使用TensorFlow中的Batch Normalization
问题
训练神经网络是一个很复杂的过程,在前面提到了深度学习中常用的激活函数,例如ELU或者Relu的变体能够在开始训练的时候很大程度上减少梯度消失或者爆炸问题,但是却不能保证在训练过程中不出现该问题,例如在训练过程中每一层输入数据分布发生了改变了,那么我们就需要使用更小的learning rate去训练,这一现象被称为internal covariate shift,Batch Normalization能够很好的解决这一问题。目前该算法已经被广泛应用在深度学习模型中,该算法的强大至于在于:
- 可以选择一个较大的学习率,能够达到快速收敛的效果。
- 能够起到Regularizer的效果,在一些情况下可以不使用Dropout,因为BN提高了模型的泛化能力
介绍
我们在将数据输入到神经网络中往往需要对数据进行归一化,原因在于模型的目的就是为了学习模型的数据的分布,如果训练集的数据分布和测试集的不一样那么模型的泛化能力就会很差,另一方面如果模型的每一 batch的数据分布都不一样,那么模型就需要去学习不同的分布,这样模型的训练速度会大大降低。
BN是一个独立的步骤,被应用在激活函数之前,它简单地对输入进行零中心(zero-center)和归一化(normalize),然后使用两个新参数来缩放和移动结果(一个用于缩放,另一个用于缩放转移)。 换句话说,BN让模型学习最佳的尺度和 每层的输入的平均值。
为了零中心和归一化数据的分布,BN需要去估算输入的mean和standard deviation,算法的计算过程如下:
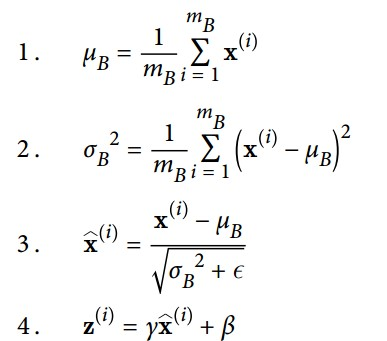
其中:
- \(u_B\)是mini-btach \(B\)的均值,\(\sigma\)是mini-btach的标准差
- \(m_B\)是mini-batch中的样本
- \(\hat{x}^{(i)}\) 是zero-center和normalize后的输入
- 公式4是一个线性变换,是对数据分布的重构,\(z^{(i)}\)是算法对数据重构的output,\(\gamma\)和\(\beta\)分别代表的是对数据的
scale和shift,是我们需要学习的参数
应用
接下来我们就使用TensorFlow来实现带有BN的神经网络,步骤和前面讲到的很多一样,只是在输入激活函数之前多处理了一部而已,在TF中我们使用的实现是tf.layers.batch_normalization。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./") #自动下载数据到这个目录
tf.reset_default_graph()
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
training = tf.placeholder_with_default(False, shape=(), name='training')
hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1")
bn1 = tf.layers.batch_normalization(hidden1, training=training, momentum=0.9)
bn1_act = tf.nn.elu(bn1)
hidden2 = tf.layers.dense(bn1_act, n_hidden2, name="hidden2")
bn2 = tf.layers.batch_normalization(hidden2, training=training, momentum=0.9)
bn2_act = tf.nn.elu(bn2)
logits_before_bn = tf.layers.dense(bn2_act, n_outputs, name="outputs")
logits = tf.layers.batch_normalization(logits_before_bn, training=training,
momentum=0.9)
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,logits=logits)#labels允许的数据类型有int32, int64
loss = tf.reduce_mean(xentropy,name="loss")
learning_rate = 0.01
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits,y,1) #取值最高的一位
accuracy = tf.reduce_mean(tf.cast(correct,tf.float32)) #结果boolean转为0,1
init = tf.global_variables_initializer()
saver = tf.train.Saver()
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
n_epochs = 20
batch_size = 200
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run([training_op, extra_update_ops],
feed_dict={training: True, X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
y: mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
在上面代码中有一句需要解释一下
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
这是因为在计算BN中需要计算moving_mean和moving_variance并且更新,所以在执行run的时候需要将其添加到执行列表中。我们还可以这样写
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(extra_update_ops):
training_op = optimizer.minimize(loss)
在训练的时候就只需要更新一个参数
sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch})
此外,我们会发现在编写神经网络代码中,很多代码都是重复的可以将其模块化,例如将构建每一层神经网络的代码封装成一个function,不过这都是后话,看个人喜好吧。
使用TensorFlow中的Batch Normalization的更多相关文章
- 在tensorflow中使用batch normalization
问题 训练神经网络是一个很复杂的过程,在前面提到了深度学习中常用的激活函数,例如ELU或者Relu的变体能够在开始训练的时候很大程度上减少梯度消失或者爆炸问题,但是却不能保证在训练过程中不出现该问题, ...
- tensorflow中使用Batch Normalization
在深度学习中为了提高训练速度,经常会使用一些正正则化方法,如L2.dropout,后来Sergey Ioffe 等人提出Batch Normalization方法,可以防止数据分布的变化,影响神经网络 ...
- Pytorch中的Batch Normalization操作
之前一直和小伙伴探讨batch normalization层的实现机理,作用在这里不谈,知乎上有一篇paper在讲这个,链接 这里只探究其具体运算过程,我们假设在网络中间经过某些卷积操作之后的输出的f ...
- PyTorch中的Batch Normalization
Pytorch中的BatchNorm的API主要有: 1 torch.nn.BatchNorm1d(num_features, 2 3 eps=1e-05, 4 5 momentum=0.1, 6 7 ...
- 神经网络中使用Batch Normalization 解决梯度问题
BN本质上解决的是反向传播过程中的梯度问题. 详细点说,反向传播时经过该层的梯度是要乘以该层的参数的,即前向有: 那么反向传播时便有: 那么考虑从l层传到k层的情况,有: 上面这个 便是问题所在.因为 ...
- tensorflow中batch normalization的用法
网上找了下tensorflow中使用batch normalization的博客,发现写的都不是很好,在此总结下: 1.原理 公式如下: y=γ(x-μ)/σ+β 其中x是输入,y是输出,μ是均值,σ ...
- Batch Normalization原理及其TensorFlow实现——为了减少深度神经网络中的internal covariate shift,论文中提出了Batch Normalization算法,首先是对”每一层“的输入做一个Batch Normalization 变换
批标准化(Bactch Normalization,BN)是为了克服神经网络加深导致难以训练而诞生的,随着神经网络深度加深,训练起来就会越来越困难,收敛速度回很慢,常常会导致梯度弥散问题(Vanish ...
- tensorflow 的 Batch Normalization 实现(tf.nn.moments、tf.nn.batch_normalization)
tensorflow 在实现 Batch Normalization(各个网络层输出的归一化)时,主要用到以下两个 api: tf.nn.moments(x, axes, name=None, kee ...
- BN(Batch Normalization)
Batch Nornalization Question? 1.是什么? 2.有什么用? 3.怎么用? paper:<Batch Normalization: Accelerating Deep ...
随机推荐
- Structured Streaming从Kafka 0.8中读取数据的问题
众所周知,Structured Streaming默认支持Kafka 0.10,没有提供针对Kafka 0.8的Connector,但这对高手来说不是事儿,于是有个Hortonworks的邵大牛(前段 ...
- Bootstrap学习笔记(二)---常见工具和流程导航范例
使用bootstrap框架避免不了写CSS,当CSS文件较大时,会发现维护起来很麻烦,一些默认值,如行高.背景色.标注颜色.字号等信息往往反复出现,还有一些大体上一致,只有小部分不同的样式定义,这就需 ...
- 初次使用Python脚本,proto协议文件转Lua代码
使用IntelliJ IDEA编辑器编写Lua脚本的时候,安装一个插件 "EmmyLua" 可以对有代码提示功能 想把protoBuf协议文件转成Lua代码,然后给出代码提示 第一 ...
- vue.js之过滤器,自定义指令,自定义键盘信息以及监听数据变化
一.监听数据变化 1.监听数据变化有两种,深度和浅度,形式如下: vm.$watch(name,fnCb); //浅度 vm.$watch(name,fnCb,{deep:true}); //深度监视 ...
- 在win7下用net命令无法实现对用户的创建(未完成)
============================================================================================= 201307 ...
- [编织消息框架][JAVA核心技术]annotation基础
应用动态代理技术要先掌握annotation技术 注解是JDK1.5之后才有的新特性,JDK1.5之后内部提供的三个注解 @Deprecated 意思是“废弃的,过时的” @Override 意思是“ ...
- 图解JQUERY尺寸及位置定义
最近在学习JQUERY的一些应用,接触到了JQUERY对于元素尺寸及位置定义,还有就是配合浏览器尺 寸及状态的计算所做出的一些动画特效.其实像这类JQUERY应用无外乎涉及这些属性的调用:innerH ...
- Django学习日记02_项目环境
创建一个工程: django-admin.py startproject mySite 将会产生以下文件: mySite/ manage.py mySite/ __init_ ...
- Linux入门篇(一)——基本命令
这一系列的Linux入门都是本人在<鸟哥的Linux私房菜>的基础上总结的基本内容,主要是记录下自己的学习过程,也方便大家简要的了解 Linux Distribution是Ubuntu而不 ...
- mac os x使用Git和bitbucket
简而言之,Git是一个分布式的代码版本管理工具.类似的常用工具还有SVN,CVS. Git相比SVN,CVS,最大的特点也是优点在于提供分布式的代码管理.这不是说SVN等不具有该功能,但就目前来看,G ...