初识Hadoop
第一部分:
初识Hadoop
一、
谁说大象不能跳舞
业务数据越来越多,用关系型数据库来存储和处理数据越来越感觉吃力,一个查询或者一个导出,要执行很长时间,这是因为数据的吞吐量太大了,导致整个程序看上去像一只体型庞大、行动笨拙的大象。
Hadoop天生就是来解决数据吞吐量太大的,它可以使大数据的存储和处理变的快速、使得应用程序运行的更加的轻盈。像《Hadoop权威指南》封皮上那句话:“谁说大象不能跳舞?!”。
二、
Hadoop解决的问题
Hadoop解决的问题就是大数据存储和运算问题。
这里要说一个宏观的问题,就是大数据产业链,来说明Hadoop在产业链中所处的位置,以便于更好的理解Hadoop是做什么的。
所谓大数据的产业链,就像于普通商品的产业链,普通商品的产业链先是原材料的搜集、原材料的预加工、深加工、
制造成各种各样的商品、最终销售变现获得利润。
大数据产业链非常类似,也可以分为三个阶段:
1、
大数据的搜集、整理阶段
2、
大数据的存储、处理阶段
3、
大数据的应用、变现阶段
Hadoop就是来解决第二步,数据存储和处理的。
拿一般公司的系统而言,数据的搜集渠道很多,也已经有了,比如订单数据、PV、UV数据等等。搜集到数据这是第一步。
第二步是如何存储和运算这些大数据,这个就是Hadoop擅长的事情了。
第三步是和具体业务相关的,是从需求的角度为出发点利用第二步中存储的大数据,来做一个应用程序。比如想做一个基于PV、UV、网友在页面上的操作路径数据,来进行分析网友行为的应用程序,来指导如何优化页面和流程,以便于更好的引导客户下单,从而实现我们的利润。
三、
Hadoop的核心和概念
像前面所说的,Hadoop是一个存储和处理大数据的解决方案,相对应地Hadoop的核心有两个:
HDFS:HDFS是分布式文件系统,提供了数据的存储方案。
MapReduce:MapReduce是一个平行运算架构,提供了数据的处理解决方案。
咱们平常说Hadoop,怎么理解所说的Hadoop,它的概念是什么?
其实Hadoop概念分狭义的和广义的:
1、
狭义的Hadoop只是Hadoop核心部分 (HDFS+MapReduce)。
2、
广义的Hadoop其实是泛指在HDFS+MapReduce核心上衍生出来的一个大的Hadoop生态系统。衍生出来的有:Hbase、Pig、Hive等等
四、
Hadoop生态系统
1、
Hadoop生态系统

对生态图的解释:
Hadoop的生态系统中,除了HDFS、MapReduce核心部分外,其他的这些灰色的,是衍生出来的项目,他们一起组成了Hadoop的生态系统。
(1) HDFS和MapReduce是Hadoop的核心,一个负责数据存储,一个负责数据处理
(2) HDFS特点是分布式存储、顺序读、只能追加
l
分布式:会将一个大文件分割后存储在不同的节点,每一个节点叫一个DataNode。
l
顺序读:在分割后的各个DataNode块上,只能从前往后读取。而且在一个具体应用中,几乎每次读取都要读取全部数据。
l
只能追加:HDFS中,数据写入只能追加到文件的末尾,不支持随机读写。
l
这样的设计看上去挺傻的、简单粗暴,但正是分布式、顺序读、只追加这些简单的规则组合起来,才是解决数据吞吐量大这个问题的方法。
l
因为HDFS不支持随机读写,所以对数据访问的实时性没法保证的。它不适合做对响应时间要求比较高的应用,Hbase可以提供实时响应的功能。
(3) MapReduce是线性的、可伸缩的编程模型,核心是两个函数:map()和reduce();
l
线性表现在:所有的数据处理都是顺序执行的,各个执行节点顺序执行map()和reduce(),这个思想和原来的结构化编程思想很像。
l
可伸缩表现在:可以在很多运算节点并行执行,而节点数量理论上是可以无限增加的。
(4) 其他都是衍生出来的项目或者叫做工具,作用是利于人们使用Hadoop,他们各有各的分工,各有各的专长
(5) Sqoop:Hadoop的数据来源往往是原有的关系型数据库,经过Hadoop的处理后,往往是把结果数据再存入关系型数据库中。Sqoop就是用来做数据导入导出的,Sqoop是关系型数据库和HDFS之间数据的传输工具。
(6) HBase是在HDFS基础上开发出来的面向列的分布式数据库。它用巧妙的方式解决了在不违反HDFS存取规则的前提下,提供随机读写、实时响应的功能。
(7) ChukWa是一个对整个Hadoop集群运行情况进行分析和反馈的工具,叫他监控不太合适,因为他有一定的延迟。他能够为Hadoop集群的使用者、Hadoop程序开发者、Hadoop集群的运维人员等人提供他们各自关心的内容。
l
使用者就是在集群上执行自己任务的人员,他们可以看到自己的任务运行状态、作业日志和作业输出结果。
l
程序开发者可以看到自己所写的程序运行情况、运行瓶颈、错误日志。
l
运维人员可以看到集群中硬件故障情况、异常状态、资源消耗情况
(8) ZooKeeper:Hadoop是分布式大的集群,在Job调度上必然变的非常复杂,ZooKeeper就是为分布式应用程序,开发的协调服务。
(9) Pig:Hadoop中数据的处理,就是通过执行很多很多map()和reduce()函数来操作,所以程序员应该写大量的map函数和reduce函数,并且要了解数据存储和数据转换的细节,是一个非常有挑战的工作。
然后雅虎开发了Pig Lation 语言,使得写程序更简单。Pig Lation程序最终还是会转换为一堆map、reduce函数来执行。
Pig项目分为两个部分:Pig Latin语言和Pig Latin的执行环境。
(10)雅虎有Pig,Facebook也有自己的解决方案,当时为了给熟悉SQL的人员提供一个好用的工具来对Hadoop中的数据来做数据分析,所以Facebook就开发了Hive。Hive的语法更像SQL。和Pig一样,Hive写的语句,最终还是要翻译为map、reduce函数来执行。
整个Hadoop生态系统中,HDFS和MapReduce是比较底层的东西,实际应用开发时,不太可能会用到,而是利用基于它们这两个核心之上的各种工具来开发。
这里就体现了开源的好处,大师级的人物设计了核心的东西,各路大牛就在核心上开发出简单好用的工具。
第二部分:
MapReduce执行机制
五、
MapReduce的组成
在MapReduce中,有两类节点控制整个程序的执行:一个jobtracker和多个tasktracker。
1、
Jobtracker是管理者,tasktracker是执行者。
2、
Jobtracker调度tasktracker上运行的任务,tasktracker会将运行状态向jobtracker报告,如果一个tasktracker失败了,jobtracker就会调度另外一个tasktracker重新运行。
3、
TaskTracker分为Map Task和Reduce
Task
六、
基本执行过程
MapReduce过程分为两个阶段:map函数阶段和reduce函数阶段
1、
map函数是数据准备阶段,并筛选掉非需要的数据,以键值对的形式输出,map函数核心目的是形成对数据的索引,以供reduce函数方便对数据进行分析。
2、
reduce函数以Map函数的输出数据为数据源,对数据进行相应的分析,输出结果为最终的目标数据。
3、
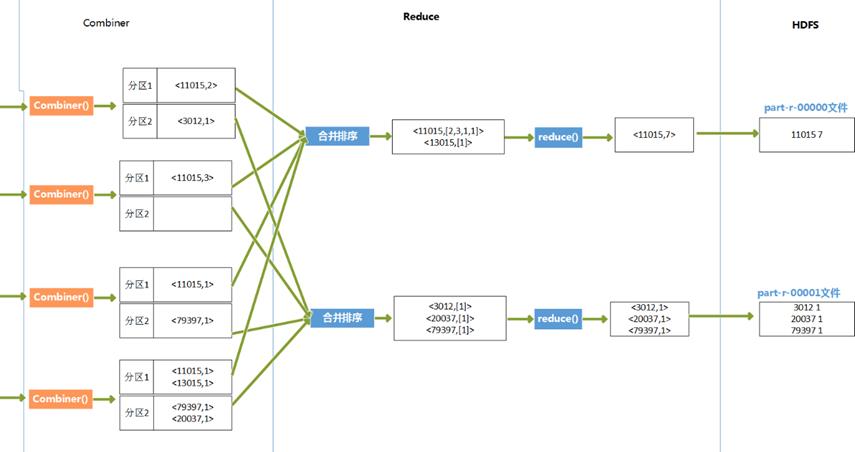
由于map任务的输出结果传递给reduce任务过程中,是在节点间的传输,是占用带宽的,这样带宽就制约了程序执行过程的最大吞吐量,为了减少map和reduce间的数据传输,在map后面添加了combiner函数来就map结果进行预处理,combiner函数是运行在map所在节点的。
七、
图解MapReduce执行过程
多个map节点和多个reduce节点
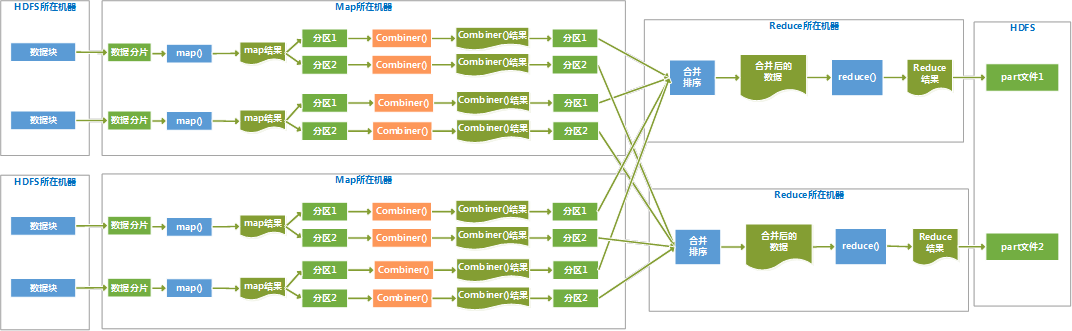
Hadoop将MapReduce输入的数据划分为等长的小分片,一般每个分片是64M,因为HDFS的每个块是64M。Hadoop 2.X中将这个数改为128M。
1、
每个分片数据分配一个map任务,任务内容是用户写的map函数,map函数是尽量运行在数据分片的机器上,这样保证了“数据本地优化”。
2、
map任务的结果是各自排好序的,各个map结果进行再次排序合并后,作为reduce任务的输入。
3、
reduce任务执行reduce函数来处理数据,得到最终结果后,存入HDFS。
4、
会有多个reduce任务,每个reduce任务的输入都来自于许多map任务,map任务和reduce任务之间是需要传输数据的,占用网络资源,影响效率,为了减少数据传输,可以在map()函数后,添加一个combiner函数来对结果做预处理。
八、
一个Java版本的MapReduce例子
1、
需求
我们有很多订单,订单有是下给经销商的,所以有dealerid信息,也有没有指定经销商的无主订单,dealerid为0。数据存储在一个文本文件中orderdata.txt,假设这个文件中大约有3亿条数据,存储在HDFS上。
文件格式如下,各个字段之间用\t分割。
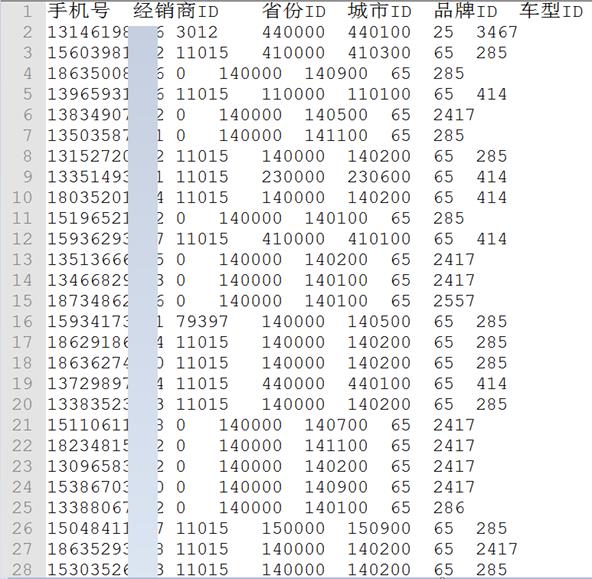
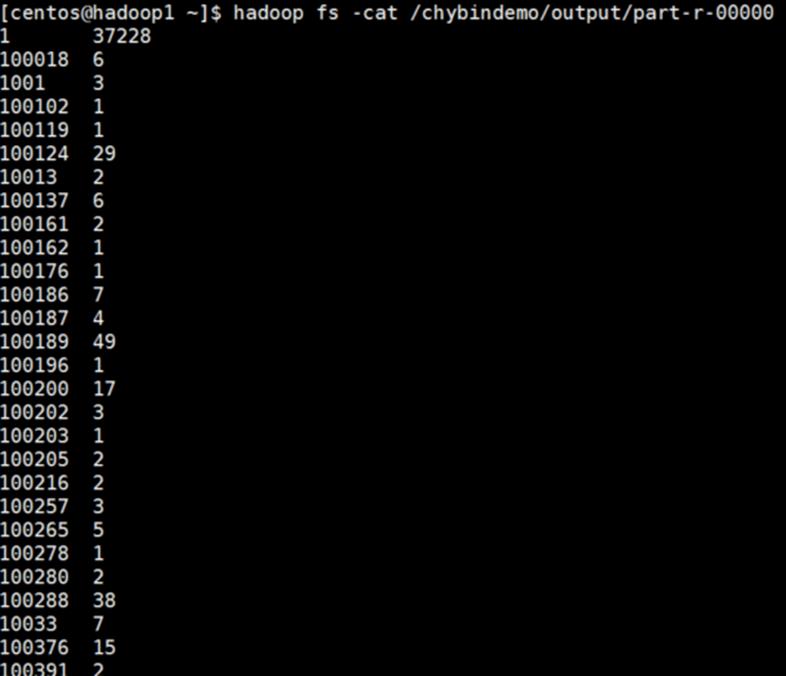
需求是:统计各个经销商下的订单数量,无主订单不统计。
输出应该类似于:

2、
代码
|
/** //设置Combiner类 job.setCombinerClass(Combiner.class); //设置Reduce方法所在类 public static class Combiner extends Reducer<Text, IntWritable, Text, } |
3、
代码执行过程推演
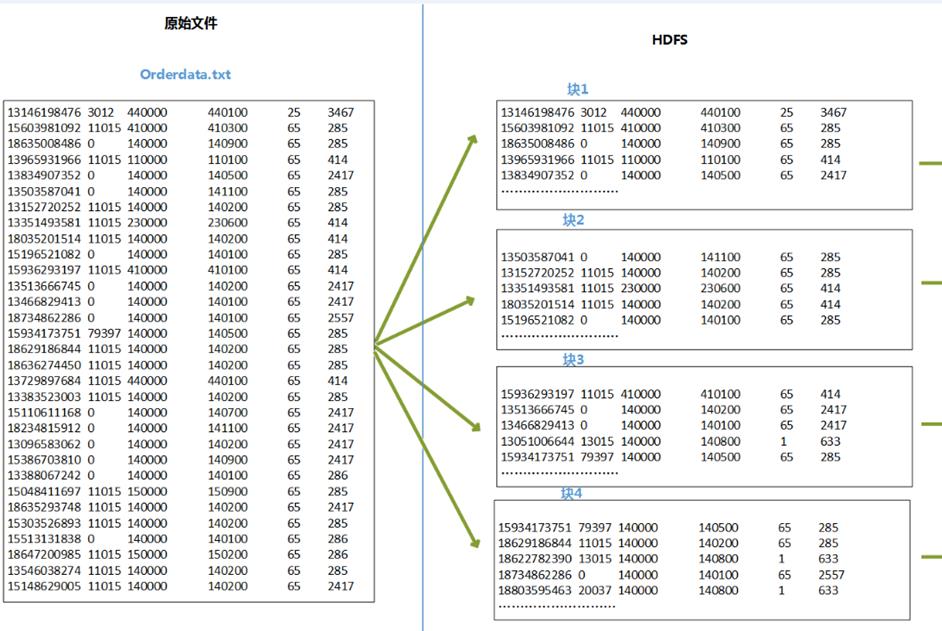
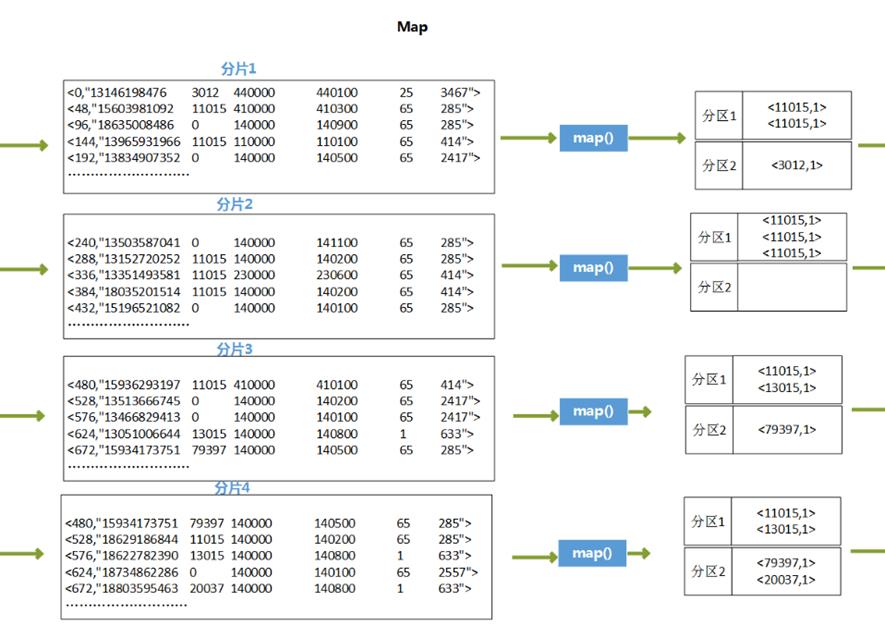
4、
在Hadoop上运行
(1) 拷贝数据源文件orderdata.txt、程序OrderDemo.jar包文件到Linux上
(2) 在HDFS上新建输入目录input
|
[centos@hadoop1 ~]$ hadoop fs -mkdir /chybindemo/input |
(3) 将orderdata.txt放入input目录中
|
[centos@hadoop1~]$ hadoop fs -put |
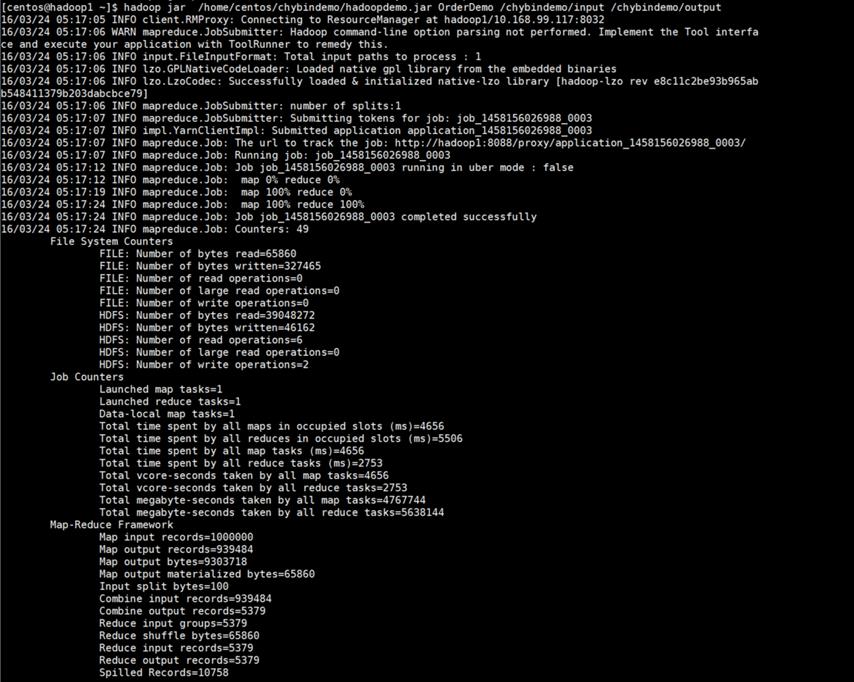
(4) 执行Hadoop,运行OrderDemo.jar程序
|
[centos@hadoop1~]$ hadoop jar 格式: hadoop jar [jar包路径] [类名] [输入路径] [输出路径] |
(5) 查看输出目录
|
[centos@hadoop1 ~]$ hadoop fs -ls -R /chybindemo/output |

(6) 查看结果文件
|
[centos@hadoop1 ~]$ hadoop fs -cat /chybindemo/output/part-r-00000 |
九、
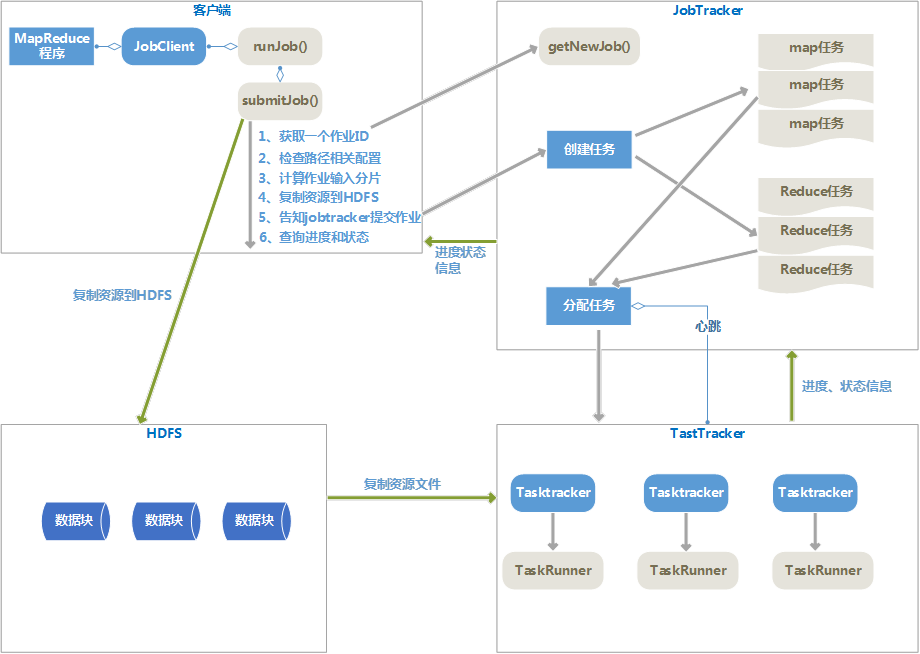
MapReduce执行流程细节(Hadoop 1.x版本下)
1、
客户端提交MapReduce作业。
客户端调用Jobclient.runJob()方法,新建JobClient实例并调用submitJob()方法,将作业提交给JobTracker,submitJob过程如下:
(1) 向jobtracker请求一个新的Job ID,是调用的getNewJob()方法。
(2) 检查作业的相关路径配置,如输入目录、输出目录是否正确。
(3) 计算作业的输入分片个数。
(4) 将运行作业所需要的资源复制到HDFS中。资源如:Jar包、配置文件等
(5) 告知jobtracker作业准备执行,调用submitJob方法提交作业。
2、
作业初始化。
jobtracker根据每个分片信息,创建一系列的map任务和一定数量的reduce任务。
3、
分配任务。
并不是Jobtracker主动给tasktracker分配任务,而是tasktrakcer来主动领任务。tasktracker通过心跳来告知jobtracker自己是否可以接受任务,jobtracker给tasktracker分配任务后,tasktracker来执行任务。
分配map任务时,jobtracker要考虑数据本地化。
分配reduce任务时,不需要考虑数据本地化。
4、
执行任务
执行任务过程包括:
(1) 复制运行用的资源文件复制到tasktracker所在的文件系统,实现作业的Jar包本地化。
(2) tasktracker为任务新建一个本地工作目录,并把jar包中内容解压到这个目录下。
(3) tasktracker新建一个taskRunner实例来运行该任务
5、
进度、状态报告
Tasktracker通过心跳来告诉jobtracker作业执行状态,jobtracker汇中整个作业的状态,客户端JobClient通过每秒查询JobTracker来查询作业进度
6、
任务完成
Jobtracker接受到最后一个任务已完成的通知后,就把作业状态设置为“成功”,jobclient查询状态时发现已经成功,就退出runJob方法。
十、
MapReduce和关系型数据库管理系统的比较
MapReduce适合一次写入,多次读取的应用场景;关系型数据库则适用于持续更新的应用场景;
MapReduce数据存储是非结构化或者半结构化得;关系型数据库则严格符合结构化的存储要求;
在数据量和数据操作时间的关系上,MapReduce是线性的,而关系型数据库非线性的。
MapReduce一个核心特征是数据本地化;关系型数据库是偏重于数据的集中存储。
第三部分:
HDFS介绍
十一、 HDFS简介
1、
HDFS全称
Hadoop
Distributed FileSystem,Hadoop分布式文件系统。
Hadoop有一个抽象文件系统的概念,Hadoop提供了一个抽象类org.apache.hadoop.fs.FilesSystem,HDFS是这个抽象类的一个实现。其他还有:
|
文件系统 |
URI方案 |
Java实现(org.apache.hadoop) |
|
Local |
file |
fs.LocalFileSystem |
|
HDFS |
hdfs |
hdfs.DistrbutedFilesSystem |
|
HFTP |
hftp |
hdfs.HftpFilesSystem |
|
HSFTP |
hsftp |
hdfs.HsftpFilesSystem |
|
HAR |
har |
fs.HarFileSystem |
|
KFS |
kfs |
fs.kfs.KosmosFilesSystem |
|
FTP |
ftp |
Fs.ftp.FtpFileSystem |
2、
HDFS特点:
(1) 超大文件数据集群
(2) 流式数据访问方式读取文件
(3) 对硬件要求并不是特别高,有很好的容错机制。
(4) 数据访问有一定的延迟,这是因为HDFS优化的是数据吞吐量,是要以提高延迟为代价的。
(5) HDFS无法高效存储大量小文件。因为NameNode限制了文件个数。
(6) HDFS不支持多个写入者,也不支持随机写。
十二、
HDFS体系结构
1、
体系结构图
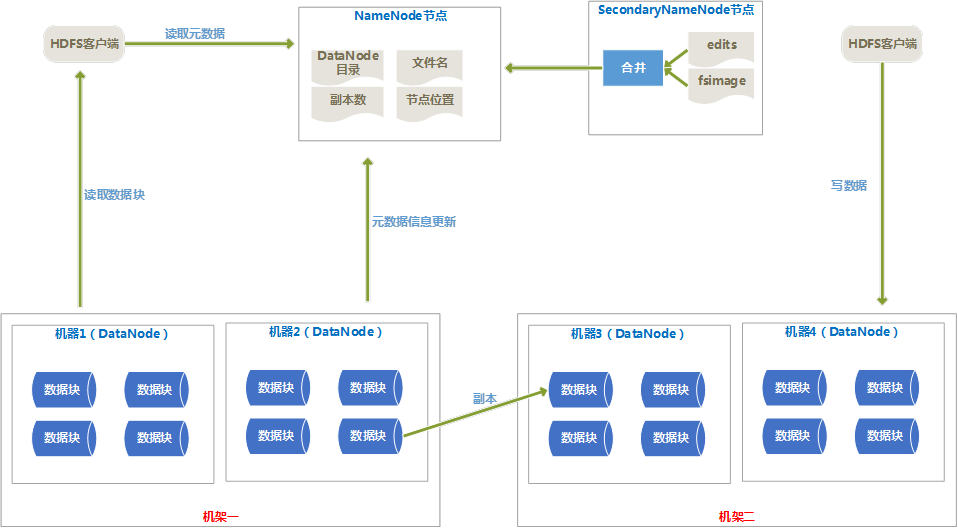
2、
体系结构介绍
(1) HDFS由Client、NameNode、DataNode、SecondaryNameNode组成。
(2) Client提供了文件系统的调用接口。
(3) NameNode由fsimage(HDFS元数据镜像文件)和editlog(HDFS文件改动日志)组成,NameNode在内存中保存着每个文件和数据块的引用关系。NameNode中的引用关系不存在硬盘中,每次都是HDFS启动时重新构造出来的。
(4) SecondaryNameNode的任务有两个:
(5) 定期合并fsimage和editlog,并传输给NameNode。
(6) 为NameNode提供热备份。
(7) 一般是一个机器上安装一个DataNode,一个DataNode上又分为很多很多数据块(block)。数据块是HDFS中最小的寻址单位,一般一个块的大小为64M,不像单机的文件系统,少于一个块大小的文件不会占用一整块的空间。
(8) 设置块比较大的原因是减少寻址开销,但是块设置的也不能过大,因为一个Map任务处理一个块的数据,如果块设置的太大,Map任务处理的数据量就会过大,会导致效率并不高。
(9) DataNode会通过心跳定时向NameNode发送所存储的文件块信息。
(10)HDFS的副本存放规则
默认的副本系数是3,一个副本存在本地机架的本机器上,第二个副本存储在本地机架的其他机器上,第三个副本存在其他机架的一个节点上。
这样减少了写操作的网络数据传输,提高了写操作的效率;另一方面,机架的错误率远比节点的错误率低,所以不影响数据的可靠性。
十三、
HDFS读写过程
1、
数据读取流程图
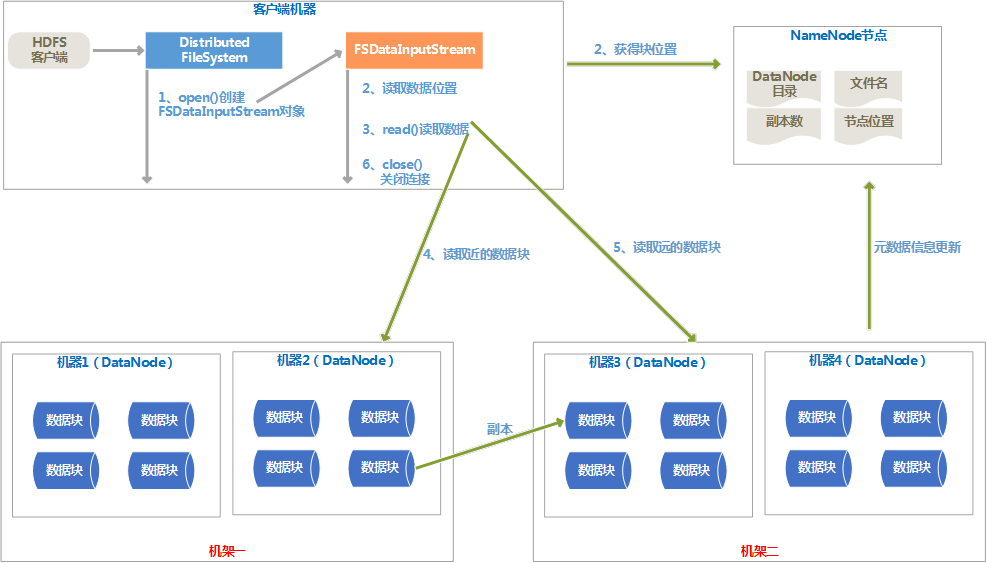
2、
读取过程说明
(1) HDFS客户端调用DistributedFileSystem类的open()方法,通过RPC协议请求NameNode来确定说请求的文件所在位置,找出最近的DataNode节点的地址。
(2) DistributedFileSystem会返回一个FSDataInputStream输入流对象给客户端。
(3) 客户端会在FSDatatInputStream上调用read()函数,按照每个DataNode的距离从近到远依次读取。
(4) 读取完每个DataNode后,在FSDataInputStream上调用close()函数。
(5) 如果读取出现故障,就会读取数据块的副本,同时向NameNode报告这个消息。
3、
文件的写入流程图
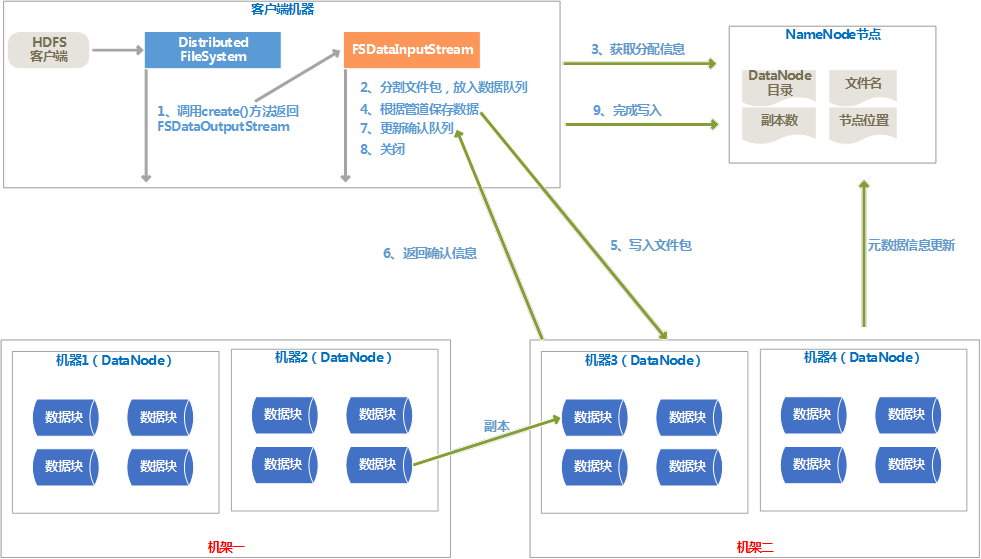
4、
写入流程说明
(1) 客户端调用DistributedFileSystem对象的create()方法,通过RPC协议调用NameNode,在命名空间创建一个新文件,此时还没有关联的DataNode与之关联。
(2) create()方法会返回一个FSDataOutputStream对象给客户端用来写入数据。
(3) 写入数据前,会将文件分割成包,放入一个“数据队列”中。
(4) NameNode为文件包分配合适的DateNode存放副本,返回一个DataNode的管道。
(5) 根据管道依次保存文件包在各个DataNode上。
(6) 各个DataNode保存好文件包后,会返回确认信息,确认消息保存在确认队列里,当管道中所有的DataNode都返回成功的的确认信息后,就会从确认队列里删除。
(7) 管道中所有的DataNode都保存完成后,调用FileSystem对象的close()关闭数据流。
十四、
HDFS的Java API
1、
使用URL读取数据
|
//用URL接口读取HDFS中文件 |
2、
FileSystem API读取数据
|
//ReadFile |
3、
FileSystem API创建目录
|
//创建HDFS目录 |
4、
FileSystem API写数据
|
//HDFS写文件 |
5、
FileSystem API删除文件
|
//删除文件 |
6、
查询元数据
|
//查询文件的元数据 |
十五、
HDFS常用命令
|
-ls -ls -lsr -lsr -du -du -dus -dus -count -mv -mv -cp -cp -rm -rm -rmr -rmr -put -put -copyFromLocal -moveFromLocal -getmerge -cat -cat -text -text -copyToLocal -moveToLocal -mkdir -setrep -touchz -stat -stat -tail -tail -chmod -chown -chgrp -help -help |
附件列表
初识Hadoop的更多相关文章
- 初识Hadoop入门介绍
初识hadoop入门介绍 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不适用我们的项目,但是我会继续研究下去,技多不压身. < ...
- 大数据测试之初识Hadoop
大数据测试之初识Hadoop POPTEST老李认为测试开发工程师是面向测试的开发,也就是说,写代码就是为完成测试任务服务的,写自动化测试(性能自动化,功能自动化,安全自动化,接口自动化等等)的cas ...
- 细细品味大数据--初识hadoop
初识hadoop 前言 之前在学校的时候一直就想学习大数据方面的技术,包括hadoop和机器学习啊什么的,但是归根结底就是因为自己太懒了,导致没有坚持多长时间,加上一直为offer做准备,所以当时重心 ...
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- [Hadoop in Action] 第2章 初识Hadoop
Hadoop的结构组成 安装Hadoop及其3种工作模式:单机.伪分布和全分布 用于监控Hadoop安装的Web工具 1.Hadoop的构造模块 (1)NameNode(名字节点) ...
- Hadoop学习笔记(1) 初识Hadoop
1. Hadoop提供了一个可靠的共享存储和分析系统.HDFS实现存储,而MapReduce实现分析处理,这两部分是Hadoop的核心. 2. MapReduce是一个批量查询处理器,并且它能够在合理 ...
- [转]《Hadoop基础教程》之初识Hadoop
原文地址:http://blessht.iteye.com/blog/2095675 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不 ...
- 初识Hadoop二,文件操作
1.使用hadoop命令查看hdfs下文件 [root@localhost hadoop-2.7.3]# hadoop fs -ls hdfs://192.168.36.134:9000/ 开始在se ...
- 初识Hadoop一,配置及启动服务
一.Hadoop简介: Hadoop是由Apache基金会所开发的分布式系统基础架构,实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS:Hadoo ...
随机推荐
- PHP赋值运算
1. 赋值运算:= ,意思是右边表达式的值赋给左边的运算数. $int1=10; $int1=$int1-6; //$int1=4 echo $int1,"<br>"; ...
- 快速搭建springmvc+spring data jpa工程
一.前言 这里简单讲述一下如何快速使用springmvc和spring data jpa搭建后台开发工程,并提供了一个简单的demo作为参考. 二.创建maven工程 http://www.cnblo ...
- 利用apply()或者rest参数来实现用数组传递函数参数
关于call()和apply()的用法,MDN文档里写的非常清晰明白,在这里就不多做记录了. https://developer.mozilla.org/zh-CN/docs/Web/JavaScri ...
- 【JS基础】循环
for 循环的语法: for (语句 1; 语句 2; 语句 3) { 被执行的代码块 } 语句 1 在循环(代码块)开始前执行 语句 2 定义运行循环(代码块)的条件 语句 3 在循环(代码块)已被 ...
- ES6之变量常量字符串数值
ECMAScript 6 是 JavaScript 语言的最新一代标准,当前标准已于 2015 年 6 月正式发布,故又称 ECMAScript 2015. ES6对数据类型进行了一些扩展 在js中使 ...
- Android—简单的仿QQ聊天界面
最近仿照QQ聊天做了一个类似界面,先看下界面组成(画面不太美凑合凑合呗,,,,):
- System进程(pid=4)占用80端口的解决方案
问题 Mail服务器在安装TFS服务(含SQLServer2016)后启动不了网页服务. 排查问题 使用命令查看端口占用情况 netstat -nao | find ":80" n ...
- Spring Security OAuth2 开发指南
官方原文:http://projects.spring.io/spring-security-oauth/docs/oauth2.html 翻译及修改补充:Alex Liao. 转载请注明来源:htt ...
- 初探java中this的用法
一般this在各类语言中都表示“调用当前函数的对象”,java中也存在这种用法: public class Leaf { int i = 0; Leaf increment(){ i++; retur ...
- DIP原则、IoC以及DI
一.DIP原则 高层模块不应该依赖于底层模块,二者都应该依赖于抽象. 抽象不应该依赖于细节,细节应该依赖于抽象. 该原则理解起来稍微有点抽象,我们可以将该原则通俗的理解为:"依赖于抽象&qu ...