C++11内存模型的粗略解释
基本解释
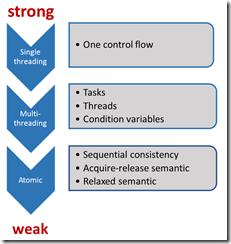
C++11引入了多线程,同时也引入了一套内存模型。从而提供了比较完善的一套多线程体系。在单线程时代,一切都很简单。没有共享数据,没有乱序执行,所有的指令的执行都是按照预定的时间线。但是也正是因为这个强的同步关系,给CPU提供的优化程度也就相对低了很多。无法体现当今多核CPU的性能。因此需要弱化这个强的同步关系,来增加CPU的性能优化。
C++11提供了6种内存模型:
enum memory_order{
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
}
原子类型的操作可以指定上述6种模型的中的一种,用来控制同步以及对执行序列的约束。从而也引起两个重要的问题:
1.哪些原子类型操作需要使用内存模型?
2.内存模型定义了那些同步语义(synchronization )和执行序列约束(ordering constraints)?
原子操作可分为3大类:
读操作:memory_order_acquire, memory_order_consume
写操作:memory_order_release
读-修改-写操作:memory_order_acq_rel, memory_order_seq_cst
未被列入分类的memory_order_relaxed没有定义任何同步语义和顺序一致性约束
执行序列约束
C++11中有3种不同类型的同步语义和执行序列约束:
1. 顺序一致性(Sequential consistency):对应的内存模型是memory_order_seq_cst
2.请求-释放(Acquire-release):对应的内存模型是memory_order_consume,memory_order_acquire,memory_order_release,memory_order_acq_rel
3.松散型(非严格约束。Relaxed):对应的内存模型是memory_order_relaxed
下面对上述3种约束做一个大概解释:
Sequential consistency:指明的是在线程间,建立一个全局的执行序列
Acquire-release:在线程间的同一个原子变量的读和写操作上建立一个执行序列
Relaxed:只保证在同一个线程内,同一个原子变量的操作的执行序列不会被重排序(reorder),这种保证也称之为modification order consistency,但是其他线程看到的这些操作的执行序列式不同的。
还有一种consume模式,也就是std::memory_order_consume。这个模式主要是引入了原子变量的数据依赖。
代码解释
Sequential consistency
Sequential consistency有两个特性:
1.所有线程执行指令的顺序都是按照源代码的顺序;
2.每个线程所能看到其他线程的操作的执行顺序都是一样的。
示例代码:
std::string work;
std::atomic<bool> ready(false); void consumer(){
while(!ready.load()){}
std::cout<< work << std::endl;
} void producer(){
work= "done";
ready=true;
}
1. work = "done" sequenced-before ready=true 推导出 work = "done" happens-before ready=true
2. while(!ready.load()){} sequenced-before std::cout<< work << std::endl 推导出 while(!ready.load()){} happens-before std::cout<< work << std::endl
3. ready = true synchronizes-with while(!ready.load()){} 推导出 ready = true inter-thread happens-before while (!ready.load()){},也就推导出ready = true happens-before while (!ready.load()){}
同时因为happens-before关系具有传递性,所以上述代码的执行序列式:
work = "done" happens-before ready = true happens-before while(!ready.load()){} happens-before std::cout<< work << std::endl
Acquire-release
关键思想是:在同一个原子变量的release操作和acquire操作间同步,同时也就建立起了执行序列约束。
所有的读和写动作不能移动到acquire操作之前。
所有的读和写动作不能移动到release操作之后。
release-acquire操作在线程间建立了一种happens-before。所以acquire之后的操作和release之前的操作就能进行同步。同时,release-acquire操作具有传递性。
示例代码:
std::vector<int> mySharedWork;
std::atomic<bool> dataProduced(false);
std::atomic<bool> dataConsumed(false); void dataProducer(){
mySharedWork={1,0,3};
dataProduced.store(true, std::memory_order_release);
} void deliveryBoy(){
while( !dataProduced.load(std::memory_order_acquire) );
dataConsumed.store(true,std::memory_order_release);
} void dataConsumer(){
while( !dataConsumed.load(std::memory_order_acquire) );
mySharedWork[1]= 2;
}
1. mySharedWork={1,0,3}; is sequenced-before dataProduced.store(true, std::memory_order_release);
2. while( !dataProduced.load(std::memory_order_acquire) ); is sequenced-before dataConsumed.store(true,std::memory_order_release);
3. while( !dataConsumed.load(std::memory_order_acquire) ); is sequenced-before mySharedWork[1]= 2;
4. dataProduced.store(true, std::memory_order_release); is synchronizes-with while( !dataProduced.load(std::memory_order_acquire) );
5. dataConsumed.store(true,std::memory_order_release); is synchronizes-with while( !dataConsumed.load(std::memory_order_acquire) );
因此dataProducer和dataConsumer能够正确同步。
原子变量的数据依赖
std::memory_order_consume说的是关于原子变量的数据依赖。
数据依赖有两种方式:
1. carries-a-dependency-to:如果操作A的结果用于操作B的操作当中,那么A carries-a-dependency-to(将依赖带入) B
2. dependency-ordered-before:如果操作B的结果进一步在相同的线程内被操作C使用,那么A的stor操作(with std::memory_order_release, std::memory_order_acq_rel or std::memory_order_seq_cst)是dependency-ordered-before(在依赖执行序列X之前)B的load操作(with std::memory_order_consume)。
示例代码:
std::atomic<std::string*> ptr;
int data;
std::atomic<int> atoData; void producer(){
std::string* p = new std::string("C++11");
data = 2011;
atoData.store(2014,std::memory_order_relaxed);
ptr.store(p, std::memory_order_release);
} void consumer(){
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_consume)));
std::cout << "*p2: " << *p2 << std::endl;
std::cout << "data: " << data << std::endl;
std::cout << "atoData: " << atoData.load(std::memory_order_relaxed) << std::endl;
}
1. ptr.store(p, std::memory_order_release) is dependency-ordered-before while (!(p2 = ptr.load(std::memory_order_consume)))。因为后面的std::cout << "*p2: " << *p2 << std::endl;将读取load操作的结果。
2. while (!(p2 = ptr.load(std::memory_order_consume)) carries-a-dependency-to std::cout << "*p2: " << *p2 << std::endl。因为*p2的输出使用了ptr.load操作的结果
综上所述,对于data和atoData的输出是没有保证的。因为它们和ptr.load操作没有carries-a-dependency-to关系。同时它们又不是原子变量,这将会导致race condition。因为在同一时间,多个线程可以访问data,线程t1(producer)同时会修改它。程序的行为因此是未定义的(undefined)。
参考:
http://en.cppreference.com/w/cpp/atomic/memory_order
http://www.modernescpp.com/
C++11内存模型的粗略解释的更多相关文章
- C++11 并发指南七(C++11 内存模型一:介绍)
第六章主要介绍了 C++11 中的原子类型及其相关的API,原子类型的大多数 API 都需要程序员提供一个 std::memory_order(可译为内存序,访存顺序) 的枚举类型值作为参数,比如:a ...
- c++11 内存模型解读
c++11 内存模型解读 关于乱序 说到内存模型,首先需要明确一个普遍存在,但却未必人人都注意到的事实:程序通常并不是总按着照源码中的顺序一一执行,此谓之乱序,乱序产生的原因可能有好几种: 编译器出于 ...
- C++11内存模型的一些补充阅读材料
<Intel Threading Building Block> O'REILLY Chapter 7 Mutual Exclusion - Atomic Operation - Memo ...
- 再说 c++11 内存模型
可见性与乱序 在说到内存模型相关的东西时,我们常常会说到两个名词:乱序与可见性,且两者经常交错着使用,容易给人错觉仿佛是两个不同的东西,其实不是这样,他们只是从不同的角度来描述一个事情,本质是相同的. ...
- [转载]《C++0x漫谈》系列之:多线程内存模型
<C++0x漫谈>系列之:多线程内存模型 By 刘未鹏(pongba) 刘言|C++的罗浮宫(http://blog.csdn.net/pongba) <C++0x漫谈>系列导 ...
- 二.GC相关之Java内存模型
根据上节描述的问题,我们知道其最终原因是GC导致的.本节我们就先详细探讨下与GC息息相关的Java内存模型. 名词解释:变量,理解为java的基本类型.对象,理解为java new出来的实例. Jav ...
- C++11并发内存模型学习
C++11标准已发布多年,编译器支持也逐渐完善,例如ms平台上从vc2008 tr1到vc2013.新标准对C++改进体现在三方面:1.语言特性(auto,右值,lambda,foreach):2.标 ...
- 11、Java并发性和多线程-Java内存模型
以下内容转自http://ifeve.com/java-memory-model-6/: Java内存模型规范了Java虚拟机与计算机内存是如何协同工作的.Java虚拟机是一个完整的计算机的一个模型, ...
- Cocos2d-x v3.11 中的新内存模型
Cocso2d-x v3.11 一项重点改进就是 JSB 新内存模型.这篇文章将专门介绍这项改进所带来的新研发体验和一些技术细节. 1. 成果 在 Cocos2d-x v3.11 之前的版本中,使用 ...
随机推荐
- 【转】Android SDK Manager 更新方法
在Android SDK Manager Setting 窗口设置HTTP Proxy server和HTTP Proxy Port这个2个参数,分别设置为: HTTP Proxy server:mi ...
- google map 点与点画线
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- PHP SQL注入的防范
说到网站安全就不得不提到SQL注入(SQL Injection),如果你用过ASP,对SQL注入一定有比较深的理解,PHP的安全性相对较高,这是因为MYSQL4以下的版本不支持子语句,而且当php.i ...
- php下删除一篇文章生成的多个静态页面
php自定义函数之删除一篇文章生成的多个静态页面,可能有多页的文章,都是需要考虑到的. 复制代码代码如下: //– 删除一篇文章生成的多个静态页面 //– 生成的文章名为 5.html 5_2.ht ...
- jsp+oracle 排序分页+Pageutil类
1.rownum和排序 Oracle中的rownum的是在取数据的时候产生的序号,所以想对指定排序的数据去指定的rowmun行数据就必须注意了. SQL> select rownum ,id,n ...
- WPF中让TextBlock每一个字符显示不同的颜色
XAML代码: <TextBlock x:Name="tb"> <Run Foreground="Red">R</Run> ...
- hdu 4622 Reincarnation SAM模板题
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4622 题意:给定一个长度不超过2000的字符串,之后有Q次区间查询(Q <= 10000),问区 ...
- 【BZOJ 2242】[SDOI2011]计算器
Description 你被要求设计一个计算器完成以下三项任务: 1.给定y,z,p,计算Y^Z Mod P 的值: 2.给定y,z,p,计算满足xy≡ Z ( mod P )的最小非负整数: 3.给 ...
- iOS应用中URL地址如何重定向-b
就用一个很简单的例子 http://www.google.com谷歌的首页 都知道现在浏览器中打开google.com的话事实上会变成http://www.google.com.hk 网址被重定向了 ...
- myeclipse2013 for linux及其破解补丁百度网盘下载
FQ下载1.1G的东西不是开玩笑的,用GA下载了两回均失败,还是用了某某门在win下下载好的,来之不易,所以特意上传分享给大家,免得FQ.破解文件也一并附上: 注意:本人这个是在原文件基础上bzip2 ...