【LeetCode二叉树#00】二叉树的基础知识
基础知识
分类
满二叉树
如果二叉树中除了叶子结点,每个结点的度都为 2,则此二叉树称为满二叉树。
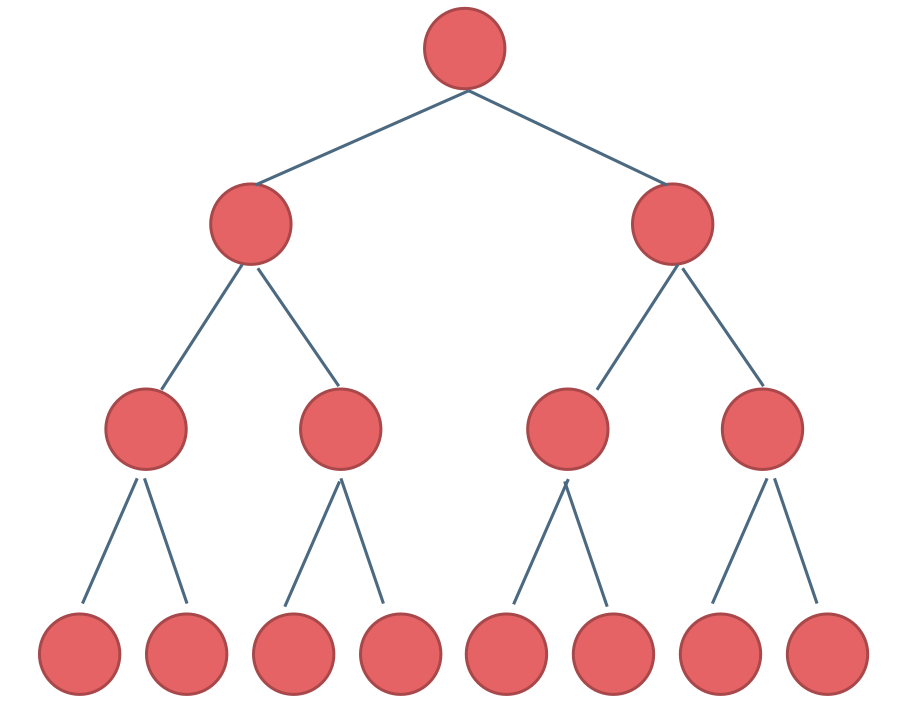
完全二叉树
除了底层外,其他部分是满的,且底层从左到右是连续的,称为完全二叉树
满二叉树一定是完全二叉树
举个例子:
完全二叉树
1
/ \
2 3
/ \ / \
4 5 6
不是完全二叉树
1
/ \
2 3
/ \ / \
4 5 6
二叉搜索树
例如:
6
/ \
3 9
/ \ / \
1 4 8 10
二叉搜索树里面的节点是有顺序的
左子树(左半边)的所有节点都小于中间节点
右子树(右半边)的所有节点都大于中间节点
并且在左/右子树的子树中也满足该规律
平衡二叉搜索树
左子树和右子树高度差的绝对值不能大于1
什么意思呢?例如:
0 6
/
1 3
/ \
2 1 4
上述二叉树不是平衡二叉搜索树
左子树的高度是2,右子树的高度是0,作差绝对值为2
再如:
0 6
/ \
1 3 9
/ \
2 1 4
这个就是平衡二叉搜索树
左子树的高度是2,右子树的高度是1,作差绝对值为1(右子树再加1个节点仍然还是)
又如:
0 6
/ \
1 3 9
/ \ /
2 1 4 8
/
3 0
这个还是平衡二叉搜索树
其左子树本身(从3开始往下的)满足条件,整棵树的左右子树也满足条件
C++中map、set、multimap,multiset的底层实现都是平衡二叉搜索树,所以map、set的增删操作时间时间复杂度是logn,注意我这里没有说unordered_map、unordered_set,unordered_map、unordered_map底层实现是哈希表。
平时在使用容器时要有意识去了解其底层实现是什么数据结构(这样才知道所使用的数据结构中的元素是否有序、时间复杂度是多少、为什么)
存储方式
链式存储
如图所示
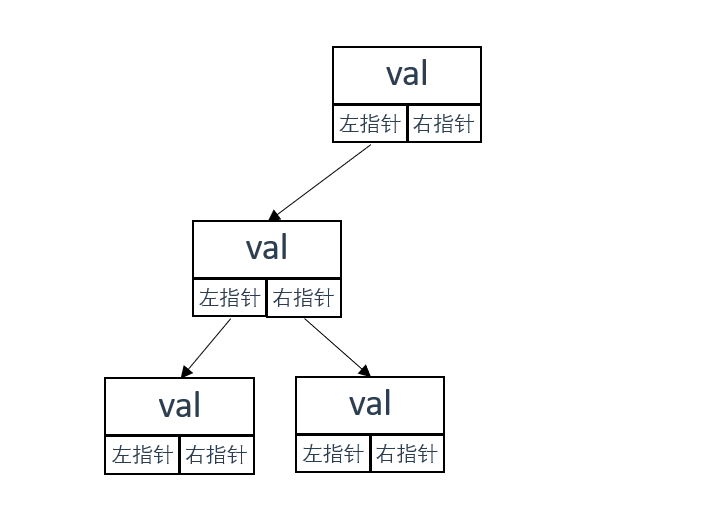
链式存储顾名思义就是使用指针(类似链表)的方式表示树
线性存储(了解)
其实就是用数组来存储二叉树,顺序存储的方式如图:
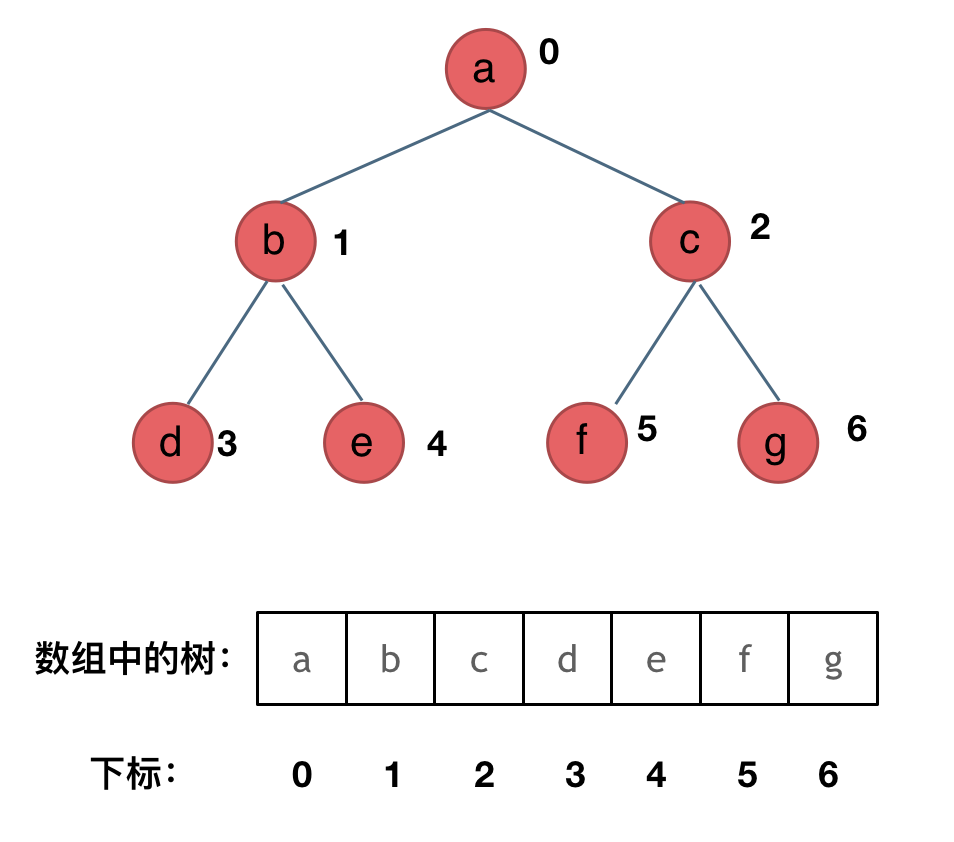
用数组来存储二叉树如何遍历的呢?
如果父节点的数组下标是 i,那么它的左孩子就是 i * 2 + 1,右孩子就是 i * 2 + 2。
但是用链式表示的二叉树,更有利于我们理解,所以一般我们都是用链式存储二叉树。
所以大家要了解,用数组依然可以表示二叉树。
注意(构造二叉树)
LeetCode上在做题时,二叉树通常是封装好的
但是实际面试的时候,有可能要手写待传入的数据。比如:请传入一个二叉树
因此,需要掌握构造一个二叉树的方法
平时做题的时候我们通常使用链式存储老保存一个二叉树
其实说白了就是一个链表,只不过这个链表的节点上有两个指针,分别指向左右子节点
(那就是双向链表咯)
于是,我们可以构造一个双向链表来表示一颗二叉树,在传入二叉树时将该链表的头结点传入即可
二叉树遍历方式
二叉树的遍历方式实际上对应与图论中的两种遍历方式:深度优先搜索和广度优先搜索
深度优先搜索
一般用 递归 的方式实现
前序遍历、中序遍历以及后序遍历均数据深度优先搜索
描述一下就是:在选定一个节点后,一直沿一跳路径搜索到末尾,然后递归回到最开始的位置再换方向继续搜索
当然使用非递归的方式也可以实现,一般使用 迭代法(即采用 栈 去模拟递归)
理论上,用递归解决的遍历问题都可以用相对应的迭代法解决(只是有些可能会麻烦一些)
(实际上计算机在实现递归时,底层就是用的栈)
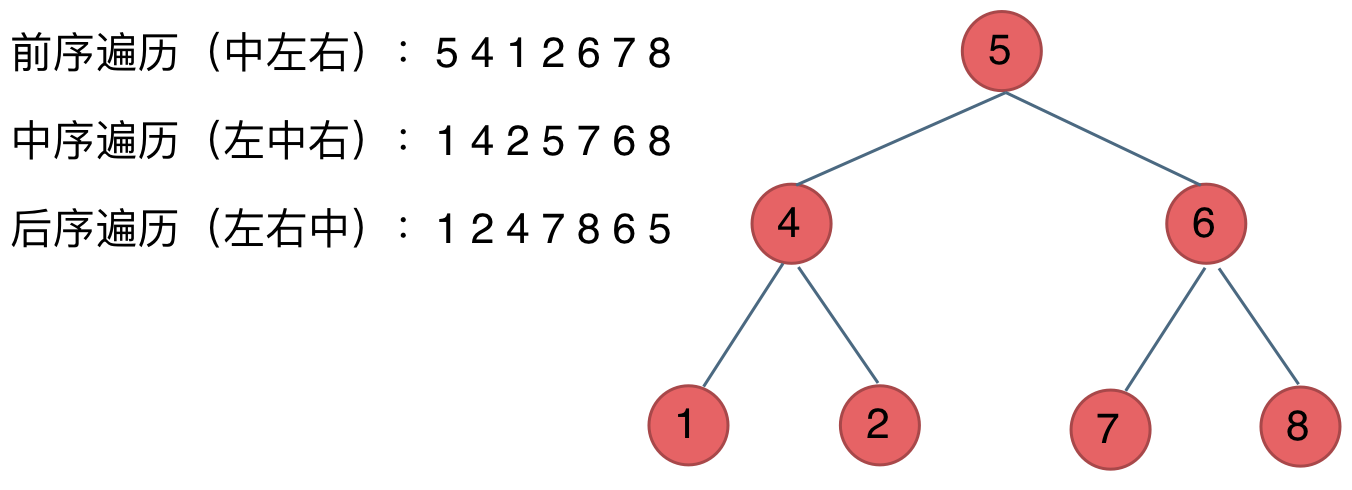
区分前/中/后序遍历
首先明确,这三种方式都是一条路先搜索到头再换方向的
那么他们的区别就是遍历时候的方向顺序
前序:中左右
中序:左中右
后序:左右中
其实“前中后”描述的就是"中"的位置
例如:
广度优先搜索
通常指一层一层遍历二叉树的方式(在图论中是一圈一圈的遍历)
常见方法是:层序遍历
一般使用 队列 实现
二叉树定义方式
顺序存储就是用数组来存,这个定义没啥可说的,我们来看看链式存储的二叉树节点的定义方式。
C++代码如下:
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
二叉树的定义 和链表是差不多的,相对于链表 ,二叉树的节点里多了一个指针, 有两个指针,指向左右子节点。
**在现场面试的时候 面试官可能要求手写代码,所以数据结构的定义以及简单逻辑的代码一定要锻炼白纸写出来。
【LeetCode二叉树#00】二叉树的基础知识的更多相关文章
- Java基础知识强化58:经典排序之二叉树排序(BinaryTreeSort)
1. 二叉树排序 二叉树排序的描述也是一个递归的描述, 所以二叉树排序的构造自然也用递归的: 二叉排序树或者是一棵空树,或者是具有下列性质的二叉树: (1)若左子树不空,则左子树上所有结点的值均小于它 ...
- Python超全干货:【二叉树】基础知识大全
概念 二叉树是每个节点最多有两个子树的树结构.通常子树被称作"左子树"(left subtree)和"右子树"(right subtree) 二叉树的链式存储: ...
- 编程熊讲解LeetCode算法《二叉树》
大家好,我是编程熊. 往期我们一起学习了<线性表>相关知识. 本期我们一起学习二叉树,二叉树的问题,大多以递归为基础,根据题目的要求,在递归过程中记录关键信息,进而解决问题. 如果还未学习 ...
- LeetCode刷题191130 --基础知识篇 二叉搜索树
休息了两天,状态恢复了一下,补充点基础知识. 二叉搜索树 搜索树数据结构支持许多动态集合操作,包括Search,minimum,maximum,predecessor(前驱),successor(后继 ...
- LeetCode:翻转二叉树【226】
LeetCode:翻转二叉树[226] 题目描述 翻转一棵二叉树. 示例: 输入: 4 / \ 2 7 / \ / \ 1 3 6 9 输出: 4 / \ 7 2 / \ / \ 9 6 3 1 题目 ...
- 【Leetcode】104. 二叉树的最大深度
题目 给定一个二叉树,找出其最大深度. 二叉树的深度为根节点到最远叶子节点的最长路径上的节点数. 说明: 叶子节点是指没有子节点的节点. 示例:给定二叉树 [3,9,20,null,null,15,7 ...
- 代码随想录算法训练营day20 | leetcode ● 654.最大二叉树 ● 617.合并二叉树 ● 700.二叉搜索树中的搜索 ● 98.验证二叉搜索树
LeetCode 654.最大二叉树 分析1.0 if(start == end) return节点索引 locateMaxNode(arr,start,end) new root = 最大索引对应节 ...
- JAVA学习基础知识总结(原创)
(未经博主允许,禁止转载!) 一.基础知识:1.JVM.JRE和JDK的区别: JVM(Java Virtual Machine):java虚拟机,用于保证java的跨平台的特性. java语言是跨平 ...
- MySQL 基础知识梳理
MySQL 的安装方式有多种,但是对于不同场景,会有最适合该场景的 MySQL 安装方式,下面就介绍一下 MySQL 常见的安装方法,包括 rpm 安装,yum 安装,通用二进制安装以及源码编译安装, ...
- JAVA面试题集之基础知识
JAVA面试题集之基础知识 基础知识: 1.C 或Java中的异常处理机制的简单原理和应用. 当JAVA程序违反了JAVA的语义规则时,JAVA虚拟机就 ...
随机推荐
- killall 以及 pkill 等命令
https://zhidao.baidu.com/question/1500084252693125099.html // 通过 killall 命令killall nginx// 通过 pkill ...
- Linux平台下面部署node npm 等工具软件
公司这边用到了运行时定制, 用的是angular 开发的. 所以需要在linux 里面安装 angular的相关工具. 需要在服务器上面有angular nodejs 还有jit的工具 然后 运行时定 ...
- 手把手带你开发starter,点对点带你讲解原理
京东物流 孔祥东 _____ _ ____ _ / ____| (_) | _ \ | | | (___ _ __ _ __ _ _ __ __ _| |_) | ___ ___ | |_ \___ ...
- empty来显示暂无数据简直太好用,阻止用户复制文本user-select
element-ui表格某一列无数据显示-- 很多时候,表格的某一列可能是没有数据的. 空着了不好看,ui小姐姐会说显示 -- 这个时候,小伙伴是怎么做的呢? 使用循环来判断是否为空,然后赋值为-- ...
- echasrts定义折线图legend的样式-优化
option = { title: { text: '折线图堆叠' }, tooltip: { trigger: 'axis' }, //定义折线图legend的形状哈 legend: { itemW ...
- flutter项目目录介绍
1 flutter项目目录介绍 android 安卓平台的的相关代理 build 编译后的 ios ios 平台的的相关代理 lib 自己写代码的目录 包好自己的代码 资源 test 放测试文件的 p ...
- 【JS 逆向百例】cnki 学术翻译 AES 加密分析
关注微信公众号:K哥爬虫,QQ交流群:808574309,持续分享爬虫进阶.JS/安卓逆向等技术干货! 声明 本文章中所有内容仅供学习交流,抓包内容.敏感网址.数据接口均已做脱敏处理,严禁用于商业用途 ...
- Fabric网络升级(二)
原文来自这里. 如果想了解最新版Fabric的特殊事项,详见Upgrading to the latest release of Fabric. 本章只介绍更新Fabric组件的操作.关于如何通过编辑 ...
- pandas高效读取大文件的探索之路
使用 pandas 进行数据分析时,第一步就是读取文件.在平时学习和练习的过程中,用到的数据量不会太大,所以读取文件的步骤往往会被我们忽视. 然而,在实际场景中,面对十万,百万级别的数据量是家常便饭, ...
- 使用 arxiv-sanity &paperwithcode 跟进最新研究领域的文章
1.arxiv-sanity介绍 arxiv.org是一个非常大的预印本资源库,里面有大量的最新的论文,但缺点是浏览.搜索和排序不是很方便.这个资源库每天会更新大量的论文,如果通过手动搜索和浏览则效率 ...