tarjan—算法的神(一)
本篇包含 tarjan 求强连通分量、边双连通分量、割点 部分,
tarjan 求点双连通分量、桥(割边)在下一篇。
伟大的 Robert Tarjan 创造了众多被人们所熟知的算法及数据结构,最著名的如:(本文的)连通性相关的 tarjan 算法,Splay-Tree,Toptree,tarjan 求 lca 等等。
注:有向图的强连通分量、无向图的双连通分量、tarjan 求最近公共祖先 被称为 tarjan 三大算法。
所以在本篇博客开篇,%%% Tarjan Dalao.
基础概念:
强连通分量:
对于一个有向图 G,存在一个子图使得从该子图中每个点出发都可以到达该子图中任意一点,则称此子图为 G 的强连通分量。特别的,一个点也是一个强连通分量。
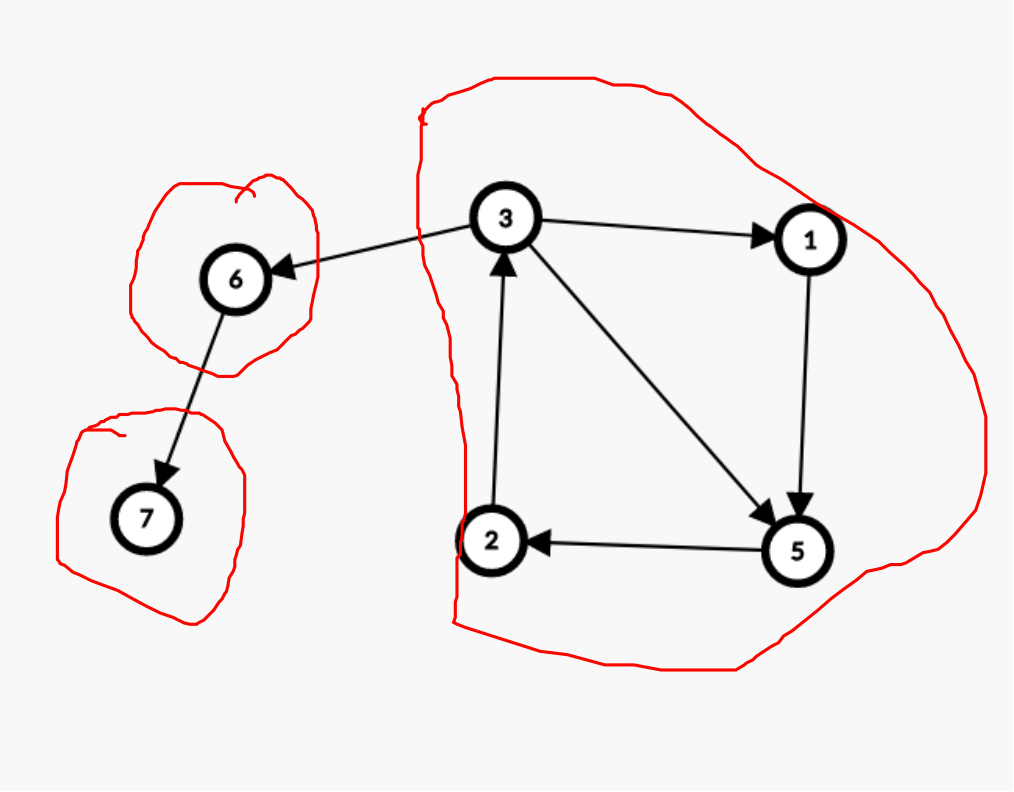
如下图红框部分都是强连通分量:(显然,红框中的点 1、2、3、5 可以互相到达)
割点:
对于一个无向连通图 G,若去除 G 中的一个节点 u,并删去与该节点相连的所有边后,G 变得不再连通,则称该点 u 为割点。
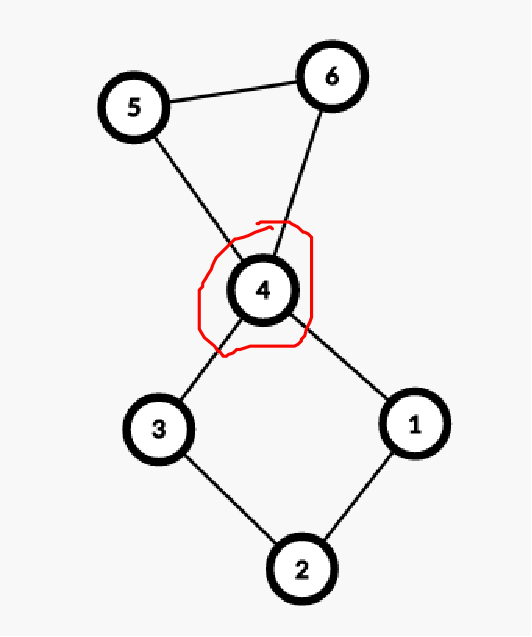
如下图标红的 4 号点就是割点:
割边(桥):
在一个连通分量中,如果删除某一条边,会把这个连通分量分成两个连通分量,那么这个边称为割边(桥)。
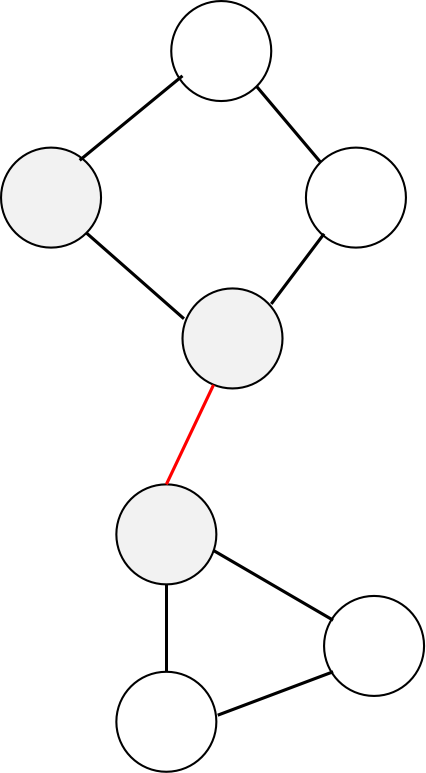
如此图中的红边
点/边双连通分量:
若一个无向图中的去掉任意一个节点(一条边)都不会改变此图的连通性,即不存在割点(桥),则称作点(边)双连通图。分别简称点双、边双。
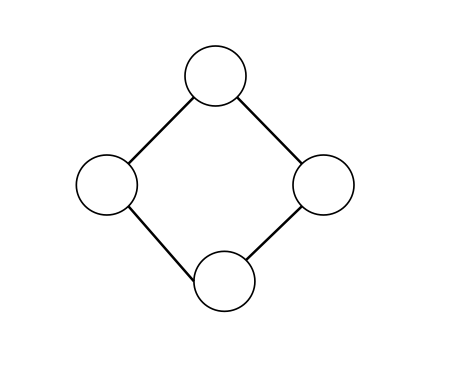
此图既是一个点双又是边双(显然它不含割点也不含桥):
前置知识:
建议先自行了解
dfs 生成树
图片摘自oi-wiki

邻接链表
存边方式,自行学习(
tarjan 求强连通分量(必看):
需要维护两个数组:
\(dfn_i\):表示 \(i\) 这个点的 dfs 序(即深度优先搜索遍历时点 \(i\) 被搜索的次序)
\(low_i\):表示从以点 \(i\) 为根节点的子树中任意一点通过一条返祖边能到达的节点的最小值
算法思路:
维护一个栈,存目前正在找的强连通分量的节点。
对图的每个节点进行深度优先搜索,同时维护每个点的 \(low、dfn\) 值,每次搜索到一个点将其加入到栈中。每当找到一个强连通元素(如果一个点的 \(low\) 值和 \(dfn\) 值相等,我们称这个点为强连通元素)时,其实便找全了一个强连通分量。
思路分析(难懂疑问):
- 如何更新 \(low\) 值?
对于搜索过程中搜到的的点 \(u\) 和它连向的点 \(v\),有以下三种情况:
1 . 点 \(v\) 还未被访问:此时我们继续对 \(v\) 进行搜索。在回溯过程中用 \(low_v\) 更新 \(low_u\)。 因为 \(v\) 的子树中的点其实也就是 \(u\) 的子树中点,那么 \(v\) 子树中一个点能到达 \(x\) 点,即为 \(u\) 子树中的点到达了 \(x\) 点。
2 . 点 \(v\) 被访问过并且已经在栈中:(即在当前强连通分量中),被访问过说明 \(v\) 在搜索树中是 \(u\) 的祖先节点,那么从 \(u\) 走到 \(v\) 的边便是我们更新 \(low\) 要用的那条返祖边,所以用 \(dfn_v\) 值更新 \(low_u\);
3 . 点 \(v\) 被访问过但不在栈中:说明该点所在强连通分量已经被找到了,且该点不在现在正找的强连通分量里,那么不用进行操作。
- 为什么找到强联通元素的时候当前的就找全了一个强连通分量呢?
我们知道强联通元素 \(x\) 有 \(low_x = dfn_x\),说明以 \(x\) 为根的子树中所有点都到达不了 \(x\) 之前的(同一强连通分量中的)点,那么 \(x\) 便是该强连通分量的“起点”。
根据栈先进后出的性质,可以知道栈中从 \(x\) 到栈顶的点都是 \(x\) 子树内的点,并且是和 \(x\) 属于同一个强连通分量的。那么找到 \(x\) 这个强连通元素后,栈中从 \(x\) 到栈顶所有点(这些点是当前的强连通分量中的点)取出即可。
伪代码:
tarjan(点 x){
low[x] = dfn[x] = ++th; // 更新 dfs 序
把 x 入栈;
for(枚举 x 相邻的点 y){
if(y 未被搜索过){
tarjan(y);
low[x] = min(low[x], low[y]);
}
if(y 被搜索过且已在栈中){
low[x] = min(low[x], dfn[y]);
}
}
if(x 为强连通元素){
scc++; //scc 为强连通分量个数
将栈中元素从 x 到栈顶依次取出;
}
}
算法演示:
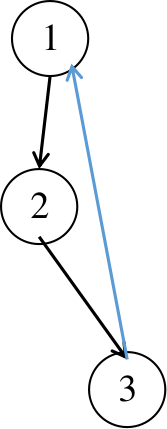
黑边为树边,蓝边为返祖边;
在此连通图中,我们以 1 号点为根进行 dfs,所有点的标号即为它们的 dfs 序:
我们从 1 开始 dfs,把 1 加进栈中,找到 1 相邻的点 2,发现 2 还未被搜索过,那么递归 dfs 2;
把 2 加进栈中,找到与 2 相邻的点 3,3 同样未被搜索,再递归搜索 3;
同样把 3 加进栈中,发现 3 相邻的点 1 已经被搜索过且在已在栈中,那么从 3 到 1 这条边就是一条返祖边,用 \(dfn_1\) 更新 \(low_3\),回溯;
回溯过程中,分别用 \(low_3\) 更新 \(low_2\), \(low_2\) 更新 \(low_1\)。
回溯到 1 号节点时,有 \(low_1 = dfn_1\),所以 1 号节点为强连通元素,那么栈中从 1 到栈顶所有元素即为一个强连通分量。
算法代码:
int th, top, scc; //分别表示 dfs 的时间戳、栈顶、强连通分量个数
int s[N], ins[N]; //s 为手写栈,ins[i] 表示 i 这个点是否在栈中
int low[N], dfn[N], belong[N]; //belong[i] 表示 i 这个点所属的强连通分量的标号
void tarjan(int x){
low[x] = dfn[x] = ++th;
s[++top] = x, ins[x] = true;
for(int i=head[x]; i; i=nxt[i]){ //链式前向星存边
int y = to[i];
if(!dfn[y]){ //若 y 还没被搜索过
tarjan(y); // 搜索 y
low[x] = min(low[x], low[y]);
}
else if(ins[y]){ // y 在栈中
low[x] = min(low[x], dfn[y]);
}
}
if(low[x] == dfn[x]){
++scc;
do{ //将栈中从 x 到栈顶所有元素取出
belong[s[top]] = scc;
ins[s[top]] = false;
}while(s[top--] != y);
}
}
但是,大多数题目并不是给定一张联通图,所以一张图可能会分成多个强连通分量,所以主函数中应这样写(来保证每个强连通分量都被跑过 tarjan):
for(int i=1; i<=n; i++)
if(!dfn[i]) tarjan(i);
例题:
不要着急看下面的内容,建议做一两道例题熟悉算法原理和代码后再继续学习。
The Cow Prom S[USACO06JAN](绝对的板子)
板!
信息传递[NOIP2015 提高组]
特殊的最小环问题,因为这个题保证每个点的出度为 1,所以这个题可以用 tarjan 求强连通分量来做,具体可以去看其他题解(比如这个)。
受欢迎的牛[USACO03FALL / HAOI2006]
缩点的思想,但很好理解,求出强联通分量,把每个强连通分量看做一个大点,计算每个大点的出度,若有一个出度为 0 的大点,则这个大点包含的所有奶牛都为明星牛;若有两个及以上出度为 0 的大点(则这些大点里的爱慕都无法传播出去)就 G 了,便不存在明星牛。
具体实现看代码吧
#include<bits/stdc++.h>
using namespace std;
const int N = 2e5 + 10;
int n, m, out[N];
int low[N], dfn[N], ins[N], th;
int s[N], belong[N], top, scc, size[N];
int head[N], to[N], nxt[N], tot;
void addedge(int x, int y){
to[++tot] = y;
nxt[tot] = head[x];
head[x] = tot;
}
void tarjan(int x){
low[x] = dfn[x] = ++th;
s[++top] = x, ins[x] = true;
for(int i=head[x]; i; i=nxt[i]){
int y = to[i];
if(!dfn[y]){
tarjan(y);
low[x] = min(low[x], low[y]);
}
else if(ins[y]){
low[x] = min(low[x], dfn[y]);
}
}
if(low[x] == dfn[x]){
++scc;
do{
size[scc]++;
belong[s[top]] = scc;
ins[s[top]] = false;
}while(s[top--] != x);
}
}
int main(){
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
cin>>n>>m;
for(int i=1; i<=m; i++){
int x, y; cin>>x>>y;
addedge(x, y);
}
for(int i=1; i<=n; i++){
if(!dfn[i]) tarjan(i);
}
for(int i=1; i<=n; i++){
for(int j=head[i]; j; j=nxt[j]){
int y = to[j];
if(belong[i] != belong[y]) out[belong[i]]++;
}
}
int cnt = 0, ans = 0;
for(int i=1; i<=scc; i++){
if(out[i]) continue;
cnt++;
if(cnt > 1){cout<<0; return 0;}
ans = size[i];
}
cout<<ans;
return 0;
}
tarjan 求边双连通分量
有一种实现是先跑出割桥再找边双,本篇不对此方法进行介绍。
其实我们可以发现边双连通分量就是强连通分量搞到无向图中,求边双的思路也和强连通分量一样。(看代码理解即可,非常简单)
和强连通分量的不同之处在代码中标出了。
算法代码:
void tarjan(int x, int p){
low[x] = dfn[x] = ++th;
s[++top] = x, ins[x] = true;
for(int i=head[x]; i; i=nxt[i]){
int y = to[i];
if(y == p) continue;//因为双向边所以搜索时加个判父亲节点
if(!dfn[y]){
tarjan(y, x);
low[x] = min(low[x], low[y]);
}
else low[x] = min(low[x], dfn[y]);
//因为在无向图中,所以若 y 已经被搜索过则一定是 x 的祖先,不用再判 ins
}
if(dfn[x] == low[x]){
++scc;
do{
belong[s[top]] = scc;
SCC[scc].emplace_back(s[top]); //将边双存起来,可根据题目需要选择写这句话
}while(s[top--] != x);
}
}
但注意题目要求,有时题目可能会有重边时,搜索过程中就不能只特判父亲节点,而是应该记一下边的编号判边。因为有重边的话是可以回到父亲节点的。
例题:
【模板】边双联通分量
板子题,但注意题目可能会有重边,所以需要记一下边防止走“回头路”。
看代码就知道了
#include <bits/stdc++.h>
using namespace std;
const int N = 5e6 + 10;
int n, m, top, th, cnt;
int s[N], low[N], dfn[N], id[N];
int tot, head[N], to[N], nxt[N];
vector<vector<int> >ans;
inline void addedge(int x, int y){
to[++tot] = y;
nxt[tot] = head[x];
head[x] = tot;
id[tot] = cnt; //id 来记一下边的编号
}
inline void tarjan(int x, int p){
low[x] = dfn[x] = ++th;
s[++top] = x;
for(int i=head[x]; i; i=nxt[i]){
int y(to[i]), edge = id[i];
if(edge == p) continue; //解决重边问题
if(!dfn[y]){
tarjan(y, edge);
low[x] = min(low[x], low[y]);
}
else low[x] = min(low[x], dfn[y]);
}
if(low[x] == dfn[x]){
vector<int>scc;
do scc.emplace_back(s[top]);
while(s[top--] != x);
ans.emplace_back(scc);
}
}
int main(){
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
cin>>n>>m;
for(int i=1; i<=m; i++){
int x, y; cin>>x>>y;
if(x == y) continue; ++cnt;
addedge(x, y), addedge(y, x);
}
for(int i=1; i<=n; i++)
if(!dfn[i]) tarjan(i, 0);
cout<<ans.size()<<"\n";
for(auto x : ans){
cout<<x.size()<<" ";
for(auto i : x){
cout<<i<<" ";
}
cout<<"\n";
}
return 0;
}
tarjan—算法的神(一)的更多相关文章
- HDOJ迷宫城堡(判断强连通 tarjan算法)
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submission( ...
- tarjan算法讲解。
tarjan算法讲解. 全网最详细tarjan算法讲解,我不敢说别的.反正其他tarjan算法讲解,我看了半天才看懂.我写的这个,读完一遍,发现原来tarjan这么简单! tarjan算法,一个关 ...
- 浅谈Tarjan算法及思想
在有向图G中,如果两个顶点间至少存在一条路径,称两个顶点强连通(strongly connected).如果有向图G的每两个顶点都强连通,称G是一个强连通图.非强连通图有向图的极大强连通子图,称为强连 ...
- 图论-强连通分量-Tarjan算法
有关概念: 如果图中两个结点可以相互通达,则称两个结点强连通. 如果有向图G的每两个结点都强连通,称G是一个强连通图. 有向图的极大强连通子图(没有被其他强连通子图包含),称为强连通分量.(这个定义在 ...
- Tarjan算法 详解+心得
Tarjan算法是由Robert Tarjan(罗伯特·塔扬,不知有几位大神读对过这个名字) 发明的求有向图中强连通分量的算法. 预备知识:有向图,强连通. 有向图:由有向边的构成的图.需要注意的是这 ...
- (转)全网最!详!细!tarjan算法讲解
byhttp://www.cnblogs.com/uncle-lu/p/5876729.html 全网最详细tarjan算法讲解,我不敢说别的.反正其他tarjan算法讲解,我看了半天才看懂.我写的这 ...
- [转]全网最!详!细!tarjan算法讲解
转发地址:https://blog.csdn.net/qq_34374664/article/details/77488976 原版的地址好像挂了..... 看到别人总结的很好,自己就偷个懒吧..以下 ...
- 【转载】全网最!详!细!tarjan算法讲解。
转自http://www.cnblogs.com/uncle-lu/p/5876729.html [转载]全网最!详!细!tarjan算法讲解.(已改正一些奥妙重重的小错误^_^) 全网最详细tarj ...
- 全网最!详!细!tarjan算法讲解。——转载自没有后路的路
全网最!详!细!tarjan算法讲解. 全网最详细tarjan算法讲解,我不敢说别的.反正其他tarjan算法讲解,我看了半天才看懂.我写的这个,读完一遍,发现原来tarjan这么简单! tarj ...
- 有向图强连通分量的Tarjan算法
有向图强连通分量的Tarjan算法 [有向图强连通分量] 在有向图G中,如果两个顶点间至少存在一条路径,称两个顶点强连通(strongly connected).如果有向图G的每两个顶点都强连通,称G ...
随机推荐
- 【Playwright+Python】系列教程(五)元素定位
一.常见元素定位 定位器是 Playwright 自动等待和重试能力的核心部分.简而言之,定位器代表了一种随时在页面上查找元素的方法,以下是常用的内置定位器. 1.按角色定位 按显式和隐式可访问性属性 ...
- oeasy教您玩转vim - 77 - # 保留环境viminfo
保留环境viminfo 回忆组合键映射的细节 上次我们定义了session :mks 还可以加载会话session :source Session.vim vim -S Session.vim 基 ...
- 数据仓库建模工具之一——Hive学习第三天
1.Hive的基本操作 1.1 Hive库操作 1.1.1 创建数据库 1)创建一个数据库,数据库在HDFS上的默认存储路径是/hive/warehouse/*.db. create database ...
- 【Java】JDBC Part2 工具类封装实现
JDBC 工具类封装实现 - 注册和配置都放在静态代码块完成 - 静态方法获取连接,和释放资源 - 本类不产生实例 - 5版本 + 已经可以实现无驱动注册,所以驱动部分注释了 package cn.d ...
- 【Oracle】Windows-19C 下载安装
下载 Download 官网下载地址[需要Oracle账号]: https://www.oracle.com/database/technologies/oracle-database-softwar ...
- 【Java,IDEA】使用IDEA自动生成序列化ID
一.设置序列化的原因: 详细见SE的IO流问题: https://www.cnblogs.com/mindzone/p/12752453.html 简单点理解就是对象的身份证号, 对于一些对象被序列之 ...
- 人形机器人专用操作系统 —— KaihongOS还是ROS
机器人不是一个新词汇,机器人在人们生产生活中已经出现了几十年了,而最近最火的词汇是"智能机器人"或者是"人形机器人(humanoid)",而这二者之间的区别就是 ...
- AMiner的数据质量和完善问题
最近参加到了一个国家科技项目中,这里就不吐槽这种高校承接国家科技项目是一件多么不靠谱的事情了,这里就说说我们的对标产品"AMiner".补充一下,虽然个人对AMiner的评价不是很 ...
- 遥遥领先!鲲鹏ARM架构下国产数据同步能力大幅提升16.9倍
在上篇文章<2.6倍!WhaleTunnel客户POC实景对弈DataX>发布之后,一个客户突然向我们控诉其苦DataX久矣,因为是在信创的鲲鹏ARM CPU上运行 ,每天同步需要很长时间 ...
- 01-canvas体验
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="U ...