AcWing 【算法提高课】笔记02——搜索
搜索进阶
22.4.14
(PS:还有 字串变换 A*两题 生日蛋糕 回转游戏 没做)
感觉暂时用不上
BFS
1. Flood Fill

在线性时间复杂度内,找到某个点所在的连通块
思路
统计连通块个数(多个连通块):逮着一个就开搜
连通性问题(能走多远,迷宫性问题,一个连通块);起点开始搜
池塘计数
城堡问题
int dx[] = {0, -1, 0, 1}, dy[] = {-1, 0, 1, 0}; //按照西北东南的顺序
int bfs (int x, int y) {
int area = 0;
q.push ({x, y});
area ++; //别忘了算自身
vis[x][y] = true;
while (!q.empty()) {
auto tt = q.front();
q.pop();
for (int i = 0; i < 4; i ++) {
int xx = tt.first + dx[i], yy = tt.second + dy[i];
if (!Range (xx, yy) || vis[xx][yy])
continue;
if (a[tt.first][tt.second] >> i & 1) //二进制表示四周的情况
continue;
q.push ({xx, yy});
area ++;
vis[xx][yy] = true;
}
}
return area;
}
山峰和山谷
核心代码
dfs()函数内部:
if (a[xx][yy] != a[tt.first][tt.second]) {
if (a[xx][yy] > a[tt.first][tt.second])
hh = true; //有比他高的,所以一定不是山峰
else
ll = true; //有比他矮的,所以一定不是山谷
}
//要注意vis出现在这里是因为,不同高度的格子是可以重复遍历的,相同的才要判重
else if (!vis[xx][yy]){
q.push ({xx, yy});
vis[xx][yy] = true;
}
main()函数内部:
if (!vis[i][j]) {
bool hh = false, ll = false; //hh代表有无比他高的,ll代表有无比他矮的
bfs (i, j, hh, ll);
if (!hh)
cnt1 ++; //没有比他高的,是山峰
if (!ll)
cnt2 ++; //没有比他矮的,是山谷
}
2. 最短路模型
迷宫问题
多加一个:记录该点是从哪个点走过来的
注意是从终点开始的BFS(反向搜的话输出的路径就是正向的)
void bfs (int x, int y) {
q.push ({x, y});
memset (ans, -1, sizeof ans);
ans[x][y] = {0, 0};
while (!q.empty()) {
auto tt = q.front();
q.pop();
for (int i = 0; i < 4; i ++) {
int xx = tt.first + dx[i], yy = tt.second + dy[i];
if (!Range(xx, yy) || a[xx][yy])
continue;
if (ans[xx][yy].first != -1) //已经被更新过了,必然不是最短
continue;
q.push ({xx, yy});
ans[xx][yy] = tt;
}
}
}
武士风度的牛
抓住那头牛
这俩都是同一类型的简单题
3. 多源BFS
只更新一次。反着来,通过1更新0
4. 最小步数模型
稍显烦人的模拟
5. 双端队列广搜
无向图,边权为0 / 1 (0表示连通,1表示不连通),求起点到终点的最短路径
(经典01问题)双端队列广搜:边权为1加到队尾,边权为0插到队头
一些性质:
当起点和终点的奇偶性不一样时(到达不了),NO SOLUTION
搞清楚格点,和格子下标
实现:类dijkstra + deque维护
6. 双向广搜
庞大空间
每次选择当前队列当中元素数量较少的进行拓展
7. A*
useless 主要是我不会。。先放一放
DFS
0. 判断是否需要回溯
若把图当成固定的,那么不需要回溯,只走一次(把点当作状态)
若考虑图变换,需要回溯,恢复状态(把棋盘当作状态)
1. 剪枝
1. 优化搜索顺序
优先搜索分支少的节点
2. 排除等效冗余
不要搜索重复状态
3. 可行性剪枝
不合法就退出
4. 最优性剪枝
已达最优状态
5. 记忆化搜索(DP)
例题
小猫爬山
填满旧车,开新车
数独
位运算优化:用一个9位01串来表示,再把行 列 九宫格 的状态与起来,该位上为1,就代表可以放这个数字
木棍
- 枚举sum的约数(保证能被整除)
- 优化搜索顺序:先枚举长的木棍
- 排除等效冗余:
- 按照组合数的方式来枚举
- 与已经失败的木棍长度相同所有 的一定也不行
- 如果某木棒放第一根木棍u导致当前这根木棒凑不成length,整个方案一定失败
- 如果木棒的最后一根木棍 u 放在这里导致后续方案失败,则整个方案一定失败
2. 迭代加深
适用:层数很深,答案很浅
定一个层数上限,搜出去了就减掉
逐步扩大范围
层层扩大,按层搜索
剪枝:
优化搜索顺序:从大到小
排除等效冗余:vis[]
bool dfs (int u, int k) { //u当前层数,k限制层数
if (u == k) //搜到限制那层了
return path[u - 1] == n; //如果最后的值是n,那么表示找到答案了
memset (vis, false, sizeof vis); //用于排除等效冗余
//从大到小,优化搜索顺序
for (int i = u - 1; i >= 0; i --)
for (int j = i; j >= 0; j --) {
int s = path[i] + path[j];
//搜过头了,答案不在此处 || 不满足逐层扩大的特点 || 等效冗余
if (s > n || s <= path[u - 1] || vis[s])
continue;
vis[s] = true;
path[u] = s;
if (dfs (u + 1, k))
return true;
}
return false;
}
3. 双向DFS
useful algo (指二分和暴力/doge)的美妙结合
双向爆搜,把一半打表(记得去重),另一半在表中二分查找
- 先搜大的
- 先将前 k 件物品能凑出的所有重量打表,再排序去重
- 搜索剩下的 n - k 件物品的选择方式,在表中二分找出不超过 W 的最大值
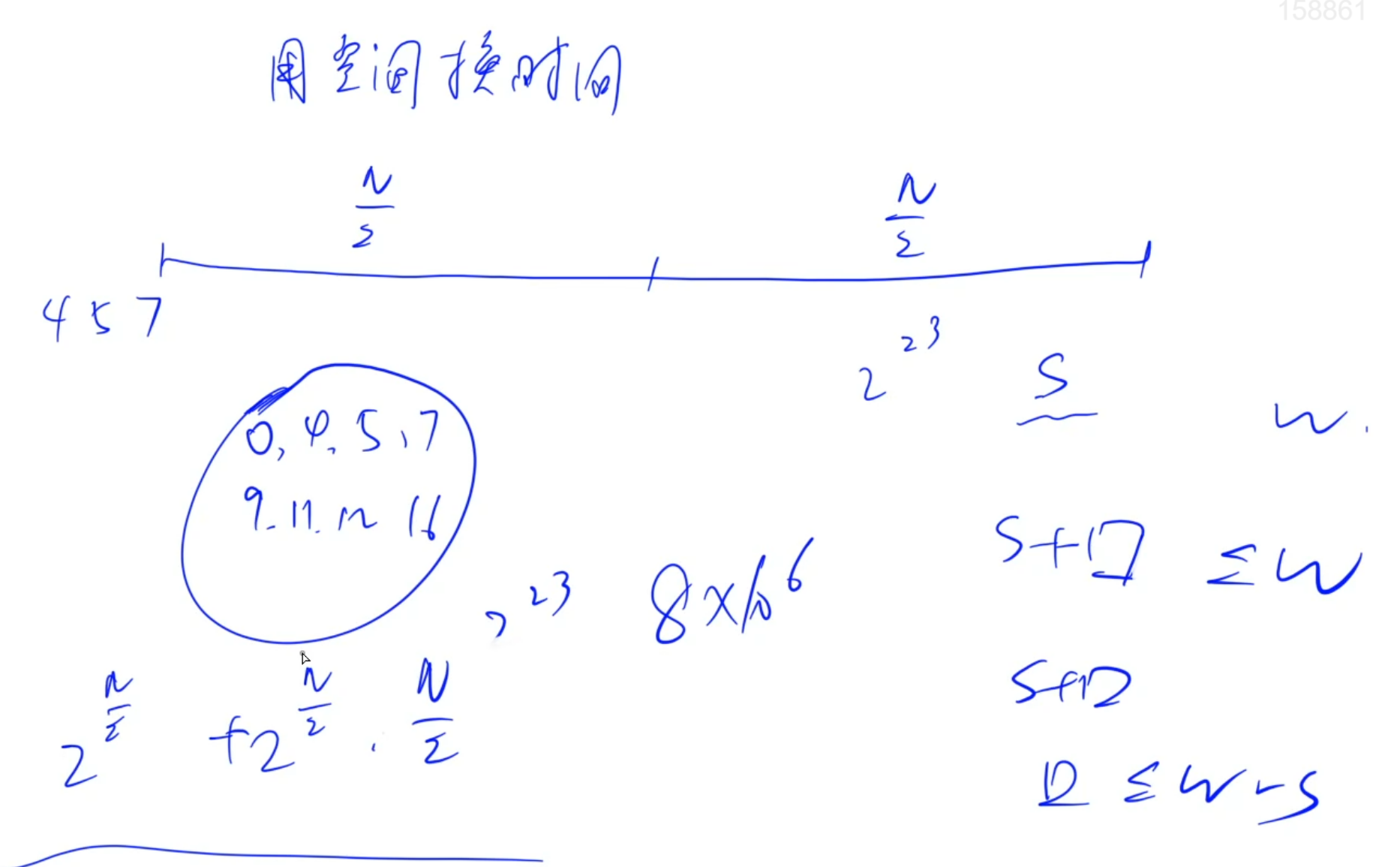
此题有背包的思想
// u表示当前枚举到哪个数了, s表示当前的和
void dfs(int u, int s)
{
// 如果我们当前已经枚举完第k个数(下标从0开始的)了, 就把当前的s, 加到weights中去
if (u == k) {
weights[cnt++] = s;
return;
}
// 枚举当前不选这个物品
dfs(u + 1, s);
// 选这个物品, 做一个可行性剪枝
if ((LL)s + g[u] <= m) { //计算和的时候转成long long防止溢出
dfs(u + 1, s + g[u]);
}
}
void dfs2(int u, int s)
{
if (u == n) { // 如果已经找完了n个节点, 那么需要二分一下
int l = 0, r = cnt - 1;
while (l < r) {
int mid = (l + r + 1) >> 1;
if (weights[mid] <= m - s)
l = mid;
else
r = mid - 1;
}
ans = max(ans, weights[l] + s);
return;
}
// 不选择当前这个物品
dfs2(u + 1, s);
// 选择当前这个物品
if ((LL)s + g[u] <= m)
dfs2(u + 1, s + g[u]);
}
int main()
{
cin >> m >> n;
for (int i = 0; i < n; i++)
cin >> g[i];
// 优化搜索顺序(从大到小)
sort(g, g + n);
reverse(g, g + n);
k = n / 2 + 2; // 把前k个物品的重量打一个表
dfs(0, 0);
// 做完之后, 把weights数组从小到大排序
sort(weights, weights + cnt);
// 判重
int t = 1;
for (int i = 1; i < cnt; i++)
if (weights[i] != weights[i - 1])
weights[t++] = weights[i];
cnt = t;
// 从k开始, 当前的和是0
dfs2(k, 0);
cout << ans << endl;
return 0;
}
4. IDA*
迭代加深 + 估价函数
在迭代加深的基础上,搜到当前这一步时,估计一下当前点搜到答案所需步数,如果该步数超过限制,就直接剪掉
估价函数 \(\leq\) 真实值
排书
枚举长度:长度为 i ** 的段有 n - i + 1 种,把这个区间拿出来之后,会剩下 n - i 个数,产生n - i + 1 ** 个空挡,除去自身原本所在地,可放置的空挡就有n - i个。
所以有(n - i + 1) * (n - i)种选择。另外,将某一段向前移动,等价于将跳过的那段向后移动,因此每种移动方式被算了两遍
\[\sum_{i = 1}^{n}\frac{(n-i+1)(n-i)}{2}=\frac{n(n+1)(n+2)}{3*2}
\]估价函数:(改变如何体现)更改后继关系(每次操作变3个)
所以用 tot 统计有多少个不正确的后继关系,则操作次数\(cnt\) 为
\]
int f() {
int cnt = 0; //统计不正确的后继
for (int i = 1; i < n; i ++)
if (a[i] != a[i - 1] + 1)
cnt ++;
return (cnt + 2) / 3;
} //估价函数,每次改变三个后继
bool dfs (int u, int lim) {
if (u + f() > lim)
return false; //超出最大限度,可行性剪枝
if (f() == 0)
return true; //全部后继都合法了,我滴任务完成啦!
for (int len = 1; len <= n; len ++)
for (int i = 0; i < n - len + 1; i ++) {
int l = i, r = i + len - 1;
for (int k = r + 1; k < n; k ++) {
memcpy (w[u], a, sizeof a); //备份当前层
//进行交换操作
int y = l;
for (int x = r + 1; x <= k; x ++, y ++)
a[y] = w[u][x];
for (int x = l; x <= r; x ++, y ++)
a[y] = w[u][x];
if (dfs (u + 1, lim))
return true; //合法不?
memcpy (a, w[u], sizeof a); //回复
}
}
return false;
}
回转游戏
AcWing 【算法提高课】笔记02——搜索的更多相关文章
- ACwing算法基础课听课笔记(第一章,基础算法一)(二分)
二分法: 在看这个视频前,我对于二分法是一头雾水的,又加上这个算法平常从来没写过所以打了一年了还没正式搞过.视频提到ACwing上的一道题,我用自以为聪明的方法去做,结果TLE了,实在丢人,不说了,开 ...
- ACwing算法基础课听课笔记(第一章,基础算法二)(差分)
前缀和以及二维前缀和在这里就不写了. 差分:是前缀和的逆运算 ACWING二维差分矩阵 每一个二维数组上的元素都可以用(x,y)表示,对于某一元素(x0,y0),其前缀和就是以该点作为右下角以整 ...
- 背包四讲 (AcWing算法基础课笔记整理)
背包四讲 背包问题(Knapsack problem)是一种组合优化的NP完全问题.问题可以描述为:给定一组物品,每种物品都有自己的重量和价格,在限定的总重量内,我们如何选择,才能使得物品的总价格最高 ...
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能. 核心思想 在使用某个特定的算法是, ...
- 机器学习实战(Machine Learning in Action)学习笔记————02.k-邻近算法(KNN)
机器学习实战(Machine Learning in Action)学习笔记————02.k-邻近算法(KNN) 关键字:邻近算法(kNN: k Nearest Neighbors).python.源 ...
- 【转载】 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
原文地址: https://www.cnblogs.com/steven-yang/p/5686473.html ------------------------------------------- ...
- 算法笔记_155:算法提高 概率计算(Java)
目录 1 问题描述 2 解决方案 1 问题描述 问题描述 生成n个∈[a,b]的随机整数,输出它们的和为x的概率. 输入格式 一行输入四个整数依次为n,a,b,x,用空格分隔. 输出格式 输出一行 ...
- 算法笔记_166:算法提高 金属采集(Java)
目录 1 问题描述 2 解决方案 1 问题描述 问题描述 人类在火星上发现了一种新的金属!这些金属分布在一些奇怪的地方,不妨叫它节点好了.一些节点之间有道路相连,所有的节点和道路形成了一棵树.一共 ...
- 算法笔记_165:算法提高 道路和航路(Java)
目录 1 问题描述 2解决方案 1 问题描述 问题描述 农夫约翰正在针对一个新区域的牛奶配送合同进行研究.他打算分发牛奶到T个城镇(标号为1..T),这些城镇通过R条标号为(1..R)的道路和P条 ...
随机推荐
- [root-me](web-client)write up 一个大坑怎么填啊
root-me web-client writeup 地址:www.root-me.org HTML - disabled buttons 打开网页发现按钮不能按,查看源代码,有 'disabled' ...
- TiDB 5.0认证指南之PCTA PCTP
1. TiDB简介 TiDB 是 PingCAP 公司自主设计.研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analyt ...
- SpringCloudAlibaba 微服务讲解(四)Sentinel--服务容错(一)
4.1 高并发带来的问题 在微服务中,我们将业务拆分成一个个的服务,服务与服务之间可以相互调用,但是由于网络原因或者自身的原因,服务并不能保证100%可用,如果单个服务出现问题,调用这个服务就会出现网 ...
- EMQX_AUTH_USERNAME 使用
emqx_auth_username 它通过比对每个终端的接入的 username 和 password 与 EMQ X 中存储的是否一致来实现终端接入的控制.其功能逻辑如下: emqx_auth_u ...
- SpringBoot单元测试携带Cookie
由于我SpringBoot项目,集成了SpringSecurity,而Security框架使用Redis存储Session,所以,这里列出几个关键的类 org.springframework.sess ...
- Eclipse建立Web项目,手动生成web.xml文件
相关文章:https://blog.csdn.net/ys_code/article/details/79156188(Web项目建立,手动生成web.xml文件
- 云计算:Ubuntu下Vue+Springboot前后端分离项目部署(多节点)
一.机器准备 首先准备三台机器: 我是一台WINDOWS系统主机,在WINDOWS里的 VMware 中安装两台Ubuntu系统虚拟机 如果你的虚拟机只有 CentOS,可以参考这篇文章:https: ...
- Effective Java —— 避免创建不必要的对象
本文参考 本篇文章参考自<Effective Java>第三版第六条"Avoid creating unnecessary objects" avoid creatin ...
- H5活动全屏滚动页面在安卓智能电视TV调试
前段时间公司做一个线上活动,在电视上商品促销.产品的要求是每个商品介绍刚好满一屏,按下遥控器向下键可以整屏切换.这种功能如果实在PC端,实现起来非常容易,引用jQuery插件就能实现.但是在安卓智能电 ...
- 深入理解ES6之《扩展对象》
属性初始值的简写 当对象字面量只有一个属性的名称时,JS引擎会在可访问作用域中查找其同名变量:如果找到则该变量的值被赋给对象字面量里的同名属性 function createPerson(name, ...