FileBeat简单使用
简介
首先要了解ELK架构
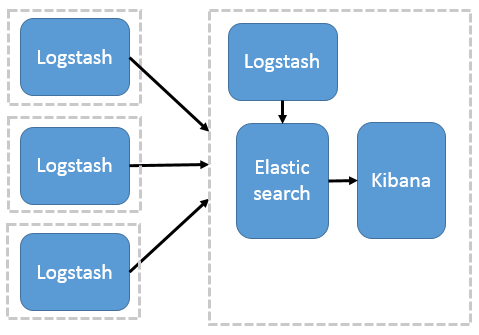
这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
Beats 同样作为ELK Stack的新成员,包含

Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户
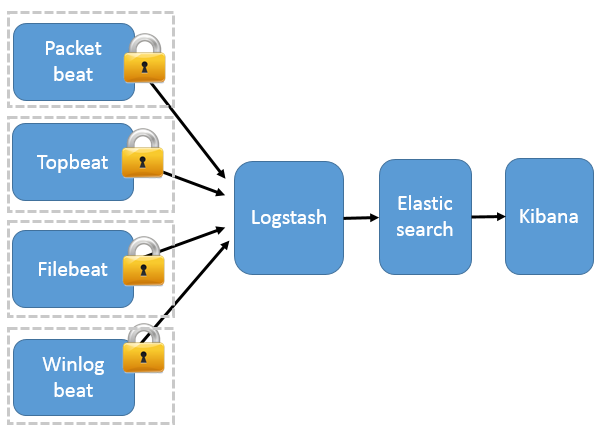
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。
filebeat是一个轻量级日志收集器,有多轻量?和logstatsh一比的话就很轻量了
首先logstatsh是使用java编写的,所以跑起来需要占用jvm资源,默认的堆大小就是1g
而filebeat是使用go语言写的,占用的资源比logstatsh少的多

官网的原话
使用
其实需要我们配置的地方就是收集日志的策略,在filebeat.yml里有很多日志策略的配置
比如说你只要收集info或者error的日志,或者合并某段日志
因为不指定合并日志的策略,filebeat会一行一行的显示在kibana上,但是比如说一些sql的日志就是占几行的
我这里的需求就很简单,日志全部收集,需要合并日志,只要通过配置multiline这个配置
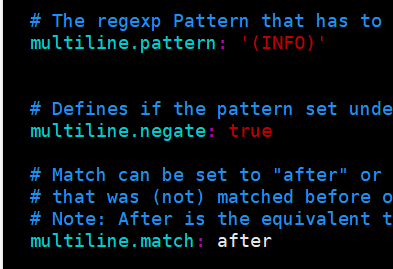
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
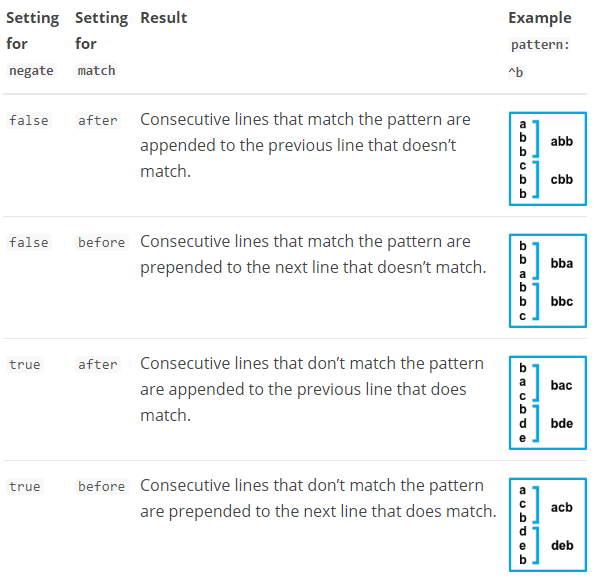
根据你配置其他多行选项的方式,与指定正则表达式匹配的行将被视为上一行的延续或新多行事件的开始。 你可以设置 negate 选项以否定模式。
multiline.pattern 匹配的正则
multiline.match after 或 before,合并到上一行的末尾或开头
multiline.negate 默认是false,匹配pattern的行合并到上一行;true,不匹配pattern的行合并到上一行
效果
实战
日志格式
配置
收集info的日志
原理
示例图

实现
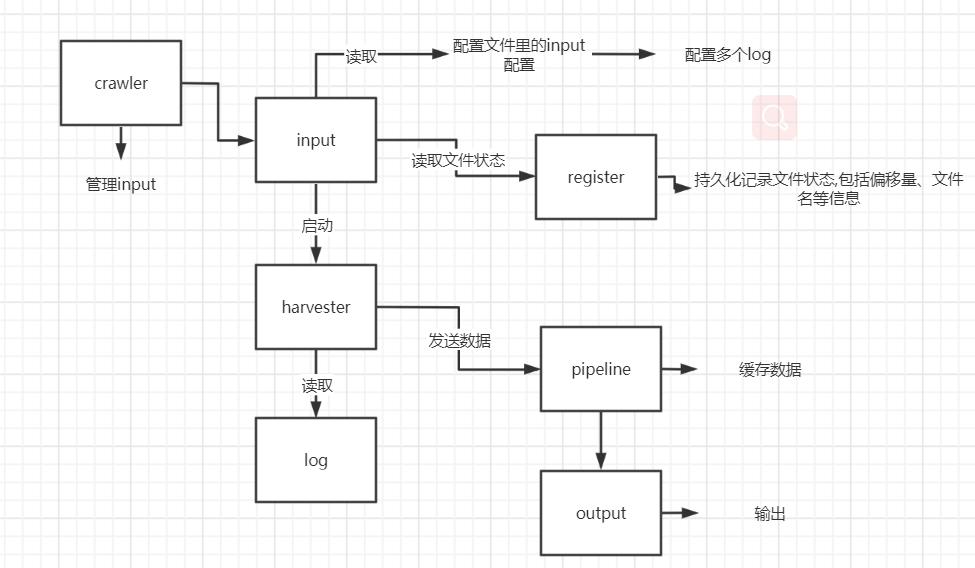
整个 filebeat 主要包含以下重要组件:
- Crawler:负责管理和启动各个 Input
- Input:负责管理和解析输入源的信息,以及为每个文件启动 Harvester。可由配置文件指定输入源信息。
- Harvester: Harvester 负责读取一个文件的信息。
- Pipeline: 负责管理缓存、Harvester 的信息写入以及 Output 的消费等,是 Filebeat 最核心的组件。
- Output: 输出源,可由配置文件指定输出源信息。
- Registrar:管理记录每个文件处理状态,包括偏移量、文件名等信息。当 Filebeat 启动时,会从 Registrar 恢复文件处理状态。
filebeat 的整个生命周期,几个组件共同协作,完成了日志从采集到上报的整个过程。
关于如何保证日志文件的正确性,input里有两个重要的状态offset和finished
- offset: 代表文件当前读取的 offset,从 Registrar 中初始化。Harvest 读取文件后,会同时修改 offset。
- finished: 代表该文件对应的 Harvester 是否已经结束,Harvester 开始时置为 false,结束时置为 True。
对于每次定时扫描到的文件,概括来说,会有三种大的情况:
- Input 找不到该文件状态的记录, 说明是新增文件,则开启一个 Harvester,从头开始解析该文件
- 如果可以找到文件状态,且 finished 等于 false。这个说明已经有了一个 Harvester 在处理了,这种情况直接忽略就好了。
- 如果可以找到文件状态,且 finished 等于 true。说明之前有 Harvester 处理过,但已经处理结束了。
除此之外,一个比较有意思的点是,Filebeat 甚至可以处理文件名修改的问题。即使一个日志的文件名被修改过,Filebeat 重启后,也能找到该文件,从上次读过的地方继读。
这是因为 Filebeat 除了在 Registrar 存储了文件名,还存储了文件的唯一标识。对于 Linux 来说,这个文件的唯一标识就是该文件的 inode ID + device ID。
FileBeat简单使用的更多相关文章
- elk + filebeat,6.3.2版本简单搭建,实现我们自己的集中式日志系统
前言 刚从事开发那段时间不习惯输出日志,认为那是无用功,徒增代码量,总认为自己的代码无懈可击:老大的叮嘱.强调也都视为耳旁风,最终导致的结果是我加班排查问题,花的时间还挺长的,要复现问题.排查问题等, ...
- fileBeat的简单使用
Beat的简单使用 Filebeat配置 Output 常见日志格式封装 简单使用filebeat格式化nginx日志 Filebeat的配置: # 修改filebeat.yml # vim file ...
- Filebeat原理与简单配置入门
Filebeat工作原理 Filebeat由两个主要组件组成:prospectors 和 harvesters.这两个组件协同工作将文件变动发送到指定的输出中. Harvester(收割机):负责读取 ...
- CentOS7下 简单安装和配置Elasticsearch Kibana Filebeat 快速搭建集群日志收集平台
目录 1.添加elasticsearch官网的yum源 2.Elasticsearch 安装elasticsearch 配置elasticsearch 启动elasticsearch并设为开机启动 3 ...
- Filebeat日志收集简单使用
1.简略介绍 轻量型日志采集器,用于转发和汇总日志与文件. 官网: https://www.elastic.co/cn/beats/filebeat 2.本文实现的功能 3.事先必备: 至少一台Kaf ...
- 日志分析 第四章 安装filebeat
在进行前面准备之后可以开始安装了,我们的安装顺序是filebeat--->logstash--->elasticsearch filebeat安装很简单,先下载filebeat,这里我们使 ...
- filebeat安装与基础用法
来自官网,版本为1.2 下载rpm包并安装 wget -c https://download.elastic.co/beats/filebeat/filebeat-1.2.3-x86_64.rpm r ...
- ELK+FileBeat+Log4Net搭建日志系统
ELK+FileBeat+Log4Net搭建日志系统 来源:https://www.zybuluo.com/muyanfeixiang/note/608470 标签(空格分隔): ELK Log4Ne ...
- Logstash学习1-logstash的简单例子
如何安装ELK Redis插件 1. 安装好logstash后.2. 最简单的logstash.logstash -e 'input { stdin { } } output { stdout {} ...
- Filebeat中文指南
Filebeat中文指南 翻译自:https://www.elastic.co/guide/en/beats/filebeat/current/index.html 译者:kerwin 鸣谢:tory ...
随机推荐
- [转帖]python字符串如何删除后几位
https://www.python51.com/jc/15070.html 1.首先在jupyter notebook中新建一个空白的python文件: 2.然后定义一个字符串,用字符串截取的方式打 ...
- [转帖]45个处理字符串的Python方法
https://baijiahao.baidu.com/s?id=1738413163267646541&wfr=spider&for=pc 一.题目解析 先来看一个题目: 判断用 ...
- vue2-vue3监听子组件的生命周期的两种方式
1.生命周期 生命周期是指:vue实例从创建到销毁这一系列过程.vue官网生命周期如下图所示: vue的生命周期有多少个 beforeCreate, created, beforeMount, mou ...
- 【记录一个问题】VictoriaMetrics的vmstorage因为慢查询导致大量写入失败
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 见上图. 一直以为vmstorage中的查询协程会让位于写 ...
- flask session 伪造
flask session 伪造 一.session的作用 由于http协议是一个无状态的协议,也就是说同一个用户第一次请求和第二次请求是完全没有关系的,但是现在的网站基本上有登录使用的功能,这就要求 ...
- Flask的cookie、session
目录 七.设置cookies 7.1 设置cookie的参数 7.2 查询cookie 八.flask的session 实现session的两种思路 8.1 设置session(使用版) 8.2 设置 ...
- 在K8S中,Pod生命周期包含哪些?
在Kubernetes(简称K8s)中,Pod的生命周期经历了一系列状态变化.以下是Pod可能处于的一些主要状态: Pending: 当创建一个Pod时,它首先会进入Pending状态.这个状态下,K ...
- 【OpenIM原创】简单轻松入门 一文讲解WebRTC实现1对1音视频通信原理
什么是 WebRTC ? WebRTC(Web Real-Time Communication)是 Google于2010以6829万美元从 Global IP Solutions 公司购买,并于20 ...
- python读取json格式文件大量数据,以及python字典和列表嵌套用法详解
1.Python读取JSON报错:JSONDecodeError:Extra data:line 2 column 1 错误原因: JSON数据中数据存在多行,在读取数据时,不能够单单用open(), ...
- 驱动开发:内核读取SSDT表基址
在前面的章节<X86驱动:挂接SSDT内核钩子>我们通过代码的方式直接读取 KeServiceDescriptorTable 这个被导出的表结构从而可以直接读取到SSDT表的基址,而在Wi ...