分布式计算框架学习笔记--hadoop工作原理
(hadoop安装方法:http://blog.csdn.net/wangjia55/article/details/53160679这里不再累述)
hadoop是针对大数据设计的一个计算架构。如果你有几百TB的数据需要检索,你在控制终端敲下命令,计算机会向几百分布式台云服务器同时发布命令,使他们开始运行。并且把结果返回给你
hadoop分为大概念,
HDFS(分布式文件系统)+MapReduce(分布式计算模型)
HDFS 优点
适合大文件的存储,并且由备份策略,有比较好的容错和恢复机制,支持流式数据访问,一次写入,多次读取最高效
HDFS 缺点
不适合大量小文件的存储
不适合并发写入,不支持文件的随机修改(只能后续添加)
不适合随机读等低延时的访问方式
存储的三个概念:
block 是一个存储的数据块,hadoop的数据存储是以数据块为单位的(而非文件)(这样的有点是易于备份,而且简化了数据空间的设计)这里有点类似于磁盘的数据块,
NameNode 是一个管理节点,它管理文件系统的命名空间,存放文件数据(这个节点相当于一个枢纽,它的保护措施是,创建一个备用节点,NameNode和备用节点的内容时刻保持一致,当NameNode崩溃的时候,会马上启用另一个节点)
维护文件系统所有的文件和目录,文件与数据块之间的映射
记录着每个文件中各个块所在的数据节点的信息。
DataNode 是数据块的实际存储点,也是工作节点,存储并检索数据块,向NameNode时刻更新所存储的数据块的列表
文件的写流程:当用户需要写一个文件进去时候,先向namenode发送请求,然后namenode把分配的datanode1、datanode2、datanode3的地址和凭证构成的存储单(假设这个清单上要求数据备份在2和3节点上)返回给用户端,用户端开始对文件进行分块,然后把第一个数据块和相应存储单的发给datanode1,datanode1存储完了以后,会向namenode发送存储报告,并且把这个数据块的信息和相应的数据块存储单转发给datanode2来备份······datanode2再把数据块转发给datanode3(也就是说datanode会自动通知其他几个datanode完成数据的备份操作),相应的存储完以后,节点2和节点3也会发送相应存储报告。
hdfs是流式数据访问,也就是说,一个数据块一旦被写入,块内的数据就不能再做随机修改,如果要修改,删除这个磁盘块,然后再把整个块的数据重新写入,(每次访问也只能从块的首部开始访问)。
它不支持用户并发的写相同的文件(不想sql数据库文件一样,可以让多个线程并发的读或者写)
namenode会找距离最近的一个datanode节点的信息
文件的读流程也相似,这里不再累述
Hadoop默认的调度器是基于队列的FIFO调度器:
所有用户的作业都被提交到一个队列中,然后由JobTracker先按照作业的优先级高低,再按照作业提交时间 的先后顺序选择将被执行的作业。
优点: 调度算法简单明了,JobTracker工作负担轻。
缺点: 忽略了不同作业的需求差异。
Fair Scheduler(公平调度器):
1:多个Pool,Job需要被提交到某个Pool中;
2:每个pool可以设置最小 task slot(猜测最小的job数),称为miniShare
3:FS会保证Pool的公平,Pool内部支持Priority(优先级)设置,支持资源抢占(优先级)
hdfs的shell命令 ls,cat, mkdir,rm,chmod ,chown等
hdfs的文件交互命令 copyFromLocal,copToLocal,get,put
常用命令:https://www.cnblogs.com/gaopeng527/p/4314215.html
MapReduce计算框架
mapreduce 计算框架使用的是分而治之的概念,一个大任务分成多个小的子任务(map),执行完,从map端输出后,会进行网络混洗,经过shuffle层后进入reduce(在shuffle层混洗时,如果数据量较大,会造成很大的网络开销,故可以先按照key先进行一轮排序与合并,再开始网络混洗,这个过程就combine),合并结果(reduce)
2.0以前的框架的结构学习笔记:
这里面有两个概念JobTracker和TaskTracker,
JobTracker 对应于 NameNode
TaskTracker 对应于 DataNode
JobTracker介绍
首先用户程序(JobClient)提交了一个job,job的信息会发送到JobTracker,JobTracker是Map-reduce框架的中心,会先将任务拆分成多个map任务(也就是子任务),分发给map层的各个datanode,等计算完成以后,结果会被发送到 reduce层的各个datanode进行合并同时他还需要与集群中的机器定时通信heartbeat(也就是心跳协议),需要管理哪些程序应该跑在哪些机器上,需要管理所有job失败、重启等操作。
JobTracker后台程序用来连接应用程序与Hadoop。由JobTracker决定哪个文件将被处理,每个Hadoop集群只有一个JobTracker,一般运行在集群的Master节点上
TaskTracker介绍
TaskTracker是Map-Reduce集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
TaskTracker同时监视当前机器的tasks运行状况。TaskTracker需要把执行状态和任务进度通过heartbeat发送给JobTracker,JobTracker会搜集这些信息以给新提交的job分配运行在哪些机器上。
MapReduce的容错机制
1重复执行,当一个datanode执行任务失败的时候,jobtracker会自动命令他重新执行,一般默认现需重新执行4次都失败的话,放弃这个节点,寻找一个和它存储内容相同的节点,继续执行,
2.推测执行,当一个datanode执行速度特别慢的时候,jobtracker则推测它出现了问题,jobtracker也会找一台和它存储相同内容的节点,来一起执行,谁先执行完,就终止另一台的执行。
新旧对比
yarn
yarn是hadoop2.0之后的版本的一个总的资源管理器,yarn中有三个概念,ResourceManager ,ApplicationMaster,和NodeManager
ResourceManager 负责调度资源,并且启动和监控ApplicationMaster和NodeManager,
ResourceManager在执行过程中不对task进行监控和状态跟踪(而是只监控ApplicationMaster和)。同样,它也不能重启因应用失败或者硬件错误而运行失败的任务。
ApplicationMaster为MapReduce类型的程序申请资源,并且分配给内部任务。负责数据的切分,监控任务的执行和容错,
NodeManager,管理单个节点的资源,处理ResourceManager的命令,处理来自ApplicationMaster的命令。NodeManager是每一台机器框架的代理,监控应用程序的资源使用情况(CPU 内存 磁盘 网络)并且向调度器汇报。
注意:yarn中jobtracker所负责的任务拆分成两个部分,资源的分配ResourceManager和对每个独立任务ApplicationMaster的管理:ResourceManager仍然运行在namenode上,负责监控所有datanode,而任务管理方面:每一个任务都会独立成立一个ApplicationMaster,这个ApplicationMaster不一定运行在哪个DataNode上,这样我们就可以设置用相对闲置的DataNode来运行ApplicationMaster。
Container是Yarn为资源分配提出的一个方案,当ApplicationMaster向ResourceManager申请资源时,ResourceManager返回的资源就被描述为container,一般而言,一个container只能用于执行一个task(一个job是一个总的任务,它会被分割成多个task,每一个task在一个datanode上执行),目前是一个框架,仅仅提供Java虚拟机内存的隔离,hadoop团队的设计思路应该后续能支持更多的资源调度和控制。
ResourceManager内部运行原理:
可参看:http://blog.csdn.net/zcc_0015/article/details/34921981

上图描述的6个步骤解释如下:
步骤1.ApplicationMasterLauncher与对应的NodeManager联系,启动ApplicationMaster。
步骤2.ApplicationMasterLivenessMonitor添加监控列表,启动对ApplicationMaster的监控列表,启动对ApplicationMaster的监控。
步骤3.ApplicationMaster启动后,向ApplicationMasterService注册,公布自己的URL,访问接口等。
步骤4.ApplicationMaster定期向ApplicationMasterService发送心跳,及时更新自己的信息,便于RM进行管理。
步骤5.当application job执行完毕后,ApplicationMaster向ApplicationMaster Service报告执行完成。
步骤6.ApplicationMaster Service 通知ApplicationMasterLivenessMonitor从监控列表中删除ApplicationMaster,释放资源
- ApplicationMaster存活监控
帮助管理活跃的及死的/不响应ApplicationMaster
map-shuffle-reduce工作原理(其中假设每个map中含有三个数据块,不同颜色的方块表示不同的分割区间。)
http://xxx.xxx.xxx.xxx:50070/查看hadoop各节点的运行情况,(其中xxx.xxx.xxx.xxx指的是所填的ip,必须是namenode的ip)
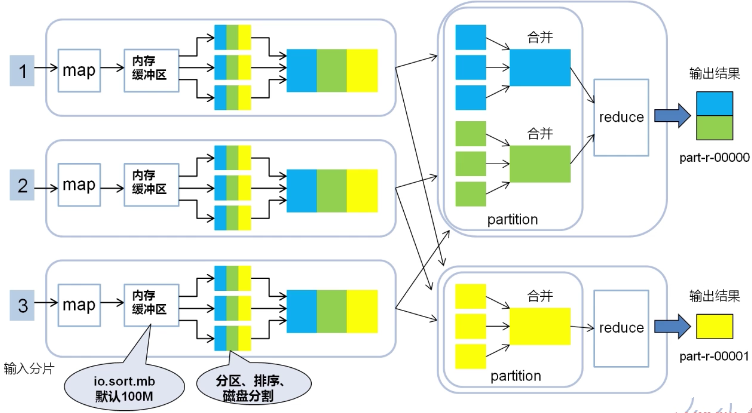
一个mapreduce作业中,partition的数量和reduce的数量和最终输出结果文件(如part-r-0001)的数量是相等的(小细节:在一个reduce中,所有数据都会按照key升序排列,故如果part输出文件包含的key值,则这个文件一定是有序的。)
hadoop的分布式缓存机制
在执行mapreduce时,可能mapper之间需要共享一些信息,如果信息量不大,可以将其从hdfs加载到内存中(每个datanode上的内存里会加载相同的共享数据),这就是hadoop的分布式缓存机制。(如果数据量太大可以将共享数据分批缓存重复执行作业)
hadoop生态圈
简要介绍,HBase是一个高可靠,高性能,面向列,可伸缩,实时读写的分布式数据库,利用hdfs作为文件存储系统,支持MR程序读取数据,存储非结构化和半结构化以及结构化的数据,column family 列族,多个列的集合,最多不超过三个
spark是一个基于内存的分布式大数据并行计算框架,spark也是MapReduce的替代方案,兼容hdfs,hive等数据源,spark抽象出分布式内存存储数据结构,弹性分布式数据集RDD,基于事件驱动,通过线程池复用线程提高性能
分布式计算框架学习笔记--hadoop工作原理的更多相关文章
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- [转]dwr3框架学习笔记--简介及原理简介
1.DWR简介 DWR(直接web远程访问),DWR是一个Java库,使服务器上的Java和JavaScript的浏览器进行交互和相互调用尽可能简单. DWR 是一个可以允许你去创建 AJAX WEB ...
- JavaSE中Collection集合框架学习笔记(2)——拒绝重复内容的Set和支持队列操作的Queue
前言:俗话说“金三银四铜五”,不知道我要在这段时间找工作会不会很艰难.不管了,工作三年之后就当给自己放个暑假. 面试当中Collection(集合)是基础重点.我在网上看了几篇讲Collection的 ...
- SSM框架学习笔记_第1章_SpringIOC概述
第1章 SpringIOC概述 Spring是一个轻量级的控制反转(IOC)和面向切面(AOP)的容器框架. 1.1 控制反转IOC IOC(inversion of controller)是一种概念 ...
- phalcon(费尔康)框架学习笔记
phalcon(费尔康)框架学习笔记 http://www.qixing318.com/article/phalcon-framework-to-study-notes.html 目录结构 pha ...
- Yii框架学习笔记(二)将html前端模板整合到框架中
选择Yii 2.0版本框架的7个理由 http://blog.chedushi.com/archives/8988 刚接触Yii谈一下对Yii框架的看法和感受 http://bbs.csdn.net/ ...
- JavaSE中Collection集合框架学习笔记(3)——遍历对象的Iterator和收集对象后的排序
前言:暑期应该开始了,因为小区对面的小学这两天早上都没有像以往那样一到七八点钟就人声喧闹.车水马龙. 前两篇文章介绍了Collection框架的主要接口和常用类,例如List.Set.Queue,和A ...
- JavaSE中线程与并行API框架学习笔记1——线程是什么?
前言:虽然工作了三年,但是几乎没有使用到多线程之类的内容.这其实是工作与学习的矛盾.我们在公司上班,很多时候都只是在处理业务代码,很少接触底层技术. 可是你不可能一辈子都写业务代码,而且跳槽之后新单位 ...
- JavaSE中线程与并行API框架学习笔记——线程为什么会不安全?
前言:休整一个多月之后,终于开始投简历了.这段时间休息了一阵子,又病了几天,真正用来复习准备的时间其实并不多.说实话,心里不是非常有底气. 这可能是学生时代遗留的思维惯性--总想着做好万全准备才去做事 ...
随机推荐
- bzoj 2727: [HNOI2012]双十字
Description 在C 部落,双十字是非常重要的一个部落标志.所谓双十字,如下面两个例子,由两条水平的和一条竖直的"1"线段组成,要求满足以下几个限制: 我们可以找到 5 个 ...
- 入门级Nginx反向代理nodejs
本着想实现前后端分离开发的初衷,我决定学习一下关于nignx反向代理的配置. 1.下载Nginx稳定版本 2.打开nginx配置文件 nginx.conf: 3.在http模块的server部分配置 ...
- eKing Cloud基础云平台演进之路
出口转内销.首发于公司微信公众号,作者本人,现转载到此.本来写得比较技术,还算有点干货,但是结果被编辑咔咔咔,就只剩下下面这些内容. 大型企业如何开启自己的快速上云之路? 2017-12-08 易建科 ...
- C#的发展已经15年了 。。。历史发展
C#是微软公司在2000年6月发布的一种新的编程语言,主要由安德斯·海尔斯伯格(Anders Hejlsberg)主持开发,它是第一个面向组件的编程语言,其源码会编译成msil再运行.它借鉴了Delp ...
- K:java中正则表达式的使用说明及其举例
从Java1.4起,java核心API就引入了java.util.regex程序包来处理正则表达式,并使用该包下的相关类进行字符串的匹配.搜索.提取.分析结构化内容等工作.需要注意的是,正则表达式本身 ...
- Java Serializable接口(序列化)理解及自定义序列化
1 Serializable接口 (1)简单地说,就是可以将一个对象(标志对象的类型)及其状态转换为字节码,保存起来(可以保存在数据库,内存,文件等),然后可以在适当的时候再将其状态恢复(也就是反 ...
- Python列表操作
自带帮助文档: >>> help(list) Help on class list in module builtins: class list(object) | list() - ...
- Python个人项目--豆瓣图书个性化推荐
项目名称: 豆瓣图书个性化推荐 需求简述:从给定的豆瓣用户名中,获取该用户所有豆瓣好友列表,从豆瓣好友中找出他们读过的且评分5星的图书,如果同一本书被不同的好友评5星,评分人数越多推荐度越高. 输入: ...
- C# DataGridView 列的显示顺序
this.dataGridView1.Columns["列名"].DisplayIndex=Convert.ToInt32("你要放置的位置")
- Life in Changsha 第一次scrum冲刺
第一次冲刺任务 基于大局的全面性功能框架定位,要求能实现用户基于自己的需求进行的一系列操作. 用户故事 用户打开“生活在长大”的界面 程序首页展示校园服务,论坛等相关信息 用户选择某个功能 程序界面跳 ...