k近邻法的C++实现:kd树
1.k近邻算法的思想
给定一个训练集,对于新的输入实例,在训练集中找到与该实例最近的k个实例,这k个实例中的多数属于某个类,就把该输入实例分为这个类。
因为要找到最近的k个实例,所以计算输入实例与训练集中实例之间的距离是关键!
k近邻算法最简单的方法是线性扫描,这时要计算输入实例与每一个训练实例的距离,当训练集很大时,非常耗时,这种方法不可行,为了提高k近邻的搜索效率,常常考虑使用特殊的存储结构存储训练数据,以减少计算距离的次数,具体方法很多,这里介绍实现经典的kd树方法。
2.构造kd树
kd树是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构,kd树是二叉树。
下面举例说明:
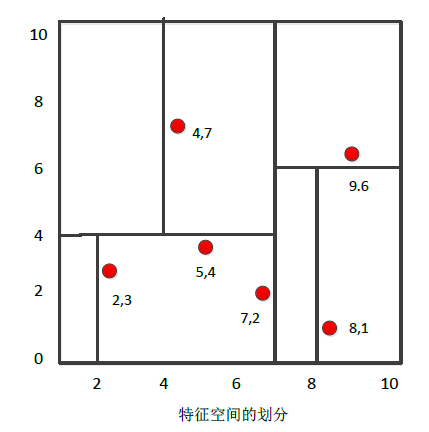
给定一个二维空间的数据集: T = {(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)},构造一个平衡kd树。
- 根结点对应包含数据集T的矩形选择x(1) 轴,6个数据点的x(1) 坐标的中位数是7,以超平面x(1) = 7将空间分为左右两个子矩形(子结点)
- 左矩形以x(2) = 4为中位数分为两个子矩形
- 右矩形以x(2) = 6 分为两个子矩形
- 如此递归,直到两个子区域没有实例存在时停止
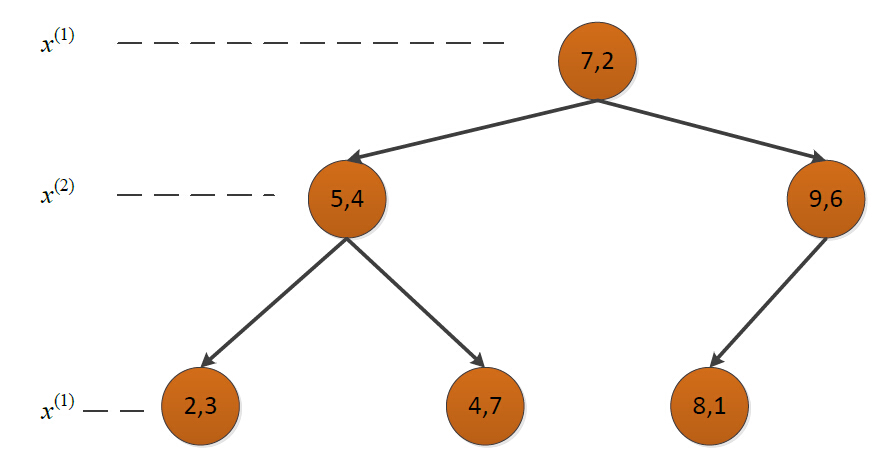
构造的kd树如下:
3.利用kd树搜索最近邻
输入:已构造的kd树;目标点x;
输出:x的最近邻
- 在kd树中找出包含目标点x的叶结点:从根结点出发,递归的向下访问kd树,若目标点x的当前维的坐标小于切分点的坐标,则移动到左子结点,否则移动到右子结点,直到子结点为叶结点为止。
- 以此叶结点为“当前最近点”
- 递归地向上回退,在每个结点进行以下操作:(a)如果该结点保存的实例点比当前最近点距离目标点更近,则以该实例点为“当前最近点”;
(b)当前最近点一定存在于某结点一个子结点对应的区域,检查该子结点的父结点的另
一子结点对应区域是否有更近的点(即检查另一子结点对应的区域是否与以目标点为球
心、以目标点与“当前最近点”间的距离为半径的球体相交);如果相交,可能在另一
个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点,接着递归进行最
近邻搜索;如果不相交,向上回退 - 当回退到根结点时,搜索结束,最后的“当前最近点”即为x的最近邻点。
4.C++实现
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
#include <cmath>
using namespace std; struct KdTree{
vector<double> root;
KdTree* parent;
KdTree* leftChild;
KdTree* rightChild;
//默认构造函数
KdTree(){parent = leftChild = rightChild = NULL;}
//判断kd树是否为空
bool isEmpty()
{
return root.empty();
}
//判断kd树是否只是一个叶子结点
bool isLeaf()
{
return (!root.empty()) &&
rightChild == NULL && leftChild == NULL;
}
//判断是否是树的根结点
bool isRoot()
{
return (!isEmpty()) && parent == NULL;
}
//判断该子kd树的根结点是否是其父kd树的左结点
bool isLeft()
{
return parent->leftChild->root == root;
}
//判断该子kd树的根结点是否是其父kd树的右结点
bool isRight()
{
return parent->rightChild->root == root;
}
}; int data[][] = {{,},{,},{,},{,},{,},{,}}; template<typename T>
vector<vector<T> > Transpose(vector<vector<T> > Matrix)
{
unsigned row = Matrix.size();
unsigned col = Matrix[].size();
vector<vector<T> > Trans(col,vector<T>(row,));
for (unsigned i = ; i < col; ++i)
{
for (unsigned j = ; j < row; ++j)
{
Trans[i][j] = Matrix[j][i];
}
}
return Trans;
} template <typename T>
T findMiddleValue(vector<T> vec)
{
sort(vec.begin(),vec.end());
auto pos = vec.size() / ;
return vec[pos];
} //构建kd树
void buildKdTree(KdTree* tree, vector<vector<double> > data, unsigned depth)
{ //样本的数量
unsigned samplesNum = data.size();
//终止条件
if (samplesNum == )
{
return;
}
if (samplesNum == )
{
tree->root = data[];
return;
}
//样本的维度
unsigned k = data[].size();
vector<vector<double> > transData = Transpose(data);
//选择切分属性
unsigned splitAttribute = depth % k;
vector<double> splitAttributeValues = transData[splitAttribute];
//选择切分值
double splitValue = findMiddleValue(splitAttributeValues);
//cout << "splitValue" << splitValue << endl; // 根据选定的切分属性和切分值,将数据集分为两个子集
vector<vector<double> > subset1;
vector<vector<double> > subset2;
for (unsigned i = ; i < samplesNum; ++i)
{
if (splitAttributeValues[i] == splitValue && tree->root.empty())
tree->root = data[i];
else
{
if (splitAttributeValues[i] < splitValue)
subset1.push_back(data[i]);
else
subset2.push_back(data[i]);
}
} //子集递归调用buildKdTree函数 tree->leftChild = new KdTree;
tree->leftChild->parent = tree;
tree->rightChild = new KdTree;
tree->rightChild->parent = tree;
buildKdTree(tree->leftChild, subset1, depth + );
buildKdTree(tree->rightChild, subset2, depth + );
} //逐层打印kd树
void printKdTree(KdTree *tree, unsigned depth)
{
for (unsigned i = ; i < depth; ++i)
cout << "\t"; for (vector<double>::size_type j = ; j < tree->root.size(); ++j)
cout << tree->root[j] << ",";
cout << endl;
if (tree->leftChild == NULL && tree->rightChild == NULL )//叶子节点
return;
else //非叶子节点
{
if (tree->leftChild != NULL)
{
for (unsigned i = ; i < depth + ; ++i)
cout << "\t";
cout << " left:";
printKdTree(tree->leftChild, depth + );
} cout << endl;
if (tree->rightChild != NULL)
{
for (unsigned i = ; i < depth + ; ++i)
cout << "\t";
cout << "right:";
printKdTree(tree->rightChild, depth + );
}
cout << endl;
}
} //计算空间中两个点的距离
double measureDistance(vector<double> point1, vector<double> point2, unsigned method)
{
if (point1.size() != point2.size())
{
cerr << "Dimensions don't match!!" ;
exit();
}
switch (method)
{
case ://欧氏距离
{
double res = ;
for (vector<double>::size_type i = ; i < point1.size(); ++i)
{
res += pow((point1[i] - point2[i]), );
}
return sqrt(res);
}
case ://曼哈顿距离
{
double res = ;
for (vector<double>::size_type i = ; i < point1.size(); ++i)
{
res += abs(point1[i] - point2[i]);
}
return res;
}
default:
{
cerr << "Invalid method!!" << endl;
return -;
}
}
}
//在kd树tree中搜索目标点goal的最近邻
//输入:目标点;已构造的kd树
//输出:目标点的最近邻
vector<double> searchNearestNeighbor(vector<double> goal, KdTree *tree)
{
/*第一步:在kd树中找出包含目标点的叶子结点:从根结点出发,
递归的向下访问kd树,若目标点的当前维的坐标小于切分点的
坐标,则移动到左子结点,否则移动到右子结点,直到子结点为
叶结点为止,以此叶子结点为“当前最近点”
*/
unsigned k = tree->root.size();//计算出数据的维数
unsigned d = ;//维度初始化为0,即从第1维开始
KdTree* currentTree = tree;
vector<double> currentNearest = currentTree->root;
while(!currentTree->isLeaf())
{
unsigned index = d % k;//计算当前维
if (currentTree->rightChild->isEmpty() || goal[index] < currentNearest[index])
{
currentTree = currentTree->leftChild;
}
else
{
currentTree = currentTree->rightChild;
}
++d;
}
currentNearest = currentTree->root; /*第二步:递归地向上回退, 在每个结点进行如下操作:
(a)如果该结点保存的实例比当前最近点距离目标点更近,则以该例点为“当前最近点”
(b)当前最近点一定存在于某结点一个子结点对应的区域,检查该子结点的父结点的另
一子结点对应区域是否有更近的点(即检查另一子结点对应的区域是否与以目标点为球
心、以目标点与“当前最近点”间的距离为半径的球体相交);如果相交,可能在另一
个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点,接着递归进行最
近邻搜索;如果不相交,向上回退*/ //当前最近邻与目标点的距离
double currentDistance = measureDistance(goal, currentNearest, ); //如果当前子kd树的根结点是其父结点的左孩子,则搜索其父结点的右孩子结点所代表
//的区域,反之亦反
KdTree* searchDistrict;
if (currentTree->isLeft())
{
if (currentTree->parent->rightChild == NULL)
searchDistrict = currentTree;
else
searchDistrict = currentTree->parent->rightChild;
}
else
{
searchDistrict = currentTree->parent->leftChild;
} //如果搜索区域对应的子kd树的根结点不是整个kd树的根结点,继续回退搜索
while (searchDistrict->parent != NULL)
{
//搜索区域与目标点的最近距离
double districtDistance = abs(goal[(d+)%k] - searchDistrict->parent->root[(d+)%k]); //如果“搜索区域与目标点的最近距离”比“当前最近邻与目标点的距离”短,表明搜索
//区域内可能存在距离目标点更近的点
if (districtDistance < currentDistance )//&& !searchDistrict->isEmpty()
{ double parentDistance = measureDistance(goal, searchDistrict->parent->root, ); if (parentDistance < currentDistance)
{
currentDistance = parentDistance;
currentTree = searchDistrict->parent;
currentNearest = currentTree->root;
}
if (!searchDistrict->isEmpty())
{
double rootDistance = measureDistance(goal, searchDistrict->root, );
if (rootDistance < currentDistance)
{
currentDistance = rootDistance;
currentTree = searchDistrict;
currentNearest = currentTree->root;
}
}
if (searchDistrict->leftChild != NULL)
{
double leftDistance = measureDistance(goal, searchDistrict->leftChild->root, );
if (leftDistance < currentDistance)
{
currentDistance = leftDistance;
currentTree = searchDistrict;
currentNearest = currentTree->root;
}
}
if (searchDistrict->rightChild != NULL)
{
double rightDistance = measureDistance(goal, searchDistrict->rightChild->root, );
if (rightDistance < currentDistance)
{
currentDistance = rightDistance;
currentTree = searchDistrict;
currentNearest = currentTree->root;
}
}
}//end if if (searchDistrict->parent->parent != NULL)
{
searchDistrict = searchDistrict->parent->isLeft()?
searchDistrict->parent->parent->rightChild:
searchDistrict->parent->parent->leftChild;
}
else
{
searchDistrict = searchDistrict->parent;
}
++d;
}//end while
return currentNearest;
} int main()
{
vector<vector<double> > train(, vector<double>(, ));
for (unsigned i = ; i < ; ++i)
for (unsigned j = ; j < ; ++j)
train[i][j] = data[i][j]; KdTree* kdTree = new KdTree;
buildKdTree(kdTree, train, ); printKdTree(kdTree, ); vector<double> goal;
goal.push_back(3);
goal.push_back(4.5);
vector<double> nearestNeighbor = searchNearestNeighbor(goal, kdTree);
vector<double>::iterator beg = nearestNeighbor.begin();
cout << "The nearest neighbor is: ";
while(beg != nearestNeighbor.end()) cout << *beg++ << ",";
cout << endl;
return ;
}
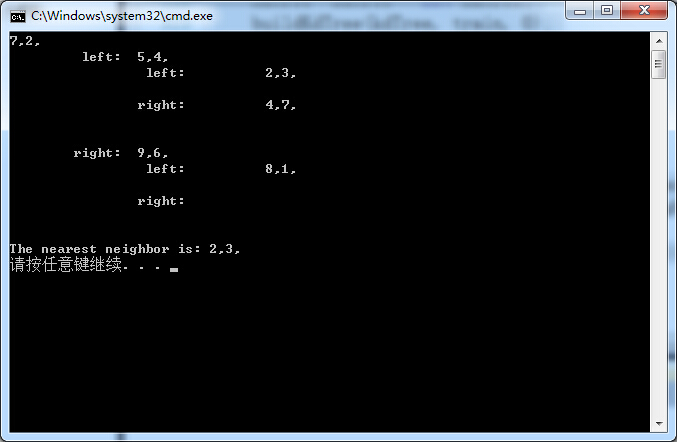
5. 运行
下面是用上面举例构造的kd树求点(3,4.5)的最近邻:
参考文献:李航《统计学习方法》,维基百科
k近邻法的C++实现:kd树的更多相关文章
- k近邻法(二)
上一篇文章讲了k近邻法,以及使用kd树构造数据结构,使得提高最近邻点搜索效率,但是这在数据点N 远大于 2^n 时可以有效的降低算法复杂度,n为数据点的维度,否则,由于需要向上回溯比较距离,使得实际效 ...
- K近邻法(KNN)原理小结
K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用.比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出 ...
- scikit-learn K近邻法类库使用小结
在K近邻法(KNN)原理小结这篇文章,我们讨论了KNN的原理和优缺点,这里我们就从实践出发,对scikit-learn 中KNN相关的类库使用做一个小结.主要关注于类库调参时的一个经验总结. 1. s ...
- 学习笔记——k近邻法
对新的输入实例,在训练数据集中找到与该实例最邻近的\(k\)个实例,这\(k\)个实例的多数属于某个类,就把该输入实例分给这个类. \(k\) 近邻法(\(k\)-nearest neighbor, ...
- 机器学习PR:k近邻法分类
k近邻法是一种基本分类与回归方法.本章只讨论k近邻分类,回归方法将在随后专题中进行. 它可以进行多类分类,分类时根据在样本集合中其k个最近邻点的类别,通过多数表决等方式进行预测,因此不具有显式的学习过 ...
- 《统计学习方法》笔记三 k近邻法
本系列笔记内容参考来源为李航<统计学习方法> k近邻是一种基本分类与回归方法,书中只讨论分类情况.输入为实例的特征向量,输出为实例的类别.k值的选择.距离度量及分类决策规则是k近邻法的三个 ...
- k近邻法(kNN)
<统计学习方法>(第二版)第3章 3 分类问题中的k近邻法 k近邻法不具有显式的学习过程. 3.1 算法(k近邻法) 根据给定的距离度量,在训练集\(T\)中找出与\(x\)最邻近的\(k ...
- 统计学习方法与Python实现(二)——k近邻法
统计学习方法与Python实现(二)——k近邻法 iwehdio的博客园:https://www.cnblogs.com/iwehdio/ 1.定义 k近邻法假设给定一个训练数据集,其中的实例类别已定 ...
- 《统计学习方法(李航)》讲义 第03章 k近邻法
k 近邻法(k-nearest neighbor,k-NN) 是一种基本分类与回归方法.本书只讨论分类问题中的k近邻法.k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类 ...
- k近邻法(一)
简介 k近邻法(k-nearest neighbors algorigthm) 是一种最基本的用于分类和回归的方法之一,当没有关于训练数据的分布时,首先最容易想到的就是采用k近邻法. k近邻法输入为实 ...
随机推荐
- 关于div居中
margin : 100px; margin-left: auto; margin-right: auto; 这样子设置css样式就可以实现一个div居中
- hdu 2897(威佐夫博奕变形)
题意:容易理解. 分析:当n%(p+q)==0时,先取者必胜,必胜方案:先取q,然后对方去x个,先取者就取(p+q-x)个,最后对方就必须取玩p个, 当n%(p+q)==r(r<=p),先取者必 ...
- Eclipse安装配置PyDev插件
Eclipse安装配置PyDev插件 关于PyDev PyDev是一个功能强大的 Eclipse插件,使用户可用 Eclipse 来进行 Python 应用程序的开发和调试.PyDev 插件的出现方便 ...
- shell语句记录-awk
cat ./daily_uv/daily_uv_20140104 | awk '{fr[$1]+=$3; k=$1 "_" $2; av[k]+=$3;} END{for (k i ...
- linux c 多线程编程
linux 下 c 语言多线程: /* 06.3.6 Mhello1.c Hello,world -- Multile Thread */ #include<stdio.h> #inclu ...
- 基于Heritrix的特定主题的网络爬虫配置与实现
建议在了解了一定网络爬虫的基本原理和Heritrix的架构知识后进行配置和扩展.相关博文:http://www.cnblogs.com/hustfly/p/3441747.html 摘要 随着网络时代 ...
- 【转】Struts2中的MethodFilterInterceptor(转)
这是一个Struts2.1.8.1应用,代码如下 首先是web.xml文件 view plaincopy to clipboardprint?01.<?xml version="1.0 ...
- Web 检测代码 web analysis 开源 open source
1. Grape Web Statistics Grape Web Statistics is a fairly simple piece of analytics software. Grape i ...
- 移动端和web端前端UI库—Frozen UI、WeUI、SUI Mobile
web http://www.pintuer.com/ 拼图 http://www.h-ui.net/ http://www.layui.com/ 很厉害的一个个人产品 http://amazeui ...
- 第三百六十天 how can I 坚持
看了两集linux视频,有点懵啊,下班还想走去天安门,想啥呢,太远了. 居住证没法办,哎,要入职两年. 考研要是也不能考,这一年也太.. 点不会那么背吧. 好像没啥了,睡觉.