PlugIR:开源还不用微调,首尔大学提出即插即用的多轮对话图文检索 | ACL 2024
即插即用的
PlugIR通过LLM提问者和用户之间的对话逐步改进文本查询以进行图像检索,然后利用LLM将对话转换为检索模型更易理解的格式(一句话)。首先,通过重新构造对话形式上下文消除了在现有视觉对话数据上微调检索模型的必要性,从而使任意黑盒模型都可以使用。其次,构建了LLM问答者根据当前情境中检索候选图像的信息生成关于目标图像属性的非冗余问题,缓解了生成问题时出现的噪音和冗余性问题。此外,还新提出Best log Rank Integral(BRI)指标,用于衡量多轮任务中的综合性能。论文验证检索系统在各种环境下的有效性,并突出了其灵活的能力。来源:晓飞的算法工程笔记 公众号
论文: Interactive Text-to-Image Retrieval with Large Language Models: A Plug-and-Play Approach

Introduction
文本到图像检索是一个专注于在图像数据库中定位与输入文本查询相对应的目标图像的任务,由于视觉-语言多模态模型的发展,这一任务取得了显著进展。传统上,该领域的方法采用单轮检索方法,依赖于初始文本输入,这需要用户提供全面和详细的描述。最近,有研究提出了一种基于聊天的图像检索系统,利用大型语言模型(LLMs)作为提问者以促进多轮对话。即使用户提供了简单的初始图像描述,也能增强检索效率和性能。然而,这种基于聊天的检索框架面临一些限制,包括需要进行精细微调以充分编码对话式文本,这个过程既消耗资源又不适合可扩展性。此外,LLM提问者依赖于初始描述和对话历史,而没有查看候选图像的能力。仅根据LLM的参数化知识,可能生成目标图像无关的内容。
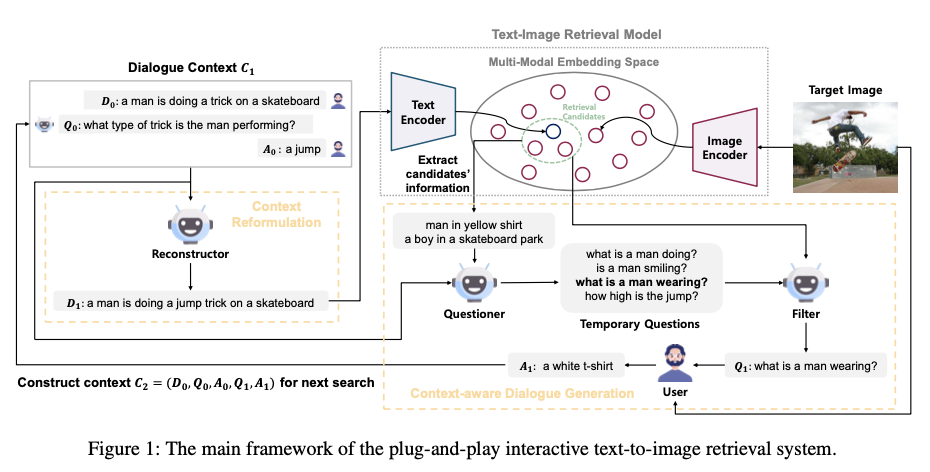
为了克服这些挑战,作者介绍了一种新颖的即插即用的交互式文本到图像检索方法PlugIR,与LLMs紧密耦合。PlugIR包括两个关键组件:上下文重构和上下文感知对话生成。利用LLMs的指令遵循能力,PlugIR将用户和提问者之间的交互上下文重构为适合预先训练好的视觉-语言模型的兼容格式。这个过程使得可以直接应用一系列多模态检索模型,包括黑盒变体,无需进一步精细调整。此外,作者的方法确保LLM提问者的询问基于检索候选集的背景,从而使其能够提出与目标图像属性相关的问题。在这个过程中,以文本形式将检索上下文注入LLM提问者作为参考输入上下文。随后,作者的方法还包括一个筛选过程,选择最符合背景、不重复的问题,简化搜索选项。
作者确定了评估交互式检索系统的三个关键方面:用户满意度、效率和排名改进的重要性,发现现有的指标,如Recall@K和Hits@K,在这些方面存在不足。例如,Hits@K未能考虑效率,而实际上通过较少的交互可以更好地定位目标图像。为了解决这些问题,作者引入了Best log Rank Integral(BRI)指标。BRI有效地涵盖了所有三个关键方面,提供了一个全面的评估,并不依赖于特定排名K,与Recall@K或Hits@K不同。我们在实证中证明BRI与人工评估更接近比起现有的指标。
在包括VisDial、COCO和Flickr30k在内的多个数据集上进行的实验表明,PlugIR在使用零样本或微调模型的现有交互式检索系统方面表现出显著优势。此外,作者的方法在应用于各种检索模型(包括黑盒模型)时显示出显著的适应性。这种兼容性扩展了其实用性,使其能够适应更广泛的应用和场景。
论文贡献如下:
提出了第一组经验证据,表明零样本模型在理解对话方面存在困难,并引入了一种上下文重构方法作为解决方案,不需要微调检索模型。
提出了一个
LLM提问者,旨在解决嘈杂和冗余问题导致的搜索瓶颈问题。引入了
BRI指标,这是一种与人类判断相一致的新型度量标准,专门设计用于实现对交互式检索系统进行全面和可量化评估。验证了论文的框架在各种不同环境中的有效性,突出了它多功能的即插即用能力。
Method
Preliminaries: Interactive Text-to-Image Retrieval
交互式文本到图像检索是一个多轮任务,从用户提供的简单初始描述 \(D_0\) 开始。这个任务涉及用户和检索系统之间关于与 \(D_0\) (目标图像)对应的图像进行对话,形成一个上下文,在每个轮(回合)中被用作搜索目标图像的查询。在每一轮 \(t\) 中,检索系统生成关于目标图像的问题 \(Q_t\) ,用户以答案 \(A_t\) 做出回应,从而为该轮创建对话上下文 \(C_t=(D_0, Q_0, A_0, …, Q_t, A_t)\) 。这个对话上下文经过适当处理,比如连接所有文本元素,形成单一的文本查询,在该轮中用于图像搜索。在进行图像搜索时,检索系统将图像池中所有图片与文本查询匹配并根据相似度得分对它们进行排名,检索系统的性能可以根据目标图片的检索排名进行评估。
对于评估,通常使用两个主要指标:Recall@K和Hits@K。当使用Recall@K进行评估时,如果当前轮计算的目标图像排名在前K名之内,则认为成功。对于Hits@K,如果目标图像在当前轮之前的任何一轮中出现在前K个结果中,则认为成功。
Context Reformulation
Do zero-shot models understand dialogs?
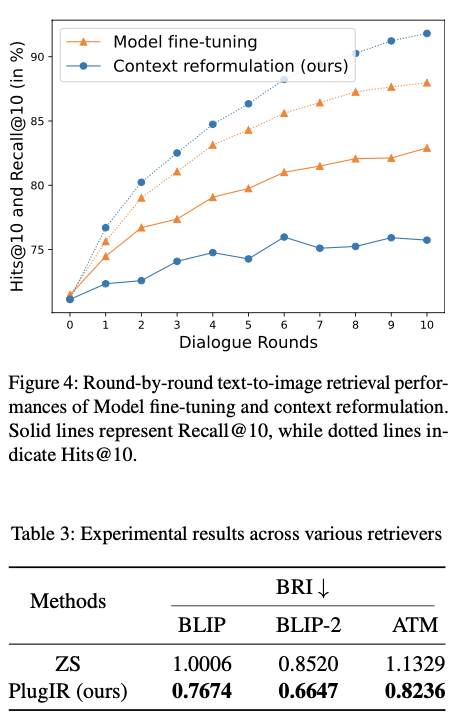
为了展示所提出方法的必要性,评估零样本模型在交互式文本到图像检索任务中理解和有效利用给定对话的程度。特别跟踪零样本模型的检索性能变化,这些模型包括三个白盒模型(CLIP、BLIP和BLIP-2)和一个黑盒模型,通过逐步提供与目标图像相关的额外问题-答案对来增强性能,共进行10轮。因此,在第10轮,输入查询是一个包含一幅图像标题和10个问题-答案对的对话。假设如果一个零样本模型能够理解对话并有效地在图像检索任务中利用它们,那么它将在后续轮次表现出比起初轮次更好的性能,初轮次仅涉及使用图像标题。
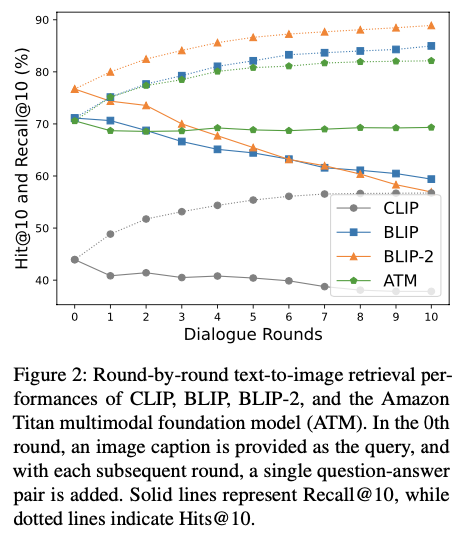
如图2示,所有测试的零样本模型在连续轮次中Hits@10分数的逐步改善。这一趋势表明,一些查询样本,在最初的检索中失败,随着对话在后续轮次中变得更丰富,最终成功。然而,不建议仅仅基于这些观察结果就匆忙得出结论,认为对话作为零样本模型输入查询是有效的。真正的分析应该更多地受到Recall@10分数而不是Hits@10分数的影响,Recall@10表现出了不同的结论:零样本模型似乎在文本到图像检索任务中难以理解对话。
事实上,通过简单地向图像标题和候选图像之间的相似度矩阵添加噪音,Hits@K分数可以在连续轮次中增加,这是因为Hits@K仅需要在每个轮次之前的任何时间点进行一次成功的检索尝试。相比之下,Recall@K反映了文本到图像检索任务中"每一轮"查询中所包含信息的数量。
如图2所示,在使用仅图像标题作为输入查询时,所有研究中的检索模型均获得其最高的Recall@10分数。值得注意的是,在CLIP、BLIP和BLIP-2模型中,随着轮次进展,它们的Recall@10分数下降。这一趋势意味着,在这些零样本模型的背景下,追加对话主要起到了噪音作用。在CLIP、BLIP和BLIP-2中,随着对话长度增加,噪音效应变得更加显著。亚马逊Titan多模态基础模型(ATM)虽然不会随着对话长度增加而导致Recall@10下降,但也没有表现出提升性能,这表明添加的对话可能并未实质性地为信息上下文做出贡献。
A plug-and-play approach
为了克服零样本检索模型在文本到图像检索任务中未能有效使用对话的挑战,一种策略可能是使用由图像和对话配对组成的数据集对预训练的检索模型进行微调。例如在VisDial上对BLIP模型进行了微调,以获得更高的Hits@K分数。论文的实验也表明,这种方法可以赋予检索模型理解对话的能力。然而,这种基于微调的方法的实施取决于并非总是可行的:(1)必须可以访问检索模型参数;(2)必须获取足够和合适的训练数据。例如,这种方法不适用于像ATM这样的黑盒式检索模型。

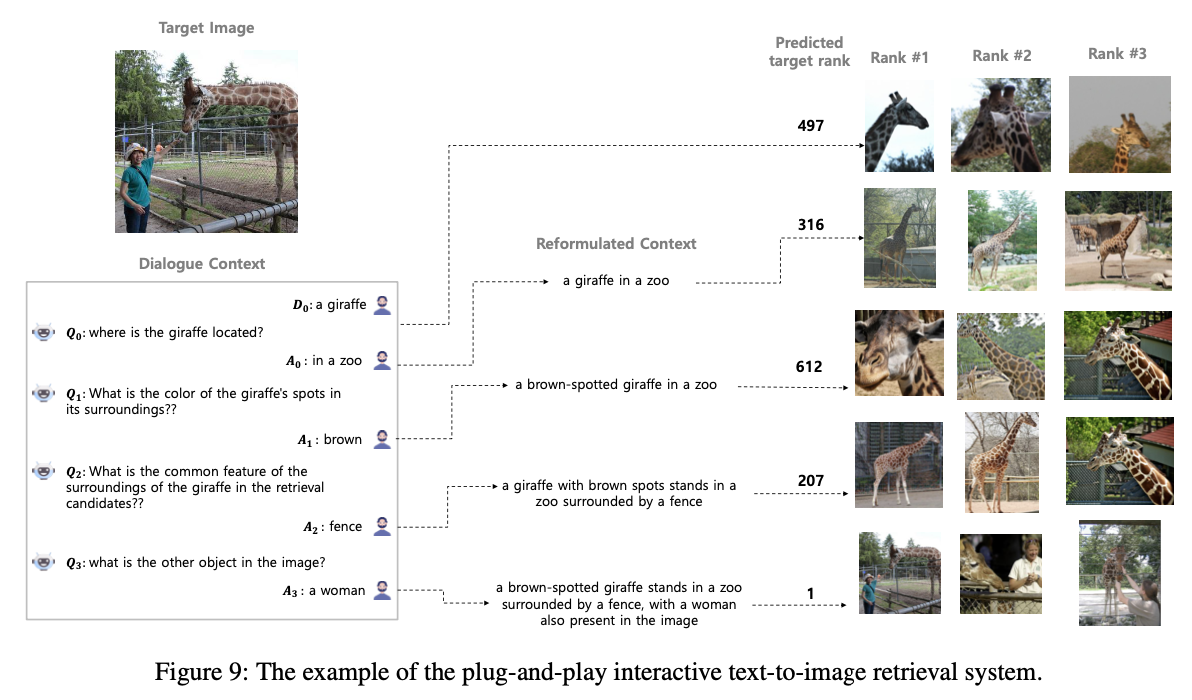
于是,作者探索了一种新颖的方法,该方法使文本查询更容易被检索模型理解,而不是修改检索模型以适应文本查询的格式。具体地说,不直接使用对话作为输入查询,而是利用LLMs将对话转换为与检索模型的训练数据分布更加一致的格式(例如,标题风格)。这种策略有效地绕过了基于微调方法的限制,因为它不需要对检索模型进行微调。
Context-aware Dialogue Generation
Is the additional information in dialogues actually effective?
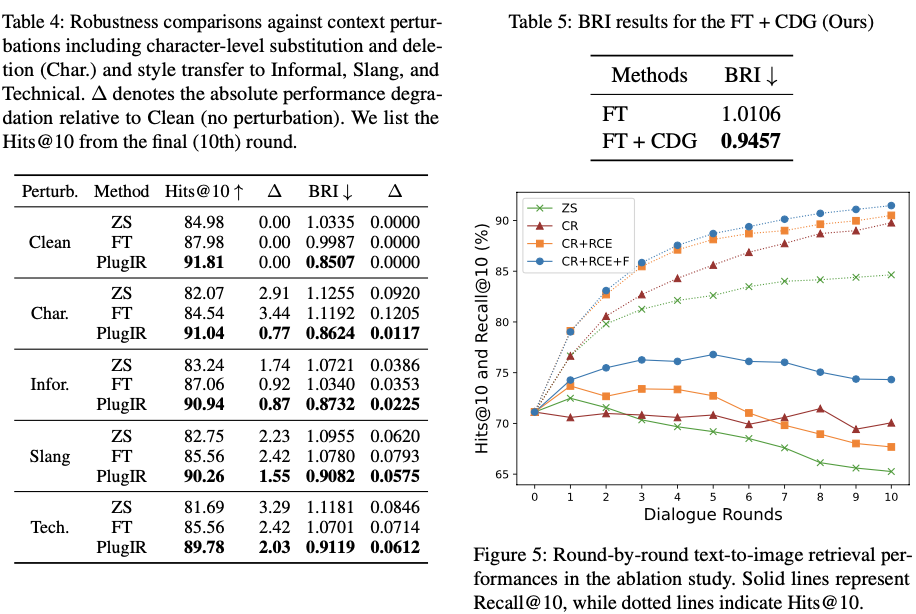
对话中的额外信息实际上有效吗?前面提出的重构的动机是基于这样的观察:对话形式往往更像噪音,而不是对预训练的检索器有用的信息。于是,作者深入探讨上下文的形式,并专注于上下文的实际内容。当仅依赖对话上下文来生成关于目标图像的问题时,作者发现了两个关键问题。首先,生成的问题可能涉及与目标图像无关的属性。例如,询问不在目标图像中的对象的问题可能会引起否定回答。这种情况本身可能在对话上下文中起到噪音作用。因此,与先前回合相比,上下文表示引入更多混乱到检索过程中,导致检索性能下降
第二个问题是生成的问题可能存在潜在的冗余性。在问题生成过程中,像“照片中的人在做什么?”这样的常规问题,通常可以根据对话上下文中已有的信息来回答,而无需查看目标图像。在这种情况下,问题-答案对也未能提供有价值的额外信息,导致冗余。因此,这种冗余并未有助于提升后续回合的检索性能。为了解决这些问题,作者提出一个可以灵活应用于各种情况的提问者结构,有效地应对对话中的噪音和冗余挑战。
A plug-and-play approach
为了避免生成与目标图像无关的属性的问题,将当前回合的检索候选图像信息注入LLM提问者的文本输入中。对于这个过程,首先从图像池中提取与(重构后的)对话上下文在嵌入空间中相似的图像,将它们作为“检索候选集”的集合。这些相似的图像包含类似于当前对话上下文的属性,其中包括一些关于目标图像的信息,确保生成的关于这些属性的问题与目标图像有一定的关联性。
对候选图像嵌入应用K-means聚类,获得每个候选图像与其他候选图像之间的相似度分布。对于每个簇,选择在其相似度分布中熵最低的图像作为代表。这种选择基于一个理念,即相似度分布中熵较低表明相应的图像包含更具体和可区分的属性。例如,在属于同一簇的图像中,对应标题“家庭办公室”的图像显示高熵,而对应标题“一张桌子上有两台电脑显示器和一个键盘”的另一张图像显示低熵。

通过这种方法获得的K张图像随后通过任意的图像标题模型转换为文本信息,并作为额外输入提供给LLM问答者。此检索上下文提取过程如算法1所示。


为确保LLM提问者有效地将检索候选的文本信息作为基础,采用一种“链式思维”(CoT)方法。这包含向LLM提问者提供少样本示例作为额外指导,有效利用检索候选的内容。
基于从检索搜索空间提取的额外上下文进行基础的生成的问题,能够包括与目标图像相关的属性,但仍可能是冗余的。为了防止生成这类问题,采用了一个额外的过滤过程,该过程在最近的Ddcot中提出的策略。对于提问者生成的每个问题,使用一个LLM代理在无法从相应描述和对话中得出答案时回答“不确定”,这意味着问题是没有冗余的,然后只使用回答为“不确定”的问题。
过滤过程可以有效地去除在不查看目标图像的情况下即可回答的问题,但未能排除即使有了目标图像也无法回答的问题,这些失败的问题涉及与候选集相关但与目标图像无关的属性。作者观察到使用这种不适当的问题会导致查询和候选图像之间相似性分布发生相对突然的变化,导致检索性能下降。因此,作者根据对话上下文的相似性分布与和结合问题后对话上下文的相似性分布进行选择,取Kullback-Leibler(KL)散度最低的问题。

算法2展示了PlugIR的过滤过程。以这种方式配置的具有上下文感知能力对话生成过程可以与前面部分描述中所述的上下文重构协同使用,并且具备独立使用灵活性,特别是在利用针对对话上下文进行微调检索模型时。
The Best log Rank Integral Metric
在评估交互式检索系统时,以下关键方面是必不可少的:
- 用户满意度:如果系统在其查询预算内至少一次成功检索到目标图像,则认为这一方面得到满足。
- 效率:系统的效率通过成功检索所需的轮次来衡量;轮次越少表示性能越好。
- 排名改进的重要性:在更高排名位置的提升在本质上更具挑战性,因此,在度量评估中应更加强调这一点。例如,当图像的排名从
2升至1时,度量指标的改善应该明显更显著,与从100升至99相反。这种区别突显了达到顶级排名所伴随的增加挑战和价值。
Recall@K,通常用于非交互式检索系统评估,在特定的情境中并未完全解决这三个方面。Hits@K,交互式系统推荐的指标,满足了用户满意度的标准,但在充分解决后两个方面上仍有所欠缺。因此,论文引入了一种新颖的评估指标,旨在全面解决这三个考虑因素。
为了解决用户满意度的问题,定义Best Rank如下:设 \(R(q)\) 表示与查询 \(q\) 对应的目标图像的检索排名。那么,在第 \(t\) 轮的查询 \(q_t\) 的最佳排名 \(\pi\) 为
\begin{cases}
\min(\pi(q_{t-1}), R(q_t))&\textup{if}\;t\geq1 \\
R(q_0)&\textup{if}\;t=0
\end{cases}
\]
设 \(Q\) 和 \(T\) 分别为测试查询集和指定的系统查询预算。那么,BRI被定义为
\left[
\frac{1}{2T}\log\pi(q_0)\pi(q_T)+\frac{1}{T}\sum^{T-1}_{t=1}\log\pi(q_t)
\right].
\]
BRI可以解释为在所有查询 \(Q\) 上,对于第 \(t\) 轮的 \(\log\pi\) 图形的平均面积。目标图像排名的改进越快,图形下方的面积就越小。函数的对数特性使得BRI在接近顶部排名时更加显著地减小,较低的BRI表示交互检索系统性能更好。值得注意的是,BRI在评估方法上与Recall@K和Hits@K有所不同。它不是基于特定排名(K)对数据样本进行二分,而是在评估过程中校准所有数据样本的结果,使其成为一种更通用和可靠的度量指标。
实验结果证实,BRI与人类评估的一致性要远远超过其他度量指标。
Experiments
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

PlugIR:开源还不用微调,首尔大学提出即插即用的多轮对话图文检索 | ACL 2024的更多相关文章
- UCloud首尔机房整体热迁移是这样炼成的
小结: 1.把两个机房在逻辑上变成一个机房: 2.新老机房的后端服务使用同一套 ZooKeeper,但是配置的却是不同的 IP: 3.UCloud内部服务所使用的数据库服务为MySQL, 内部MySQ ...
- NGK Global首尔站:内存是未来获取数字财富的新模式
近日,NGK路演在NGK韩国社区的积极举办下顺利落下帷幕.此次路演在首尔举行,在活动当天,NGK的核心团队成员.行业专家.投资银行精英.生态产业代表和数百名NGK韩国社区粉丝一起参加NGK Globa ...
- 【爆料】-《英博夏尔大学毕业证书》BPP一模一样原件
英博夏尔大学毕业证[微/Q:2544033233◆WeChat:CC6669834]UC毕业证书/联系人Alice[查看点击百度快照查看][留信网学历认证&博士&硕士&海归&a ...
- 杜伦大学提出GANomaly:无需负例样本实现异常检测
杜伦大学提出GANomaly:无需负例样本实现异常检测 本期推荐的论文笔记来自 PaperWeekly 社区用户 @TwistedW.在异常检测模块下,如果没有异常(负例样本)来训练模型,应该如何实现 ...
- 实操 | 内存占用减少高达90%,还不用升级硬件?没错,这篇文章教你妙用Pandas轻松处理大规模数据
注:Pandas(Python Data Analysis Library) 是基于 NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.此外,Pandas 纳入了大量库和一些标准的数据模型 ...
- GCP消息队列Pubsub详解,简单好用还不用自己运维
我最新最全的文章都在南瓜慢说 www.pkslow.com,欢迎大家来喝茶! 1 简介 GCP的Pubsub是一种异步消息传递服务,可将生产事件的服务与处理事件的服务隔离开.消息队列的作用就不多作介绍 ...
- 【点分治】2019 首尔 icpc Gene Tree
题目 链接:https://ac.nowcoder.com/acm/contest/15644/B来源:牛客网 A gene tree is a tree showing the evolution ...
- 开源跳板机(堡垒机)系统 Jumpserver安装教程(带图文)
环境 系统: CentOS 7 IP: 192.168.244.144 关闭 selinux 和防火墙 # CentOS 7 $ setenforce 0 # 可以设置配置文件永久关闭 $ syste ...
- AI佳作解读系列(二)——目标检测AI算法集杂谈:R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- 检测算法简介及其原理——fast R-CNN,faster R-CNN,YOLO,SSD,YOLOv2,YOLOv3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
随机推荐
- Linux Mint操作系统安装
1,Linux 发行版 什么是Linux 发行版呢?这要从Linux 来源说起.Unix操作系统后期,开始收费和商业闭源了.一个叫Richard Stallman 的人就发起 GNU 计划,想模仿U ...
- 算法金 | DL 骚操作扫盲,神经网络设计与选择、参数初始化与优化、学习率调整与正则化、Loss Function、Bad Gradient
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 今日 216/10000 抱个拳,送个礼 神经网络设计与选择 参数初始化与优化 学习率 ...
- 很好用的SSH工具FinalShell
上图片:1.远程连接Linux 2.Linux:CentOS 3.虚拟机:
- Profinet转Modbus模块减轻通讯编程工作量实现Modbus通讯
巴图自动化PN转Modbus模块(BT-MDPN10)能够实现Profinet协议与Modbus协议之间的转换,使得Profinet协议设备与Modbus协议设备进行连接并能够相互通信. 通过使用巴图 ...
- 文件系统(十):一文看懂 UBI 文件系统
liwen01 2024.07.21 前言 UBI (Unsorted Block Images)文件系统是一种用于裸 flash 的文件系统管理层.它是专为管理原始闪存设备而设计,特别适用于嵌入式系 ...
- 是否可以在线创建ios证书
生成苹果证书,假如使用官方的教程去生成,非常麻烦,因为它需要使用苹果mac电脑去生成,而且生成的流程还要对苹果电脑的证书导入和导出比较熟. 因此,生成苹果ios证书,不建议使用官方的方法去生成,少走弯 ...
- midjourney 生成相似类型图片
生成类似形象 midjourney 核心就是一次运行3次图片,多尝试 上传此图片到discord里的mj -> 复制图片的link -> 使用describe拆词 也可以自己手动拆词,人工 ...
- python面向对象:继承
python面向对象:继承super()的用 super()的用法 一: class A: def __init__(self): self.a = '这是一个属性' def add(self, x) ...
- Jmeter让线程循环变量值不重复
我们定义用户参数时为了保证某个参数值不重复会设置为随机变量 1.使用[用户定义的变量]组件,传入随机值如"HELLO${__Random(100,200,)}_${__counter(FAL ...
- SpringBoot整合Redis,并处理序列化反序列化问题
1.添加Redis依赖 在项目的pom.xml文件中添加Redis的依赖项.例如,可以使用spring-boot-starter-data-redis依赖项来引入Redis的支持. <depen ...