并查集(union-find)算法
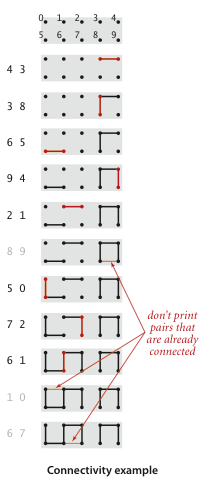
动态连通性
 、
、
假设程序读入一个整数对p q,如果所有已知的所有整数对都不能说明p和q是相连的,那么将这一整数对写到输出中,如果已知的数据可以说明p和q是相连的,那么程序忽略p q继续读入下一整数对.
为了实现这个效果,我们设计并查集这种数据结构来保存程序已知的所有整数对的足够多的信息,并用它们来判断一对新对象是否连通,这个问题通俗地叫做动态连通性问题.
union-find算法的api

为了方便,我们把每个对象称为触点,使用一个触点为索引的数组id[]作为基本的数据结构来表示所有分量,对于每个触点i,用find()方法来判定它分量所需的信息是否保存在id[i]中,connected()方法实现只用了一条语句 find(p) == find(q),它返回一个布尔值.
算法实现
public class UF {
private int[] id; //分量id
private int count; //连通分量数目
public UF(int N){
id = new int[N];
count = N;
//初始化分量id数组
for(int i = 0; i < N; i++){
id[i] = i;
}
}
//连通分量个数
public int count(){
return count;
}
//是否连通
public boolean connected(int p, int q){
return find(p) == find(q);
}
//在p q之间添加一条链接
public void union(int p, int q){
}
//分量标识符
public int find(int p){
}
public static void main(String[] args) {
// TODO Auto-generated method stub
int N = StdIn.readInt();
UF uf = new UF(N);
while(!StdIn.isEmpty()){
int p = StdIn.readInt();
int q = StdIn.readInt();
if(uf.connected(p, q)){
continue;
}
uf.union(p, q);
StdOut.println(p + " " + q);
}
StdOut.println(uf.count()+"components");
}
}
quick-find算法
这种实现方法保证当且仅当 id[p] = id[q] p和q是连通的.即同一连通分量的所有触点id[]中的值全部相同,这意味着connected()只需判断id[p]和id[q]的值是否相等即可.
调用union()将p和q归并到相同的分量中,如果 id[p] == id[q],则不需要进行任何改变,否则遍历整个数组id,将所有和id[p] 相等的元素变成id[q],当然也可以将所有和id[q]相等的元素变成id[p]——两者皆可.

//在p q之间添加一条链接
public void union(int p, int q){
//p q已经连通,直接返回
if(find(p) == find(q))
return ;
//遍历数组,找出和id[p]相等的元素置换成id[q]
for(int i = 0; i < id.length; i++){
if(id[i]==find(p)){
id[i] = find(q);
}
}
count--;
} //分量标识符
public int find(int p){
return id[p];
}
find()操作很快,因为它只需要访问数组一次,但quick-find算法一般无法处理大型问题,因为对于每一次输入union()都要扫描整个id[]数组.quick-find算法的运行时间对于最终只能得到少数连通分量的一般应用是平方级的.
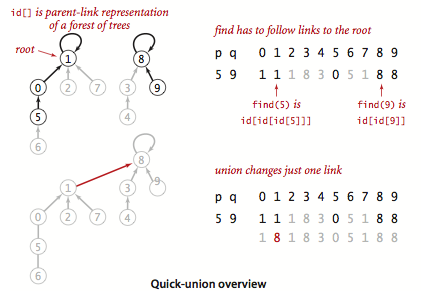
quick-union算法
这个算法提高了union()的速度,它和quick-find算法是互补的.
它也基于相同的数据结构——以触点作为索引的id[]数组,确切地说,每个id[]元素都是同一个分量中另一个触点的名字(也可能是自己),由它链接到另一个触点,再由这个触点链接到第三个触点,如此继续直到到达一个根触点,即链接指向自己的触点.
union(p,q)实现很简单,由p,q分别找到它们的根触点,然后将一个根触点链接到另一个.和上面一样,无论是重命名含有p的分量还是重命名含有q的分量都可以.
public int find(int p){
//找出分量名称
while(p!=id[p]){
p = id[p];
}
return p;
}
public void union(int p, int q){
//将p和q的根节点统一
int pRoot,qRoot;
pRoot = find(p);
qRoot = find(p);
if(pRoot==qRoot){
return ;
}
id[pRoot] = qRoot;
count--;
}
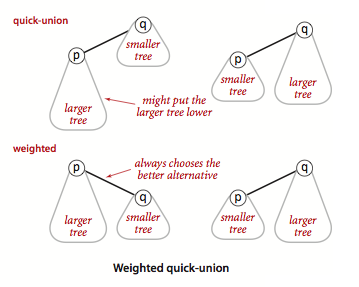
加权quick-union算法
与其在union()中随意将一棵树连接到另一棵树,我们现在记录下每一棵树的大小并总是将较小的树连接到较大的树上.这项改动需要添加一个数组和一些代码来记录树中的节点数,它能够大大改进算法的效率,我们称它为加权quick-union算法.
public class WeightQuickUnionUF {
private int[] id; //父链接数组
private int[] sz; //(由触点索引的)各个根节点所对应分量的大小.
private int count; //连通分量数目
public WeightQuickUnionUF(int N){
id = new int[N];
count = N;
//初始化id父链接数组
for(int i = 0; i < N; i++){
id[i] = i;
}
//初始化分量大小数组
for(int i = 0; i < N; i++){
sz[i] = 1;
}
}
//连通分量个数
public int count(){
return count;
}
//是否连通
public boolean connected(int p, int q){
return find(p) == find(q);
}
public int find(int p){
//找出分量名称
while(p!=id[p]){
p = id[p];
}
return p;
}
public void union(int p, int q){
//将p和q的根节点统一
int pRoot,qRoot;
pRoot = find(p);
qRoot = find(p);
if(pRoot==qRoot){
return ;
}
if(sz[pRoot]<sz[qRoot]){
id[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
}else{
id[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
count--;
}
}
加权quick-union算法最坏情况是将要被归并的树的大小总是相等的(且总是2的幂),这些树的结构看起来很复杂,但它们都含有2的n次方个节点,因此高度都正好是n.另外,当我们归并两个含有2的n次方个节点的树时,得到的树含有2的n+1次方个节点,此时树的高度增加到了n+1,由此推广我们可以证明quick-union算法能够保证对数级别的性能.
加权qucik-union算法是三种算法中唯一可以用于解决大型问题的算法,它在处理N个触点和M条连接时最多访问数组cMlgN次,这个结果和quick-find(以及某些情况下的quick-union算法)需要访问数组至少MN次形成了鲜明的对比.
最优算法
理想情况下,我们希望每个节点都直接链接到它的根节点上,但我们又不希望像union-find算法那样通过修改大量链接做到这一点,这时可以通过检查节点的同时把它直接链接到根节点上面去.
要实现路径压缩,只需要为find()添加一个循环,将在路径上遇到的节点全部链接到根节点.
路径压缩的加权quick-union算法是最优的算法,但并非所有操作都能在常数时间内完成.
public int find(int p){
int root = p;
//找出根节点
while(root!=id[root]){
root = id[root];
}
while(p!=root){
int x = p;
id[x] = root;
p = id[p];
}
return root;
}
各种union-find算法的性能特点

并查集(union-find)算法的更多相关文章
- 并查集(Union/Find)模板及详解
概念: 并查集是一种非常精巧而实用的数据结构,它主要用于处理一些不相交集合的合并问题.一些常见的用途有求连通子图.求最小生成树的Kruskal 算法和求最近公共祖先等. 操作: 并查集的基本操作有两个 ...
- 最小生成数(并查集)Kruskal算法
并查集:使用并查集可以把每个连通分量看作一个集合,该集合包含连通分量的所有点.这两两连通而具体的连通方式无关紧要,就好比集合中的元素没有先后顺序之分,只有属于和不属于的区别.#define N 100 ...
- 并查集实现Tarjan算法
本文是对http://noalgo.info/476.html的一点理解,特别是对其中 int father[mx]: //节点的父亲 int ancestor[mx]; //已访问节点集合的祖先 这 ...
- 普林斯顿算法(1.3)并查集(union-find算法)——本质就是一个数 下面的子树代表了连在一起的点
转自:https://libhappy.com/2016/03/algs-1.3/ 假设在互联网中有两台计算机需要互相通信,那么该怎么确定它们之间是否已经连接起来还是需要架设新的线路连接这两台计算机. ...
- POJ 1611 The Suspects 并查集 Union Find
本题也是个标准的并查集题解. 操作完并查集之后,就是要找和0节点在同一个集合的元素有多少. 注意这个操作,须要先找到0的父母节点.然后查找有多少个节点的额父母节点和0的父母节点同样. 这个时候须要对每 ...
- Union-Find(并查集): Quick find算法
解决dynamic connectivity的一种算法:Quick find Quick find--Data sturcture 如果两个objects是相连的,则它们有相同的array value ...
- 九度OJ 1024 畅通工程 -- 并查集、贪心算法(最小生成树)
题目地址:http://ac.jobdu.com/problem.php?pid=1024 题目描述: 省政府"畅通工程"的目标是使全省任何两个村庄间都可以实现公路交通(但 ...
- HDU ACM 2586 How far away ?LCA->并查集+Tarjan(离线)算法
题意:一个村子有n个房子,他们用n-1条路连接起来,每两个房子之间的距离为w.有m次询问,每次询问房子a,b之间的距离是多少. 分析:近期公共祖先问题,建一棵树,求出每一点i到树根的距离d[i],每次 ...
- Java 并查集Union Find
对于一组数据,主要支持两种动作: union isConnected public interface UF { int getSize(); boolean isConnected(int p,in ...
- hdu5441 并查集+克鲁斯卡尔算法
这题计算 一张图上 能走的 点对有多少个 对于每个限制边权 , 对每条边排序,对每个查询排序 然后边做克鲁斯卡尔算法 的时候变计算就好了 #include <iostream> #inc ...
随机推荐
- iOS字体
- 一步步搭建react-native环境(苹果OS X)
因重新升级了系统,一步步搭建react-native环境. 1.安装Homebrew 打开终端命令->ruby -e "$(curl -fsSL https://raw.githubu ...
- SQL2008使用json.net实现XML与JSON互转
借助CLR,首先实现字符串的互转,然后使用存储过程实现JSON2table public class JsonFunction { /// <summary> ...
- 学习linux之用mail命令发邮件
背景 这两天工作比较闲,网上各种冲浪(这个词暴露我的网龄了).看到一位大神的文章更闲 <>.端详一番,原来是用R语言拼接字符串后用shell命令发出去.发现shell命令既然还能直接发邮件 ...
- python编码问题
SCII编码是1个字节,而Unicode编码(汉字)通常是2个字节.一个字节8位(bit) 如果统一成Unicode编码,英文字母就会占用2个字节,造成空间浪费.从而出现了utf8可变编码,utf8编 ...
- 15天玩转redis —— 第十一篇 让你彻底了解RDB存储结构
接着上一篇说,这里我们来继续分析一下RDB文件存储结构,首先大家都知道RDB文件是在redis的“快照”的模式下才会产生,那么如果 我们理解了RDB文件的结构,是不是让我们对“快照”模式能做到一个心中 ...
- EF如何操作内存中的数据以及加载相关联表的数据:延迟加载、贪婪加载、显示加载
之前的EF Code First系列讲了那么多如何配置实体和数据库表的关系,显然配置只是辅助,使用EF操作数据库才是每天开发中都需要用的,这个系列讲讲如何使用EF操作数据库.老版本的EF主要是通过Ob ...
- eAccelerator、memcached、xcache、APC 等四个加速扩展的区别
折腾VPS的朋友,在安装好LNMP等Web运行环境后都会选择一些缓存扩展安装以提高PHP运行速度,常被人介绍的有eAccelerator.memcached.xcache.Alternative PH ...
- 【mysql】关于悲观锁
关于mysql中的锁 在并发环境下,有可能会出现脏读(Dirty Read).不可重复读(Unrepeatable Read). 幻读(Phantom Read).更新丢失(Lost update)等 ...
- Asp.Net MVC+BootStrap+EF6.0实现简单的用户角色权限管理2
首先我们来写个类进行获取当前线程内唯一的DbContext using System; using System.Collections.Generic; using System.Data.Enti ...