNotInvoked(get());
} catch (InterruptedException e) {
android.util.Log.w(LOG_TAG, e);
} catch (ExecutionException e) {
throw new RuntimeException("An error occurred while executing doInBackground()",
e.getCause());
} catch (CancellationException e) {
postResultIfNotInvoked(null);
}
}
};
}
这个构造函数将我们传入的Params和Result先封装成了一个WorkerRunnable,再将其传入FutureTask中。这边它返回的是postResult方法,查看这个方法
private Result postResult(Result result) {
@SuppressWarnings("unchecked")
Message message = getHandler().obtainMessage(MESSAGE_POST_RESULT,
new AsyncTaskResult<Result>(this, result));
message.sendToTarget();
return result;
}
在这个方法里似乎调用了Handler,并发送了message。点开getHandler方法,最后追踪到InternalHandler类,正是它实现了执行环境从线程池到主线程的切换。,它的逻辑很常见,这边就不解释了。
private static class InternalHandler extends Handler {
public InternalHandler() {
super(Looper.getMainLooper());
}
@SuppressWarnings({"unchecked", "RawUseOfParameterizedType"})
@Override
public void handleMessage(Message msg) {
AsyncTaskResult<?> result = (AsyncTaskResult<?>) msg.obj;
switch (msg.what) {
case MESSAGE_POST_RESULT:
// There is only one result
result.mTask.finish(result.mData[0]);
break;
case MESSAGE_POST_PROGRESS:
result.mTask.onProgressUpdate(result.mData);
break;
}
}
}
获取这个Handler对象,这边有一个简单的同步。
private static Handler getHandler() {
synchronized (AsyncTask.class) {
if (sHandler == null) {
sHandler = new InternalHandler();
}
return sHandler;
}
}
前面我们通过构造函数了解了AsyncTask如何将Params和Result进行封装,如何利用Handler将执行环境从线程池切换到主线程中。接下来我们来具体看一下AsyncTask的调用过程。我们从execute()方法入手

可以看到这边注解了execute方法必须在主线程上调用,并且这个方法接着调用了executeOnExecutor方法,传入了sDefalutExecutor,这边我们首先得知道这个参数是什么,找到这个参数。
private static volatile Executor sDefaultExecutor = SERIAL_EXECUTOR;
这个sDefalutExecutor是什么呢?查找SERIAL_EXECUTOR的初始化地方,我们看到了
public static final Executor SERIAL_EXECUTOR = new SerialExecutor();
下面我们就可以查看这个SerialExecutor线程池内部类。
public static final Executor SERIAL_EXECUTOR = new SerialExecutor();
private static volatile Executor sDefaultExecutor = SERIAL_EXECUTOR;
private static class SerialExecutor implements Executor {
final ArrayDeque<Runnable> mTasks = new ArrayDeque<Runnable>();
Runnable mActive; public synchronized void execute(final Runnable r) {
mTasks.offer(new Runnable() {
public void run() {
try {
r.run();
} finally {
scheduleNext();
}
}
});
if (mActive == null) {
scheduleNext();
}
} protected synchronized void scheduleNext() {
if ((mActive = mTasks.poll()) != null) {
THREAD_POOL_EXECUTOR.execute(mActive);
}
}
}
从SerialExecutor的实现可以分析AsyncTask的串行执行的过程。首先系统会把AsyncTask的Params参数封装为FutureTask对象,这个FutrueTask对象就被充当为Runnable叫给SerialExecutor的execute方法去处理。这个方法首先会把FutureTask对象插入到任务队列mTasks中,并对其进行一定程度的封装,在后面增加了scheduleNext()方法。注意这个时候它并没有进行任务的执行(可见SerialExecutor线程池并不是用来执行任务的,而是用来任务的排队的)如果这个时候没有处理活动状态的AsyncTask任务,会调用scheduleNext()方法,来执行下一个任务。
这边我们又看到一个线程池,THREAD_POOL_EXECUTOR,这个线程池才是真正用来执行任务的。
static {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
CORE_POOL_SIZE, MAXIMUM_POOL_SIZE, KEEP_ALIVE_SECONDS, TimeUnit.SECONDS,
sPoolWorkQueue, sThreadFactory);
threadPoolExecutor.allowCoreThreadTimeOut(true);
THREAD_POOL_EXECUTOR = threadPoolExecutor;
}
接着我们回到executeOnExecutor,
@MainThread
public final AsyncTask<Params, Progress, Result> executeOnExecutor(Executor exec,
Params... params) {
if (mStatus != Status.PENDING) {
switch (mStatus) {
case RUNNING:
throw new IllegalStateException("Cannot execute task:"
+ " the task is already running.");
case FINISHED:
throw new IllegalStateException("Cannot execute task:"
+ " the task has already been executed "
+ "(a task can be executed only once)");
}
} mStatus = Status.RUNNING; onPreExecute(); mWorker.mParams = params;
exec.execute(mFuture); return this;
}
不难发现上面进行了两个异常抛出,这就是我们先前提到的在execute方法只能执行一次。在executeOnExecutor方法中onPreExecute()方法最早被执行,而后再调用execute进入到我们先去讲到的SerialExecutor线程池进行任务的排队,最后进入任务执行的线程池进行任务的执行。
至此,大部分结构就算理清了。
七、总结
Android平台提供了上述诸多异步处理技术,我们在进行选择的时候需要根据就提的需要而定。
主要的参考点:
- 尽量少地占用系统资源,如cpu和内存
- 为应用提供更好的性能和响应度
- 实现和使用起来复杂度不高,结构清晰。
- 写出来的代码是否符合好的设计,是否容易理解和维护。
Android异步处理技术的更多相关文章
- Android异步下载图片并且缓存图片到本地
Android异步下载图片并且缓存图片到本地 在Android开发中我们经常有这样的需求,从服务器上下载xml或者JSON类型的数据,其中包括一些图片资源,本demo模拟了这个需求,从网络上加载XML ...
- Android 异步消息处理机制终结篇 :深入理解 Looper、Handler、Message、MessageQueue四者关系
版权声明:本文出自汪磊的博客,转载请务必注明出处. 一.概述 我们知道更新UI操作我们需要在UI线程中操作,如果在子线程中更新UI会发生异常可能导致崩溃,但是在UI线程中进行耗时操作又会导致ANR,这 ...
- 深入探讨Android异步精髓Handler
探索Android软键盘的疑难杂症 深入探讨Android异步精髓Handler 详解Android主流框架不可或缺的基石 站在源码的肩膀上全解Scroller工作机制 Android多分辨率适配框架 ...
- 关于如何提高Web服务端并发效率的异步编程技术
最近我研究技术的一个重点是java的多线程开发,在我早期学习java的时候,很多书上把java的多线程开发标榜为简单易用,这个简单易用是以C语言作为参照的,不过我也没有使用过C语言开发过多线程,我只知 ...
- Atitit.异步编程技术原理与实践attilax总结
Atitit.异步编程技术原理与实践attilax总结 1. 俩种实现模式 类库方式,以及语言方式,java futuretask ,c# await1 2. 事件(中断)机制1 3. Await 模 ...
- Android的NDK技术
Android的NDK技术
- 本人讲课时录制的Android应用开发技术教学视频
网盘地址:http://yun.baidu.com/pcloud/album/info?query_uk=1963923831&album_id=3523786484935252365 本人讲 ...
- Android异步回调中的UI同步性问题
Android程序编码过程中,回调无处不在.从最常见的Activity生命周期回调开始,到BroadcastReceiver.Service以及Sqlite等.Activity.BroadcastRe ...
- 【android异步处理】一个关于android异步处理的文章系列
最近读了Android异步处理系列文章索引,感觉这个文章系列写得不错!可以作为参考
随机推荐
- CentOS7安装docker 启动不了解决篇
[root@test ~]# yum update [root@test ~]# yum install docker [root@test ~]# service docker start Redi ...
- 数据结构与算法(c++)——查找二叉树与中序遍历
查找树ADT--查找二叉树 定义:对于树中的每个节点X,它的左子树中的所有项的值小于X中的项,而它的右子树中所有项的值大于X中的项. 现在给出字段和方法定义(BinarySearchTree.h) # ...
- 关于MATLAB处理大数据坐标文件2017620
暑假已至,接下来组内成员将会各回各家,各找各妈,这肯定是对本次大数据比赛是很不利的. 接下来我会把任务分配给组员,当然任务会比起初的时候轻一点,因为我认为本次比赛的目的并不是我要求组员做什么,而是我的 ...
- 关于MATLAB处理大数据坐标文件201761
前几天备战考试,接下来的日子将会继续攻克大数据比赛 虽然停止了一段时间没有提交数据,但是这几天的收获还是有的,对Python 随机森林了解的更了解了 随机森林是由多课决策树组成(当然这个虽然我们初学者 ...
- DataFrame创建
DataFrame/DataSet 创建 读文件接口 import org.apache.spark.sql.SparkSession val spark = SparkSession .builde ...
- bootstrap-datepicker的bug:有日期输入的地方在下个月页面选择当天日期会以当天日期减少一个月显示
Bug复现详细描述:先选择今日日期,然后点击下个月的某个日期,注意,是直接点击下个月的某个日期,不能通过日期显示tab的下个月箭头进入下个月再来点击某个日期,然后再直接点击本月的今日日期.然后bug会 ...
- css清除浮动float
css清除浮动float 1.分析HTML代码 <div class="outer"> <div class="div1">1</ ...
- 从 JavaScript 到 TypeScript
本文首发在我的个人博客:http://muyunyun.cn/posts/66a54fc2/ 文中的案例代码已经上传到 TypeScript TypeScript 并不是一个完全新的语言, 它是 Ja ...
- pl_sql develope连接远程数据库的方法
需要修改你所安装的数据的路径下 tnsnames.ora 文件(我安装路径是F:\app\Aside\product\11.2.0\dbhome_1\NETWORK\ADMIN) tnsnames.o ...
- ionicangular 成长日记
//首先配置文件ionic.bundle.min.jsionic.min.css" //创建一个angular控制器,控制器给body/html都可以angular.module('myap ...