Pandas从入门到放弃
Pandas简介
Pandas是Panel data(面板数据)和Data analysis(数据分析)的缩写,是基于NumPy的一种工具,故性能更加强劲。Pandas在管理结构数据方面非常方便,其基本功能可以大致概括为一下5类:
- 数据 / 文本文件读取;
- 索引、选取和数据过滤;
- 算法运算和数据对齐;
- 函数应用和映射;
- 重置索引。
这些基本操作都建立在Pandas的基础数据结构之上。Pandas有两大基础数据结构:Series(一维数据结构)和DataFrame(二维数据结构)。
Series、DataFrame及其基本操作
Series 和 DataFrame 是 Pandas 的两个核心数据结构, Series 是一维数据结构,DataFrame 是二维数据结构。 Pandas 是基于 NumPy 构建的,这两大数据结构也为时间序列分析提供了很好的支持。
Series
Series是一个类似于一维数组和字典的结合,类似于Key-Value的结构,Series包括两个部分:index、values,这两部分的基础结构都是ndarray。Series可以实现转置、拼接、迭代等。使用Series之前需要先导入:
import pandas as pd
import numpy as np
(1)创建Series
可以通过以下两种方式创建
# 直接创建
a = pd.Series({'a' : 10, 'b' : 2, 'c' : 3})
a

# 直接创建
b = pd.Series([10, 2, 3], index = ['a', 'b', 'c'])
b

# 从现有数据创建
data = {'first':'hello', 'second':'world', 'third':'!!'}
c = pd.Series(data)
c

(2)访问Series中的元素
可以通过下标,也可以通过类似于字典通过key获取value
a = pd.Series({'a' : 10, 'b' : 10, 'c' : 3})
a[1]#10
a['b']#10
(3)修改索引
a = pd.Series({'a' : 10, 'b' : 2, 'c' : 3})
a.index = ['x', 'y', 'z']
a

(4)拼接不同的Series
a = pd.Series({'a':1, 'b':2, 'c':3})
b = pd.Series([10, 2, 3], index = ['x', 'y', 'z'])
c = pd.concat([a, b])
c
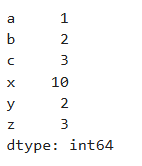
DataFrame
DataFrame是一个类似于Excel表格的数据结构,索引包括行索引和列索引,每列可以是不同的数据类型(String、int、bool、...),DataFrame的每一列(行)都是一个Series,每一列(行)的Series.name即为当前列(或行)索引名。
(1)创建DataFrame
DataFrame是一个二维结构,较为常见的创建方法有:
- 通过二维数组结构创建
- 通过字典创建
- 通过读取既有文件创建
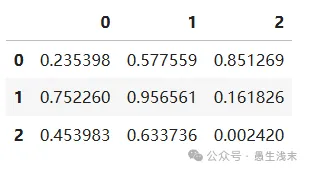
# 不指定行索引、列索引
arr = np.random.rand(3, 3)# 生成一个3x3的随机数矩阵
df = pd.DataFrame(arr)
display(df)
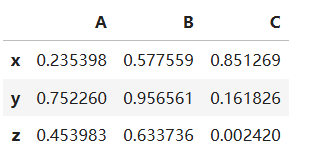
此外,也可以制定行索引和列索引,可以理解城市存储了点A、B、C的三位坐标的一个表。代码如下:
# 指定行索引和列索引
df2 = pd.DataFrame(arr, index=list("xyz"), columns=list("ABC"))
display(df2)
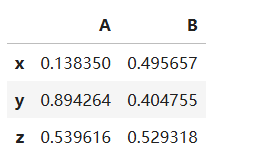
(2)DataFrame的列操作
以前面的df2这一DataFrame变量为例,若希望获取点A的x、y、z坐标,则可以通过三种方法获取:
1、df[列索引];2、df.列索引;3、df.iloc[:, :]
注意:
在使用第一种方式时,获取的永远是列,索引只会被认为是列索引,而不是行索引;相反,第二种方式没有此类限制,故在使用中容易出现问题。第三类方法常用于获取多个列,其返回值也是一个DataFrame。以第三种方式为例:
pos_A = df2.iloc[:, 0] # 选取所有行第0列
pos_A

pos_A = df2.iloc[:, 0:2] # 选取所有行第0列和第1列
pos_A
df2['B'] # 选取单列
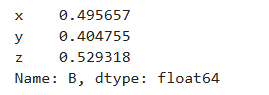
df2[['B','C']] # 选取多列,注意是两个方括号。
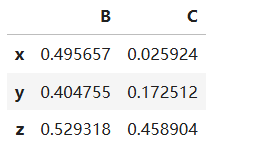
如果想再df2的最后一列加上点D的坐标(1,1,1),可以通过df[列索引]=列数据的方式,代码如下:
df2['D'] = [1, 1, 1]
df2
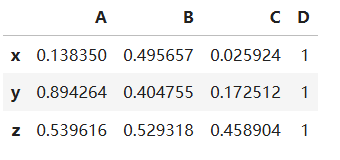
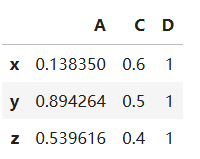
修改C的坐标为(0.6, 0.5, 0.4),并删除点B
df2['C'] = [0.6, 0.5, 0.4]
del df2['B']
df2
(3) DataFrame的行操作
以处理过后的df2为例,若希望获取所有点在x轴上的位置,则可以通过两种方法:
1、df.loc[行标签][列标签];2、df.iloc[:, :]
以第一种方法为例,代码如下:
x = df2.loc['x'] # 选取x行
x
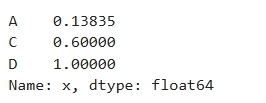
x = df2.loc['x']['A'] # 选取x行A列的数据
x #0.13834995969465658
至此已经了解了df.loc[][]以及df.iloc[],我们可以进行一下对比:
1)使用.iloc访问数据的时候,可以不考虑数据的索引名,只需要知道该数据在整个数据集中的序号即可
2)使用.loc访问数据的时候,需要考虑数据的索引名,通过索引名来获取数据,效果与iloc一致
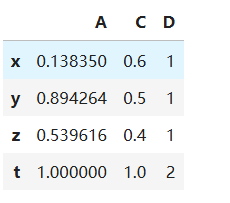
若想给变量再增加一个维度,例如t维度,可以通过append的方法,这个方法会返回一个新的DataFrame,而不会改变原有的DataFrame
t = pd.Series([1, 1, 2], index=list("ACD"), name='t')
df3 = df2.append(t)
#display(df2) # 无变化
df3
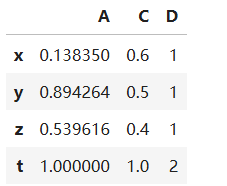
若想删除新增的’t’这一行,可以通过df.drop(行索引,axis)实现,axis默认值为None即删除行,若axis=1,则删除列
df3.drop(['t'])
display(df3)
修改行数据的方法与列相同。
(4)DataFrame 数据查询
数据查询的方法可以分为以下五类:按区间查找、按条件查找、按数值查找、按列表查找、按函数查找。
这里以df.loc方法为例,df.iloc方法类似。先创建一个DataFrame:
arr = np.array([[1, 3, 5], [0, 2, 1], [32, 2, -3]])
df = pd.DataFrame(arr, index=list("abc"), columns=list("xyz"))
df

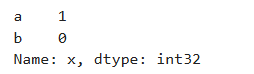
在前面已经调到过如何使用df.loc和df.iloc按照标签值去查询,这里介绍按照区间范围进行查找,例如:获取x轴上a、b的坐标
df.loc['a':'b', 'x'] # {'a':1, 'b':0}
按条件表达式查询,获取位于z轴正半轴的点的数据,代码如下:
df.loc[(df['z'] > 0) & (df['z'] < 2), :]
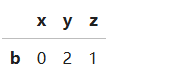
还可以编写lambda函数来查找,获取在x、z轴正半轴的点的数据
df.loc[lambda df : (df['z'] > 0) & (df['x'] > 0)]
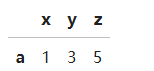
(5)DataFrame数据统计
①数据排序
在处理带时间戳的数据时,如地铁刷卡数据等,有时需要将数据按照时间顺序进行排列,这样数据预处理时能更加方便,或者按照已有的索引给数据进行重新排序,DataFrame提供了这类方法。
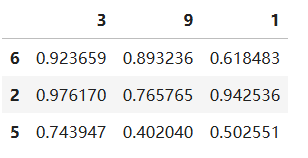
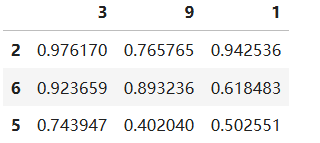
# 创建一个DataFrame
dfs = pd.DataFrame(np.random.random((3, 3)), index=[6, 2, 5], columns=[3, 9, 1])
dfs
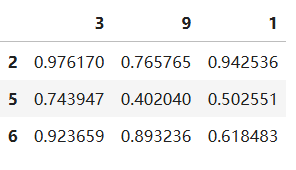
按照索引升序排序,可以通过df.sort_index(axis=0, ascending=True)实现。默认通过行索引,按照升序排序
newdfs1 = dfs.sort_index()
newdfs1
按照值的降序排序,可以通过df.sort_values(列索引, ascending = False)
newdfs2 = dfs.sort_values(3, ascending = False)
newdfs2
②统计指标
通过DataFrame.describe()可以获取整个DataFrame不同类别的各类统计指标,先读取测试文件。
文件:https://gitee.com/kohler19/kohler19/blob/master/Python数据分析/DataSet/test1.CSV
# 读取测试文件
file = pd.read_csv('./test1.CSV')
file
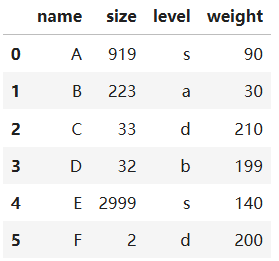
测试完文件记录了A~F 6个物品的大小、等级以及重量。
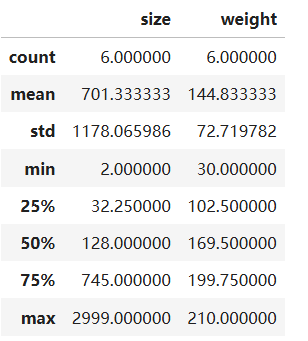
使用file.describe()对所有数字列进行统计,返回值中统计了个数、均值、标准差、最小值、25%-75%分位数、最大值
file.describe()
通过file[].mean()或file[].max()等方法,单独计算某一列某一统计指标
print(file['size'].max()) # 2999
print(file['weight'].mean()) # 144.8333
③ 分类汇总
GroupBy可以将数据按条件进行分类,进行分组索引。以另一个测试文件test2.csv为例。
https://gitee.com/kohler19/kohler19/blob/master/Python数据分析/DataSet/test2.CSV
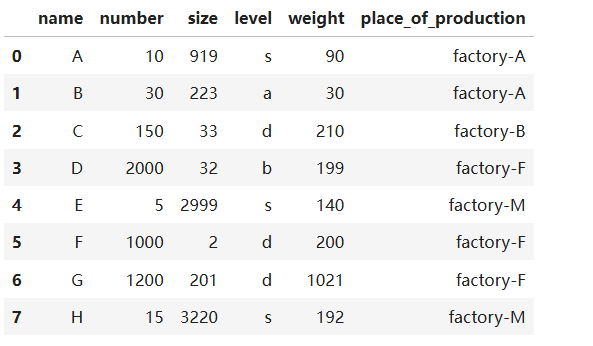
file2 = pd.read_csv('./test2.CSV')
file2
通过GroupBy可以计算目标类别的统计特征,例如按“level”将物品分类,并计算所有数字列的统计特征
file2.groupby('level').describe()

除了对单一列进行分组,也可以对多个列进行分组。
例如对“level”、“place_of_production”两个列同时进行分组,希望看到每个工厂都生成了哪些类别的物品,每个类别的数字特征的均值和求和是多少
df = file2.groupby(['place_of_production','level']).agg([np.mean, np.sum])
df
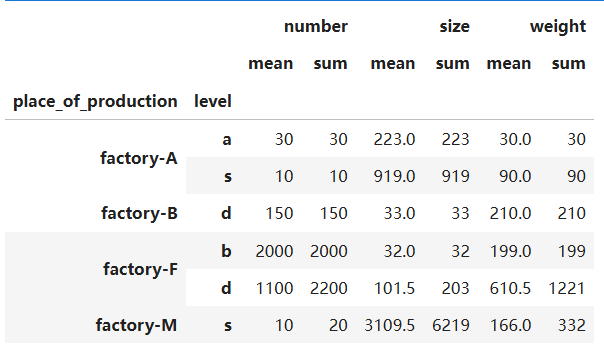
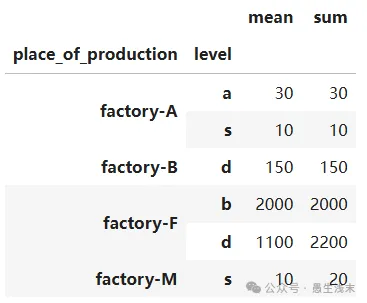
进一步,分析各个工厂生产不同类别商品的数量的均值和求和
df2 = file2.groupby(['place_of_production','level'])['number'].agg([np.mean, np.sum])
df2
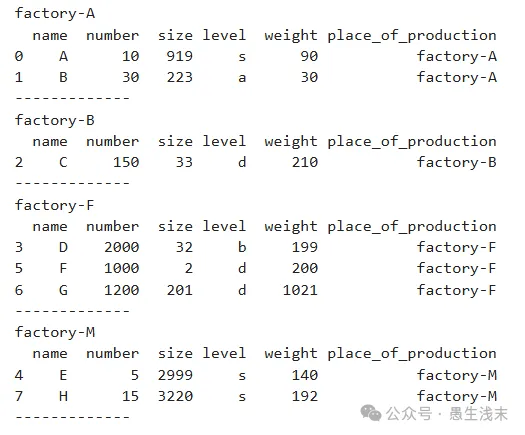
最后,如果要遍历GroupBy的结果,则不能直接打印其内容,而是要通过迭代获取
# 首先尝试打印GroupBy结果
df3 = file2.groupby('place_of_production')
print(df3) # <pandas.core.groupby.generic.DataFrameGroupBy object at 0x00000186E3D3C3D0>
当然我们可以把df3强制转换格式为list再输出,但结果并不是很方便进行进一步处理。因此,可以通过对GroupBy的结果进行遍历,再获取我们期望的信息
for name, group in df3:
print(name) # 分组后的组名
print(group) # 组内信息
print('-------------') # 分割线
![]
Pandas与NumPy异同
1)Numpy是数值计算的扩展包,能够高效处理N维数组,即处理高维数组或矩阵时会方便。Pandas是python的一个数据分析包,主要是做数据处理用的,以处理二维表格为主。
2)Numpy只能存储相同类型的ndarray,Pandas能处理不同类型的数据,例如二维表格中不同列可以是不同类型的数据,一列为整数一列为字符串。
3)Numpy支持并行计算,所以TensorFlow2.0、PyTorch都能和numpy能无缝转换。Numpy底层使用C语言编写,效率远高于纯Python代码。
4)Pansdas是基于Numpy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas提供了大量快速便捷地处理数据的函数和方法。
5)Pandas和Numpy可以相互转换,DataFrame转化为ndarray只需要使用df.values即可,ndarray转化为DataFrame使用pd.DataFrame(array)即可。
Pandas从入门到放弃的更多相关文章
- 爬虫入门到放弃系列05:从程序模块设计到代理IP池
前言 上篇文章吧啦吧啦讲了一些有的没的,现在还是回到主题写点技术相关的.本篇文章作为基础爬虫知识的最后一篇,将以爬虫程序的模块设计来完结. 在我漫(liang)长(nian)的爬虫开发生涯中,我通常将 ...
- CYQ.Data 从入门到放弃ORM系列:开篇:自动化框架编程思维
前言: 随着CYQ.Data 开始回归免费使用之后,发现用户的情绪越来越激动,为了保持这持续的激动性,让我有了开源的念头. 同时,由于框架经过这5-6年来的不断演进,以前发的早期教程已经太落后了,包括 ...
- [精品书单] C#/.NET 学习之路——从入门到放弃
C#/.NET 学习之路--从入门到放弃 此系列只包含 C#/CLR 学习,不包含应用框架(ASP.NET , WPF , WCF 等)及架构设计学习书籍和资料. C# 入门 <C# 本质论&g ...
- OpenStack从入门到放弃
OpenStack从入门到放弃 目录: 为何选择云计算/云计算之前遇到的问题 什么是云计算 云服务模式 云应用形式 传统应用与云感知应用 openstack及其相关组件介绍 flat/vlan/gre ...
- 绕过校园网的共享限制 win10搭建VPN服务器实现--从入门到放弃
一.开篇立论= =.. 上次说到博主在电脑上搭建了代理服务器来绕过天翼客户端的共享限制,然而经过实际测试还不够完美,所以本着生命不息,折腾不止的精神,我又开始研究搭建vpn服务器= =... (上次的 ...
- 《区块链:从入门到放弃》之obc安装步骤
obc安装步骤 朋友们可能会好奇,厨师不研究菜谱怎么改研究兵法了,哈哈,我原本是app出身,最近被安排去预研区块链和比特币技术,2个月下来,颇有斩获.期间得到IBM的CC同学指导我一步一步安装obc的 ...
- win10搭建代理服务器实现绕过校园网的共享限制--从入门到放弃
博主所在学校特别坑爹,校园网被电信一家垄断了,而且最恶心的还是电信要求一条网线只能供一台电脑上网,不许接路由器共享网络= =- (还有电信2M价格是380+每年,20m是500每年,而且网速都很慢= ...
- Pandas简易入门(二)
目录: 处理缺失数据 制作透视图 删除含空数据的行和列 多行索引 使用apply函数 本节主要介绍如何处理缺失的数据,可以参考原文:https://www. ...
- WPF从入门到放弃系列第二章 XAML
本文是作者学习WPF从入门到放弃过程中的一些总结,主要内容都是对学习过程中拜读的文章的整理归纳. 参考资料 XAML 概述 (WPF):https://msdn.microsoft.com/zh-cn ...
- Android -- 带你从源码角度领悟Dagger2入门到放弃
1,以前的博客也写了两篇关于Dagger2,但是感觉自己使用的时候还是云里雾里的,更不谈各位来看博客的同学了,所以今天打算和大家再一次的入坑试试,最后一次了,保证最后一次了. 2,接入项目 在项目的G ...
随机推荐
- linux 查看端口状态
查看端口 netstat -tlun 查看端口被那个服务占用 netstat -tunlp |grep 8080
- python配置国内pypi镜像源操作步骤
使用pip config命令设置默认镜像源,使用国内的源,提高安装速度 操作步骤 临时方式pip install xxx -i https://pypi.tuna.tsinghua.edu.cn/si ...
- 深入理解 React 的 useSyncExternalStore Hook
深入理解 React 的 useSyncExternalStore Hook 大家好,今天我们来聊聊 React 18 引入的一个新 Hook:useSyncExternalStore.这个 Hook ...
- WebGL实践之半透阴影
楔子 相信很多人都知道,通过ShadowMap可以产生阴影,通过渲染阴影可以增加场景渲染的对比度,增加渲染的真实效果. 如下图所示: 但是对于透明或者半透明的对象,WebGL在处理阴影效果的时候,会把 ...
- 基于Java+SpringBoot+Vue宠物咖啡馆平台设计和实现
\n文末获取源码联系 感兴趣的可以先收藏起来,大家在毕设选题,项目以及论文编写等相关问题都可以给我加好友咨询 系统介绍: 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成 ...
- JMeter 后置处理器之JSON提取器
后置处理器之JSON提取器 By:授客 QQ:1033553122 测试环境 JMeter 5.4.1 插件介绍 JSON后置处理器(PostProcessor)允许使用 JSON Path 语法从J ...
- app备案证明需要提供md5值和公钥的解决方案
现在app上架华为市场.小米市场.苹果市场等大型的应用商店,都需要提供国内的app备案证明.无论是安卓还是ios,都需要备案了. 但是问题是备案的时候需要填写app的bundle ID.公钥和MD5值 ...
- vue3 + ts 中出现 类型“typeof import(".........../node_modules/vue/dist/vue")”的参数不能赋给类型“Component<any, any, any, ComputedOptions, MethodOptions>”的参数。
错误示例截图 解决方法 修改shims-vue.d.ts中的内容 declare module "*.vue" { import { defineComponent } from ...
- 甄嬛霸气照 —— Chinese Queen
- 带有最小间隔时间的队列读取实现 —— 最小等待时间的队列 —— Python编程(续)
接前文: 带有最小间隔时间的队列读取实现 -- 最小等待时间的队列 -- Python编程 由于上次的设计多少有些简单,这里对此丰富一下. ============================== ...