图像检索在高德地图POI数据生产中的应用
简介: 高德通过自有海量的图像源,来保证现实世界的每一个新增的POI及时制作成数据。在较短时间间隔内(小于月度),同一个地方的POI 的变化量是很低的。

作者 | 灵笼、怀迩
来源 | 阿里技术公众号
一 背景
POI 是 Point of Interest 的缩写。在电子地图上,POI 代表餐厅、超市、政府机关、旅游景点、交通设施等等 。POI是电子地图的核心数据。对普通用户而言,POI 数据包含的名称和位置信息,能够满足其使用电子地图“查找目的地”,进而唤起导航服务的基本需求;对电子地图而言,通过提供“搜索附近”、“点评”等操作,可提高用户的活跃时长。另外,POI数据是线上线下连接互动的一个纽带,是基于位置服务(Location Based Service)产业的一个重要组件。
高德通过自有海量的图像源,来保证现实世界的每一个新增的POI及时制作成数据。在较短时间间隔内(小于月度),同一个地方的POI 的变化量是很低的,如下图所示,只有“汤火功夫”POI是一个新增的挂牌。

图1. 同一地方上不同时间的POI牌匾对比
如果对全部POI进行处理的话,则会带来高昂的作业成本,因此需要对其中没有变化的POI进行自动化过滤,其中关键技术能力就是图像匹配,该场景是一个较为典型的图像检索任务。
1 技术定义
图像检索问题定义:给定查询图像(Query),通过分析视觉内容,在大型图像库中(Gallery)中搜索出相似的图像。该方向一直是计算机视觉领域的一个长期研究课题,在行人重识别、人脸识别、视觉定位等任务中均有广泛的研究。图像检索的核心技术是度量学习,其目标是在固定维度的特征空间中,约束模型将同类别样本拉近,不同类别样本推远。在深度学习时代,主要有几种经典的结构,包括:对比损失(contractive loss)、三元组损失(triplet loss)、中心损失(center loss)等,均是通过正负样本定义以及损失函数设计上进行优化。此外,图像检索还有一个必不可少的要素就是特征提取,通常包括:全局特征、局部特征、辅助特征等,主要是针对不同任务特点进行相应的优化,例如:行人重识别以及人脸识别具有很强的刚性约束,并且具备明显的关键特征(行人/人脸关键点),因此会将人体分割或关键点检测信息融合到模型特征提取中。
2 问题特点
POI牌匾的图像检索和学术上主流检索任务(如行人重识别)有着较大的区别,主要包括以下几点:异源数据、遮挡严重以及文本依赖性。
异源数据
行人重识别任务也存在异源数据问题,但是该任务的异源更多是不同相机拍摄以及不同场景的区别。而在POI牌匾检索场景中,存在更严重的异源数据问题,如下图所示:

图2. 不同拍摄条件下的异源图像
左图来自低质量相机,并且是前向拍摄;右图来自高质量相机,并且是侧向拍摄;因为相机拍摄质量以及拍摄视角不同,这就导致POI牌匾的亮度、形状、清晰度等都存在非常大的差异。而如何在差异较大的异源数据中实现POI牌匾检索,是一个非常具有挑战性的问题。
遮挡严重
在道路场景中,经常存在树木以及车辆等干扰信息,并且由于拍摄视角原因,拍摄到的POI牌匾经常会面临严重的遮挡问题,如下图所示:

图3. 遮挡严重的POI牌匾示例
而且该遮挡场景还是不规则的,导致很难对两个牌匾进行较好地特征对齐,这给POI牌匾检索带来巨大的挑战。
文本依赖性
POI牌匾还有一个独有特性就是对文本强依赖,主要是对POI名称文本的依赖。在下图场景中,两个牌匾的整体布局以及颜色都非常相似,但是其中POI名称发生了变化。而在该场景下,我们希望两个牌匾不要匹配,这就需要引入文本特征来增强特征区分性。不过,由于遮挡原因也会导致文本特征不同,因此需要结合图像特征进行权衡。而且,文本特征和图像特征来自多个模态,如何将多模信息进行融合也是该业务特有的技术难点。

图4. 仅文本变化的POI牌匾示例
二 技术方案
牌匾检索的技术方案主要包括数据迭代和模型优化两块。在数据生成部分,我们分为了冷启动自动生成数据以及模型迭代生成数据两个步骤。在模型优化部分,我们设计了一个多模态检索模型,包括视觉分支和文本分支两部分,主要是考虑到牌匾的文本信息比较丰富,因此将视觉信息与文本信息进行融合。针对视觉信息特征的提取,我们进一步设计了全局特征分支与局部特征分支,并分别进行了优化。整体技术框架如下图所示:

图5. 整体技术方案
首先利用传统匹配算法Sift自动生成模型所需的训练数据,完成模型的冷启动;并且在模型上线后,对线上人工作业结果进行自动挖掘,并组织成训练数据,以迭代模型优化。多模态检索模型是基于三元组损失(Triplet Los)的度量学习框架下进行设计的,输入包括了:1)POI牌匾的图像信息;2)POI牌匾的文本信息。图像信息使用双分支进行特征提取,文本信息使用BERT进行特征提取,最后再将文本特征与视觉特征进行融合。
1 数据
为训练检索模型,通常需要进行实例级标注,即按照POI牌匾粒度进行标注。而在不同资料中筛选同一POI牌匾是一件非常复杂的工作,如果进行人工标注的话,则会带来高昂的标注成本,并且无法大规模标注。因此,我们设计了一套简单高效的训练数据自动生成方式,可用于模型冷启动,整个环节无需任何人工标注。
我们借鉴了传统特征点匹配算法思想,利用Sift特征点匹配算法对两趟资料中的所有牌匾进行两两匹配,并通过内点数量对匹配结果进行筛选,即内点数量大于阈值的匹配牌匾视作同一牌匾。通常来说,传统特征点匹配算法会存在泛化性不足问题,由此生成的训练数据很可能导致模型无法很好学习,具体体现在:1)训练样本较为简单;2)类别冲突,即同一牌匾分为多个类别;3)类别错误,即不同牌匾分为同一类别。因此,我们针对该问题进行了相应优化:1)采用多趟资料匹配结果,提升同一类别下牌匾的多样性;2)采用Batch采样策略以及MDR loss[2]来降低模型对错误标签数据的敏感性。
具体来说,对于样本多样性问题,我们使用了多趟资料的匹配结果来生成训练数据,因为在不同资料中同一牌匾存在多张来自不同视角的拍摄结果,这就保证了同一类别下牌匾的多样性,避免了自动生成的样本都为简单样本问题。Batch采样策略即按类别进行采样,而数据中类别总数远远大于batch size,因此可以缓解类别冲突的问题。MDR loss是在Triplet loss基础上设计了根据不同距离区间进行正则化约束的新的度量学习框架,从而减少模型对对噪声样本的过拟合。

图6. MDR loss示意图,和Triplet loss相比增加了距离正则约束
图6 是Triplet loss和MDR loss的对比示意图。MDR loss希望正样本和anchor之间的距离不被拉到无限近,同时负样本也不希望被推到无限远。以类别错误噪声样本来说,不同牌匾被误分为同一类别,按照Triplet loss的优化目标则会强制模型将两者距离学习到无限近,这样的话,模型会过拟合到噪声样本上,从而导致最终效果较差。
2 模型
为了优化牌匾检索效果,我们融合了牌匾中的视觉信息与文本信息,设计了多模态检索模型。针对视觉信息,我们优化了模型全局特征和局部特征的提取能力。针对文本信息,我们使用BERT对牌匾的OCR结果进行编码,将其作为辅助特征,并与视觉特征融合后进行度量学习。
全局特征
通常对于检索任务来说,使用深度学习模型提取到的全局特征更为鲁棒,可以适应牌匾视角、颜色、光照变化等不同场景。为了进一步提升全局特征的鲁棒性,我们主要从以下两方面进行了优化:1)采用Attention机制,加强对重要特征的关注;2)网络backbone的改进,以关注到更多细粒度特征。
在我们的业务场景中,存在一些外观相似而细节有一定差异的牌匾,如图8 (c) 所示,在这种情况下,我们希望模型可以关注到牌匾中的细粒度信息,比如牌匾中文字的字体、文字排版或者是文字内容本身。而注意力机制则可以帮助模型在大量信息中准确地关注到能够区分不同牌匾更为关键的部分。因此,我们在网络中引入了注意力模块,让模型学习关键信息,以提升全局特征的辨别能力。我们采用了空间注意力机制SGE(Spatial Group-wise Enhance)[4],SGE通过对特征图上的每个空间位置生成一个注意力因子来调整每个空间位置处特征的重要性。SGE模块如图7所示。它首先对特征图进行了分组,然后对每组特征图计算语义特征向量,使用语义特征向量和特征图进行position-wise点乘,得到注意力图,然后将注意力图与特征图进行position-wise点乘,以此来增强特征,从而获得在空间上分布更好的语义特征。

图7. SGE示意图,引入了空间注意力机制
为了减少局部特征的损失,我们对网络backbone进行了改进,取消了ResNet网络最后一个block中的下采样,使得最终的特征图中包含更多的局部信息。除此之外,我们使用GeM[3]池化层替代了最后一个global average pooling,GeM是一种可学习的特征聚合方法,global max pooling和global average pooling都是它的特殊情况,使用GeM池化可以进一步提升全局特征鲁棒性。
局部特征
在针对全局特征进行优化以后,现有模型仍然在以下三个方面表现不够好:1)牌匾截断的情况,特征学习质量差,如图8(a);2)遮挡的牌匾,特征中引入一些无关的上下文信息,如图8(b);3)相似但不同的牌匾难以区分,如图8(c)。因此,我们进一步设计了局部特征分支[1],让模型更加关注牌匾的几何、纹理等局部信息,与全局特征共同做牌匾检索。

(a)

(b)

(c)
图8. 需局部特征优化的不同示例,(a)截断 (b)遮挡(c)文本变化
针对局部特征的提取,我们主要的思路是将牌匾垂直切分成几个部分,分别关注每个部分的局部特征[7],并对局部特征进行对齐后优化。对齐操作如下图9所示,首先将特征图进行垂直池化,得到分块的局部特征图,再计算两张图局部特征之间的相似度矩阵,然后根据公式1找到最短距离将两张图像进行对齐,其中,i,j分别表示两张图中的第i块特征和第j块特征,dij表示两张图中第i块和第j块特征的欧式距离。
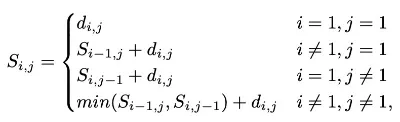
公式1. 局部对齐计算公式

图9. POI牌匾局部对齐示意图
通过这种方式进行局部特征对齐,可以很好地提升牌匾在截断、遮挡、检测框不准等情况下的检索效果。
文本特征
POI牌匾对文本强依赖,可能存在仅牌匾名称文本发生变化的场景。我们设计的全局特征分支以及局部特征分支,虽然可一定程度上学习到文本特征,但是文本信息在整体信息中占比较小,并且监督信号仅为两张图是否相似,导致文本特征并没有被很好的学习到。因此,我们利用已有的文本OCR识别结果,并引入BERT对OCR结果进行编码得到文本特征,该特征作为辅助特征分支和视觉特征进行融合,融合后的特征用于最终的牌匾检索度量学习。值得注意的是,在对牌匾提取OCR结果时,为了减少单帧内识别结果不准的影响,我们利用了一趟资料内同一牌匾的多帧OCR结果,并且将所得到的OCR结果进行拼接,使用BERT对OCR结果特征编码时,对来自不同帧的OCR结果之间插入符号做区分。
3 模型效果
在新的技术方案下,POI牌匾图像检索取得了非常好的效果,准确率和召回率都大于95%,大幅提升了线上指标,并且模型速度也有了巨大的提升。我们随机选择了一些匹配结果,如图10所示。

图10. 评测集中随机抽取的POI牌匾检索结果
我们在优化过程中,有一些非常难的Case也在逐渐被解决,如下图11所示:

图11. 评测集中难例展示,(a)(b)(c)是优化前的错误检索结果,(d)(e)(f)是优化后的检索结果
图(a)、(b)、(c)展示的是优化前的Bad case(左图为query图像,右图为Rank1检索结果),从Bad case中我们不难发现,牌匾检索对细粒度特征提取要求非常高,因为这些case普遍特点是具备整体相似性,但是局部特征有区别。这些Bad case就是我们设计的多模态检索模型的初衷,并且也在优化过程逐渐得以解决,如图(d)、(e)、(f)所示。我们提出的多模态检索模型通过对全局特征优化以及引入局部特征对齐,使得模型更多关注到牌匾上更有区分性的局部特征,如文字信息,文字字体、板式,牌匾纹理等,因此我们的模型对于外观相似的不同牌匾具有更好的区分能力,如图(a)和图(d)效果对比。此外,由于不同视角牌匾存在遮挡、拍摄时的光照强度不同以及不同相机色彩差异大等因素,部分牌匾只利用视觉特征检索非常困难。因此,我们通过辅助特征分支加入了OCR信息,进一步增强了特征的鲁棒性,使得牌匾检索可以综合考虑牌匾的视觉信息和牌匾中的文本信息进行检索,如图(b)和图(e)效果对比。
三 未来发展和挑战
图像检索是在高德地图数据自动化生产中的一次尝试,取得了不错的效果,并且已在实际业务中使用。但是模型并不是完美的,仍会存在Corner case,为了解决这些case,我们未来将会从半监督学习/主动学习自动补充数据,以及引入Transformer[9,10]优化特征提取和融合两方面进行探讨。
1 数据:基于半监督学习/主动学习的数据挖掘
数据是非常重要的,因为模型很难做到完美,总是会存在Corner case,而解决Corner case的一个非常高效的手段就是针对性补充数据。补充数据的关键是如何挖掘Corner case以及如何自动标注,该方向也是目前学术的研究热点,即半监督学习以及主动学习。半监督学习利用有标签数据训练出的模型来对海量无标签数据产生伪标签,进一步标签数据和伪标签数据混合后再优化模型。主动学习是利用有标签数据训练出的模型对海量无标签数据进行数据挖掘,并人工标注挖掘出的有价值数据。两者区别在于是否需要部分人工标注,半监督学习是完全由模型自身产生标签,但是可能导致模型效果存在上限,而主动学习则可以一定程度可提高该上限,因此未来需要深入研究两者的结合,从而更好的补充训练数据,解决Corner case。
2 模型:基于Transformer的特征提取与融合
Transformer是目前学术的研究热点,大量的工作已证明其在分类、检测、分割、跟踪以及行人重识别等任务上的有效性。和CNN相比,Transformer具有全局感受野以及高阶相关性建模的特点,使其在特征提取上有着更好的表征能力。此外,Transformer的输入较为灵活,可以方便地将其他模态信息进行编码,并和图像特征一起输入到模型中,因此其在多模特征融合上也有较大的优势。综上来看,Transformer可以通过对图像Patch的相关性建模来解决POI牌匾在遮挡/截断场景下的匹配效果,并且可以通过对文本特征编码来实现多模特征的融合。
本文参考文献
[1] Zhang X, Luo H, Fan X, et al. Alignedreid: Surpassing human-level performance in person re-identification[J]. arXiv preprint arXiv:1711.08184, 2017.
[2]Kim, Yonghyun, and Wonpyo Park. "Multi-level Distance Regularization for Deep Metric Learning." arXiv preprint arXiv:2102.04223,2021.
[3]Radenović F, Tolias G, Chum O. Fine-tuning CNN image retrieval with no human annotation[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 41(7): 1655-1668.
[4]Li X, Hu X, Yang J. Spatial group-wise enhance: Improving semantic feature learning in convolutional networks[J]. arXiv preprint arXiv:1905.09646, 2019.
原文链接
本文为阿里云原创内容,未经允许不得转载。
图像检索在高德地图POI数据生产中的应用的更多相关文章
- 根据关键字获取高德地图poi信息
根据关键字获取高德地图poi信息 百度地图和高德地图都提供了根据关键字获取相应的poi信息的api,不过它们提供给普通开发者使用的次数有限无法满足要求.其次百度地图返回的poi中位置信息不是经纬度,而 ...
- 高德地图POI爬取_Python
高德地图POI 官方文档:https://lbs.amap.com/api/webservice/guide/api/search#introduce 官网控制台:https://lbs.amap.c ...
- 获取百度地图POI数据三(模拟关键词搜索)
上一篇博文中讲到如何获取用于搜索的关键词,并且已经准备好了一百五十万的关键词 这其中有门牌号码,餐馆酒店名称,公司名称,道路名称等.有了这些数据,我们就可以通过代码,模拟我们在百度地图的搜索框中搜 ...
- 获取百度地图POI数据二(准备搜索关键词)
上篇讲到 想要获取尽可能多的POI数据 需要准备尽可能多的搜索关键字 那么这些关键字如何得来呢? 本人使用的方法是通过一些网站来获取这些关键词 http://poi.mapbar.com ...
- 基于 Golang 完整获取百度地图POI数据的方案
百度地图为web开发者提供了基于HTTP/HTTPS协议的丰富接口,其中包括地点检索服务,web开发者通过此接口可以检索区域内的POI数据.百度地图处于数据保护对接口做了限制,每次访问服务,最多只能检 ...
- 高德地图POI采集(URL-API)
新手从零学起,成功跑通,记一下,技术大神们多多指点. ———————————————— 1-概述 POI:兴趣点.对于百度.高德等电子地图来说,一个POI是地图上的一个店铺/商场/小区等等. 这次要解 ...
- 高德地图poi关键字搜索-vue+ant-design
最近有个需求,需要输入上车点,下车点,然后输入上车点的时候还要在下方显示地图附近的车辆.百度了一波之后,完全莫得头绪,很多代码也都用不了,即便改了之后也不怎么生效.我用的是jeecg-boot.最后静 ...
- 获取百度地图POI数据一(详解百度返回的POI数据)
POI是一切可以抽象为空间点的现实世界的实体,比如餐馆,酒店,车站,停车场等.POI数据具有空间坐标和各种属性,是各种地图查询软件的基础数据之一.百度地图作为国内顶尖的地图企业,其上具有丰富的POI数 ...
- 百度地图POI数据爬取,突破百度地图API爬取数目“400条“的限制11。
1.POI爬取方法说明 1.1AK申请 登录百度账号,在百度地图开发者平台的API控制台申请一个服务端的ak,主要用到的是Place API.检校方式可设置成IP白名单,IP直接设置成了0.0.0.0 ...
- 百度地图和高德地图结合在web中的使用(二)
百度地图在web中的使用(二) 背景:在做一个关于地理位置字段时,初始位置使用百度地图获取时失败,获取的位置信息不准确,奈何产品说友商好使的啊,F12看后是采用的高德,所以在这采用高德地图获取初始位置 ...
随机推荐
- C++ 传递数组引用
不用额外变量可以在函数中得到数组长度信息,函数的形参声明为数组引用 #include <iostream> using namespace std; void f(int(&a) ...
- 记录--不定高度展开收起动画 css/js 实现
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 不定高度展开收起动画 最近在做需求的时候,遇见了元素高度展开收起的动画需求,一开始是想到了使用 transition: all .3s; ...
- 记录--JavaScript 中有趣的 9 个常用编码套路
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 1️⃣ set对象:数组快速去重 常规情况下,我们想要筛选唯一值,一般会想到遍历数组然后逐个对比,或者使用成熟的库比如lodash之类的. ...
- Linunx安装wkhtmltox
1.下载wkhtmltox安装包 官网:https://wkhtmltopdf.org/downloads.html 根据系统类型选择下载wkhtmltox 环境:centos6 32位.wkhtml ...
- Windows中控制台(cmd)模式下运行程序卡死/挂起现象解决方案(快速编辑模式)
最近在运行编译好的exe文件时,发现了一个现象,就是通过cmd运行exe文件或者双击执行运行exe文件,偶尔会出现程序没有执行的情况.最开始发现这个现象时,还以为是程序出现了什么Bug.后面经过网上查 ...
- Redis(5)——亿级数据过滤和布隆过滤器
一.布隆过滤器简介 上一次 我们学会了使用 HyperLogLog 来对大数据进行一个估算,它非常有价值,可以解决很多精确度不高的统计需求.但是如果我们想知道某一个值是不是已经在 HyperLogLo ...
- [MAUI]模仿哔哩哔哩的一键三连
@ 目录 创建弧形进度条 绘制弧 准备物料 创建气泡 创建手势 创建交互与动效 项目地址 哔哩哔哩(Bilibili)中用户可以通过长按点赞键同时完成点赞.投币.收藏对UP主表示支持,后UP主多用&q ...
- KingbaseES V8R3 集群运维系列之 -- network_rewind.sh磁盘检测功能详解
案例说明: 在KingbaseES V8R3集群,network_rewind.sh用于当节点数据库服务down时,实现数据库服务的自动恢复功能.在network_rewind.sh执行时,会对数 ...
- java实战字符串2:中英字符串相互转换
题目描述 输入字符串为中文拼音号码串或者英文号码串,如果输入是中文拼音号码串则转成英文号码串,如果输入是英文号码串则转成中文号码串. 特殊情况是英文号码串会出现Double + 英文数字或者拼音数值. ...
- JDK 14的新特性:switch表达式
目录 简介 写在前面 连写case switch返回值 yield 总结 简介 switch的新特性可是源远流长,早在JDK 12就以预览功能被引入了,最终在JDK 14成为了正式版本的功能:JEP ...