pyspark 结构化数据开发实例
什么是SPARK?
1. 先进的大数据分布式编程和计算框架
2. 替换Hadoop 中的MR计算引擎。
3. 内存分布式计算:运行数度快
4. 可以使用不同的语言编程(java,scala,r 和python)
5. 可以从不同的数据源获取数据,可以从HDFS,Cassandea,HBase等等,同时可以支持很多的文件格式:text Seq AVRO Parquet
6. 实现不同的大数据功能:Spark Core,Sparc SQL等等
本文是基于pyspark 的进行数据ETL 和统计分析的代码示例,数据源来源于MySQL。 本文使用较小的数据量作为实例,当然同样适用于海量数据的情况。 运行本文代码的前提是
在Windows11 上搭建 pyspark 的开发环境。
我的环境:
1,jdk 1.8
2, hadoop 3.3.4
3, spark 3.3.1
4,python 3.9
代码设计要点:
1, 使用pyspark 读取 mysql 表数据。
2,使用rdd api 对 结构化数据做简单ETL,设置了简单的清洗规则。
1,cityCode 字段非空,全部为数字, 位数为9位, 前3位必须为”001“ 。
3, 使用3种抽象层级的API (RDD API , Dataframe api, SQL api )对数据进行分析计算 ,比较3种API的使用区别
4,包括了一些 rdd, Datafram 相互转换, ROW类型的使用
# Imports
from pyspark.sql import SparkSession # Create SparkSession
spark = SparkSession.builder \
.appName('SparkByExamples.com') \
.config("spark.jars", "mysql-connector-java-5.1.28.jar") \
.getOrCreate() # Read from MySQL Table
table_df = spark.read \
.format("jdbc") \
.option("driver", "com.mysql.jdbc.Driver") \
.option("url", "jdbc:mysql://134.**.**.**:9200/hesc_stm_xhm") \
.option("dbtable", "temp_user_grid") \
.option("user", "root") \
.option("password", "****") \
.load() # check read accessable
# print( table_df.count()) # 总行数 # etl 使用rdd 算子
rdd = table_df.rdd
# print(rdd.first()) # cityCode
# print(rdd.filter(lambda r: r(5) == None).count()) # gridCode为空的行数 rdd1 = rdd.filter(lambda r: Row.asDict(r).get("cityCode") != None).filter(
lambda r: len(Row.asDict(r).get("cityCode")) == 9) # print(rdd.map(lambda r: Row.asDict(r).get("cityCode")).take(5)) # ROW类型的元素读取 使用 r(19)读取列有问题 def checkCityCode(str):
# 判断字符串的格式,前3位为001,而且全为数字
if (str[:3] == '001') and str.isnumeric():
return True
else:
return False rdd2 = rdd1.filter(lambda r: checkCityCode(Row.asDict(r).get("cityCode")))
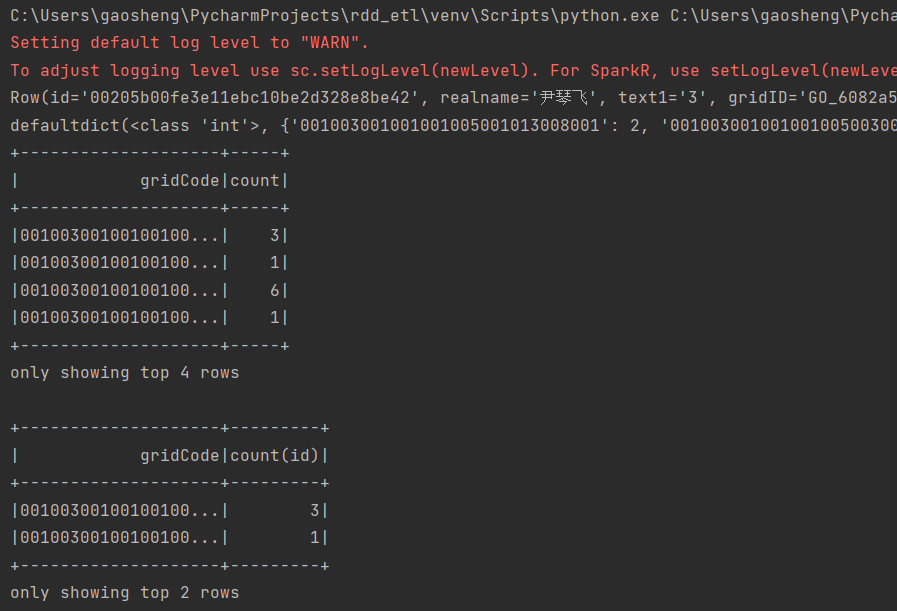
print(rdd2.first()) # 数据分析 使用 rdd df算子 sql 三种算子 ; 统计不同网格的人员数量。
# rdd operator map = rdd2.map(lambda r: (Row.asDict(r).get("gridCode"), Row.asDict(r).get("id"))).countByKey()
print(map) # 查询python rdd api # df/ds operator dataset 1.6之后加入, 整合了RDD 的强类型便于使用lambda函数以及 sqpark sql 优化引擎
# python 没有dataset 类型。java scala 可以。 dataframe是 dataset 的 一种。 dataframe 适用python . df = rdd2.toDF()
df1 = df.groupBy('gridCode').count() # dataframe 特定编程语言 对结构化数据操作, 也称 无类型dataset算子
df1.show(4) # sql operator
df.createOrReplaceTempView('temp_user_grip')
df2 = spark.sql("select gridCode, count(id) from temp_user_grip group by gridCode")
df2.show(2) spark.stop()
运行输出:
pyspark 结构化数据开发实例的更多相关文章
- seo之google rich-snippets丰富网页摘要结构化数据(微数据)实例代码
seo之google rich-snippets丰富网页摘要结构化数据(微数据)实例代码 网页摘要是搜索引擎搜索结果下的几行字,用户能通过网页摘要迅速了解到网页的大概内容,传统的摘要是纯文字摘要,而结 ...
- Bigtable:一个分布式的结构化数据存储系统
Bigtable:一个分布式的结构化数据存储系统 摘要 Bigtable是一个管理结构化数据的分布式存储系统,它被设计用来处理海量数据:分布在数千台通用服务器上的PB级的数据.Google的很多项目将 ...
- [Python]ctypes+struct实现类c的结构化数据串行处理
1. 用C/C++实现的结构化数据处理 在涉及到比较底层的通信协议开发过程中, 往往需要开发语言能够有效的表达和处理所定义的通信协议的数据结构. 在这方面是C/C++语言是具有天然优势的: 通过str ...
- Spark如何与深度学习框架协作,处理非结构化数据
随着大数据和AI业务的不断融合,大数据分析和处理过程中,通过深度学习技术对非结构化数据(如图片.音频.文本)进行大数据处理的业务场景越来越多.本文会介绍Spark如何与深度学习框架进行协同工作,在大数 ...
- 【阿里云产品公测】结构化数据服务OTS之JavaSDK初体验
[阿里云产品公测]结构化数据服务OTS之JavaSDK初体验 作者:阿里云用户蓝色之鹰 一.OTS简单介绍 OTS 是构建在阿里云飞天分布式系统之上的NoSQL数据库服务,提供海量结构化数据的存储和实 ...
- TensorFlow从1到2(六)结构化数据预处理和心脏病预测
结构化数据的预处理 前面所展示的一些示例已经很让人兴奋.但从总体看,数据类型还是比较单一的,比如图片,比如文本. 这个单一并非指数据的类型单一,而是指数据组成的每一部分,在模型中对于结果预测的影响基本 ...
- Solr系列四:Solr(solrj 、索引API 、 结构化数据导入)
一.SolrJ介绍 1. SolrJ是什么? Solr提供的用于JAVA应用中访问solr服务API的客户端jar.在我们的应用中引入solrj: <dependency> <gro ...
- Salesforce开源TransmogrifAI:用于结构化数据的端到端AutoML库
AutoML 即通过自动化的机器学习实现人工智能模型的快速构建,它可以简化机器学习流程,方便更多人利用人工智能技术.近日,软件行业巨头 Salesforce 开源了其 AutoML 库 Transmo ...
- Bigtable:结构化数据的分布式存储系统
Bigtable最初是谷歌设计用来存储大规模结构化数据的分布式系统,其可以在数以千计的商用服务器上存储高达PB级别的数据量.开源社区根据Bigtable的设计思路开发了HBase.其优势在于提供了高效 ...
- RocketMQ Schema——让消息成为流动的结构化数据
本文作者:许奕斌,阿里云智能高级研发工程师. Why we need schema RocketMQ 目前对于消息体没有任何数据格式的约束,可以是 JSON ,可以是对象 toString ,也可以只 ...
随机推荐
- 使用云服务器配置MariaDB环境,Navicat远程连接一直出错误代码 "2002 - Can't connect to server on '' (10060)"
使用腾讯云或者阿里云的服务器配置MariaDB数据库环境的时候,用Navicat远程连接在Centos7的Linux上配置MariaDB数据库环境的时候一直出错误代码 "2002 - Can ...
- 东方CannonBall
代码 #include<cstdio> using namespace std; const int N = 1e5; double fx[N + 5] , fy[N + 5] , g[N ...
- 从零开始使用阿里云OSS服务(白嫖)
阿里云对象存储服务OSS使用记录 1 新人免费开通OSS服务 访问 阿里云官网,登录账号(个人新用户账号),首页搜索 对象存储OSS,点击下方的直达. 点击立即开通,此时会在一个新网页中完成开通 完成 ...
- key对象转换数组title
before <!DOCTYPE HTML> <html> <head> <title>key对象转换数组title</title> < ...
- wpf 样式style封装以及点击按钮打开新窗口
在页面引用: ok~ 点击按钮打开新窗口: 1.点击按钮 点击工具栏的这个小闪电 2.双击click后的灰框或者输入点击事件名称 3.这里是打开window1窗口 ok~
- 通过反射机制简化 JDBC ResultSet 实体类的注入
提出问题 查询完某个表之后,一般都是把结果的每一个字段注入到一个实体类中.比如,数据库 users 表,查询出来的结果注入到 User 实体类中. 通过 while 遍历 ResultSet,把字段对 ...
- pat乙级 1017 A除以B 模拟除法
#include <stdio.h> #define MAX_A 1000 int A[MAX_A]; int B; /* 除数 */ int num; /* A 被除数有多少位 */ v ...
- 四大组件之广播接收者BroadcastReceiver
参考:Android开发基础之广播接收者BroadcastReceiver 什么是广播接收者? 我们小时候都知道,听广播,收听广播!什么是收听广播呢?打开收音机,调频就可以收到对应的广播节目了.其实我 ...
- 查电脑并修改IP地址,你晓得吗?
查电脑并修改IP地址,你晓得吗? 好记性不如烂笔头,古人的话,浅显却好有深意,越品越有味道. 每次都会忘记怎么查电脑IP,那么今天就写下来吧! 方法一:通过命令行查询IP地址 快捷键Win ...
- 【面试题】ES6语法五之箭头函数
ES6特性=>. function foo(x, y){ return x + y } var foo = (x, y) => x + y 包括一个参数列表(零个或多个参数,如果参数不是一 ...