[转帖]十九、Linux性能优化实战学习笔记- 为什么系统的Swap变高了?
目录
一、什么是文件页?什么是脏页?什么是匿名页?
1、缓存和缓冲区,就属于可回收内存。它们在内存管理中,通常被叫做文件页(File-backed Page),
此外除了缓存和缓冲区,通过内存映射获取的文件映射页,也是一种常见的文件页。它也可以被释放掉,下次再访问的时候,从文件重新读取。
2、大部分文件页,都可以直接回收,以后有需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放
脏页的写入磁盘的方式:
- 系统调用 fsync ,把脏页同步到磁盘中
- 也可以交给系统,由内核线程 pdflush 负责这些脏页的刷新
3、应用程序动态分配的堆内存称为匿名页(Anonymous Page)
堆内存很可能还要再次被访问,当然不能直接回收了。非常正确,这些内存自然不能直接释放。
但是,如果这些内存在分配后很少被访问,似乎也是一种资源浪费。是不是可以把它们暂时先存在磁盘里,释放内存给其他更需要的进程?这就是Linux 的 Swap 机制。Swap 把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
二、linux swap原理
Swap 把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
换出
把进程暂时不用的内存数据(经过上文分析主要是堆内存)存储到磁盘中,并释放这些数据占用的内存
换入
在进程再次访问这些内存的时候,把它们从磁盘读到内存中来。
给人的感觉是Swap 其实是把系统的可用内存变大了。这样,即使服务器的内存不足,也可以运行大内存的应用程序。其实在现在内存比较廉价的年代,对于追求高性能的业务完全可以关闭swap,因为内存和硬盘的速度在目前还存在瓶颈。
典型场景:
- 即使内存不足时,有些应用程序也并不想被 OOM 杀死,而是希望能缓一段时间,等待人工介入,或者等系统自动释放其他进程的内存,再分配给它。
- 我们常见的笔记本电脑的休眠和快速开机的功能,也基于 Swap 。休眠时,把系统的内存存入磁盘,这样等到再次开机时,只要从磁盘中加载内存就可以。这样就省去了很多应用程序的初始化过程,加快了开机速度
三、内存回收的时机
1、直接内存回收
有新的大块内存分配请求,但是剩余内存不足。这个时候系统就需要回收一部分内存(比如前面提到的缓存),进而尽可能地满足新内存请求。这个过程通常被称为直接内存回收
2、kswapd0内核线程
除了直接内存回收,还有一个专门的内核线程用来定期回收内存,也就是kswapd0。
为了衡量内存的使用情况,kswapd0 定义了三个内存阈值(watermark,也称为水位)
- 页最小阈值(pages_min)
- 页低阈值(pages_low)
- 页高阈值(pages_high)
剩余内存,则使用 pages_free 表。
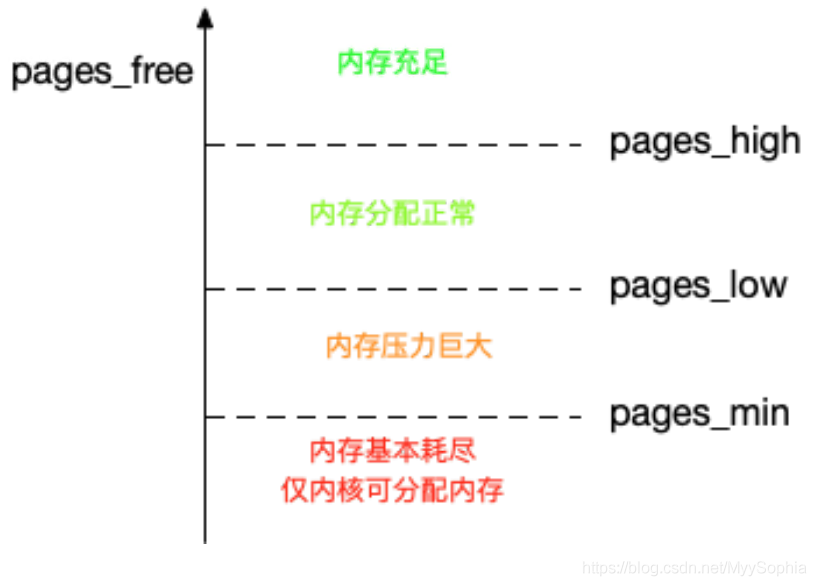
kswapd0 定期扫描内存的使用情况,并根据剩余内存落在这三个阈值的空间位置,进行内存的回收操作
- 剩余内存小于页最小阈值,说明进程可用内存都耗尽了,只有内核才可以分配内存。
- 剩余内存落在页最小阈值和页低阈值中间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值为止。
- 剩余内存落在页低阈值和页高阈值中间,说明内存有一定压力,但还可以满足新内存请求
- 剩余内存大于页高阈值,说明剩余内存比较多,没有内存压力。
一旦剩余内存小于页低阈值,就会触发内存的回收。这个页低阈值,其实可以通过内核选项 /proc/sys/vm/min_free_kbytes 来间接设置。min_free_kbytes 设置了页最小阈值,而其他两个阈值,都是根据页最小阈值计算生成的,计算方法如下
-
pages_low = pages_min*5/4
-
pages_high = pages_min*3/2
实际例子

四、内存回收的方式
一旦发现内存紧张,系统会通过三种方式回收内存。这三种方式分别是 :
- 基于 LRU(Least Recently Used)算法,回收缓存;
- 基于 Swap 机制,回收不常访问的匿名页;
- 基于 OOM(Out of Memory)机制,杀掉占用大量内存的进程
前两种方式,缓存回收和 Swap 回收,实际上都是基于 LRU 算法,也就是优先回收不常访问的内存。LRU 回收算法,实际上维护着 active 和 inactive 两个双向链表,其中:
- active 记录活跃的内存页;
- inactive 记录非活跃的内存页
越接近链表尾部,就表示内存页越不常访问。这样,在回收内存时,
系统就可以根据活跃程度,优先回收不活跃的内存。
活跃和非活跃的内存页,按照类型的不同,又分别分为文件页和匿名页,对应着缓存回收和 Swap 回收。
-
# grep 表示只保留包含 active 的指标(忽略大小写)
-
# sort 表示按照字母顺序排序
-
$ cat /proc/meminfo | grep -i active | sort
-
Active(anon): 167976 kB
-
Active(file): 971488 kB
-
Active: 1139464 kB
-
Inactive(anon): 720 kB
-
Inactive(file): 2109536 kB
-
Inactive: 2110256 kB
第三种方式,OOM 机制按照 oom_score 给进程排序。oom_score 越大,进程就越容易被系统杀死
当系统发现内存不足以分配新的内存请求时,就会尝试直接内存回收。这种情况下,如果回收完文件页和匿名页后,内存够用了,当然皆大欢喜,把回收回来的内存分配给进程就可以了。但如果内存还是不足,OOM 就要登场。
OOM 发生时,你可以在 dmesg 中看到 Out of memory 的信息,从而知道是哪些进程被 OOM 杀死了。比如,你可以执行下面的命令,查询 OOM 日志
dmesg | grep -i "Out of memory"
OOM什么时候会发生?
OOM 触发的时机基于虚拟内存。换句话说,进程在申请内存时,如果申请的虚拟内存加上服务器实际已用的内存之和,比总的物理内存还大,就会触发 OOM
因此不能单纯的看cache和 buffer还有很多,实际可回收的有多少呢?回收的能赶得上请求分配吗?
四、NUMA 与 Swap关系
很多情况下,你明明发现了 Swap 升高,可是在分析系统的内存使用时,却很可能发现,系统剩余内存还多着呢。为什么剩余内存很多的情况下,也会发生 Swap 呢?这正是处理器的 NUMA (Non-UniformMemory Access)架构导致的。
在 NUMA 架构下,多个处理器被划分到不同 Node 上,且每个 Node 都拥有自己的本地内存空间。而同一个 Node 内部的内存空间,实际上又可以进一步分为不同的内存域(Zone),比如直接内存访问区(DMA)、普通内存区(NORMAL)、伪内存区(MOVABLE)等,
如下图所示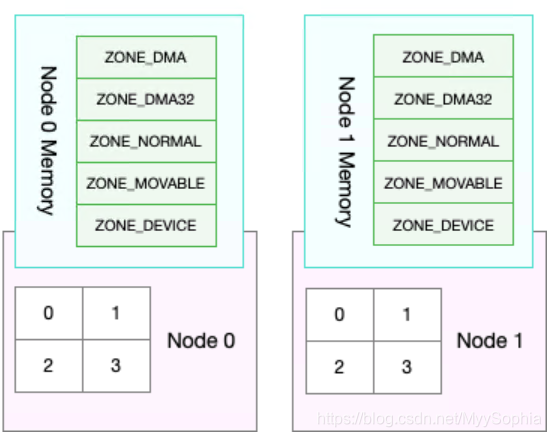
先不用特别关注这些内存域的具体含义,我们只要会查看阈值的配置,以及缓存、匿名页的实际使用情况就够了
既然 NUMA 架构下的每个 Node 都有自己的本地内存空间,那么,在分析内存的使用时,我们也应该针对每个 Node 单独分析。
你可以通过 numactl 命令,来查看处理器在 Node 的分布情况,以及每个 Node 的内存使用情况
-
tune]$ numactl --hardware
-
available: 2 nodes (0-1)
-
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35
-
node 0 size: 163710 MB
-
node 0 free: 654 MB
-
node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46 47
-
node 1 size: 163840 MB
-
node 1 free: 11017 MB
-
node distances:
-
node 0 1
-
0: 10 21
-
1: 21 10
这个界面显示,我的系统中有两个 Node
编号为 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35的24个CPU, 都位于 Node 0 上。
编号为12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46 47 的24个CPU, 都位于 Node1 上。
另外,Node 0 的内存大小为 163710 MB,剩余内存为 654MB
Node 1 的内存大小为 163840 MB,剩余内存为 11017MB
了解了 NUNA 的架构和 NUMA 内存的查看方法后,你可能就要问了这跟 Swap 有什么关系呢?
前面提到的三个内存阈值(页最小阈值、页低阈值和页高阈值),都可以通过内存域在 proc 文件系统中的接口 /proc/zoneinfo 来查看
pages 处的 min、low、high,就是上面提到的三个内存阈值,而 free 是剩余内存页数,它跟后面的 nr_free_pages 相同。
nr_zone_active_anon 和 nr_zone_inactive_anon,分别是活跃和非活跃的匿名页数。
nr_zone_active_file 和 nr_zone_inactive_file,分别是活跃和非活跃的文件页数
剩余内存远大于页高阈值,所以此时的 kswapd0 不会回收内存。
某个 Node 内存不足时,系统可以从其他 Node 寻找空闲内存,也可以从本地内存中回收内存。具体选哪种模式,你可以通过 /proc/sys/vm/zone_reclaim_mode来调整
- 默认的 0 ,表示既可以从其他 Node 寻找空闲内存,也可以从本地回收内存。
- 1、2、4 都表示只回收本地内存
- 2 表示可以回写脏数据回收内存4 表示可以用Swap 方式回收内存
五、swappiness
- 对文件页的回收,当然就是直接回收缓存,或者把脏页写回磁盘后再回收。
- 对匿名页的回收,其实就是通过 Swap 机制,把它们写入磁盘后再释放内存
既然有两种不同的内存回收机制,那么在实际回收内存时,到底该先回收哪一种呢?
Linux 提供了一个 /proc/sys/vm/swappiness选项,用来调整使用 Swap 的积极程度。
swappiness 的范围是 0-100,数值越大,越积极使用 Swap,也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页
swappiness 的范围是 0-100,不过要注意,这并不是内存的百分比,而是调整Swap 积极程度的权重,即使你把它设置成 0,当剩余内存 + 文件页小于页高阈值时,还是会发生 Swap。
[转帖]十九、Linux性能优化实战学习笔记- 为什么系统的Swap变高了?的更多相关文章
- Linux性能优化实战学习笔记:第四十九讲
一.上节回顾 上一期,我们一起梳理了,网络时不时丢包的分析定位和优化方法.先简单回顾一下.网络丢包,通常会带来严重的性能下降,特别是对 TCP 来说,丢包通常意味着网络拥塞和重传,进而会导致网络延迟增 ...
- Linux性能优化实战学习笔记:第四十五讲
一.上节回顾 专栏更新至今,四大基础模块的最后一个模块——网络篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,热情地留言和互动.还有不少同学分享了在实际生产环境中,碰到各种性能 ...
- Linux性能优化实战学习笔记:第三十二讲
一.上节总结 专栏更新至今,四大基础模块的第三个模块——文件系统和磁盘 I/O 篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,并且热情地留言与讨论. 今天是性能优化的第四期. ...
- Linux性能优化实战学习笔记:第三十六讲
一.上节总结回顾 上一节,我们回顾了经典的 C10K 和 C1000K 问题.简单回顾一下,C10K 是指如何单机同时处理 1 万个请求(并发连接 1 万)的问题,而 C1000K 则是单机支持处理 ...
- Linux性能优化实战学习笔记:第四十三讲
一.上节回顾 上一节,我们了解了 NAT(网络地址转换)的原理,学会了如何排查 NAT 带来的性能问题,最后还总结了 NAT 性能优化的基本思路.我先带你简单回顾一下. NAT 基于 Linux 内核 ...
- Linux性能优化实战学习笔记:第四十四讲
一.上节回顾 上一节,我们学了网络性能优化的几个思路,我先带你简单复习一下. 在优化网络的性能时,你可以结合 Linux 系统的网络协议栈和网络收发流程,然后从应用程序.套接字.传输层.网络层再到链路 ...
- Linux性能优化实战学习笔记:第五十二讲
一.上节回顾 上一节,我们一起学习了怎么使用动态追踪来观察应用程序和内核的行为.先简单来回顾一下.所谓动态追踪,就是在系统或者应用程序还在正常运行的时候,通过内核中提供的探针,来动态追踪它们的行为,从 ...
- Linux性能优化实战学习笔记:第五十五讲
一.上节回顾 上一节,我们一起学习了,应用程序监控的基本思路,先简单回顾一下.应用程序的监控,可以分为指标监控和日志监控两大块. 指标监控,主要是对一定时间段内的性能指标进行测量,然后再通过时间序列的 ...
- Linux性能优化实战学习笔记:第五十六讲
一.上节回顾 上一节,我带你一起梳理了,性能问题分析的一般步骤.先带你简单回顾一下. 我们可以从系统资源瓶颈和应用程序瓶颈,这两个角度来分析性能问题的根源. 从系统资源瓶颈的角度来说,USE 法是最为 ...
- Linux性能优化实战学习笔记:第五十八讲
一.上节回顾 专栏更新至今,咱们专栏最后一部分——综合案例模块也要告一段落了.很高兴看到你没有掉队,仍然在积极学习思考.实践操作,并热情地分享你在实际环境中,遇到过的各种性能问题的分析思路以及优化方法 ...
随机推荐
- 现代 CMake 模块化项目管理指南
现代 CMake 模块化项目管理指南 参考小彭老师的视频教程整理笔记,学习同时方便快速查阅,视频链接如下 [公开课]现代 CMake 模块化项目管理指南[C/C++] 对应课程 PPT 和源码见 ht ...
- Pikachu漏洞靶场 Over Permission(越权)
Over Permission(越权) 文章目录 Over Permission(越权) 水平越权 垂直越权 水平越权 首先根据提示信息的账号密码登录: 点击查看个人信息: 抓包之后发现查的人是在UR ...
- AutomaticKeepAliveClientMixin 缓存PageView页面
一旦页面滑出屏幕它就会被销毁 ,实际项目开发中对页面进行缓存是很常见的一个需求,下面我们就看看如何使用AutomaticKeepAliveClientMixin 缓存页面. 注意:使用时一定要注意是否 ...
- 在 K8S 大规模场景下, Service 性能如何优化?
摘要:Kubernetes 原生的 Service 负载均衡基于 Iptables 实现,其规则链会随 Service 的数量呈线性增长,在大规模场景下对 Service 性能影响严重.本文分享了华为 ...
- PPT MBE风格的插画
两种或多种不同的图形,通过合并形状等一些操作叫布尔运算 渐变模式 线性渐变:几个不同的颜色[垂直] 射线渐变:圆形弧度的渐变 矩形渐变:矩形 路径渐变:中心形状和外面形状保持一致 渐变方向 射线渐变方 ...
- Selenium八大元素定位(元素定位,元素等待)
Selenium WebDriver查找页面元素及元素操作 元素常用方法定位方法 通过id定位元素:find_element_by_id('id_value') 通过name定位元素:find_ele ...
- 跟着老猫来搞GO,系好安全带,准备发车!
为什么想要开篇这么一个系列博客主题? 我想有很多小伙伴想要问我这个,其实主要有以下几个原因. 在粉丝面前丢脸了 之前写过几篇关于java分布式系统的一些坑,然后就有小伙伴挺崇拜的,认为老猫啥都会,甚至 ...
- python 正则表达式简单使用
定义: 正则表达式,又称规则表达式,通常被用来检索.替换那些符合某个模式(规则)的文本. 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个&quo ...
- 详解 SSL(三):SSL 证书该如何选择?
在上一篇< 详解 SSL(二):SSL 证书对网站的好处>中,我们知道了在网站部署 SSL 证书后,不管是对网站本身还是对网站的用户都能够带来许多好处.那么随着 HTTPS 的普及,市面上 ...
- 【JAVA基础】日志管理
LOGGER.debug("Request uri: {}, headers: {}", signedRequest.getURI(), signedRequest.getAllH ...