7.OpenACC
OpenACC:
openacc 可以用于fortran, c 和 c++程序,可以运行在CPU或者GPU设备.
openacc的代码就是在原有的C语言基础上进行修改,通过添加:
compiler directives 编译器指令(pragmas): #pragma 来标示.
cuda 中有 __syncthreads()来进行线程同步,目前的OpenAcc还没有线程同步机制.
OpenAcc device model

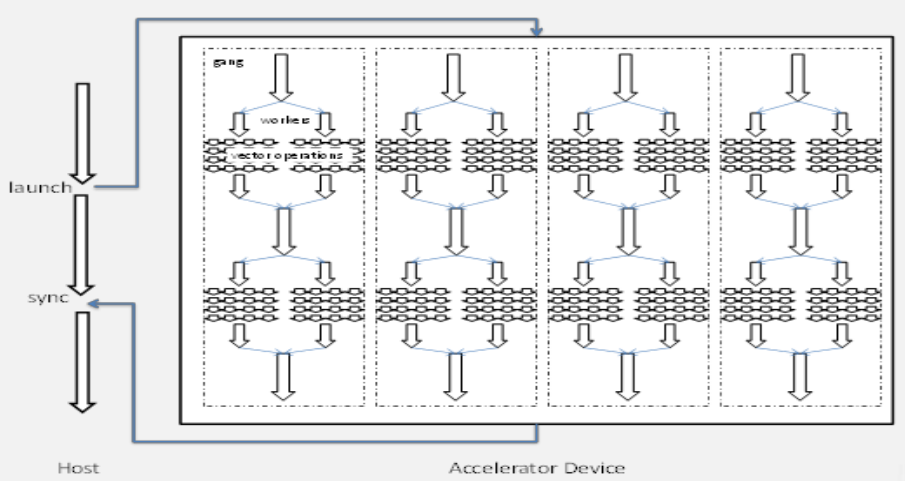
OpenAcc excute model
parallel loops
下面地一段代码和第二段代码是等效的,在OpenAcc中一个parallel区域有一个单个loop组成.
#pragma acc parallel loop copyin(M[0:Mh*Mw])
copyin(N[:Mw*Nw]) copyout(P[:Mh*Nw])
for (int i=; i<Mh; i++) {
...
} is equivalent to:
#pragma acc parallel copyin(M[0:Mh*Mw])
copyin(N[:Mw*Nw]) copyout(P[:Mh*Nw])
{
#pragma acc loop
for (int i=; i<Mh; i++) {
...
}
}
}
copyin对应拷贝内存从host到device,
copyout对应拷贝内存从device到host
gangs and workers
gangs可以类比成cuda的block,
workers可以类比成thread
#pragma acc parallel num_gangs(1024) num_workers(32)
{
#pragma acc loop gang
for (int i=; i<; i++) {
#pragma acc loop worker
for (int j=; j<; j++) {
foo(i,j);
}
}
}
这段代码会分配: 1024*32 = 32K 个thread, 这两个循环题一共是执行2048*512 = 1M, 所以每个thread执行foo()函数 1M/32K = 32 次.
再看另外一个代码:
#pragma acc parallel copyout(a) num_gangs(1024) num_workers(32)
{
a = ;
}
这段代码会分配1023*32个thread,每个gang=1024, 对于每个gang来说执行a =23 是冗余的,只需要执行一次即可.再看下面的例子:
#pragma acc parallel num_gangs(32)
{
Statement ;
#pragma acc loop gang
for (int i=; i<n; i++) {
Statement ;
}
Statement ;
#pragma acc loop gang
for (int i=; i<m; i++) {
Statement ;
}
Statement ;
if (condition) Statement ;
}
gang有32个,statement2的循环次数是n,statement4循环次数是m, 最终到底分配多少个thread取决于编译器,有可能m>n,则分配m个,当然实际情况可能更加复杂,
statement1, 3, 5,6 对于32gang来说是冗余的,情况和上面的相同,可以看出OpenAcc中的冗余是对于gang来说的,下面的这种写法可以消除这种冗余:
#pragma acc parallel num_gangs(1)
num_workers()
{
Statement ;
#pragma acc loop gang
for (int i=; i<n; i++) {
Statement ;
}
Statement ;
#pragma acc loop gang
for (int i=; i<m; i++) {
Statement ;
}
Statement ;
if (condition) Statement ;
}
kernel regions
#pragma acc kernels
{
#pragma acc loop num_gangs(1024)
for (int i=; i<; i++) {
a[i] = b[i];
}
#pragma acc loop num_gangs(512)
for (int j=; j<; j++) {
c[j] = a[j]*;
}
for (int k=; k<; k++) {
d[k] = c[k];
}
}
这段代码和前面的代码比较起来,区别是 acc kernel, 而前面的代码用的是acc parallel.
Kernel 结构主要是描述程序员的意图: 当前程序适合并行,编译器根据这个描述会有非常灵活的表现,
而parallel则是规定,规定编译器必须把下面的代码段并行操作.
7.OpenACC的更多相关文章
- PGI Compiler for OpenACC Output Syntax Highlighting
PGI Compiler for OpenACC Output Syntax Highlighting When use the PGI compiler to compile codes with ...
- OpenACC 云水参数化方案
▶ 书上第十三章,用一系列步骤优化一个云水参数化方案.用于熟悉 Fortran 以及 OpenACC 在旗下的表现 ● 代码,文件较多,放在一起了 ! main.f90 PROGRAM main US ...
- OpenACC 绘制曼德勃罗集
▶ 书上第四章,用一系列步骤优化曼德勃罗集的计算过程. ● 代码 // constants.h ; ; ; ; const double xmin=-1.7; ; const double ymin= ...
- OpenACC 梯度下降法求解线性方程的优化
▶ 书上第二章,用一系列步骤优化梯度下降法解线性方程组.才发现 PGI community 编译器不支持 Windows 下的 C++ 编译(有 pgCC 命令但是不支持 .cpp 文件,要专业版才支 ...
- OpenACC 优化矩阵乘法
▶ 按书上的步骤使用不同的导语优化矩阵乘法 ● 所有的代码 #include <iostream> #include <cstdlib> #include <chrono ...
- OpenACC 简单的原子操作
▶ OpenACC 的原子操作,用到了 C++ 的一个高精度计时器 ● 代码,直接的原子操作 #include <iostream> #include <cstdlib> #i ...
- OpenACC 与 CUDA 的相互调用
▶ 按照书上的代码完成了 OpenACC 与CUDA 的相互调用,以及 OpenACC 调用 cuBLAS.便于过程遇到了很多问题,注入 CUDA 版本,代码版本,计算能力指定等,先放在这里,以后填坑 ...
- OpenACC Julia 图形
▶ 书上的代码,逐步优化绘制 Julia 图形的代码 ● 无并行优化(手动优化了变量等) #include <stdio.h> #include <stdlib.h> #inc ...
- OpenACC 异步计算
▶ 按照书上的例子,使用 async 导语实现主机与设备端的异步计算 ● 代码,非异步的代码只要将其中的 async 以及第 29 行删除即可 #include <stdio.h> #in ...
随机推荐
- python读写配置文件
#coding:utf-8 import ConfigParser class Conf(): def __init__(self,name): self.name = name self.cp = ...
- Side by Side Assembly介绍--manifest文件的使用
什么是Side-by-Side Assembly? Side-by-Side Assembly(建称SxS)是微软在Visual Studio 2005(Windows 2000?)中引入的技术,用来 ...
- HDU4611+数学
/* 找规律 题意:abs(i%A - i%B) 对i从0~N-1求和 从0~N-1一个一个算必TLE,着A,B两者差相同的部分合并起来算 */ #include<stdio.h> #in ...
- 【疯狂Java讲义学习笔记】【数据类型与运算符】
[学习笔记]1.8bit = 1byte,4byte = 1word.Java中的整型数据有byte(1字节),short(2字节),int(4字节),long(8字节).Java中的浮点数据有flo ...
- ANDROID_MARS学习笔记_S01_010日期时间控件
1.xml <RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns: ...
- 使用intellij idea搭建MAVEN+springmvc+mybatis框架
原文:使用intellij idea搭建MAVEN+springmvc+mybatis框架 1.首先使用idea创建一个maven项目 2.接着配置pom.xml,以下为我的配置 <projec ...
- WampServer安装图解教程
WampServer中文安装教程_百度经验 http://jingyan.baidu.com/article/0bc808fc9d66f41bd485b925.html WampServer是国外知名 ...
- ZOJ1586——QS Network(最小生成树)
QS Network DescriptionIn the planet w-503 of galaxy cgb, there is a kind of intelligent creature nam ...
- Django用户认证系统(三)组与权限
Django的权限系统很简单,它可以赋予users或groups中的users以权限. Django admin后台就使用了该权限系统,不过也可以用到你自己的代码中. User对象具有两个ManyTo ...
- MSSQL复制功能实现与Oracle数据库同步
1.分别建立链接对数据库进行操作,SQLServer可以用ADO.NET,操作Oracle可以用OLEDB或者用System.Data.OracleClient(需要添加引用才能用) 这种方案的优点就 ...