CUDA C编程权威指南:2.1-CUDA编程模型
本文主要通过例子介绍了CUDA异构编程模型,需要说明的是Grid、Block和Thread都是逻辑结构,不是物理结构。实现例子代码参考文献[2],只需要把相应章节对应的CMakeLists.txt文件拷贝到CMake项目根目录下面即可运行。
1.Grid、Block和Thread间的关系
GPU中最重要的2种内存是全局内存和共享内存,前者类似于CPU系统内存,而后者类似于CPU缓存,然后GPU共享内存可由CUDA C内核直接控制。GPU简化的内存结构,如下所示:

由一个内核启动所产生的所有thread统称为一个grid,同一个grid中的所有thread共享相同的全局内存空间。一个grid由多个block构成,一个block包含一组thread,同一block内的thread通过同步、共享内存方式进行线程协作,不同block内的thread不能协作。由block和grid构成的2层的thread层次结构,如下所示:
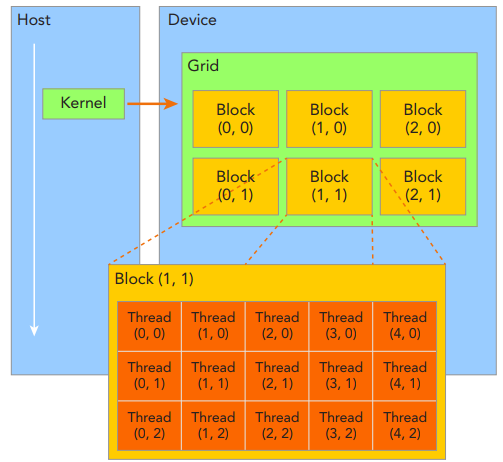
CUDA可以组织3维的grid和block。blockIdx表示线程块在线程格内的索引,threadIdx表示块内的线程索引;blockDim表示每个线程块中的线程数,gridDim表示网格中的线程块数。这些变量允许开发人员在编写CUDA代码时,从逻辑上管理和组织线程块和网格的大小,从而优化并行执行的效率。如下所示:

2.检查网格和块的索引和维度(checkDimension.cu)
确定grid和block的方法为先确定block的大小,然后根据实际数据大小和block大小的基础上计算grid维度,如下所示:
// 检查网格和块的索引和维度
# include <cuda_runtime.h>
# include <stdio.h>
__global__ void checkIndex(void) {
// gridDim表示grid的维度,blockDim表示block的维度,grid维度表示grid中block的数量,block维度表示block中thread的数量
printf("threadIdx:(%d, %d, %d) blockIdx:(%d, %d, %d) blockDim:(%d, %d, %d) "
"gridDim:(%d, %d, %d)\n", threadIdx.x, threadIdx.y, threadIdx.z,
blockIdx.x, blockIdx.y, blockIdx.z, blockDim.x, blockDim.y, blockDim.z,
gridDim.x, gridDim.y, gridDim.z); // printf函数只支持Fermi及以上版本的GPU架构,因此编译的时候需要加上-arch=sm_20编译器选项
}
int main(int argc, char** argv) {
// 定义全部数据元素
int nElem = 6;
// 定义grid和block的结构
dim3 block(3); // 表示一个block中有3个线程
dim3 grid((nElem + block.x - 1) / block.x); // 表示grid中有2个block
// 检查grid和block的维度(host端)
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
printf("block.x %d block.y %d block.z %d\n", block.x, block.y, block.z);
// 检查grid和block的维度(device端)
checkIndex<<<grid, block>>>();
// 离开之前重置设备
cudaDeviceReset();
return 0;
}
输出结果如下所示:
threadIdx:(0, 0, 0) blockIdx:(1, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(1, 0, 0) blockIdx:(1, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(2, 0, 0) blockIdx:(1, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(0, 0, 0) blockIdx:(0, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(1, 0, 0) blockIdx:(0, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(2, 0, 0) blockIdx:(0, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
grid.x 2 grid.y 1 grid.z 1
block.x 3 block.y 1 block.z 1
3.在主机上定义网格和块的大小(defineGridBlock.cu)
接下来通过一个1维网格和1维块讲解当block大小变化时,gird的size也随之变化,如下所示:
#include <cuda_runtime.h>
#include <stdio.h>
int main(int argc, char** argv) {
// 定义全部数据元素
int cElem = 1024;
// 定义grid和block结构
dim3 block(1024);
dim3 grid((cElem + block.x - 1) / block.x);
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
// 重置block
block.x = 512;
grid.x = (cElem + block.x - 1) / block.x;
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
// 重置block
block.x = 256;
grid.x = (cElem + block.x - 1) / block.x;
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
// 重置block
block.x = 128;
grid.x = (cElem + block.x - 1) / block.x;
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
// 离开前重置device
cudaDeviceReset();
return 0;
}
输出结果,如下所示:
grid.x 1 grid.y 1 grid.z 1
grid.x 2 grid.y 1 grid.z 1
grid.x 4 grid.y 1 grid.z 1
grid.x 8 grid.y 1 grid.z 1
4.基于GPU的向量加法(sumArraysOnGPU-small-case.cu)
#include <cuda_runtime.h>
#include <stdio.h>
#define CHECK(call)
//{
// const cudaError_t error = call;
// if (error != cudaSuccess)
// {
// printf("Error: %s:%d, ", __FILE__, __LINE__);
// printf("code:%d, reason: %s\n", error, cudaGetErrorString(error));
// exit(1);
// }
//}
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("Arrays do not match!\n");
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i], gpuRef[i], i);
break;
}
}
if (match) printf("Arrays match.\n\n");
}
void initialData(float *ip, int size)
{
// generate different seed for random number
time_t t;
srand((unsigned int) time(&t));
for (int i = 0; i < size; i++)
{
ip[i] = (float) (rand() & 0xFF) / 10.0f;
}
}
void sumArraysOnHost(float *A, float *B, float *C, const int N)
{
for (int idx = 0; idx < N; idx++)
{
C[idx] = A[idx] + B[idx];
}
}
__global__ void sumArraysOnGPU(float *A, float *B, float *C)
{
// int i = threadIdx.x; // 获取线程索引
int i = blockIdx.x * blockDim.x + threadIdx.x; // 获取线程索引
printf("threadIdx.x: %d, blockIdx.x: %d, blockDim.x: %d\n", threadIdx.x, blockIdx.x, blockDim.x);
C[i] = A[i] + B[i]; // 计算
}
int main(int argc, char** argv) {
printf("%s Starting...\n", argv[0]);
// 设置设备
int dev = 0;
cudaSetDevice(dev);
// 设置vectors数据大小
int nElem = 32;
printf("Vector size %d\n", nElem);
// 分配主机内存
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *hostRef, *gpuRef; // 定义主机内存指针
h_A = (float *) malloc(nBytes); // 分配主机内存
h_B = (float *) malloc(nBytes); // 分配主机内存
hostRef = (float *) malloc(nBytes); // 分配主机内存,用于存储host端计算结果
gpuRef = (float *) malloc(nBytes); // 分配主机内存,用于存储device端计算结果
// 初始化主机数据
initialData(h_A, nElem);
initialData(h_B, nElem);
memset(hostRef, 0, nBytes); // 将hostRef清零
memset(gpuRef, 0, nBytes); // 将gpuRef清零
// 分配设备全局内存
float *d_A, *d_B, *d_C; // 定义设备内存指针
cudaMalloc((float **) &d_A, nBytes); // 分配设备内存
cudaMalloc((float **) &d_B, nBytes); // 分配设备内存
cudaMalloc((float **) &d_C, nBytes); // 分配设备内存
// 从主机内存拷贝数据到设备内存
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice); // d_A表示目标地址,h_A表示源地址,nBytes表示拷贝字节数,cudaMemcpyHostToDevice表示拷贝方向
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice); // d_B表示目标地址,h_B表示源地址,nBytes表示拷贝字节数,cudaMemcpyHostToDevice表示拷贝方向
// 在host端调用kernel
dim3 block(nElem); // 定义block维度
dim3 grid(nElem / block.x); // 定义grid维度
sumArraysOnGPU<<<grid, block>>>(d_A, d_B, d_C); // 调用kernel,<<<grid, block>>>表示执行配置,d_A, d_B, d_C表示kernel参数
printf("Execution configuration <<<%d, %d>>>\n", grid.x, block.x); // 打印执行配置
// 拷贝device结果到host内存
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost); // gpuRef表示目标地址,d_C表示源地址,nBytes表示拷贝字节数,cudaMemcpyDeviceToHost表示拷贝方向
// 在host端计算结果
sumArraysOnHost(h_A, h_B, hostRef, nElem);
// 检查device结果
checkResult(hostRef, gpuRef, nElem);
// 释放设备内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// 释放主机内存
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return 0;
}
输出结果如下所示:

threadIdx.x: 0, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 1, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 2, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 3, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 4, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 5, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 6, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 7, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 8, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 9, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 10, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 11, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 12, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 13, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 14, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 15, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 16, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 17, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 18, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 19, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 20, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 21, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 22, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 23, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 24, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 25, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 26, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 27, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 28, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 29, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 30, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 31, blockIdx.x: 0, blockDim.x: 32
L:\20200706_C++\C++Program\20231003_ClionProgram\cmake-build-debug\20231003_ClionProgram.exe Starting...
Vector size 32
Execution configuration <<<1, 32>>>
Arrays match.
5.其它知识点
(1)host和device同步
核函数的调用和主机线程是异步的,即核函数调用结束后,控制权立即返回给主机端,可以调用cudaDeviceSynchronize(void)函数来强制主机端程序等待所有的核函数执行结束。当使用cudaMemcpy函数在host和device间拷贝数据时,host端隐式同步,即host端程序必须等待数据拷贝完成后才能继续执行程序。需要说明的是,所有CUDA核函数的启动都是异步的,当CUDA内核调用完成后,控制权立即返回给CPU。
(2)函数类型限定符
函数类型限定符指定一个函数在host上执行还是在device上执行,以及可被host调用还是被device调用,函数类型限定符如下所示:

说明:__device__和__host__限定符可以一起使用,这样可同时在host和device端进行编译。
参考文献:
[1]《CUDA C编程权威指南》
[2]2.1-CUDA编程模型概述:https://github.com/ai408/nlp-engineering/tree/main/20230917_NLP工程化/20231004_高性能计算/20231003_CUDA编程/20231003_CUDA_C编程权威指南/2-CUDA编程模型/2.1-CUDA编程模型概述
CUDA C编程权威指南:2.1-CUDA编程模型的更多相关文章
- 『CUDA C编程权威指南』第二章编程题选做
第一题 设置线程块中线程数为1024效果优于设置为1023,且提升明显,不过原因未知,以后章节看看能不能回答. 第二题 参考文件sumArraysOnGPUtimer.cu,设置block=256,新 ...
- 读《Android编程权威指南》
因为去年双十二购买了一折的<Android 编程权威指南(第一版)>,在第二版出来后图灵社区给我推送了第二版的优惠码,激动之余就立马下单购买电子书,不得不说Big Nerd Ranch G ...
- 《Android编程权威指南》
<Android编程权威指南> 基本信息 原书名:Android programming: the big nerd ranch guide 原出版社: Big Nerd Ranch Gu ...
- Swift编程权威指南第2版 读后收获
自从参加工作一直在用OC做iOS开发.在2015年的时候苹果刚推出swift1.0不久,当时毕竟是新推出的语言,大家也都很有激情的学习.不过在学完后发现很难在实际项目中使用,再加上当时公司项目都是基于 ...
- 《Android编程权威指南》PhotoGallery应用梳理
PhotoGalley是<Android编程权威指南>书中另外一个重要的应用.
- 《Android编程权威指南》CriminalIntent项目梳理
相信很多新手或者初级开发人员都已经买了第2版的<Android编程权威指南>, 这本书基于Android Studio开发,对入门人员来说是很好的选择,但是很可惜的是, 在完成一个项目后, ...
- 使用最新AndroidStudio编写Android编程权威指南(第3版)中的代码会遇到的一些问题
Android编程权威指南(第3版)这本书是基于Android7.0的,到如今已经过于古老,最新的Android版本已经到10,而这本书的第四版目前还没有正式发售,在最近阅读这本书时,我发现这本书的部 ...
- Android编程权威指南第三版 第32章
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/qq_35564145/article/de ...
- Android编程权威指南(第2版)--第16章 使用intent拍照 挑战练习
16.7挑战练习:优化照片显示 新建dialog_photo.xml 1234567891011121314 <?xml version="1.0" encoding=&qu ...
- 《Cortex-M0权威指南》之Cortex-M0编程入门
转载请注明来源:cuixiaolei的技术博客 嵌入式系统编程入门 微控制器是如何启动的 为了保存编译号的二进制程序代码,大多数的现代微控制器都会包含片上flash存储器.有些微控制器还可能有一个独立 ...
随机推荐
- Kali Linux的目录结构
Linux目录和Windows目录有着很大的不同,Linux目录类似一个树,最顶层是其根目录,如下图: kali Linux 目录结构 bin目录 存放二进制可执行文件(如我们常用的 ls ping ...
- win10搜索框的热门搜索怎么关闭?
搜索cmd,以管理员模式运行,输入下列命令,重启生效 reg add HKCU\Software\Policies\Microsoft\Windows\explorer /v DisableSearc ...
- 【C#/.NET】MAUI上的依赖注入
引言 在移动应用开发中,依赖注入是一项非常重要的技术,它可以帮助我们简化代码结构.提高可维护性并增加测试覆盖率.在最新的.NET跨平台框架MAUI中,我们也可以利用依赖注入来构建高效的应用程序架构 ...
- PostgreSQL 12 文档: 部分 I. 教程
部分 I. 教程 欢迎来到PostgreSQL教程.下面的几章将为那些新接触PostgreSQL.关系数据库概念和 SQL 语言的读者给出一个简单介绍.我们只假定读者拥有关于如何使用计算机的一般知识. ...
- 性能优化之window.onload
前言 最近在做一些性能优化相关的工作,相信大家在工作过程中也会遇到一些性能优化相关的场景,这对于前端开发者来讲是一项加分技能.为了我们的用户在使用我们的产品时能够有一个非常好的体验,我们需要对页面进行 ...
- ArcMap镶嵌数据集的创建、数据导入与数据范围修改方法
本文介绍基于ArcMap软件,建立镶嵌数据集(Mosaic Datasets).导入栅格图像数据,并调整像元数值范围的方法. 镶嵌数据集(Mosaic Datasets)是一种用以管理.显示. ...
- python笔记:第二章基本数据类型
基本数据类型 Python中的数据类型可以分为五大类:字符串.数字.容器.布尔.None 1.字符串 可以使用单引号或双引号创建字符串,可以用加号将两个字符串合并 name = '小明' age = ...
- LeetCode 周赛上分之旅 #35 两题坐牢,菜鸡现出原形
️ 本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 和 [BaguTree Pro] 知识星球提问. 学习数据结构与算法的关键在于掌握问题背后的算法思维框架,你的思 ...
- Ubuntu18.04 软件源更新:图形界面
通过图形UI界面更新Ubuntu的软件源,手动修改虽然简单,但是要自己去找源,选一个系统配置好的更简单.但是新版的好像没有该功能,找到个奇葩的路径: 将Ubuntu16.04升级为Ubuntu18.0 ...
- Qt+GDAL开发笔记(一):在windows系统mingw32编译GDAL库、搭建开发环境和基础Demo
前言 麒麟系统上做全球北斗定位终端开发,调试工具要做一个windows版本方便校对,北斗GPS发过来的是大地坐标,应用需要的是经纬度坐标,所以需要转换,可以使用公式转换,但是之前涉及到了另一个sh ...