Elasticsearch:Index生命周期管理入门
如果您要处理时间序列数据,则不想将所有内容连续转储到单个索引中。 取而代之的是,您可以定期将数据滚动到新索引,以防止数据过大而又缓慢又昂贵。 随着索引的老化和查询频率的降低,您可能会将其转移到价格较低的硬件上,并减少分片和副本的数量。
要在索引的生命周期内自动移动索引,可以创建策略来定义随着索引的老化对索引执行的操作。 索引生命周期策略在与Beats数据发件人一起使用时特别有用,Beats数据发件人不断将运营数据(例如指标和日志)发送到Elasticsearch。 当现有索引达到指定的大小或期限时,您可以自动滚动到新索引。 这样可以确保所有索引具有相似的大小,而不是每日索引,其大小可以根beats数和发送的事件数而有所不同。
让我们通过动手操作场景跳入索引生命周期管理(Index cycle management: ILM)。 本文章将利用您可能不熟悉的ILM独有的许多新概念。 我们先用一个示例来展示。本示例的目标是建立一组索引,这些索引将封装来自时间序列数据源的数据。 我们可以想象有一个像Filebeat这样的系统,可以将文档连续索引到我们的书写索引中。 我们希望在索引达到50 GB,或文档的数量超过10000,或已在30天前创建索引后对其进行rollover,然后在90天后删除该索引。

上图显示一个Log文档在Elasticsearch中生命周期。
运行两个node的Elasticsearch集群
我们可以参考文章“Elasticsearch:运用shard filtering来控制索引分配给哪个节点”运行起来两个node的cluster。其实非常简单,当我们安装好Elasticsearch后,打开一个terminal,并运行如下的命令:
./bin/elasticsearch -E node.name=node1 -E node.attr.data=hot -Enode.max_local_storage_nodes=2
它将运行起来一个叫做node1的节点。同时在另外terminal中运行如下的命令:
./bin/elasticsearch -E node.name=node2 -E node.attr.data=warm -Enode.max_local_storage_nodes=2
它运行另外一个叫做node2的节点。我们可以通过如下的命令来进行查看:
GET _cat/nodes?v
显示两个节点:

我们可以用如下的命令来检查这两个node的属性:
GET _cat/nodeattrs?v&s=name
显然其中的一个node是hot,另外一个是warm。

准备数据
运行起来我们的Kibana:
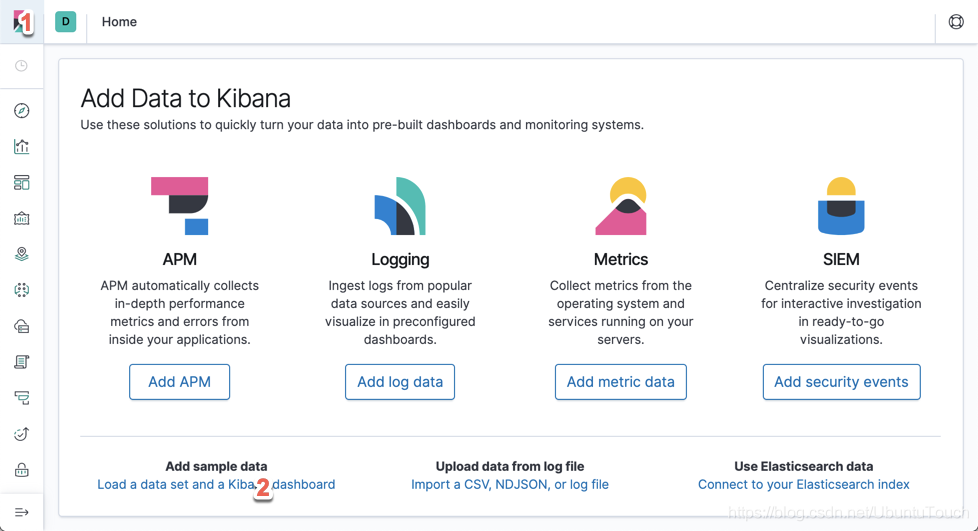
我们分别点击上面的1和2处:
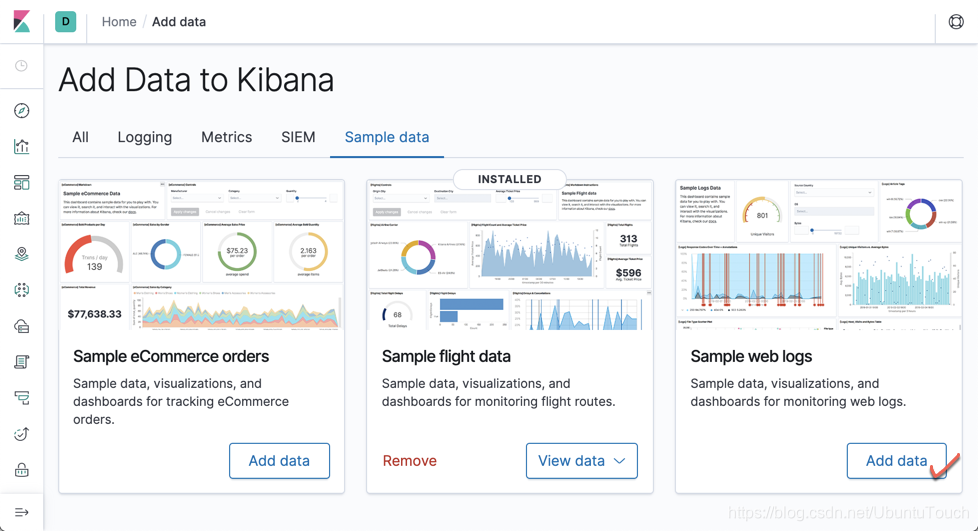
点击上面的“Add data”。这样我们就可以把我们的kibana_sample_data_logs索引加载到Elasticsearch中。我们可以通过如下的命令进行查看:
GET _cat/indices/kibana_sample_data_logs
命令显示结果为:
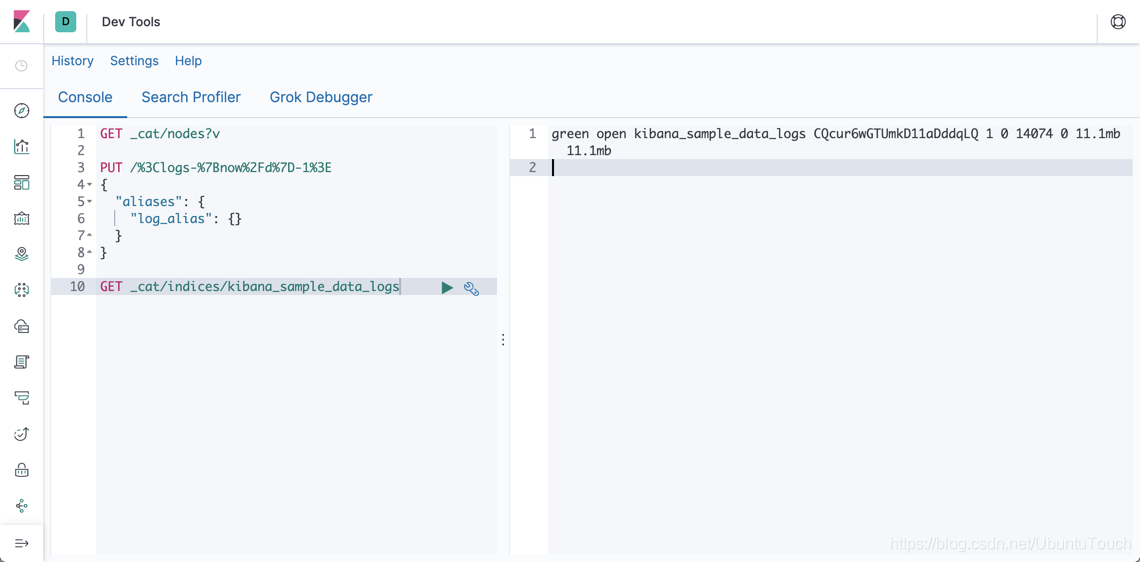
它显示kibana_sample_data_logs具有11.1M的数据,并且它有14074个文档。
建立ILM policy
我们可以通过如下的方法来建立一个ILM的policy.
PUT _ilm/policy/logs_policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_size": "50gb",
"max_age": "30d",
"max_docs": 10000
},
"set_priority": {
"priority": 100
}
}
},
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
}
}
这里定义的一个policy意思是:
- 如果一个index的大小超过50GB,那么自动rollover
- 如果一个index日期已在30天前创建索引后,那么自动rollover
- 如果一个index的文档数超过10000,那么也会自动rollover
- 当一个index创建的时间超过90天,那么也自动删除
其实这个我们也可以通过Kibana帮我们来实现。请按照如下的步骤:

紧接着点击“Index Lifecycle Policies”:

再点击“Create Policy”:


最后点“Save as new Policy”及可以在我们的Kibana中同过如下的命令可以查看到:
GET _ilm/policy/logs_policy
显示结果:

设置Index template
我们可以通过如下的方法来建立template:
PUT _template/datastream_template
{
"index_patterns": ["logs*"],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "logs_policy",
"index.routing.allocation.require.data": "hot",
"index.lifecycle.rollover_alias": "logs"
}
}
这里的意思是所有以logs开头的index都需要遵循这个规律。这里定义了rollover的alias为“logs ”。
这在我们下面来定义。同时也需要注意的是"index.routing.allocation.require.data": "hot"。
这个定义了我们需要indexing的node的属性是hot。请看一下我们上面的policy里定义的有一个叫做phases里的,它定义的是"hot"。
在这里我们把所有的logs*索引都置于hot属性的node里。在实际的使用中,hot属性的index一般用作indexing。我们其实还可以定义一些其它phase,比如warm,这样可以把我们的用作搜索的index置于warm的节点中。这里就不一一描述了。
定义Index alias
我们可以通过如下的方法来定义:
PUT logs-000001
{
"aliases": {
"logs": {
"is_write_index": true
}
}
}
在这里定义了一个叫做logs的alias,它指向logs-00001索引。注意这里的is_write_index为true。如果有rollover发生时,这个alias会自动指向最新rollover的index。
生产数据
在这里,我们使用之前我们已经导入的测试数据kibana_sample_data_logs,我们可以通过如下的方法来写入数据:
POST _reindex?requests_per_second=500
{
"source": {
"index": "kibana_sample_data_logs"
},
"dest": {
"index": "logs"
}
}
上面的意思是每秒按照500个文档从kibana_sample_data_logs索引reindex文档到logs别名所指向的index。我们运行后,通过如下的命令来查看最后的结果:
GET logs*/_count
显示如下:

我们可以看到有14074个文档被reindex到logs*索引中。通过如下的命令来查看:
GET _cat/shards/logs*

我们可以看到logs-000002已经生产,并且所有的索引都在node1上面。我们可以通过如下的命令:
GET _cat/indices/logs?v

我们可以看到logs-000001索引中有10000个文档,而logs-000002中含有4074个文档。
由于我们已经设定了policy,那么所有的这些logs*索引的生命周期只有90天。90天过后(从索引被创建时算起),索引会自动被删除掉。
汇总整理一下
创建索引生命周期策略
可以通过命令行工具创建,也可以通过在kibana界面创建,建议通过kibana界面创建把索引关联到索引生命周期策略
可以通过命令行工具进行关联,也可以通过在kibana界面进行关联,建议通过kibana界面创建,若不生效,再采用命令行工具进行关联
命令行工具关联:
PUT _template/filebeat_template
{
"index_patterns": ["filebeat-84-*","filebeat-61-*","filebeat-128-*"], # 索引模式
"settings": {
"index.lifecycle.name": "filebeat-7.3.0" # 索引生命周期策略名称
}
}
通过kibana界面进行关联:


Elasticsearch:Index生命周期管理入门的更多相关文章
- Elasticsearch索引生命周期管理方案
一.前言 在 Elasticsearch 的日常中,有很多如存储 系统日志.行为数据等方面的应用场景,这些场景的特点是数据量非常大,并且随着时间的增长 索引 的数量也会持续增长,然而这些场景基本上只有 ...
- Elasticsearch 快照生命周期管理 (SLM) 实战指南
文章转载自:https://mp.weixin.qq.com/s/PSfgPJc4dKN2pOZd0Y02wA 1.Elasticsearch 保证高可用性的方式 Elasticsearch 保证集群 ...
- Elasticsearch索引生命周期管理探索
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484130&idx=1&sn=454f199 ...
- Elasticsearch 索引生命周期管理 ILM 实战指南
文章转载自:https://mp.weixin.qq.com/s/7VQd5sKt_PH56PFnCrUOHQ 1.什么是索引生命周期 在基于日志.指标.实时时间序列的大型系统中,集群的索引也具备类似 ...
- ElasticSearch——索引生命周期管理
从ES6.6开始,Elasticsearch提供索引生命周期管理功能,索引生命周期管理可以通过API或者kibana界面配置,详情参考[index-lifecycle-management] 本文仅通 ...
- ElasticSearch生命周期管理-索引策略配置与操作
概述 本文是在本人学习研究ElasticSearch的生命周期管理策略时,发现官方未提供中文文档,有的也是零零散散,此文主要是翻译官方文档Policy phases and actions模块. 注: ...
- Elasticsearch7.X ILM索引生命周期管理(冷热分离)
Elasticsearch7.X ILM索引生命周期管理(冷热分离) 一.“索引生命周期管理”概述 Elasticsearch索引生命周期管理指:Elasticsearch从设置.创建.打开.关闭.删 ...
- Logstash & 索引生命周期管理(ILM)
Grok语法 Grok是通过模式匹配的方式来识别日志中的数据,可以把Grok插件简单理解为升级版本的正则表达式.它拥有更多的模式,默认,Logstash拥有120个模式.如果这些模式不满足我们解析日志 ...
- Elastic 使用索引生命周期管理实现热温冷架构
Elastic: 使用索引生命周期管理实现热温冷架构 索引生命周期管理 (ILM) 是在 Elasticsearch 6.6(公测版)首次引入并在 6.7 版正式推出的一项功能.ILM 是 Elast ...
随机推荐
- ETL工具 Flume (一)
分布式日志采集系统Flume学习 一.Flume架构 1.1 Hadoop业务开发流程 1.2 Flume概述 flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. 支持在日志系统 ...
- Hive sql 经典题目和 复杂hsq
案例一 练习:一:将下列数据加载hive表. 员工信息表emp:字段:员工id,员工名字,工作岗位,部门经理,受雇日期,薪水,奖金,部门编号英文名:EMPNO,ENAME,JOB,MGR,HIREDA ...
- 「一本通 1.1 例 4」加工生产调度(贪心算法)(luogu P1248)题解
加工生产调度 题目描述 某工厂收到了 n n n 个产品的订单,这 n n n 个产品分别在 A.B 两个车间加工,并且必须先在 A 车间加工后才可以到 B 车间加工. 某个产品 i i i 在 A. ...
- GDOI 2022 普及组游记
To LuoguDAY -1 期中考成绩下来了,全无了除了历史 (96) 和生物 (95) 还能看,剩下的-,语文 101.5 ,少错一道选择和断句就 107.5 了,居然比雌兔还低 数学少错一道选择 ...
- redis集群的三种方式
Redis三种集群方式:主从复制,哨兵模式,Cluster集群. 主从复制 基本原理 当新建立一个从服务器时,从服务器将向主服务器发送SYNC命令,接收到SYNC命令后的主服务器会进行一次BGSAVE ...
- 乘风破浪,遇见未来新能源汽车(Electric Vehicle)之特斯拉提车必须知道的十个流程
订车 线下门店或者官网可以咨询和下单,一般来说,订金就是1000,还算可以接受. 订单账号 特斯拉账号是以邮箱为区分的,而不是手机号,我们下单的时候需要提供一个邮箱用来注册特斯拉账号. 注意了,敲黑板 ...
- input 回车输入+选择标签
来源 博客园收藏博客 页面展示 模板代码 需求 点击按钮可在已建标签列表中选择标签: 对于没有的标签:在输入框中输入后,回车键新建标签 补充 以前做过类似这样的组件:select 下拉列表 + 回车新 ...
- mysql玩法
如何字段名查找所在的表名 SELECT TABLE_NAME FROM INFORMATION_SCHEMA.COLUMNS WHERE COLUMN_NAME = '字段名字' select sys ...
- 原型设计工具Axure RP9下载、汉化操作说明(赠授权码)
Axure是产品经理.交互设计常用的一款原型设计工具,能实现比较复杂的交互效果.其实在功能上是十分齐全的,并且其交互的样式也比较多样,主要是通过动态面板.函数.中继器等几个模块就几乎可以实现任何常见的 ...
- ExcelPatternTool: Excel表格-数据库互导工具
ExcelPatternTool Excel表格-数据库互导工具 介绍: 指定Pattern文件-一个规则描述的json文档,基于此规则实现Excel表格与数据库之间的导入导出,校验等功能. 特点: ...