Python 康德乐大药房网站爬虫,使用bs4获取json,导入mysql
故事开端
目标地址
https://www.baiji.com.cn 康德乐大药房
程序流程
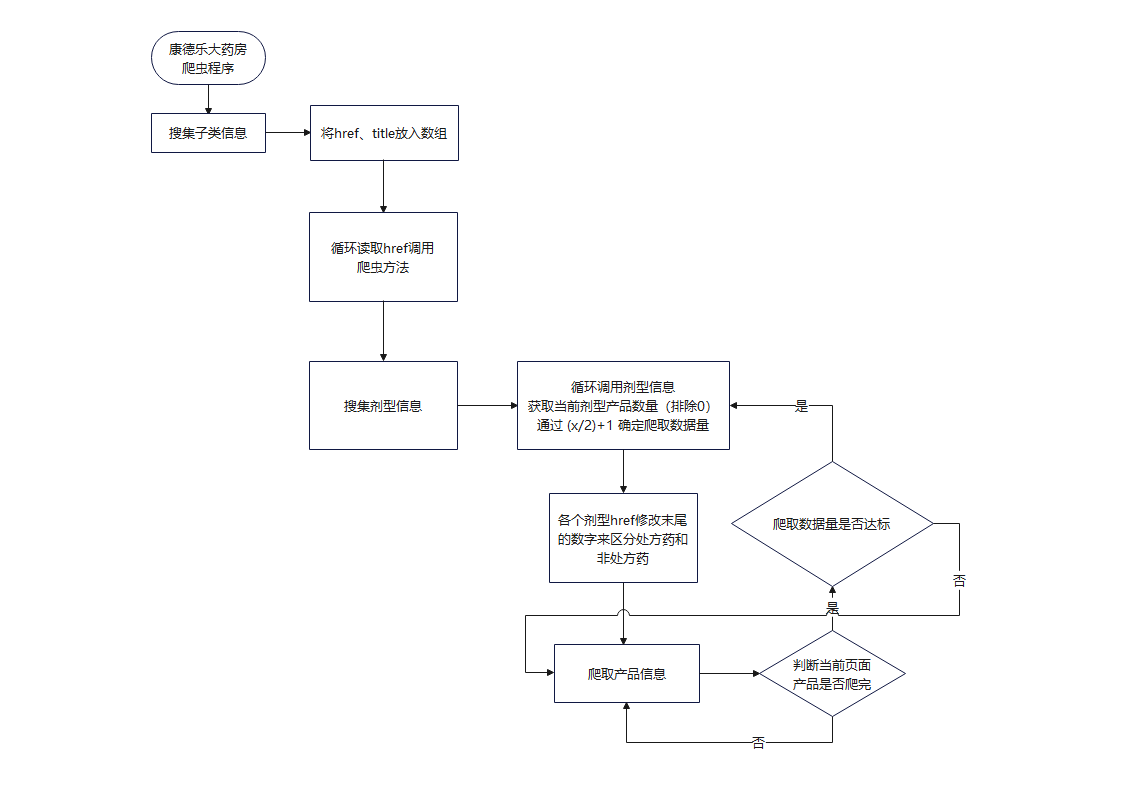
"爬取数量是否达标"这块没有写代码,因为我发现单页数量够多了,每页爬一半数据大概有8000条
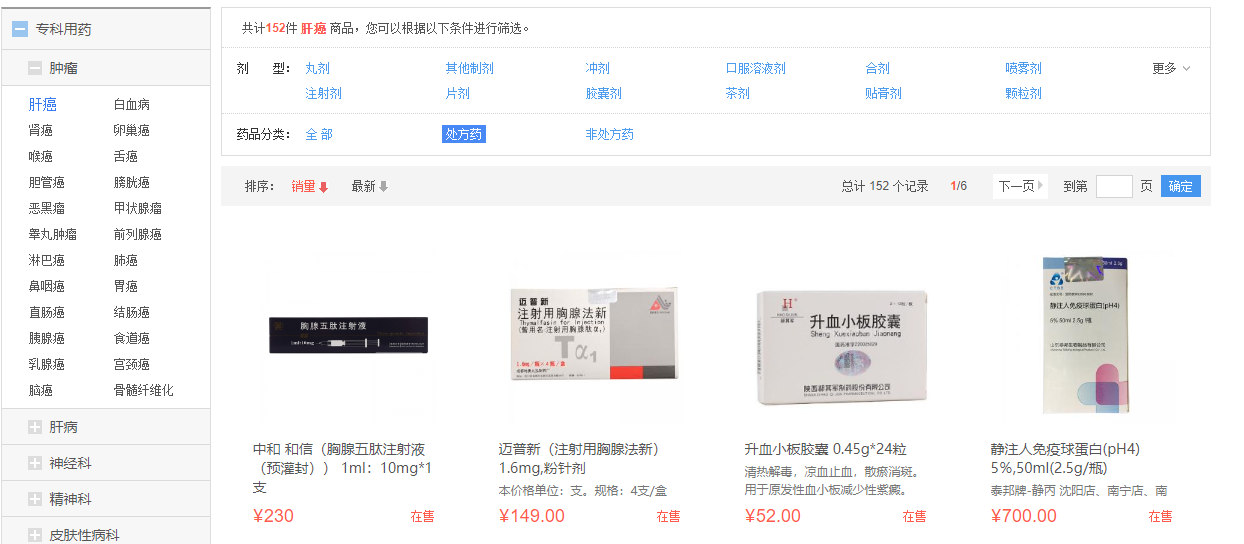
获取商品价格接口
我发现商品价格在soup结构里面没有生成,是空值,应该是动态请求加载的。
就讲一下这部分接口我是怎么获取的吧,使用软件 Fiddler 进行抓包,如果你不知道这是什么 Fiddler使用方式
随便打开一个网站
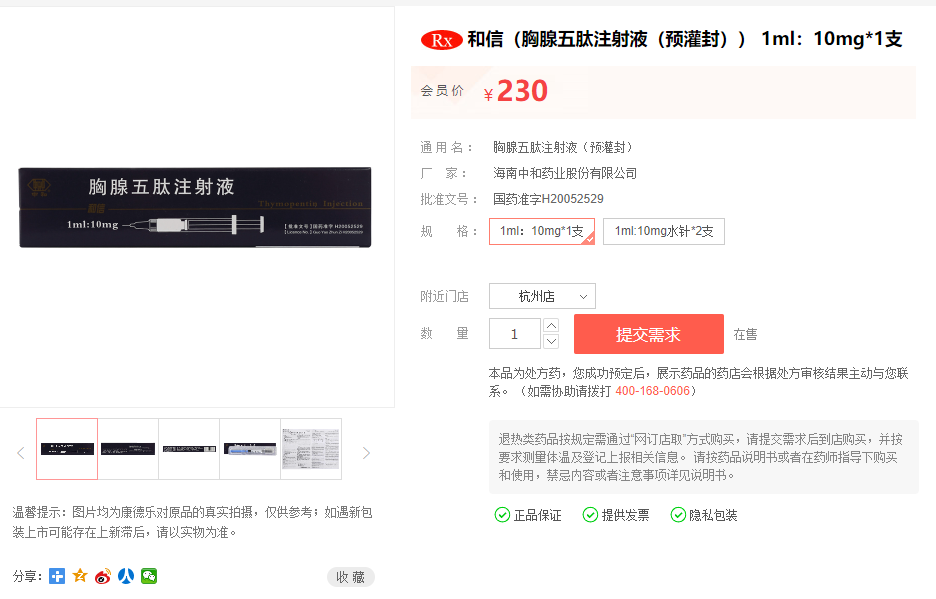

可以看到请求的地址,这是一个 get 请求,包含了三个参数分别是 jsonp+时间戳、act 方法、goods_id 商品id,返回体是一个json,显示商品价格(注意!商品可能缺货会返回 {"price":"特价中"},所以要做判断处理,可以看 spider.py 里的 product() 函数)
# ^ 获取价格
goods_id = re.search(r'\d+', href).group(0)
url = "https://www.baiji.com.cn/domain/goods_info.php?fn=jsonp{}&act=goods_info&goods_id={}".format(int(time.time()), goods_id)
headers_2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39',
'Referer': "https://www.baiji.com.cn/goods-{}.html".format(goods_id)
}
cookie = {
'Cookie': 'NTKF_T2D_CLIENTID=guest59D35491-8F98-DD91-B9BE-A1ADEB5C6CBF; real_ipd=112.10.183.174; UserId=0; kdlusername=0; kdl_username=0; ECS_ID=887e4472a5a3613c59df1c0e60cc2a93a40d401e; nTalk_CACHE_DATA={uid:kf_9261_ISME9754_guest59D35491-8F98-DD,tid:1647709025522701}; ECS[history]=7526%2C7522%2C14684%2C15717%2C11560; arp_scroll_position=300'
}
res = requests.get(url, headers=headers_2, cookies=cookie, timeout=None)
res.encoding = "utf-8"
MyJson = loads_jsonp(res.text)
try:
price = float(MyJson['price'])
except:
price = 0
isStockOut = True可以看到我们先处理了 jsonp 转化为 json 对象,对取得的 json 的 price 键对应值进行 float 类型转换,如果转换失败会抛出异常,我们使用 try: ? expect: ? 的方式进行判断
代码
代码写的很难看,但是能用,Wow!It just works!
work.py
import os
import json
import threading
import requests
import re
import time
from spider import Spider
from bs4 import BeautifulSoup
class MyThread(threading.Thread):
"""重写多线程,使其能够返回值"""
def __init__(self, target=None, args=()):
super(MyThread, self).__init__()
self.func = target
self.args = args
def run(self):
self.result = self.func(*self.args)
def get_result(self):
try:
return self.result # 如果子线程不使用join方法,此处可能会报没有self.result的错误
except Exception:
return None
host = "https://www.baiji.com.cn"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'
}
res = requests.get(host, headers=headers)
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, "html.parser")
item_list = soup.find_all(class_='tcon')
items = []
for item in item_list:
a = item.find_all('a')
for i in a:
href = i['href'].strip('// http:')
title = i['title']
if re.search('category', href) != None:
items.append((href, title))
# ^ only for test 暴力开启多线程
infos = []
threads = []
start = time.perf_counter()
for item in items:
t = MyThread(target=Spider, args=(item,))
threads.append(t)
t.start()
print('启动!')
# ^ 等待所有子线程结束,主线程再运行
for t in threads:
t.join()
result = t.get_result()
infos.extend(result)
with open('data.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(infos, indent=4, ensure_ascii=False))
exit()spider.py
import time
import os
import json
import requests
import re
from bs4 import BeautifulSoup
COUNT = 0
host = "https://"
host_ = "https://www.baiji.com.cn/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'
}
path = os.path.dirname(__file__)
# ^ 主入口
def Spider(item):
# temp = []
# isPrescription = False
category = item[1]
classes = CatchClasses(item[0])
infos = GoPage(classes, category)
return infos
# ^ 获取所有剂型
def CatchClasses(url):
res = requests.get(host+url, headers=headers)
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, "html.parser")
temp = soup.find(class_="det").find_all('a')
classes = [a['href'] for a in temp]
titles = [a['title'] for a in temp]
return [classes, titles]
# ^ 进行爬虫
def GoPage(classes, category):
isPrescribed = True
length = len(classes[0])
href = classes[0]
titles = classes[1]
infos = []
for index, h_ in enumerate(href):
Collect(h_, '-0.html', titles, index, category, infos)
# ---------------------------------------------------------------------------- #
Collect(h_, '-1.html', titles, index, category, infos)
print('已处理', COUNT, '个商品')
return infos
def Collect(h_, add, titles, index, category, infos):
h = h_.replace('.html', add)
url = host_ + h
res = requests.get(url, headers=headers)
res.encoding = "utf-8"
# ^ 获取该类别共几条商品记录
target = re.findall(r'共计<strong class="red">\d+</strong>', res.text)
target = re.search(r'\d+', target[0]).group(0)
target = int(target)
# ^ 如果商品记录为 0 直接跳过
if target != 0:
# ^ 减少爬的数据量
target = int(target/2+1)
print(titles[index], "需要获取的数据条目", target)
isPrescribed = False
products = GetProducts(h)
print("非处方页面共有", len(products), "个商品", time.ctime())
for product in products:
info = Product(product, index)
info['category'] = category
info['isPrescribed'] = isPrescribed
info['class'] = titles[index]
infos.append(info)
# ^ 获取当前页面所有产品
def GetProducts(url):
res = requests.get(host_+url, headers=headers)
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, "html.parser")
products = soup.find_all(class_='pro_boxin')
return products
# ^ 解析jsonp对象
def loads_jsonp(_jsonp):
try:
return json.loads(re.match(".*?({.*}).*", _jsonp, re.S).group(1))
except:
raise ValueError('Invalid Input')
# ^ 获取指定商品信息
# @ info 传入一个 class = pro_boxin 的soup对象
def Product(p, category):
global COUNT
COUNT += 1
a = p.find(class_="name").a
isStockOut = False # IMPORTANT
productname = a['title'] # IMPORTANT
QuantityPerunit = a.contents[0].strip().split(' ')[1] # IMPORTANT
describe = a.span.string # IMPORTANT
img = p.find('img')
try:
imageSrc = img['data-original'].strip('//') # IMPORTANT
# ^ 下载图片到本地
imageSrc = DownloadPic(imageSrc, category)
except:
imageSrc = None
# ^ 准备获取商品页面
href = a['href'] # IMPORTANT
# print(productname, unit, href)
# ^ 获取价格
goods_id = re.search(r'\d+', href).group(0)
url = "https://www.baiji.com.cn/domain/goods_info.php?fn=jsonp{}&act=goods_info&goods_id={}".format(int(time.time()), goods_id)
headers_2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39',
'Referer': "https://www.baiji.com.cn/goods-{}.html".format(goods_id)
}
cookie = {
'Cookie': 'NTKF_T2D_CLIENTID=guest59D35491-8F98-DD91-B9BE-A1ADEB5C6CBF; real_ipd=112.10.183.174; UserId=0; kdlusername=0; kdl_username=0; ECS_ID=887e4472a5a3613c59df1c0e60cc2a93a40d401e; nTalk_CACHE_DATA={uid:kf_9261_ISME9754_guest59D35491-8F98-DD,tid:1647709025522701}; ECS[history]=7526%2C7522%2C14684%2C15717%2C11560; arp_scroll_position=300'
}
res = requests.get(url, headers=headers_2, cookies=cookie, timeout=None)
res.encoding = "utf-8"
MyJson = loads_jsonp(res.text)
try:
price = float(MyJson['price'])
except:
price = 0
isStockOut = True
# print(price)
return dict(
productname=productname,
QuantityPerunit=QuantityPerunit,
unitprice=price,
isStockOut=isStockOut,
notes=describe,
imageSrc=imageSrc
)
def DownloadPic(src, category):
category = str(category+1)
# print(src)
fileName = src.split('/')
fileName.reverse()
fileName = fileName[0].strip('/')
# print(fileName)
pic = requests.get(host+src)
savePath = path+'/goods_img/'+category+'/'
isExists = os.path.exists(savePath)
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(savePath)
with open(savePath+fileName, 'wb') as b:
b.write(pic.content)
return '/goods_img/'+category+'/'+fileName
json_to_mysql.py
import os
import json
import random
import mysql.connector
path = os.path.dirname(__file__)
db = mysql.connector.connect(
host="localhost",
user="root",
passwd="sql2008",
database="test",
auth_plugin='mysql_native_password'
)
cursor = db.cursor()
with open(path+'/data.json', 'r', encoding='utf-8') as f:
data = json.load(f)
print(data[0], len(data))
cursor.execute("SELECT categoryid, categoryname FROM t_categorytreeb")
res = cursor.fetchall()
categoryid = [i[0] for i in res]
categoryname = [i[1] for i in res]
print(categoryname.index('丙肝'))
cursor.execute("SELECT supplierid FROM t_suppliers")
res = cursor.fetchall()
suppliers = [i[0] for i in res]
print(suppliers)
# ^ 插入数据
sql = "INSERT INTO t_medicines(ProductName,QuantityPerunit,Unitprice,SupplierID,SubcategoryID,Photopath,notes,ytype,isPrescribed,isStockOut) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
val = [
]
print()
for item in data:
try:
# print(item['category'], categoryname.index(item['category']))
index = categoryname.index(item['category'].strip())
cid = categoryid[index]
except:
cid = None
val.append((
item["productname"],
item["QuantityPerunit"],
item["unitprice"],
random.choice(suppliers),
cid,
item["imageSrc"],
item["notes"],
item["class"],
item["isPrescribed"],
item["isStockOut"]
))
cursor.executemany(sql, val)
db.commit()
print(cursor.rowcount, "was inserted.")数据集
2020_3/data.zip (80MB)包括图片
故事结尾
Python 康德乐大药房网站爬虫,使用bs4获取json,导入mysql的更多相关文章
- (转)Python新手写出漂亮的爬虫代码2——从json获取信息
https://blog.csdn.net/weixin_36604953/article/details/78592943 Python新手写出漂亮的爬虫代码2——从json获取信息好久没有写关于爬 ...
- python下载各大主流视频网站电影
You-Get 是一个命令行工具, 用来下载各大视频网站的视频, 是我目前知道的命令行下载工具中最好的一个, 之前使用过 youtube-dl, 但是 youtube-dl 吧, 下载好的视频是分段的 ...
- python 全栈开发,Day134(爬虫系列之第1章-requests模块)
一.爬虫系列之第1章-requests模块 爬虫简介 概述 近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的 ...
- (转)Python新手写出漂亮的爬虫代码1——从html获取信息
https://blog.csdn.net/weixin_36604953/article/details/78156605 Python新手写出漂亮的爬虫代码1初到大数据学习圈子的同学可能对爬虫都有 ...
- Python 利用 BeautifulSoup 爬取网站获取新闻流
0. 引言 介绍下 Python 用 Beautiful Soup 周期性爬取 xxx 网站获取新闻流: 图 1 项目介绍 1. 开发环境 Python: 3.6.3 BeautifulSoup: ...
- 零基础学完Python的7大就业方向,哪个赚钱多?
“ 我想学 Python,但是学完 Python 后都能干啥 ?” “ 现在学 Python,哪个方向最简单?哪个方向最吃香 ?” “ …… ” 相信不少 Python 的初学者,都会遇到上面的这些问 ...
- python学习笔记(11)--爬虫下载漫画图片
说明: 1. 某本子网站爬虫,现在只实现了扒取一页,已经凌晨两点了,又饿又困,先睡觉,明天再写总结吧! 2. 我是明天,我来写总结了! 3. 这个网站的结构是这样的: 主页: 主页-第1页-漫画1封面 ...
- Python爬取mc皮肤【爬虫项目】
首先,找到一个皮肤网站,其中一个著名的皮肤网站就是 https://littleskin.cn .进入网站,我们就会见到一堆皮肤,这就是今天我们要爬的皮肤.给各位分享一下代码. PS:另外很多人在学习 ...
- python基础--14大内置模块(下)
(9)正则表达式和re模块(重点模块) 在我们学习这个模块之前,我们先明确一个关系.模块和实际工作的关系. 1)模块和实际工作时间的关系 1.time模块和时间是什么关系?time模块和时间本身是没有 ...
随机推荐
- 在基于ABP框架的前端项目Vue&Element项目中采用电子签章处理文件和打印处理
在一些内部OA或者流转的文件,或者给一些客户的报价文件.合同,或者一些医院出示的给保险机构的病历资料等,有时候可能都希望快速的使用电子签章的处理方式来给文件盖上特定的印章,本篇随笔介绍基于Vue&am ...
- CF1545X Codeforces Round #732
A. AquaMoon and Strange Sort 叉人题 如果数字各不相同,只需要统计每个数参与构成的逆序对总数,如果是奇数一定最终朝左,偶数朝右.无意义的数字交换对方向是没有影响的 继续考虑 ...
- Mybatis mapper文件占位符设置默认值
如果要设置占位符默认值的话:需要进行 设置 org.apache.ibatis.parsing.PropertyParser.enable-default-value 属性为true启用占位符默认值处 ...
- BIO、NIO、AIO的区别
一.基本概念 1.BIO:同步阻塞IO 2.NIO:同步非阻塞IO 3.AIO:异步阻塞IO IO操作包括两部分,发起IO请求.IO数据读写.阻塞非阻塞主要针对线程发起IO请求之后是否立即返回来定义的 ...
- ssl免密登录(centos6)
1.首先执行ll -a查看是否有隐藏文件.ssh,如果没有,需要执行ssh localhost登录以下即可 cd ~/.ssh 2.生成秘钥: 可查看https://hadoop.apache.org ...
- centos容器安装nginx及运行
进入centos容器: 安装依赖:yum insatll -y wget gcc gcc-c++ make openssl-devel 安装: 到官网复制下载链接:http://nginx.org/d ...
- 解释 AOP 模块?
AOP 模块用于发给我们的 Spring 应用做面向切面的开发, 很多支持由 AOP 联 盟提供,这样就确保了 Spring 和其他 AOP 框架的共通性.这个模块将元数据编 程引入 Spring.
- OGNL(Object-Graph Navigation Language)使用
OGNL表达式:https://www.jianshu.com/p/6bc6752d11f4 Apache OGNL:http://commons.apache.org/proper/commons- ...
- Java根路径设置(在获取本地路径时会获取到这个文件夹,,这样就可以专门放配置文件了)
在获取本地路径时会获取到这个文件夹,,这样就可以专门放配置文件了
- html5手机页面的那些meta
一.普通手机页的设置1.<meta name="viewport" content=""/>说明:屏幕的缩放 content的几个属性: width ...