利用docker搭建spark hadoop workbench
目的
- 用docker实现所有服务
- 在spark-notebook中编写Scala代码,实时提交到spark集群中运行
- 在HDFS中存储数据文件,spark-notebook中直接读取
组件
- Spark (Standalone模式, 1个master节点 + 可扩展的worker节点)
- Spark-notebook
- Hadoop name node
- Hadoop data node
- HDFS FileBrowser
实现
最初用了Big Data Europe的docker-spark-hadoop-workbench,但是docker 服务运行后在spark-notebook中运行代码会出现经典异常:
java.lang.ClassCastException: cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD
发现是因为spark-notebook和spark集群使用的spark版本不一致. 于是fork了Big Data Europe的repo,在此基础上做了一些修改,基于spark2.11-hadoop2.7实现了一个可用的workbench.
运行docker服务
docker-compose up -d
扩展spark worker节点
docker-compose scale spark-worker=
测试服务
各个服务的URL如下:
Namenode: http://localhost:50070
Datanode: http://localhost:50075
Spark-master: http://localhost:8080
Spark-notebook: http://localhost:9001
Hue (HDFS Filebrowser): http://localhost:8088/home
以下是各个服务的运行截图
HDFS Filebrower

Spark集群

Spark-notebook

运行例子
1. 上传csv文件到HDFS FileBrowser,
2. Spark notebook新建一个notebook
3. 在新建的notebook里操作HDFS的csv文件
具体的步骤参考这里
以下是spark-notebook运行的截图:
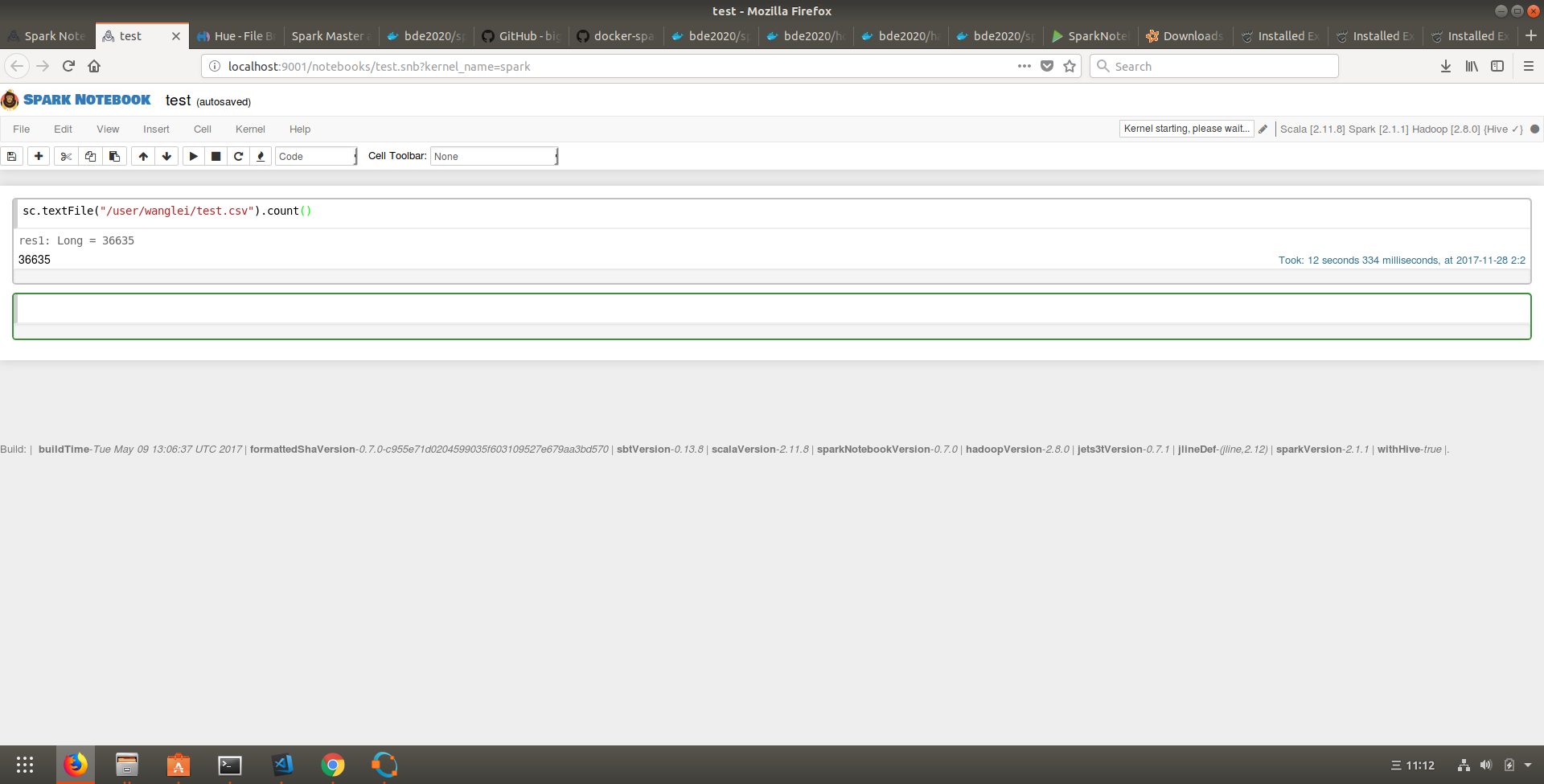
代码链接
利用docker搭建spark hadoop workbench的更多相关文章
- 使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析 ...
- Windows下搭建Spark+Hadoop开发环境
Windows下搭建Spark+Hadoop开发环境需要一些工具支持. 只需要确保您的电脑已装好Java环境,那么就可以开始了. 一. 准备工作 1. 下载Hadoop2.7.1版本(写Spark和H ...
- 利用Docker搭建本地https环境的完整步骤
利用Docker搭建本地https环境的完整步骤 这篇文章主要给大家介绍了关于如何利用Docker搭建本地https环境的完整步骤,文中通过示例代码将实现的步骤介绍的非常详细,对大家的学习或者工作具有 ...
- 利用 Docker 搭建 IPFS 私有网络
利用 Docker 搭建 IPFS 私有网络 本文原始地址:https://sitoi.cn/posts/40630.html 下载项目 项目地址:https://github.com/Sitoi/p ...
- 利用 Docker 搭建单机的 Cloudera CDH 以及使用实践
想用 CDH 大礼包,于是先在 Mac 上和 Centos7.4 上分别搞个了单机的测试用.其实操作的流和使用到的命令差不多就一并说了: 首先前往官方下载包: https://www.cloudera ...
- 利用Docker搭建开发环境
一. 前言 随着平台的不断壮大,项目的研发对于开发人员而言,对于外部各类环境的依赖逐渐增加,特别是针对基础服务的依赖.这些现象导致开 发人员常常是为了简单从而直接使用公有的基础组件进行协同开发,在出现 ...
- ubuntu14.04环境下利用docker搭建solrCloud集群
在Ubuntu14.04操作系统的宿主机中,安装docker17.06.3,将宿主机的操作系统制作成docker基础镜像,之后使用自制的基础镜像在docker中启动3个容器,分配固定IP,再在3个容器 ...
- Docker入门详解——安装docker并利用docker搭建lnmp
首先我们需先安装docker环境,这个比较简单,以centos7为例 docker在centos7上安装需要系统内核版本3.10+,可以通过uname -r查看内核版本号,如果版本不符请自行查阅资料更 ...
- Docker 搭建Spark 依赖singularities/spark:2.2镜像
singularities/spark:2.2版本中 Hadoop版本:2.8.2 Spark版本: 2.2.1 Scala版本:2.11.8 Java版本:1.8.0_151 拉取镜像: [root ...
随机推荐
- maven的java web项目启动找不到Spring ContextLoaderListener的解决办法
用maven搭建的java web项目,上传到git仓库后,当同事clone下来项目,部署到tomcat运行时,就报了如下错误,即启动web项目时,加载web.xml文件,找不到spring的监听器, ...
- Jfinal配置不得不注意的问题
问题摘要 使用jfinal mvc开发的时候,输出配置环境一定要注意,因为jfinal项目的依赖与log4j,等全部是在此目录下. 使用eclipse做演示一般有两种情况 1. WebContent\ ...
- java如何调用接口方式一
java如何调用接口 其实对于java调用接口进行获取对方服务器的数据在开发中特别常见,然而一些常用的基础的知识总是掌握不牢,让人容易忘记,写下来闲的时候看看,比回想总会好一些. 总体而言,一些东西知 ...
- LINUX 笔记-scp命令
从本地服务器复制到远程服务器: (1) 复制文件: 命令格式: scp local_file remote_username@remote_ip:remote_folder (2) 复制目录: 命令格 ...
- Java的绝对路径和相对路径
Java的绝对路径和相对路径 参考:http://blog.csdn.net/u011225629/article/details/46872775 1. 绝对路径 以根部件开始的路径是绝对路径,比如 ...
- Kotlin——最详细的接口使用、介绍
在Kotlin中,接口(Interface)的使用和Java中的使用方式是有很大的区别.不管是接口中的属性定义,方法等.但是定义方式还是相同的. 目录 一.接口的声明 1.接口的声明 关键字:inte ...
- Android开发中的OpenCV霍夫直线检测(Imgproc.HoughLines()&Imgproc.HoughLinesP())
本文为作者原创,转载请注明出处(http://www.cnblogs.com/mar-q/)by 负赑屃 //2017-04-21更新: 很多网友希望能得到源码,由于在公司做的,所以不太方便传出来 ...
- d3根据数据绘制不同的形状
绘制力导向图的时候通常节点都是圆形,但也会遇到公司节点绘制成圆型,人绘制成方形的情况,那我们怎么依据数据绘制不同的形状. 你可能首先会想到,这很简单啊,是公司的时候append circle,是人的时 ...
- ES6 class的继承使用细节
ES6 class的继承与java的继承大同小异,如果学过java的话应该很容易理解,都是通过extends关键字继承. class Animal{ constructor(color){ this. ...
- Python 爬虫:把廖雪峰教程转换成 PDF 电子书
写爬虫似乎没有比用 Python 更合适了,Python 社区提供的爬虫工具多得让你眼花缭乱,各种拿来就可以直接用的 library 分分钟就可以写出一个爬虫出来,今天尝试写一个爬虫,将廖雪峰老师的 ...