大数据 - MapReduce:从原理到实战的全面指南
本文深入探讨了MapReduce的各个方面,从基础概念和工作原理到编程模型和实际应用场景,最后专注于性能优化的最佳实践。
关注【TechLeadCloud】,分享互联网架构、云服务技术的全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、引言
1.1 数据的价值与挑战
在信息爆炸的时代,数据被视为新的石油。每天都有数以百万计的数据被生成、存储和处理,覆盖了从互联网搜索、电子商务,到生物信息学和气候研究等各个领域。数据的价值体现在多个层面:为企业提供商业洞见、驱动科研创新,甚至在社会治理和公共政策制定中也起到关键作用。然而,随着数据规模的不断增长,如何高效、准确地从这些数据中提取有用信息成为一个巨大的挑战。
1.2 MapReduce的出现与意义
针对大规模数据处理的需求,MapReduce模型应运而生。自2004年由Google首次公开介绍以来,MapReduce已成为分布式数据处理的金标准。它通过简单、优雅的编程模型,使得开发者可以将复杂的数据处理任务分解为可并行化的小任务,从而在数百或数千台机器上并行处理数据。
1.3 不仅是工具,更是思维方式
MapReduce不仅是一个强大的计算框架,更是一种解决问题的方法论。它颠覆了传统的数据处理思维,将问题分解和数据流动性放在了首位。通过Map和Reduce两个基本操作,可以构建出复杂的数据分析管道,解决从文本分析、图计算到机器学习等多种类型的问题。
1.4 持久的影响和现实应用
尽管现在有许多更加先进和灵活的大数据处理框架,如Apache Spark、Flink等,但MapReduce的基础思想和设计原则仍然在各种现代框架和应用中得到体现。它的出现极大地推动了大数据生态系统的发展,包括但不限于Hadoop生态圈、NoSQL数据库以及实时流处理。
二、MapReduce基础
MapReduce模型简介
MapReduce是一种编程模型,用于大规模数据集(特别是非结构化数据)的并行处理。这个模型的核心思想是将大数据处理任务分解为两个主要步骤:Map和Reduce。
- Map阶段:接受输入数据,并将其分解成一系列的键值对。
- Reduce阶段:处理由Map阶段产生的键值对,进行某种形式的聚合操作,最终生成输出结果。
这两个阶段的组合使得MapReduce能够解决一系列复杂的数据处理问题,并可方便地进行分布式实现。
关键组件:Mapper与Reducer
Mapper
Mapper是实现Map阶段功能的代码组件。它接受原始数据作为输入,执行某种转换操作,然后输出一组键值对。这些键值对会作为Reduce阶段的输入。
// Java Mapper示例
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// 输入:行号和行内容
// 输出:单词和对应的计数(此处为1)
public void map(LongWritable key, Text value, Context context) {
// 代码注释:将输入行分解为单词,并输出键值对
}
}
Reducer
Reducer是实现Reduce阶段功能的代码组件。它从Mapper接收键值对,并对具有相同键的所有值进行聚合。
// Java Reducer示例
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 输入:单词和一组计数
// 输出:单词和总计数
public void reduce(Text key, Iterable<IntWritable> values, Context context) {
// 代码注释:对输入的计数进行求和,并输出结果
}
}
数据流
在MapReduce模型中,数据流是非常关键的一个环节。一般而言,数据流经历以下几个阶段:
- 输入分片(Input Splitting):原始输入数据被分解为更小的数据块。
- Map阶段:每个数据块被送到一个Mapper进行处理。
- Shuffling:由Mapper产生的键值对会根据键进行排序和分组。
- Reduce阶段:每一组具有相同键的键值对被送到同一个Reducer进行聚合。
- 输出汇总(Output Collection):最终的输出数据被写入磁盘或其他存储介质。
以上概述为你提供了MapReduce的基础知识和主要组件。这些构成了MapReduce强大灵活性和广泛应用的基础。
三、工作原理
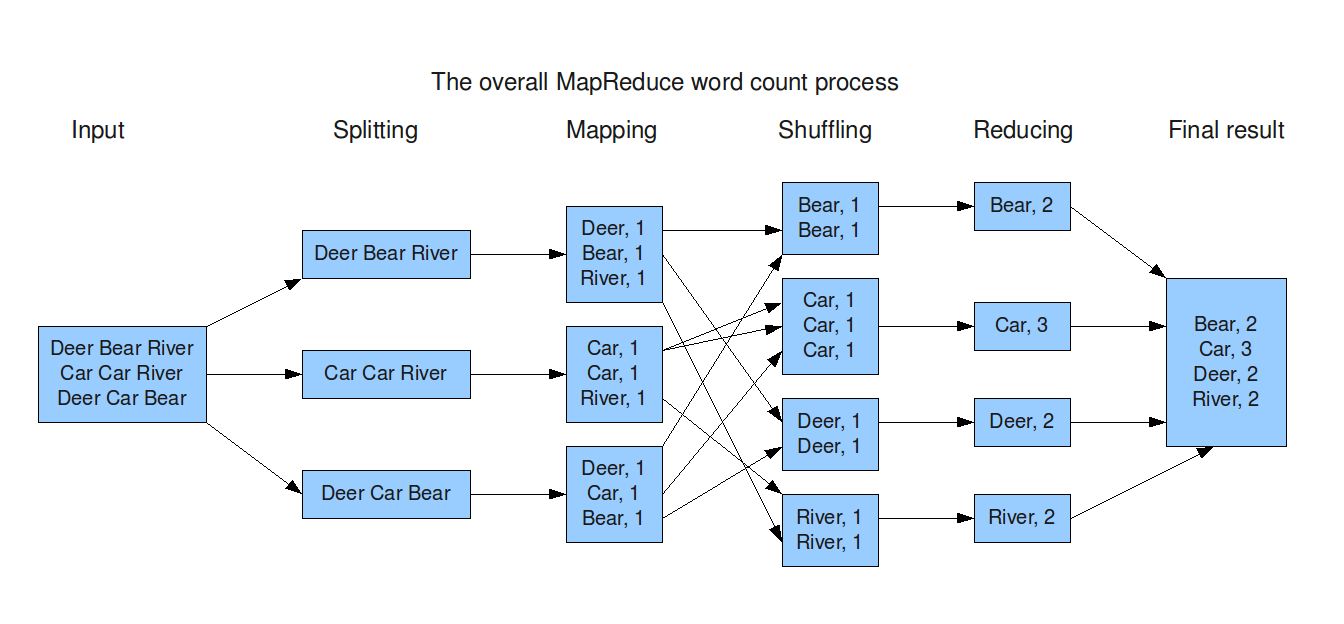
在掌握了MapReduce的基础概念之后,理解其内部工作机制是深入掌握这一技术的关键。本部分将从数据流动、任务调度,到数据局部性等方面,深入剖析MapReduce的工作原理。
数据分片与分布
在一个典型的MapReduce作业中,输入数据首先会被分成多个分片(Splits),以便并行处理。这些数据分片通常会被存储在分布式文件系统(例如,HDFS)中,并尽量保持数据局部性,以减少数据传输的开销。
# 数据分片示例:将大文件分成多个小文件
split -b 64m input-file
任务调度
MapReduce框架负责对Mapper和Reducer任务进行调度。一旦一个数据分片准备好,调度器会找到一个可用的节点,并将Mapper任务分配给该节点。同样地,Reducer任务也会被调度到具有必要数据的节点。
// Java代码:使用Hadoop的Job类来配置和提交一个MapReduce任务
Job job = Job.getInstance(conf, "example-job");
job.setMapperClass(ExampleMapper.class);
job.setReducerClass(ExampleReducer.class);
...
job.waitForCompletion(true);
Shuffling和Sorting
在Map阶段之后和Reduce阶段之前,存在一个被称为Shuffling和Sorting的关键步骤。在这一步中,来自不同Mapper的输出会被集中、排序并分组,以便发送给特定的Reducer。
# 伪代码:Shuffling的简化表示
cat mapper-output-* | sort | group-by-key
数据局部性和优化
为了提高作业的执行效率,MapReduce实现了多种优化技术,其中最重要的一项就是数据局部性。通过将计算任务发送到存储有相应数据分片的节点,MapReduce尽量减少了网络传输的延迟和带宽消耗。
// Java代码:使用Hadoop API设置数据局部性优先级
job.setInputFormatClass(InputFormatWithLocality.class);
容错与恢复
在一个大规模分布式系统中,节点故障是无法避免的。MapReduce通过任务重试和数据备份等机制,确保了作业的高可用性和数据的完整性。
# 伪代码:当一个Mapper任务失败时,重新调度该任务
if mapper_task.status == FAILED:
reschedule(mapper_task)
以上内容详细解释了MapReduce的工作原理,从数据准备、任务调度,到数据处理和优化,每个步骤都有其特定的逻辑和考量。理解这些内部机制不仅有助于更有效地使用MapReduce,还能在遇到问题时提供更多的解决方案。
四、MapReduce编程模型
MapReduce编程模型是理解和有效利用这一框架的基础。本节将从编程接口、设计模式,到最佳实践等方面,深入探讨如何通过编程实现MapReduce。
编程接口
MapReduce提供了一组简单的编程接口,通常包括一个Mapper类和一个Reducer类,以及它们各自的map和reduce方法。
Mapper接口
// Java:定义一个Mapper
public class MyMapper extends Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public void map(KEYIN key, VALUEIN value, Context context) {
// 实现map逻辑
}
}
Reducer接口
// Java:定义一个Reducer
public class MyReducer extends Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public void reduce(KEYIN key, Iterable<VALUEIN> values, Context context) {
// 实现reduce逻辑
}
}
常见设计模式
MapReduce框架虽然简单,但其支持多种设计模式,可以解决各种复杂的数据处理问题。
计数器模式(Counting Pattern)
// Java:使用MapReduce进行数据计数
public void map(LongWritable key, Text value, Context context) {
context.getCounter("Stats", "ProcessedRecords").increment(1);
}
聚合模式(Aggregation Pattern)
// Java:使用Reduce阶段进行数据聚合
public void reduce(Text key, Iterable<IntWritable> values, Context context) {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
最佳实践
编程不仅仅是按照规范进行操作,还需要根据经验和场景选择最佳实践。
选择合适的数据结构
例如,选择适当的数据结构如ArrayWritable或者MapWritable可以显著提高性能。
// Java:使用MapWritable存储中间结果
MapWritable intermediateResult = new MapWritable();
优化Shuffle过程
通过合理设置Partitioner和Combiner,你可以显著减少Shuffle阶段的数据传输量。
// Java:自定义Partitioner
public class MyPartitioner extends Partitioner<KEY, VALUE> {
@Override
public int getPartition(KEY key, VALUE value, int numPartitions) {
// 自定义逻辑
}
}
这一节详尽地介绍了MapReduce的编程模型,包括其核心接口、常见设计模式和最佳实践。通过结合代码示例,本节旨在帮助读者更有效地进行MapReduce编程,进而解决实际问题。
五、实战应用
理论知识和编程模型的理解固然重要,但仅有这些还不足以让我们全面掌握MapReduce。本节将通过几个典型的实战应用案例,展示如何将MapReduce应用到实际问题中。
文本分析
文本分析是MapReduce应用中较为常见的一个场景。通过MapReduce,我们可以高效地进行词频统计、倒排索引等操作。
词频统计
// Java:词频统计的Mapper
public void map(Object key, Text value, Context context) {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
倒排索引
// Java:倒排索引的Reducer
public void reduce(Text key, Iterable<Text> values, Context context) {
for (Text val : values) {
indexList.add(val.toString());
}
context.write(key, new Text(StringUtils.join(indexList, ",")));
}
网络分析
网络数据也是一个应用MapReduce的热点领域。例如,通过MapReduce你可以分析社交网络中的用户互动。
PageRank算法
// Java:PageRank的Reducer
public void reduce(Text key, Iterable<PageRankNodeWritable> values, Context context) {
// 实现PageRank逻辑
}
机器学习
MapReduce也常用于处理大规模的机器学习任务,如分类、聚类等。
k-means聚类
// Java:k-means的Mapper
public void map(LongWritable key, VectorWritable value, Context context) {
// 实现k-means逻辑
}
最佳实践与优化
在进行实战应用时,也需要考虑一些最佳实践和优化手段。
数据倾斜处理
数据倾斜可能会严重影响MapReduce的性能。一种解决方案是使用二次排序或者自定义Partitioner。
// Java:自定义Partitioner来解决数据倾斜
public class SkewAwarePartitioner extends Partitioner<KEY, VALUE> {
// 实现自定义逻辑
}
本节通过多个实战应用案例,展示了MapReduce如何解决实际问题。我们讨论了文本分析、网络分析和机器学习等多个应用领域,每个案例都配有具体的代码示例,旨在帮助你更全面地了解MapReduce的实用性和强大功能。
六、性能优化
理解MapReduce的基础和实战应用是第一步,但在生产环境中,性能优化是不可或缺的。本节将详细探讨如何优化MapReduce作业以达到更高的性能。
数据局部性
数据局部性是提高MapReduce性能的关键之一。
数据分布与节点选择
通过合理地安排数据和计算节点,你可以最小化数据传输延迟。
// Java:设置InputSplit以优化数据局部性
FileInputFormat.setInputPaths(job, new Path(inputPath));
Shuffle和Sort优化
Shuffle阶段往往是性能瓶颈,以下是一些优化手段。
Combiner的使用
使用Combiner可以减少Map和Reduce之间的数据传输。
// Java:设置Combiner
job.setCombinerClass(MyCombiner.class);
自定义Partitioner
通过自定义Partitioner,你可以控制数据的分布。
// Java:设置自定义Partitioner
job.setPartitionerClass(MyPartitioner.class);
计算优化
除了数据和Shuffle阶段,直接的计算优化也是非常重要的。
循环和算法优化
选择合适的数据结构和算法,避免不必要的循环。
// Java:使用HashSet而非ArrayList进行查找,以提高速度
HashSet<String> myHashSet = new HashSet<>();
并行度调整
合理地设置Map和Reduce的并行度也是优化的一个方面。
// Java:设置Map和Reduce的并行度
job.setNumMapTasks(20);
job.setNumReduceTasks(10);
资源配置
合适的资源配置可以显著影响性能。
内存设置
通过设置更多的内存,你可以减少垃圾回收的影响。
# 设置Map和Reduce的Java堆大小
export HADOOP_HEAPSIZE=2048
本节涵盖了性能优化的多个方面,包括数据局部性、Shuffle和Sort优化、计算优化和资源配置等。每个小节都有具体的代码和配置示例,以助于你在实践中快速应用这些优化策略。
七、总结
经过前面的多个章节的深入探讨,我们不仅理解了MapReduce的基础概念和工作原理,还探索了其在实际应用中的多样性和灵活性。更重要的是,我们还对如何优化MapReduce作业性能有了深入的了解。
数据是核心,但优化是关键:虽然MapReduce以其强大的数据处理能力著称,但优化性能的重要性不可低估。通过合理的数据局部性、Shuffle优化和资源配置,甚至可以在大数据环境下实现接近实时的处理速度。
不仅仅是“Map”和“Reduce”:初学者可能会误以为MapReduce仅仅是一种简单的编程模型,然而其背后的设计理念和应用场景远比表面上看到的要复杂得多。例如,在机器学习和网络分析等领域,MapReduce也有广泛的应用。
拓展性和通用性的平衡:MapReduce在设计之初就兼顾了拓展性和通用性,但这并不意味着它是万能的。对于某些特定的应用场景,可能还需要其他并行计算框架或者数据存储方案来配合。
开源生态的重要性:MapReduce的成功在很大程度上得益于其强大的开源生态。这一点不仅降低了技术门槛,也极大地促进了该技术的快速发展和普及。
关注【TechLeadCloud】,分享互联网架构、云服务技术的全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
大数据 - MapReduce:从原理到实战的全面指南的更多相关文章
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- 大数据学习笔记——Hadoop编程实战之Mapreduce
Hadoop编程实战——Mapreduce基本功能实现 此篇博客承接上一篇总结的HDFS编程实战,将会详细地对mapreduce的各种数据分析功能进行一个整理,由于实际工作中并不会过多地涉及原理,因此 ...
- 大数据 --> MapReduce原理与设计思想
MapReduce原理与设计思想 简单解释 MapReduce 算法 一个有趣的例子:你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃? MapReduce方法则是: 给在座 ...
- 大数据高并发系统架构实战方案(LVS负载均衡、Nginx、共享存储、海量数据、队列缓存)
课程简介: 随着互联网的发展,高并发.大数据量的网站要求越来越高.而这些高要求都是基础的技术和细节组合而成的.本课程就从实际案例出发给大家原景重现高并发架构常用技术点及详细演练. 通过该课程的学习,普 ...
- 《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门.概念.原理.实战.性能调优.系统案例的讲解. 专栏介绍 扫码下面专栏二维码可以订阅该专栏 首发地址:http://www.54tianzhisheng. ...
- 我要进大厂之大数据MapReduce知识点(2)
01 我们一起学大数据 今天老刘分享的是MapReduce知识点的第二部分,在第一部分中基本把MapReduce的工作流程讲述清楚了,现在就是对MapReduce零零散散的知识点进行总结,这次的内容大 ...
- 我要进大厂之大数据MapReduce知识点(1)
01 我们一起学大数据 老刘今天分享的是大数据Hadoop框架中的分布式计算MapReduce模块,MapReduce知识点有很多,大家需要耐心看,用心记,这次先分享出MapReduce的第一部分.老 ...
- 大数据之 ZooKeeper原理及其在Hadoop和HBase中的应用
ZooKeeper是一个开源的分布式协调服务,由雅虎创建,是Google Chubby的开源实现.分布式应用程序可以基于ZooKeeper实现诸如数据发布/订阅.负载均衡.命名服务.分布式协调/通知. ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据mapreduce俩表join之python实现
二次排序 在Hadoop中,默认情况下是按照key进行排序,如果要按照value进行排序怎么办?即:对于同一个key,reduce函数接收到的value list是按照value排序的.这种应用需求在 ...
随机推荐
- UI通过元素定位实现特定区域截图
最近计划做一个自动截图的工具,目的是实现性能测试资源监控平台(grafana)各硬件资源的自动截图,解放手工操作.前期的截图做了如下探索. 1. 整个页面截图 1.1 代码实现 通过save_scre ...
- Java不能操作内存?Unsafe了解一下
前言 C++可以动态的分类内存(但是得主动释放内存,避免内存泄漏),而java并不能这样,java的内存分配和垃圾回收统一由JVM管理,是不是java就不能操作内存呢?当然有其他办法可以操作内存,接下 ...
- 三维模型OSGB格式轻量化技术在大规模场景的加载和渲染的作用分析
三维模型OSGB格式轻量化技术在大规模场景的加载和渲染的作用分析 在移动设备上,大规模场景的加载和渲染是一个不容忽视的问题.对于OSGB格式轻量化处理来说,大规模场景的加载和渲染也是其中一项重要的任务 ...
- DesignPattern-part1
title: "modern C++ DesignPattern-Part1" date: 2018-04-03T16:06:33+08:00 lastmod: 2018-04-0 ...
- ATtiny88初体验(七):TWI
ATtiny88初体验(七):TWI TWI模块介绍 ATtiny88的TWI模块兼容Phillips I2C以及SMBus,支持主从模式,支持7bit地址,最大允许128个不同的从机地址.在多主机模 ...
- Solution -「营业」「ABC 170D」Not Divisible
Description Link. 给出一个长度为 \(n\) 的序列 \(a\),求 \(\sum_{i=1}^{n}[\forall j\in[1,i)\cup(i,n],a_{j}\nmid a ...
- c语言代码练习1
//输出1-n阶乘的和,n为输入值//计算n的阶乘可以使用for循环,也可使用while循环#define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h ...
- 记录一次gcc的编译
在deepin23上编译gcc13.2 deepin20素以软件版本过老被人诟病,换成最新的deepin23之后情况大有好转,但是gcc版本为11.2,鄙人对此仍有意见,所以特意研究了如何编译一份较新 ...
- VS Code代码提示( AcWing算法模板,C++实现)
算法模板提取于AcWing上的代码提示 作者:yxc 链接:https://www.acwing.com/file_system/file/content/whole/index/content/21 ...
- PostgreSQL学习笔记-1.基础知识:创建、删除数据库和表格
PostgreSQL 创建数据库 PostgreSQL 创建数据库可以用以下三种方式:1.使用 CREATE DATABASE SQL 语句来创建.2.使用 createdb 命令来创建.3.使用 p ...