PyTorch显存机制分析——显存碎片问题
参考前文:
https://www.cnblogs.com/devilmaycry812839668/p/15578068.html
====================================
从前文我们知道pytorch中是分层进行管理显存的,最小的管理单位是512B,然后上一层是2MB,那么如果我们按照这个原理写一个碎片化的显存分配,就可以实现2GB数据占4GB的显存空间的操作。
现有显存:

运行代码:
import torch
import time device = "cuda:0" tensor_ = torch.randn(5*256*1024*1024, device=device)
print(torch.cuda.memory_summary())
time.sleep(60000)
申请5G显存,报错:

更改代码:
import torch
import time device = "cuda:0" tensor_ = torch.randn(4*256*1024*1024, device=device)
print(torch.cuda.memory_summary())
time.sleep(60000)

可以成功运行:

说明当前显卡可以成功分配4G显存,5G显存则不够分配。
执行大量的小显存分配:
import torch
import time device = "cuda:0"
data = [] for _ in range(1024*1024*4):
data.append(torch.randn(128+1, device=device)) # tensor_ = torch.randn(4*256*1024*1024, device=device)
print(torch.cuda.memory_summary())
time.sleep(60000)
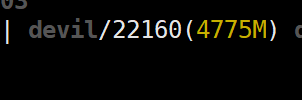
可以看到实际给tensor分配的显存空间为4GB,
那么我们的tensor的实际大小为:4*1024*1024*129*4=2164260864=2.015625GB,
但是实际分配的显存为4*1024*1024*512*2=4294967296=4GB,
其中的原因就是pytorch中显存的最小分配单位是512B,pytorch分配显存时如果存在有以前分配512B的空间没有填满的情况,这时如果又一次分配显存时不能在现有所有的未填满的512B显存中全部装下就会重新分配新的512B显存,这是分配显存的对齐方式。
上面代码中128个float32大小为512B,刚好填满一个最小显存分配单元,这时再分配一个float32大小为4B,则需要重新分配一个512B大小的显存,然后再下一次分配512B大小显存,但是上次分配显存单元中虽然还剩512-4=508B大小,但是不足以装下需要分配的512B大小显存,于是就需要重新分配一个512B大小的显存,那么上一块512大小显存空间中508B大小的空间就空下来了。
采用上面的分配方式如果再申请一个1G连续空间的显存,那么情况如何呢?
代码:
import torch
import time device = "cuda:0"
data = [] for _ in range(1024*1024*4):
data.append(torch.randn(128+1, device=device)) tensor_ = torch.randn(1*256*1024*1024, device=device)
print(torch.cuda.memory_summary())
time.sleep(60000)

显示显存不够无法分配。
如果把1GB连续大显存空间变成256*1024*1024个4B小显存分配呢?
代码:
import torch
import time device = "cuda:0"
data = [] for _ in range(1024*1024*4):
data.append(torch.randn(128+1, device=device)) # tensor_ = torch.randn(1*256*1024*1024, device=device)
for _ in range(1*256*1024*1024):
data.append(torch.randn(1, device=device)) print(torch.cuda.memory_summary())
time.sleep(60000)
依然报错:

由此我们可以大胆猜测pytorch在分配显存时最小分配单元512B大小空间中只有在连续分配时才会对未填满空间进行填充,为此补充一次测试:
import torch
import time device = "cuda:0"
data = [] for _ in range(1024*1024*4*129):
data.append(torch.randn(1, device=device)) # tensor_ = torch.randn(1*256*1024*1024, device=device)
# for _ in range(1*256*1024*1024):
# data.append(torch.randn(1, device=device)) print(torch.cuda.memory_summary())
time.sleep(60000)

结果显示我们上面的猜测是不对的,也就是说最小分配单元512B大小的空间如果一次没有填满那么以后则不再对这部分空间进行填充。
再次进行补充测试;
import torch
import time device = "cuda:0"
data = [] for _ in range(4*1024*1024*2):
data.append(torch.randn(1, device=device)) # tensor_ = torch.randn(1*256*1024*1024, device=device)
# for _ in range(1*256*1024*1024):
# data.append(torch.randn(1, device=device)) print(torch.cuda.memory_summary())
time.sleep(60000)

成功运行,由此我们基本可以得出结论,512B最小分配单元必须一次性进行填充,即使是没有填充满在下一次申请空间时也不可以使用为填满的512B最小分配单元中的空余空间,而上一层的分配空间2MB里面有2*1024=2048个最小分配单元,2MB空间内的这2048个空间是可以进行连续填充的,比如第一次分配显存使用掉了2048个最小分配单元中的100个,那么下次分配显存可以从第101个512B大小的最小分配单元开始。那么这2MB空间是否会存在对齐问题呢?
如果每次分配2MB空间,共分配4GB空间,运行如下:
import torch
import time device = "cuda:0"
data = [] for _ in range(2*1024):
data.append(torch.randn(128*2*1024*2, device=device))
# data.append(torch.randn(128*2*1024+1, device=device)) print(torch.cuda.memory_summary())
time.sleep(60000)

如果2MB空间中存在未填满的情况,而下一次的申请空间又大于未填满的空间,那么会不会对未填满的显存空间进行填充呢?
再次测试:
代码:
import torch
import time device = "cuda:0"
data = [] for _ in range(2*1024):
# data.append(torch.randn(128*2*1024*2, device=device))
data.append(torch.randn(128*2*1024+1, device=device)) print(torch.cuda.memory_summary())
time.sleep(60000)

可以看到只有最小分配单元512B空间是不能再次填充的,2MB空间内的4096个最小空间是不仅可以再次填充而且如果剩余空间不够是可以一段内存跨多个2MB空间的。
总结的说就是512B空间是只进行一次分配,不允许多个变量使用这512B空间,即使一个变量是1个float32,4B大小那么也是分配给512B空间的,这时再为另一个变量事情1个float32,4B大小也是不能利用上个空闲的508B大小而是需要重新申请一个512B空间的。同时,2MB空间可以为多个变量进行分配。
2MB大小的显存空间是pytorch向系统一次申请的最小显存空间,512B大小显存时pytorch为变量分配的最小显存空间。
==============================================
PyTorch显存机制分析——显存碎片问题的更多相关文章
- Android内存机制分析1——了解Android堆和栈
//----------------------------------------------------------------------------------- Android内存机制分析1 ...
- Linux内核态抢占机制分析(转)
Linux内核态抢占机制分析 http://blog.sina.com.cn/s/blog_502c8cc401012pxj.html 摘 要]本文首先介绍非抢占式内核(Non-Preemptive ...
- Linux内核抢占实现机制分析【转】
Linux内核抢占实现机制分析 转自:http://blog.chinaunix.net/uid-24227137-id-3050754.html [摘要]本文详解了Linux内核抢占实现机制.首先介 ...
- 浩瀚技术团队... 安卓智能POS移动PDA开单器 开单器 进销存系统 进销存系统
浩瀚技术团队... 智能POS移动PDA开单器 开单器 进销存系统 进销存系统 点餐 会员管理 会员管理 深度解读 手机APP移动办公到底是什么? 快速打单POS·不仅仅是快那么简单!
- Linux mips64r2 PCI中断路由机制分析
Linux mips64r2 PCI中断路由机制分析 本文主要分析mips64r2 PCI设备中断路由原理和irq号分配实现方法,并尝试回答如下问题: PCI设备驱动中断注册(request_irq) ...
- IOS Table中Cell的重用reuse机制分析
IOS Table中Cell的重用reuse机制分析 技术交流新QQ群:414971585 创建UITableViewController子类的实例后,IDE生成的代码中有如下段落: - (UITab ...
- 您还有心跳吗?超时机制分析(java)
注:本人是原作者,首发于并发编程网(您还有心跳吗?超时机制分析),此文结合那里的留言作了一些修改. 问题描述 在C/S模式中,有时我们会长时间保持一个连接,以避免频繁地建立连接,但同时,一般会有一个超 ...
- Java 类反射机制分析
Java 类反射机制分析 一.反射的概念及在Java中的类反射 反射主要是指程序可以访问.检测和修改它本身状态或行为的一种能力.在计算机科学领域,反射是一类应用,它们能够自描述和自控制.这类应用通过某 ...
- Linux信号(signal) 机制分析
Linux信号(signal) 机制分析 [摘要]本文分析了Linux内核对于信号的实现机制和应用层的相关处理.首先介绍了软中断信号的本质及信号的两种不同分类方法尤其是不可靠信号的原理.接着分析了内核 ...
- Java 动态代理机制分析及扩展
Java 动态代理机制分析及扩展,第 1 部分 王 忠平, 软件工程师, IBM 何 平, 软件工程师, IBM 简介: 本文通过分析 Java 动态代理的机制和特点,解读动态代理类的源代码,并且模拟 ...
随机推荐
- 【译】Visual Studio 17.10 发布了新版扩展管理器
我们将更新的扩展管理器带给所有用户!在过去的一年里,我们已经将更新后的扩展管理器作为可选的预览功能提供,并一直期待您的反馈.基于您令人难以置信的反馈,我们现在准备从 Visual Studio 17. ...
- Kubernetes监控手册06-监控APIServer
写在前面 如果是用的公有云托管的 Kubernetes 集群,控制面的组件都交由云厂商托管的,那作为客户的我们就省事了,基本不用操心 APIServer 的运维.个人也推荐使用云厂商这个服务,毕竟 K ...
- CSS和CSS3(背景,图片,浮动等)
CSS和CSS3背景图片 CSS的背景,无法伸缩图片. <!DOCTYPE html> <html lang="en"> <head> < ...
- python基础-集合set { }
集合的定义和操作 集合的特性: 元素数量 支持多个 元素类型 任意 下标索引 支持 重复元素 不支持 可修改性 支持 数据有序 否 使用场景 不可重复的数据记录场景 # 定义集合 my_set = { ...
- ElasticSearch不区分字母大小写搜索
0.停止使用该索引的服务(避免新加了数据没备份) 1.备份filesearch索引(检查备份的索引和原索引数据条数是否一致) 1 POST http://127.0.0.1:9200/_reindex ...
- Vue手稿4
- mac idea代码颜色修改、主题
下载样式包 下载样式 网址一:http://www.riaway.com/ 网址二:http://www.themesmap.com/theme.html?t=down 我使用的这几款 链接: htt ...
- Spring里面bean的依赖和继承
继承 bean继承:两个类之间大多数的属性都相同,避免重复配置,通过bean标签的parent属性重用已有的Bean元素的配置信息 继承指的是配置信息的复用,和java类的继承没有关系 video.j ...
- yolov5+deepsort+slowfast复现
1.运行环境 ubuntu 18.04.1 Cuda 11.5 Python 3.8.15 torch 1.10.1+cu113 torchvision 0.11.2+cu113 2.安装PyTorc ...
- VBA | 统计数组某元素出现的次数,适用于一维、二维数组
很简单的需求,但是中文网络上基本都是循环的方法,经过查找下面的方法很有效.为了方便用户的使用,进行了如下的整改. 1 Sub Statistics_Number_of_occurrences_test ...