算法金 | 详解过拟合和欠拟合!性感妩媚 VS 大杀四方

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
今天我们来战 过拟合和欠拟合,特别是令江湖侠客闻风丧胆的 过拟合,简称过儿,
Emmm 过儿听起来有点怪怪的

1. 楔子
机器学习模型是一种能够从数据中学习规律并进行预测的算法。我们希望通过算法预测未来,大杀四方
事实上,可能在内一条龙在外一条虫
过拟合和欠拟合的定义
- 欠拟合:模型在训练数据和测试数据上都表现不佳,在内也是一条虫虫啊大郎
- 过拟合:模型过度拟合训练数据,如下图右3。这通常导致模型在训练数据上表现非常好,但在测试数据上表现很差
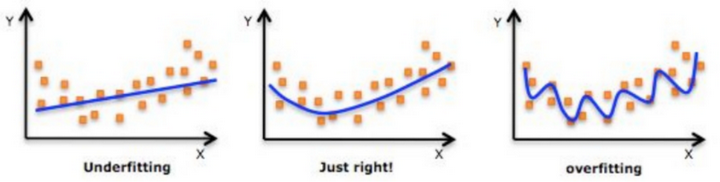

2. 过拟合
2.1 过拟合的定义
过拟合现象是指模型过于复杂,捕捉到了训练数据中的噪声和细节,从而失去了泛化能力。如下图右三这只喵
这种情况下,模型通常在训练数据上表现极好,但在测试数据上表现很差。
训练时 海绵宝宝上线了,测试时海绵宝宝不见了,有没有

2.2 过拟合的原因
数据量不足
当数据量不足时,模型容易记住训练数据中的每一个细节和噪声,从而导致过拟合。
模型复杂度过高
过于复杂的模型(例如具有大量参数的神经网络)可以拟合训练数据中的任何模式,包括噪声。
2.3 过拟合的表现
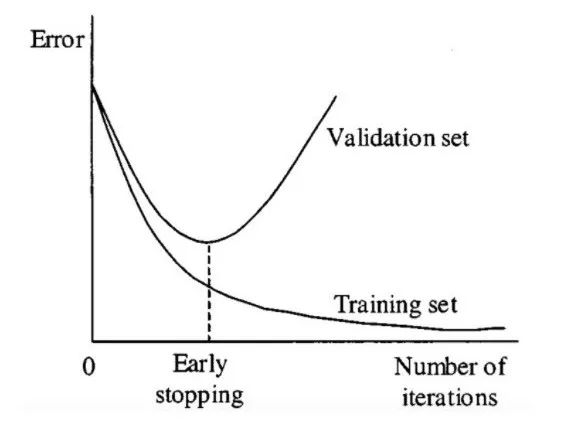
过拟合的主要表现是模型在训练集上的误差很低,但在测试集上的误差很高。下面我们用代码示例和可视化来展示过拟合的现象。
代码示例
通过增加模型复杂度来展示过拟合的现象。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import mean_squared_error
# 生成武侠数据集
np.random.seed(42)
X = np.linspace(1, 10, 100)
y = 2 * X + np.sin(X) * 5 + np.random.randn(100) * 2 # 假设某个武侠角色的武功值与其年龄的关系
# 拆分数据集
X = X.reshape(-1, 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 多项式回归模型(过拟合)
poly_features_high = PolynomialFeatures(degree=20) # 增加模型复杂度
X_poly_train_high = poly_features_high.fit_transform(X_train)
X_poly_test_high = poly_features_high.transform(X_test)
poly_reg_high = LinearRegression()
poly_reg_high.fit(X_poly_train_high, y_train)
y_poly_train_pred_high = poly_reg_high.predict(X_poly_train_high)
y_poly_test_pred_high = poly_reg_high.predict(X_poly_test_high)
# 训练集和测试集的表现
print("高阶多项式回归 - 训练集误差:", mean_squared_error(y_train, y_poly_train_pred_high))
print("高阶多项式回归 - 测试集误差:", mean_squared_error(y_test, y_poly_test_pred_high))
# 可视化结果
plt.scatter(X, y, color='blue', label='数据点')
plt.plot(X, poly_reg_high.predict(poly_features_high.transform(X)), color='red', label='高阶多项式回归拟合线')
plt.xlabel('年龄')
plt.ylabel('武功值')
plt.title('高阶多项式回归(过拟合)')
plt.legend()
plt.show()
在这个示例中,我们将多项式回归的阶数提高到了 20,从而增加了模型的复杂度。模型想要迎合每一个样本数据,通过可视化可以看到这条拟合的线非常的妩媚。(记住她的性感小尾巴,下面会有选美环节)
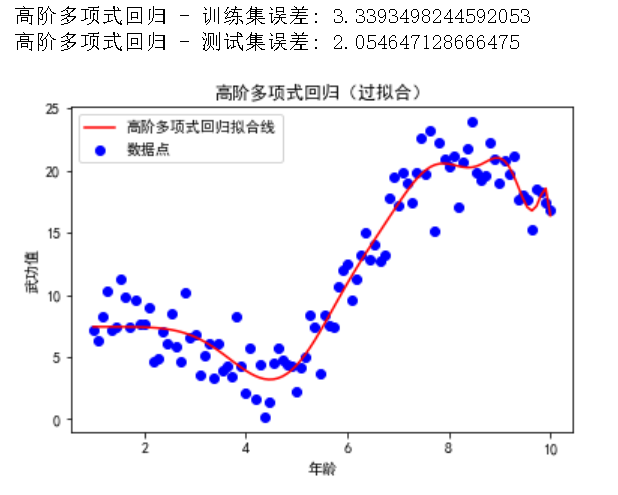

2.4 过拟合的解决方法
增加数据量
通过增加数据量,可以使模型更好地学习到数据中的一般规律,而不是记住每个细节和噪声。
正则化方法(L1, L2)
正则化是在模型的损失函数中加入一个惩罚项,以防止模型过于复杂。L1 和 L2 正则化是两种常见的方法。
L1 正则化通过最小化权重的绝对值之和来优化模型,这有助于创建一个简洁且易于理解的模型,并且它对异常值具有较好的抵抗力。
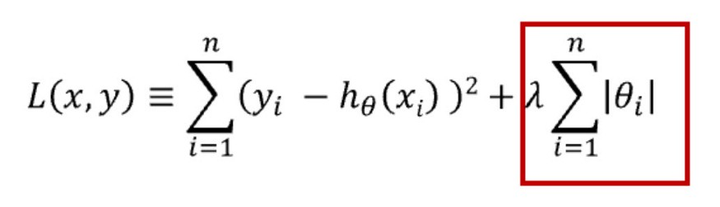
L2 正则化则通过最小化权重值的平方和来工作,这种方法能够使模型捕捉到数据中的复杂模式,但它对异常值的敏感度较高。
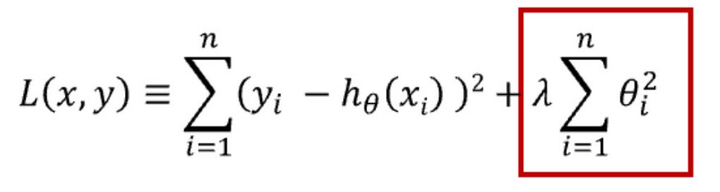
剪枝(对于决策树)
对于决策树模型,可以通过剪枝来减少其复杂度,从而防止过拟合。
交叉验证
通过交叉验证,可以更好地评估模型的性能,并选择最合适的模型复杂度。
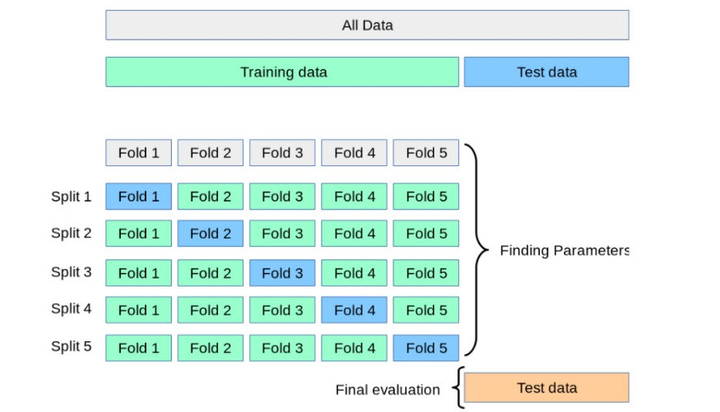
提前停止训练
在训练过程中监控模型在验证集上的表现,当性能不再提高时停止训练,可以防止模型过度拟合训练数据。
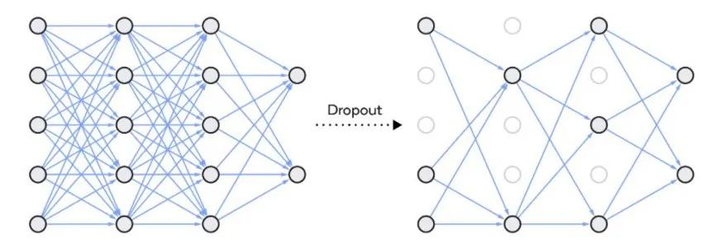
Dropout
Dropout 是一种在神经网络中使用的正则化技术,它通过随机地停用一些神经网络单元来工作。这种技术可以应用于网络中的任意隐藏层或输入层,但通常不应用于输出层。Dropout 的作用是减少神经元之间的相互依赖,促使网络学习到更加独立的特征表示。通过这种方式,Dropout 有助于降低模型的复杂度,防止过拟合,如下面的图表所示。

代码示例 - 正则化
我们将使用岭回归(L2 正则化)来演示如何减轻过拟合。
from sklearn.linear_model import Ridge
# 岭回归模型
ridge_reg = Ridge(alpha=1)
ridge_reg.fit(X_poly_train_high, y_train)
y_ridge_train_pred = ridge_reg.predict(X_poly_train_high)
y_ridge_test_pred = ridge_reg.predict(X_poly_test_high)
# 训练集和测试集的表现
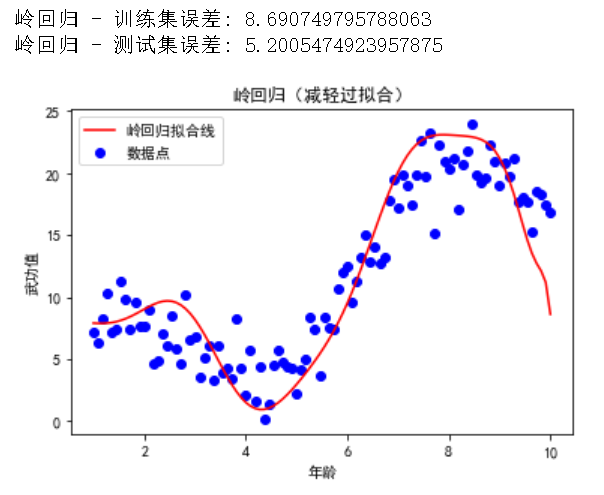
print("岭回归 - 训练集误差:", mean_squared_error(y_train, y_ridge_train_pred))
print("岭回归 - 测试集误差:", mean_squared_error(y_test, y_ridge_test_pred))
# 可视化结果
plt.scatter(X, y, color='blue', label='数据点')
plt.plot(X, ridge_reg.predict(poly_features_high.transform(X)), color='red', label='岭回归拟合线')
plt.xlabel('年龄')
plt.ylabel('武功值')
plt.title('岭回归(减轻过拟合)')
plt.legend()
plt.show()
通过引入岭回归(L2 正则化),我们可以看到模型的复杂度降低了,训练集和测试集的误差更加接近,从而减轻了过拟合现象。通过可视化直观感受一下,性感小尾巴不见了;跟上面那条线相比,这个拟合的线少了几分妖娆,但明显更加丝滑(是算法金喜欢的 Style)
3. 欠拟合
3.1 欠拟合的定义
欠拟合现象是指模型在训练数据和测试数据上都表现不佳。这通常是因为模型过于简单,无法捕捉数据中的规律。
3.2 欠拟合的原因
模型复杂度过低
当模型的复杂度过低时,无法捕捉数据中的复杂模式,导致欠拟合。
特征不足
当模型没有足够的特征来描述数据时,也会导致欠拟合。
3.3 欠拟合的表现
欠拟合的主要表现是模型在训练集和测试集上的误差都很高。下面我们用代码示例和可视化来展示欠拟合的现象。
代码示例
我们将使用一个简单的线性回归模型来展示欠拟合的现象。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 生成武侠数据集
np.random.seed(42)
X = np.linspace(1, 10, 100)
y = 2 * X + np.sin(X) * 5 + np.random.randn(100) * 2 # 假设某个武侠角色的武功值与其年龄的关系
# 拆分数据集
X = X.reshape(-1, 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 简单线性回归模型(欠拟合)
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)
y_train_pred = lin_reg.predict(X_train)
y_test_pred = lin_reg.predict(X_test)
# 训练集和测试集的表现
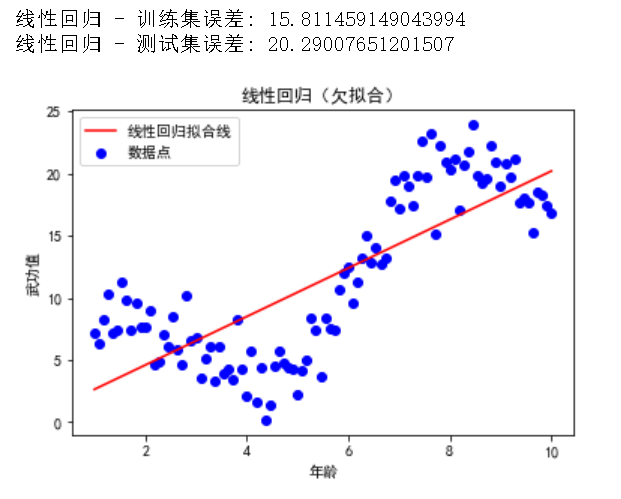
print("线性回归 - 训练集误差:", mean_squared_error(y_train, y_train_pred))
print("线性回归 - 测试集误差:", mean_squared_error(y_test, y_test_pred))
# 可视化结果
plt.scatter(X, y, color='blue', label='数据点')
plt.plot(X, lin_reg.predict(X), color='red', label='线性回归拟合线')
plt.xlabel('年龄')
plt.ylabel('武功值')
plt.title('线性回归(欠拟合)')
plt.legend()
plt.show()
在这个示例中,我们使用简单的线性回归模型来拟合数据。可以看到模型在训练集和测试集上的误差都很高,表现出欠拟合的特征。

3.4 欠拟合的解决方法
增加模型复杂度
通过增加模型的复杂度(例如,使用更复杂的算法或增加多项式特征),可以帮助模型更好地拟合数据。
提供更多特征
通过提供更多有意义的特征,可以帮助模型捕捉数据中的复杂模式。
减少正则化强度
如果正则化强度过高,模型的复杂度会受到限制,导致欠拟合。可以通过减少正则化强度来缓解这个问题。
代码示例 - 增加模型复杂度
我们将使用多项式回归模型来演示如何减轻欠拟合。
from sklearn.preprocessing import PolynomialFeatures
# 多项式回归模型(减轻欠拟合)
poly_features = PolynomialFeatures(degree=3)
X_poly_train = poly_features.fit_transform(X_train)
X_poly_test = poly_features.transform(X_test)
poly_reg = LinearRegression()
poly_reg.fit(X_poly_train, y_train)
y_poly_train_pred = poly_reg.predict(X_poly_train)
y_poly_test_pred = poly_reg.predict(X_poly_test)
# 训练集和测试集的表现
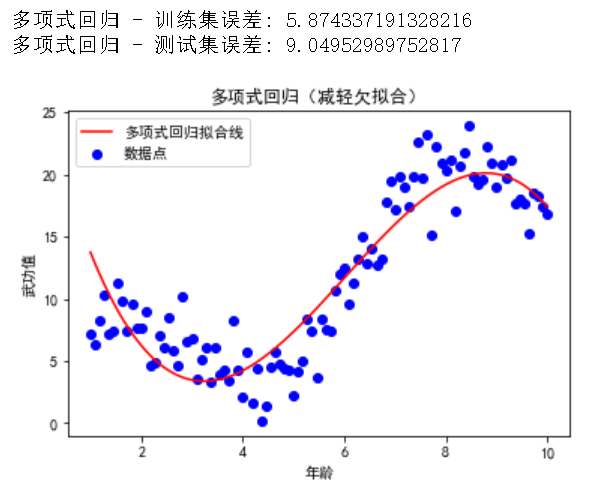
print("多项式回归 - 训练集误差:", mean_squared_error(y_train, y_poly_train_pred))
print("多项式回归 - 测试集误差:", mean_squared_error(y_test, y_poly_test_pred))
# 可视化结果
plt.scatter(X, y, color='blue', label='数据点')
plt.plot(X, poly_reg.predict(poly_features.transform(X)), color='red', label='多项式回归拟合线')
plt.xlabel('年龄')
plt.ylabel('武功值')
plt.title('多项式回归(减轻欠拟合)')
plt.legend()
plt.show()
通过使用三阶多项式回归模型,我们可以看到模型在训练集和测试集上的表现有所改善,从而减轻了欠拟合现象。

4. 过拟与欠拟合的对比
4.1 视觉化对比
为了更直观地理解过拟合和欠拟合,我们通过可视化来展示它们的区别。我们将使用之前生成的武侠数据集,并同时展示欠拟合、适度拟合和过拟合的模型拟合情况。
代码示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
# 生成武侠数据集
np.random.seed(42)
X = np.linspace(1, 10, 100)
y = 2 * X + np.sin(X) * 5 + np.random.randn(100) * 2 # 假设某个武侠角色的武功值与其年龄的关系
# 拆分数据集
X = X.reshape(-1, 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 欠拟合模型 - 简单线性回归
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)
y_lin_pred = lin_reg.predict(X)
# 适度拟合模型 - 三阶多项式回归
poly_reg_3 = make_pipeline(PolynomialFeatures(degree=3), LinearRegression())
poly_reg_3.fit(X_train, y_train)
y_poly_3_pred = poly_reg_3.predict(X)
# 过拟合模型 - 二十阶多项式回归
poly_reg_20 = make_pipeline(PolynomialFeatures(degree=20), LinearRegression())
poly_reg_20.fit(X_train, y_train)
y_poly_20_pred = poly_reg_20.predict(X)
# 可视化结果
plt.figure(figsize=(14, 7))
# 原始数据点
plt.scatter(X, y, color='blue', label='数据点')
# 欠拟合
plt.plot(X, y_lin_pred, color='green', label='线性回归(欠拟合)')
# 适度拟合
plt.plot(X, y_poly_3_pred, color='orange', label='三阶多项式回归(适度拟合)')
# 过拟合
plt.plot(X, y_poly_20_pred, color='red', label='二十阶多项式回归(过拟合)')
plt.xlabel('年龄')
plt.ylabel('武功值')
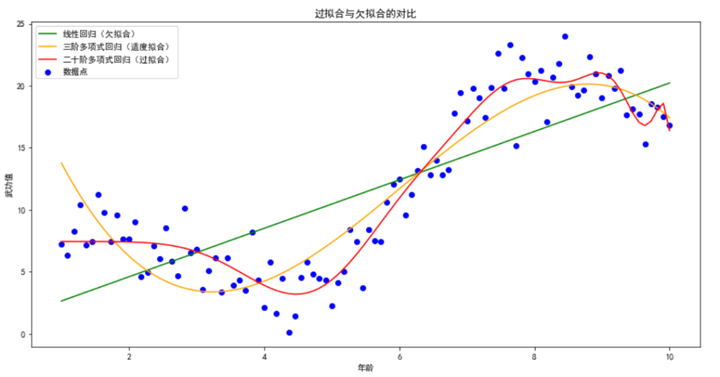
plt.title('过拟合与欠拟合的对比')
plt.legend()
plt.show()
结果分析
在这个可视化示例中,我们可以清楚地看到三种模型的拟合情况:
- 欠拟合(绿色线):简单的线性回归模型无法捕捉数据中的复杂模式,导致在训练集和测试集上都表现不佳。
- 适度拟合(橙色线):三阶多项式回归模型能够较好地捕捉数据中的规律,同时在训练集和测试集上都有较好的表现。
- 过拟合(红色线):二十阶多项式回归模型虽然在训练集上表现非常好,但在测试集上表现很差。模型过于复杂,倾向于记住训练数据中的噪声和细节。
通过这种对比,可以帮助我们更好地理解过拟合和欠拟合现象,以及如何在模型训练中找到适度的复杂度。
[ 抱个拳,总个结 ]
在本文中,我们详细讨论了过拟合和欠拟合这两个机器学习中常见的问题。我们通过定义、原因、表现和解决方法的层层解析,帮助少侠理解和识别这些现象,并提供了实际的代码示例和案例研究来进一步说明。
过拟合
过拟合是指模型在训练数据上表现良好,但在测试数据上表现差。这通常是因为模型过于复杂,记住了训练数据中的噪声和细节。解决过拟合的方法包括:
- 增加数据量
- 正则化方法(L1, L2)
- 剪枝(对于决策树)
- 交叉验证
- 提前停止训练
- Dropout
欠拟合
欠拟合是指模型在训练数据和测试数据上都表现不佳。这通常是因为模型过于简单,无法捕捉数据中的规律。解决欠拟合的方法包括:
- 增加模型复杂度
- 提供更多特征
- 减少正则化强度
在实际项目中避免过拟合和欠拟合
在实际项目中,避免过拟合和欠拟合是构建高性能模型的关键。以下是一些实用的建议:
- 合理选择模型:根据数据的复杂度选择合适的模型。如果数据复杂,选择更复杂的模型;如果数据简单,选择简单的模型。
- 充分利用数据:增加训练数据的量,同时确保数据的多样性和代表性。
- 特征工程:通过特征工程来提升模型的性能。可以增加有意义的特征,或者通过特征选择来减少冗余特征。
- 正则化技术:合理使用正则化技术,如L1正则化和L2正则化,来防止模型过拟合。
- 交叉验证:通过交叉验证来评估模型的泛化能力,选择最佳的模型参数。
通过本文的学习,希望少侠能够更好地理解过拟合和欠拟合的概念,并在实际项目中应用相应的解决方法,构建出性能优良的机器学习模型。

[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖
算法金 | 详解过拟合和欠拟合!性感妩媚 VS 大杀四方的更多相关文章
- 各大公司广泛使用的在线学习算法FTRL详解
各大公司广泛使用的在线学习算法FTRL详解 现在做在线学习和CTR常常会用到逻辑回归( Logistic Regression),而传统的批量(batch)算法无法有效地处理超大规模的数据集和在线数据 ...
- 一致性算法RAFT详解
原帖地址:http://www.solinx.co/archives/415?utm_source=tuicool&utm_medium=referral一致性算法Raft详解背景 熟悉或了解 ...
- 转】Mahout推荐算法API详解
原博文出自于: http://blog.fens.me/mahout-recommendation-api/ 感谢! Posted: Oct 21, 2013 Tags: itemCFknnMahou ...
- MD5算法步骤详解
转自MD5算法步骤详解 之前要写一个MD5程序,但是从网络上看到的资料基本上一样,只是讲了一个大概.经过我自己的实践,我决定写一个心得,给需要实现MD5,但又不要求很高深的编程知识的童鞋参考.不多说了 ...
- 斯坦福大学公开课机器学习: advice for applying machine learning - evaluatin a phpothesis(怎么评估学习算法得到的假设以及如何防止过拟合或欠拟合)
怎样评价我们的学习算法得到的假设以及如何防止过拟合和欠拟合的问题. 当我们确定学习算法的参数时,我们考虑的是选择参数来使训练误差最小化.有人认为,得到一个很小的训练误差一定是一件好事.但其实,仅仅是因 ...
- [转]Mahout推荐算法API详解
Mahout推荐算法API详解 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeepe ...
- 2. EM算法-原理详解
1. EM算法-数学基础 2. EM算法-原理详解 3. EM算法-高斯混合模型GMM 4. EM算法-高斯混合模型GMM详细代码实现 5. EM算法-高斯混合模型GMM+Lasso 1. 前言 概率 ...
- [置顶]
Isolation Forest算法实现详解
本文算法完整实现源码已开源至本人的GitHub(如果对你有帮助,请给一个 star ),参看其中的 iforest 包下的 IForest 和 ITree 两个类: https://github.co ...
- [置顶]
Isolation Forest算法原理详解
本文只介绍原论文中的 Isolation Forest 孤立点检测算法的原理,实际的代码实现详解请参照我的另一篇博客:Isolation Forest算法实现详解. 或者读者可以到我的GitHub上去 ...
- Isolation Forest算法实现详解
本文介绍的 Isolation Forest 算法原理请参看我的博客:Isolation Forest异常检测算法原理详解,本文中我们只介绍详细的代码实现过程. 1.ITree的设计与实现 首先,我们 ...
随机推荐
- 草之王qsnctfwp
文件内容(举例): 林间小路旁有一条小溪 草之王许下三个诺言 无人知晓神诏背后的真相 草之王许下三个诺言 === 林间小路旁有一条小溪 草之王许下三个诺言 林间小路旁有一条小溪 无人知晓神诏背后的真相 ...
- Spring Cloud OpenFeign:基于Ribbon和Hystrix的声明式服务调用
Spring Cloud OpenFeign:基于Ribbon和Hystrix的声明式服务调用 SpringCloud学习教程 SpringCloud Spring Cloud OpenFeign 是 ...
- OpenStack实战安装部署
OpenStack安装部署 一.基础准备工作 部署环境:CentOS 7 64 1.关闭本地iptables防火墙并设置开机不自启动 <span style="color:#33333 ...
- sql 语句系列(分割ip)[八百章之第十四章]
前言 单独列出的章节.因为用处比较多. mysql select SUBSTRING_INDEX(SUBSTRING_INDEX("192.168.1.1",".&quo ...
- EDA(Exploratory Data Analysis)数据探索性分析
EDA目的:通过了解数据集的分布情况,数据之间的关系,来帮我们更好的后期进行特征工程和建立模型. 本文主要是一个根据coco数据集格式的json文件,来分析数据集中图片尺寸,宽高比,bbox尺寸,宽高 ...
- marquee实现滚动
marquee的基本语法:<marquee> ... </marquee> 参数:1.滚动方向 (direction):left(左).right(右).up(上).down( ...
- 简述Linux磁盘IO
1.什么是磁盘 在讲解磁盘IO前,先简单说下什么是磁盘.磁盘是可以持久化存储的设备,根据存储介质的不同,常见磁盘可以分为两类:机械磁盘和固态磁盘. 1.1 机械磁盘 第一类,机械磁盘,也称为硬盘驱动器 ...
- 阿里云数字化安全生产平台 DPS V1.0 正式发布!
简介:数字化安全生产平台则帮助客户促进业务与 IT 的全面协同,从业务集中监控.业务流程管理.应急指挥响应等多维度来帮助客户建立完善专业的业务连续性保障体系. 作者:银桑.比扬 阿里云创立于 200 ...
- OpenSergo 正式开源,多家厂商共建微服务治理规范和实现
简介 OpenSergo,Open 是开放的意思,Sergo 则是取了服务治理两个英文单词 Service Governance 的前部分字母 Ser 和 Go,合起来即是一个开放的服务治理项目. ...
- 系列解读SMC-R:透明无感提升云上 TCP 应用网络性能(一)| 龙蜥技术
简介:已有的应用若想使用RDMA技术改造成本高,那么有没有一种技术是不做任何改造就可以享受RDMA带来的性能优势? 文/龙蜥社区高性能网络SIG 引言 Shared Memory Communi ...